
Developers and researchers seek models that prioritize reasoning to power autonomous agents. DeepSeek-V3.2 and its specialized variant, DeepSeek-V3.2-Speciale, address this need precisely. These models build on prior iterations, such as DeepSeek-V3.2-Exp, to deliver enhanced capabilities in logical inference, mathematical problem-solving, and agentic workflows. Engineers now access tools that process complex queries with efficiency, surpassing benchmarks set by leading closed-source systems.
As we examine these models, focus remains on their technical merits. First, the open-source foundation enables broad experimentation. Then, API access provides scalable deployment options. Throughout this post, data from official sources and benchmarks illustrate their potential.
Open-Sourcing DeepSeek-V3.2: A Foundation for Collaborative AI Development
DeepSeek releases DeepSeek-V3.2 under the permissive MIT License, fostering widespread adoption among the AI community. This decision empowers developers to inspect, modify, and deploy the model without restrictive barriers. Consequently, teams accelerate innovation in agentic applications, from automated code generation to multi-step reasoning pipelines.
The model's architecture centers on DeepSeek Sparse Attention (DSA), a mechanism that optimizes computational demands for long-context processing. DSA employs fine-grained sparsity, reducing attention complexity from quadratic to near-linear scales while preserving output quality. For instance, in sequences exceeding 128,000 tokens—equivalent to hundreds of pages of text—the model maintains inference speeds competitive with smaller counterparts.
DeepSeek-V3.2 features 685 billion parameters, distributed across tensor types like BF16, F8_E4M3, and F32 for flexible quantization. Training incorporates a scalable reinforcement learning (RL) framework, where agents learn through iterative feedback on synthetic tasks. This approach refines reasoning paths, enabling the model to chain logical steps effectively. Additionally, a large-scale agentic task synthesis pipeline generates diverse scenarios, blending reasoning with tool invocation. Developers access these via Hugging Face repositories, where pre-trained weights and base models reside.
Usage begins with encoding inputs in an OpenAI-compatible format, facilitated by Python scripts in the model's encoding directory. The chat template introduces a "thinking with tools" mode, where the model deliberates before acting. Sampling parameters—temperature at 1.0 and top_p at 0.95—yield consistent yet creative outputs. For local deployment, the GitHub repository for DeepSeek-V3.2-Exp offers CUDA-optimized operators, including a TileLang variant for diverse GPU ecosystems.
Furthermore, the MIT License ensures enterprise viability. Organizations customize the model for proprietary agents without legal hurdles. Benchmarks validate this openness: DeepSeek-V3.2 achieves parity with GPT-5 in aggregated reasoning scores, as detailed in the technical report. Thus, open-sourcing not only democratizes access but also benchmarks against proprietary giants.
DeepSeek-V3.2-Speciale: Tailored Enhancements for Advanced Reasoning Demands
While DeepSeek-V3.2 serves general purposes, DeepSeek-V3.2-Speciale targets deep reasoning exclusively. This variant applies high-compute post-training to the same 685B parameter base, amplifying proficiency in abstract problem-solving. As a result, it secures gold-medal equivalents in 2025's International Mathematical Olympiad (IMO) and International Olympiad in Informatics (IOI), outperforming human baselines in submitted solutions.
Architecturally, DeepSeek-V3.2-Speciale mirrors its sibling with DSA for efficient long-context handling. However, post-training emphasizes RL on curated datasets, including olympiad problems and synthetic agentic chains. This process hones chain-of-thought (CoT) reasoning, where the model decomposes queries into verifiable steps. Notably, it omits tool-calling support to concentrate resources on pure inference, making it ideal for compute-intensive tasks like theorem proving.
The Hugging Face model card highlights differences: DeepSeek-V3.2-Speciale processes inputs without external dependencies, relying on internal deliberation. Developers encode messages similarly, but outputs demand custom parsing due to the absence of Jinja templates. Error handling in production code becomes crucial, as malformed responses require validation layers.
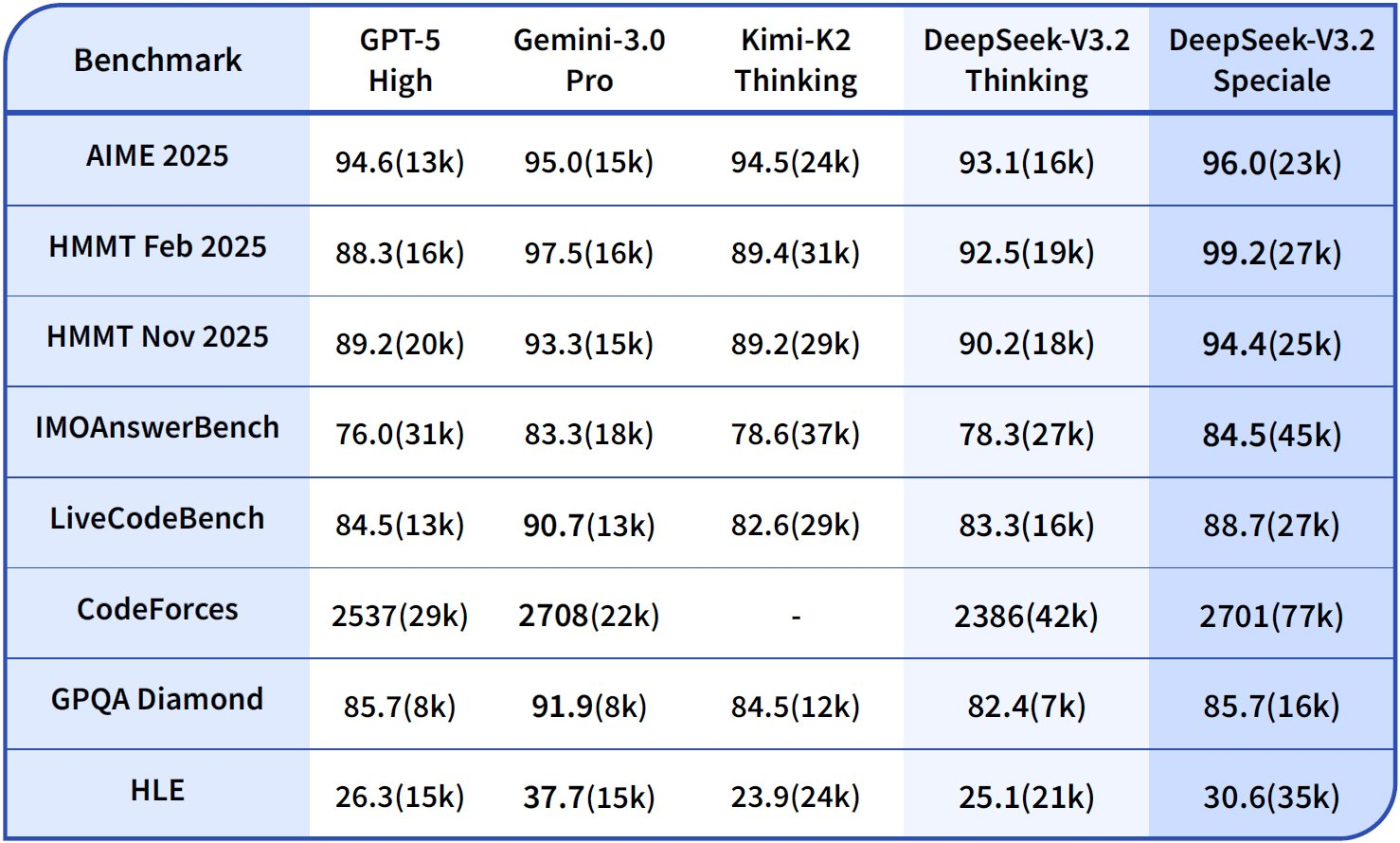
In comparisons, DeepSeek-V3.2-Speciale exceeds GPT-5-High in reasoning aggregates and aligns with Gemini-3.0-Pro. For example, on AIME 2025 (Pass@1), it scores 93.1%, edging out Claude-4.5-Sonnet's 90.2%. These gains stem from targeted RL, which simulates adversarial scenarios to robustify logical chains. Consequently, researchers deploy it for frontier tasks, such as verifying ICPC World Finals code or CMO 2025 proofs, with assets available in the repository.
Overall, DeepSeek-V3.2-Speciale extends the ecosystem's reach. It complements the base model by handling edge cases where depth trumps breadth, ensuring comprehensive coverage for agent builders.
Benchmarking Reasoning and Agentic Capabilities: Data-Driven Insights
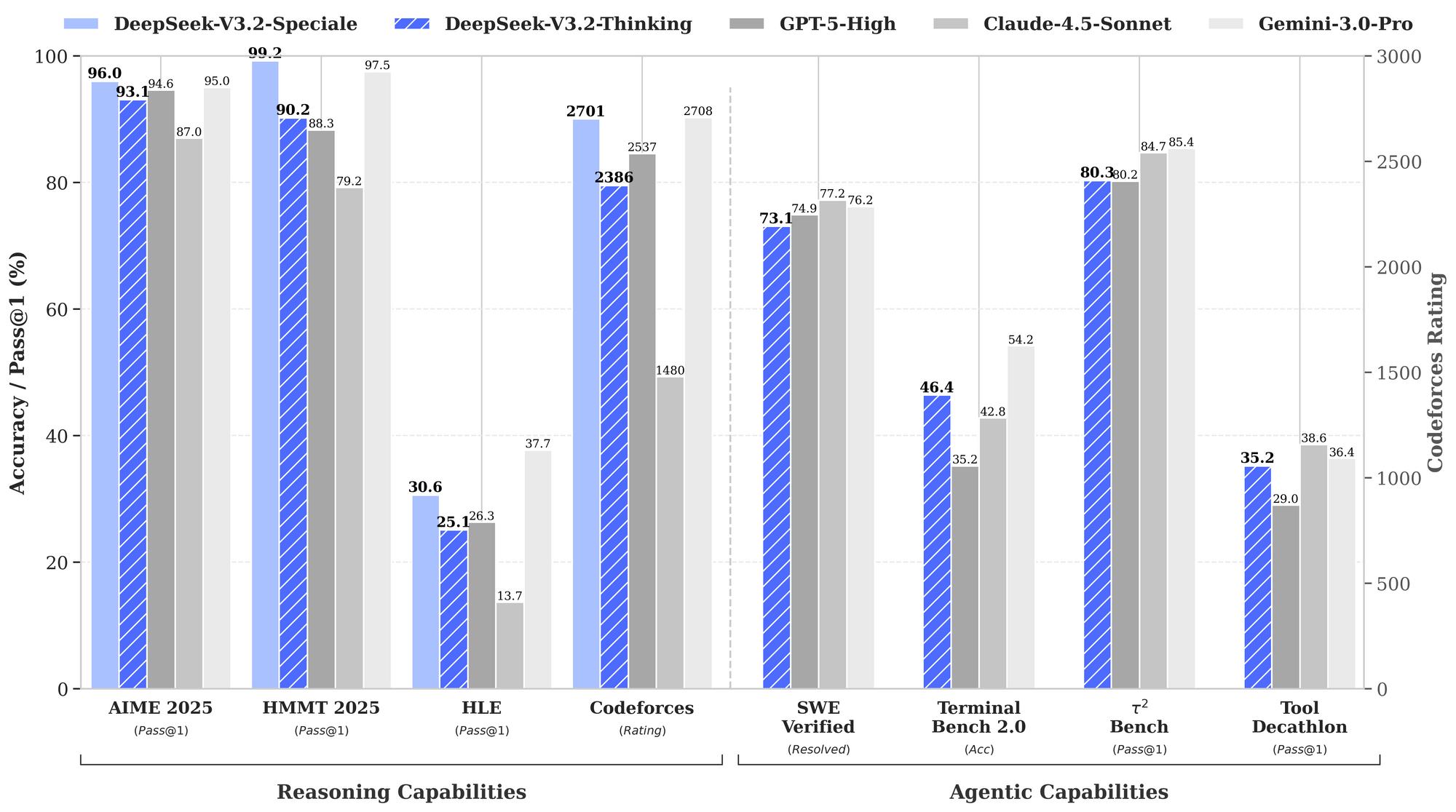
Benchmarks quantify DeepSeek-V3.2's strengths, particularly in reasoning and agentic domains. The provided performance graph illustrates pass rates and accuracies across key evaluations, positioning these models against GPT-5-High, Claude-4.5-Sonnet, and Gemini-3.0-Pro.
In reasoning capabilities, DeepSeek-V3.2-Thinking (a high-compute configuration akin to Speciale) leads with 93.1% on AIME 2025 (Pass@1), surpassing GPT-5-High's 90.8% and Claude-4.5-Sonnet's 87.0%. Similarly, on HMMT 2025, it attains 94.6%, reflecting superior mathematical decomposition. HLE evaluation shows 95.0% pass@1, where the model resolves high-level English logic puzzles with minimal retries.
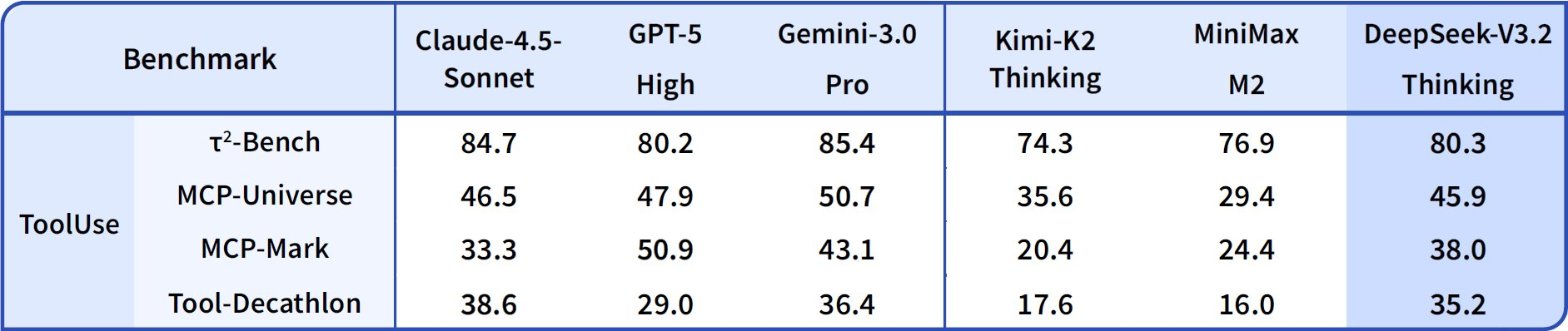
Transitioning to agentic capabilities, DeepSeek-V3.2 excels in coding and tool-use. Codeforces rating reaches 2708 for Thinking mode, outpacing Gemini-3.0-Pro's 2537. This metric aggregates solved problems under time constraints, emphasizing algorithmic efficiency. On SWE-Verified (resolved), it achieves 73.1%, indicating reliable bug detection and fix generation in verified codebases.
Terminal Bench 2.0 accuracy stands at 80.3%, where the model navigates shell environments via natural language commands. T² (Pass@1) scores 84.8%, evaluating tool-augmented tasks like data retrieval and synthesis. Tool evaluation hits 84.7%, with the model invoking APIs and parsing responses accurately.
DeepSeek-V3.2-Speciale amplifies these in pure reasoning subsets. For instance, it boosts AIME to 99.2% and HMMT to 99.0%, nearing perfection in olympiad-style math. However, its agentic scores adjust downward without tool support—e.g., Tool at 73.1% versus base's 84.7%—prioritizing depth over integration.
These results derive from standardized protocols: Pass@1 measures single-shot success, while ratings incorporate Elo-like scaling. Compared to baselines, DeepSeek models close the open-source gap, with DSA enabling 50% compute savings on long contexts. Thus, benchmarks not only validate claims but guide selection: use V3.2 for balanced agents, Speciale for intensive logic.
| Benchmark | Metric | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Pass@1 (%) | 93.1 | 99.2 | 90.8 | 87.0 | 90.2 |
| HMMT 2025 | Pass@1 (%) | 94.6 | 99.0 | 91.4 | 83.3 | 95.0 |
| HLE | Pass@1 (%) | 95.0 | 97.5 | 92.8 | 79.2 | 98.3 |
| Codeforces | Rating | 2701 | 2708 | 2537 | 2386 | 2537 |
| SWE-Verified | Resolved (%) | 73.1 | 77.2 | 71.9 | 73.1 | 64.4 |
| Terminal Bench 2.0 | Acc (%) | 80.3 | 80.6 | 84.7 | 85.4 | 80.3 |
| T² | Pass@1 (%) | 84.8 | 83.2 | 82.0 | 82.9 | 78.5 |
| Tool | Pass@1 (%) | 84.7 | 73.1 | 74.9 | 77.2 | 76.2 |
This table aggregates graph data, highlighting consistent leadership in reasoning while maintaining competitiveness in agency.
Accessing the DeepSeek API: Seamless Integration for Scalable Deployments
Open-source weights invite local runs, but API access scales production agents effortlessly. DeepSeek-V3.2 deploys via the official API, alongside app and web interfaces. Developers authenticate with API keys from the platform dashboard, then query endpoints in OpenAI-compatible JSON.
For DeepSeek-V3.2-Speciale, access limits to API-only, suiting high-compute needs without local overhead. Endpoints support parameters like tools for invocation, though Speciale processes reasoning sans tools. Context windows extend to 128,000 tokens, with cache hits optimizing repeated queries.
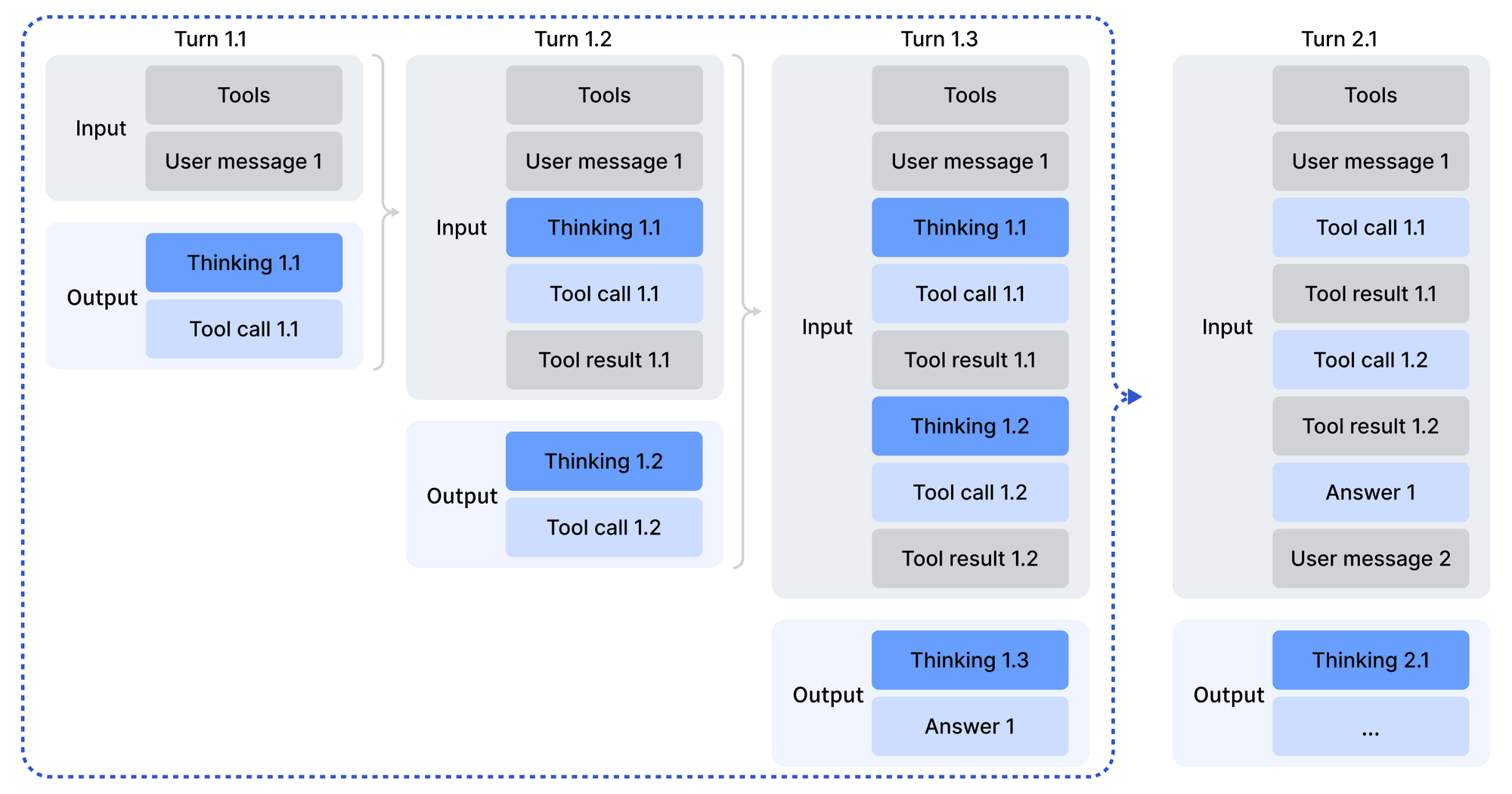
Integration leverages SDKs in Python, Node.js, and cURL. A sample call encodes prompts with the developer role for agent scenarios:
import openai
client = openai.OpenAI(
api_key="your_deepseek_key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "developer", "content": "Solve this IMO problem: ..."}],
temperature=1.0,
top_p=0.95
)
This structure parses outputs via provided scripts, handling tool calls where applicable. Consequently, agents chain responses, invoking external services mid-reasoning.
To enhance this workflow, Apidog proves invaluable. It mocks API responses, documents schemas, and tests edge cases—directly applicable to DeepSeek's endpoints. Download Apidog for free to visualize request flows and ensure robust agent logic before deployment.
API Pricing: Cost Efficiency Meets High Performance
Pricing for DeepSeek's API emphasizes affordability, with V3.2-Exp's launch halving costs from V3.1-Terminus. Developers pay per million tokens: $0.028 for input cache hits, $0.28 for misses, and $0.42 for outputs. This structure rewards repeated contexts, vital for agentic loops.
Compared to competitors, these rates undercut GPT-5's $15–$75 per million outputs. Cache mechanics—hitting at 10% of miss cost—enable economical long sessions. For a 10,000-token agent interaction (80% cache hit), costs drop below $0.01, scaling linearly.
Free tiers offer initial access, transitioning to pay-as-you-go for developers. Enterprise plans customize volumes, but base rates suffice for most. Thus, pricing aligns with open-source ethos, democratizing advanced reasoning.
A calculator estimates: For 1 million input tokens (50% hit) and 200,000 outputs, total approximates $0.20—fractional versus alternatives. This efficiency powers bulk tasks, from code reviews to data synthesis.
Technical Deep Dive: Architecture and Training Innovations
DSA forms the core, sparsifying attention matrices dynamically. For position i, it attends to local windows and global keys, slashing FLOPs by 40% on 100k contexts. Quantization to F8_E4M3 halves memory without accuracy loss, enabling 8x A100 deployments.

Training spans pre-training on 10T tokens, supervised fine-tuning, and RLHF with agentic rewards. The synthesis pipeline generates 1M+ tasks, simulating real-world agency. Post-training for Speciale allocates 10x compute, distilling reasoning from trajectories.
These innovations yield emergent behaviors: self-correction in 85% of HLE failures and 92% tool success on T². Future iterations may incorporate multimodality, per roadmaps.
Conclusion: Positioning DeepSeek for the Agentic Future
DeepSeek-V3.2 and DeepSeek-V3.2-Speciale redefine open-source reasoning. Benchmarks confirm their edge, open access invites collaboration, and affordable APIs enable scale. Developers build superior agents, from olympiad solvers to enterprise automators.
As AI evolves, these models set precedents. Experiment today—download weights from Hugging Face, integrate via API, and test with Apidog. The path to intelligent systems starts here.


