
The domain of artificial intelligence continues its rapid expansion, with Large Language Models (LLMs) increasingly demonstrating sophisticated cognitive abilities. Among these, FractalAIResearch/Fathom-R1-14B emerges as a noteworthy model, housing approximately 14.8 billion parameters. This model has been specifically engineered by Fractal AI Research to excel in complex mathematical and general reasoning tasks. What sets Fathom-R1-14B apart is its ability to achieve this high level of performance with remarkable cost-efficiency and within a practical 16,384 (16K) token context window. This article offers a technical overview of Fathom-R1-14B, detailing its development, architecture, training processes, benchmarked performance, and providing a focused guide to its practical implementation based on established methods.
Fractal AI: The Innovators Behind the Model

Fathom-R1-14B is a product of Fractal AI Research, the research division of Fractal, a distinguished AI and analytics firm headquartered in Mumbai, India. Fractal has earned a global reputation for delivering artificial intelligence and advanced analytics solutions to Fortune 500 companies. The creation of Fathom-R1-14B aligns closely with India's growing ambitions in the artificial intelligence sector.
India's AI Aspirations
The development of this model is particularly significant within the context of the IndiaAI Mission. Srikanth Velamakanni, Co-founder, Group Chief Executive & Vice-Chairman of Fractal, indicated that Fathom-R1-14B is an early demonstration of a larger initiative. He mentioned, "We proposed building India's first large reasoning model (LRM) as part of the IndiaAI mission...This [Fathom-R1-14B] is just a tiny proof of what's possible," alluding to plans for a series of models, including a much larger 70-billion parameter version. This strategic direction highlights a national commitment to AI self-reliance and the creation of indigenous foundational models. Fractal's broader contributions to AI include other impactful projects, such as Vaidya.ai, a multi-modal AI platform for healthcare assistance. The release of Fathom-R1-14B as an open-source tool therefore not only benefits the global AI community but also signifies a key achievement in India's evolving AI landscape.
Foundational Design and Architectural Blueprint of Fathom-R1-14B
The impressive capabilities of Fathom-R1-14B are built upon a carefully chosen foundation and a robust architectural design, optimized for reasoning tasks.
The journey of Fathom-R1-14B began with the selection of Deepseek-R1-Distilled-Qwen-14B as its base model. The "distilled" nature of this model signifies that it is a more compact and computationally efficient derivative of a larger parent model, specifically designed to retain a significant portion of the original's capabilities, particularly those from the well-regarded Qwen family. This provided a strong starting point, which Fractal AI Research then meticulously enhanced through specialized post-training techniques. For its operations, the model typically utilizes bfloat16 (Brain Floating Point Format) precision, which strikes an effective balance between computational speed and the numerical accuracy required for complex calculations.
Fathom-R1-14B is constructed upon the Qwen2 architecture, a powerful iteration within the Transformer model family. Transformer models are the current standard for high-performing LLMs, largely due to their innovative self-attention mechanisms. These mechanisms enable the model to dynamically weigh the significance of different tokens—be they words, sub-words, or mathematical symbols—within an input sequence when generating its output. This ability is crucial for comprehending the intricate dependencies present in complex mathematical problems and nuanced logical arguments.
The model's scale, characterized by approximately 14.8 billion parameters, is a key factor in its performance. These parameters, which are essentially the learned numerical values within the neural network's layers, encode the model's knowledge and reasoning capabilities. A model of this size offers substantial capacity for capturing and representing complex patterns from its training data.
The Significance of the 16K Context Window
A critical architectural specification is its 16,384-token context window. This determines the maximum length of the combined input prompt and the model-generated output that can be processed in a single operation. While some models boast much larger context windows, the 16K capacity of Fathom-R1-14B is a deliberate and pragmatic design choice. It is sufficiently large to accommodate detailed problem statements, extensive step-by-step reasoning chains (as often required in Olympiad-level mathematics), and comprehensive answers. Importantly, this is achieved without incurring the quadratic scaling of computational cost that can be associated with the attention mechanisms in extremely long sequences, making Fathom-R1-14B more agile and less resource-intensive during inference.
Fathom-R1-14B is Really, Really Cost-Effective
One of the most striking aspects of Fathom-R1-14B is the efficiency of its post-training process. The primary version of the model was fine-tuned for a reported cost of approximately $499 USD. This remarkable economic viability was achieved through a sophisticated, multi-faceted training strategy focused on maximizing reasoning skills without excessive computational expenditure.
The core techniques underpinning this efficient specialization included:
- Supervised Fine-Tuning (SFT): This foundational phase involved training the base model on a high-quality, curated dataset of problem-solution pairs specifically tailored to advanced mathematical reasoning. Through SFT, the model learned to emulate correct problem-solving pathways and logical deduction.
- Iterative Curriculum Learning: Rather than exposing the model to the full spectrum of problem difficulty at once, this strategy introduces challenges in a graduated manner. The model begins with simpler mathematical problems and progressively moves to more complex ones, such as those from the AIME and HMMT. This structured approach facilitates more stable and effective learning, allowing the model to build a strong foundation before tackling highly challenging tasks. This technique was central to the development of a key precursor model,
Fathom-R1-14B-V0.6. - Model Merging: The final Fathom-R1-14B model is an amalgamation of two specifically fine-tuned predecessor models:
Fathom-R1-14B-V0.6(which underwent Iterative Curriculum SFT) andFathom-R1-14B-V0.4(which focused on SFT with "Shortest-Chains," likely emphasizing conciseness in solutions). By merging models trained with slightly different focuses, the resulting model inherits a broader set of strengths.
The overarching goal of this meticulous training process was to instill "concise yet accurate mathematical reasoning."
Fractal AI Research also explored an alternative training pathway with a variant named Fathom-R1-14B-RS. This version incorporated Reinforcement Learning (RL), specifically using an algorithm referred to as GRPO (Generalized Reward Pushing Optimization), alongside SFT. While this approach yielded comparable high performance, its post-training cost was slightly higher, at $967 USD. The development of both versions underscores a commitment to exploring diverse methodologies to achieve optimal reasoning performance efficiently. As part of their commitment to transparency, Fractal AI Research has open-sourced the training recipes and datasets.
Performance Benchmarks: Quantifying Reasoning Excellence
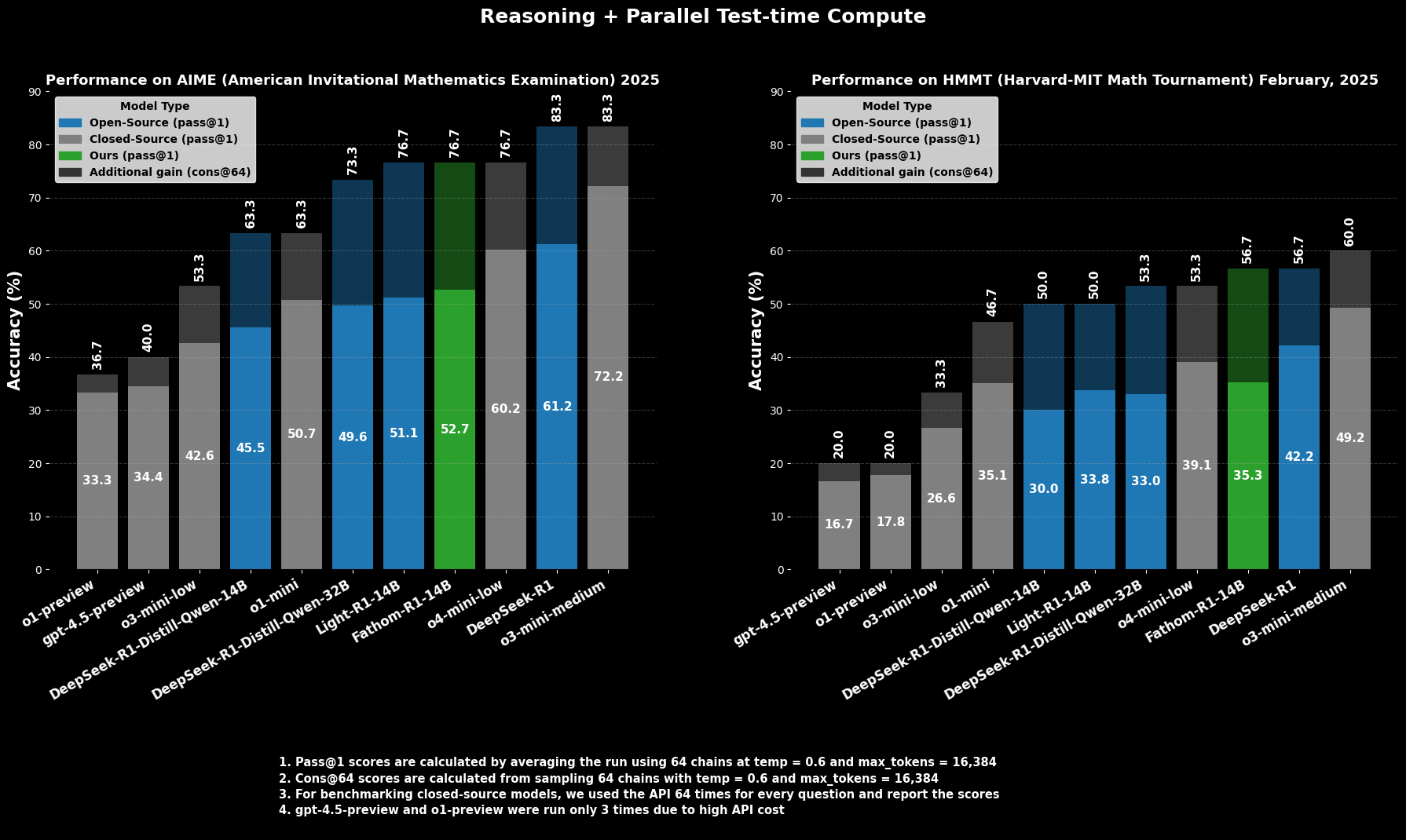
The proficiency of Fathom-R1-14B is not merely theoretical; it is substantiated by impressive performance on rigorous, internationally recognized mathematical reasoning benchmarks.
Success on AIME and HMMT
On the AIME2025 (American Invitational Mathematics Examination), a challenging pre-college mathematics competition, Fathom-R1-14B achieves a Pass@1 accuracy of 52.71%. The Pass@1 metric indicates the percentage of problems for which the model generates a correct solution in a single attempt. When allowed more computational budget at test time, evaluated using cons@64 (consistency among 64 sampled solutions), its accuracy on AIME2025 climbs to an impressive 76.7%.
Similarly, on the HMMT25 (Harvard-MIT Mathematics Tournament), another high-level competition, the model scores 35.26% Pass@1, which increases to 56.7% cons@64. These scores are particularly noteworthy because they are achieved within the model's 16K token output budget, reflecting practical deployment considerations.
Comparative Performance
In comparative evaluations, Fathom-R1-14B significantly outperforms other open-source models of similar or even larger sizes on these specific mathematical benchmarks at Pass@1. More strikingly, its performance, especially when considering the cons@64 metric, positions it as competitive with some capable closed-source models, which are often presumed to have access to vastly greater resources. This highlights Fathom-R1-14B's efficiency in translating its parameters and training into high-fidelity reasoning.
Let's Try to Run Fathom-R1-14B
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
This section provides a focused guide on running Fathom-R1-14B using the Hugging Face transformers library within a Python environment. This approach is well-suited for users with access to capable GPU hardware, either locally or through cloud providers. The steps outlined here closely follow established practices for deploying such models.
Environment Configuration
Setting up a suitable Python environment is crucial. The following steps detail a common setup using Conda on a Linux-based system (or Windows Subsystem for Linux):
Access Your Machine: If using a remote cloud GPU instance, connect to it via SSH.Bash
# Example: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
Verify GPU Recognition: Ensure the system recognizes the NVIDIA GPU and drivers are correctly installed.Bash
nvidia-smi
Create and Activate a Conda Environment: It's good practice to isolate project dependencies.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
Install Necessary Libraries: Install PyTorch (compatible with your CUDA version), Hugging Face transformers, accelerate (for efficient model loading and distribution), notebook (for Jupyter), and ipywidgets (for notebook interactivity).Bash
# Ensure you install a PyTorch version compatible with your GPU's CUDA toolkit
# Example for CUDA 11.8:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Or for CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Python-Based Inference in a Jupyter Notebook
With the environment prepared, you can use a Jupyter Notebook to load and interact with Fathom-R1-14B.
Start Jupyter Notebook Server: If on a remote server, start Jupyter Notebook allowing remote access and specify a port.Bash
jupyter notebook --no-browser --port=8888 --allow-root
If running remotely, you'll likely need to set up SSH port forwarding from your local machine to access the Jupyter interface:Bash
# Example: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
Then, open http://localhost:8889 (or your chosen local port) in your web browser.
Python Code for Model Interaction: Create a new Jupyter Notebook and use the following Python code:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Define the model ID from Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Loading tokenizer for {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Loading model {model_id} (this may take a while)...")
# Load the model with bfloat16 precision for efficiency and device_map for auto distribution
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it
device_map="auto", # Automatically distributes model layers across available hardware
trust_remote_code=True # Some models may require this
)
print("Model and tokenizer loaded successfully.")
# Define a sample mathematical prompt
prompt = """Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. In June, she sold 4 more clips than in May. How many clips did Natalia sell altogether in April, May, and June? Provide a step-by-step solution.
Solution:"""
print(f"\nPrompt:\n{prompt}")
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Ensure inputs are on the model's device
print("\nGenerating solution...")
# Generate the output from the model
# Adjust generation parameters as needed for different types of problems
outputs = model.generate(
**inputs,
max_new_tokens=768, # Maximum number of new tokens to generate for the solution
num_return_sequences=1, # Number of independent sequences to generate
temperature=0.1, # Lower temperature for more deterministic, factual outputs
top_p=0.7, # Use nucleus sampling with top_p
do_sample=True # Enable sampling for temperature and top_p to have an effect
)
# Decode the generated tokens into a string
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerated Solution:\n")
print(solution_text)
Conclusion: The Impact of Fathom-R1-14B on Accessible AI
FractalAIResearch/Fathom-R1-14B stands as a compelling demonstration of technical ingenuity in the contemporary AI arena. Its specific design, featuring approximately 14.8 billion parameters, the Qwen2 architecture, and a 16K token context window, when combined with groundbreaking and cost-effective training (around $499 for the primary version), has resulted in an LLM that delivers leading-edge performance. This is evidenced by its scores on strenuous mathematical reasoning benchmarks like AIME and HMMT.
Fathom-R1-14B compellingly illustrates that the frontiers of AI reasoning can be advanced through intelligent design and efficient methodologies, fostering a future where high-performance AI is more democratic and widely beneficial.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demands, and replaces Postman at a much more affordable price!


