
Whether you’re using OpenAI Codex in your IDE, via a CLI, or through an API, a central question remains: How accurate is Codex in generating code? In this technical guide, we break down Codex’s performance across benchmarks, real-world tasks, refactoring, and collaborative workflows. We also provide guidance on when and how to use Codex effectively without over-relying on its outputs.
By the end, you’ll understand Codex’s strengths and limitations and know how it fits into real engineering workflows.
What Is Codex and Why Does Accuracy Matter?
OpenAI Codex is a specialized AI model trained to translate natural language into code and assist with software development tasks across languages like Python, JavaScript, TypeScript, and more. Its usage spans:
- Code generation from natural language
- Code completion, auto-generation, and scaffolding
- Refactoring and review tasks
- Pull request automation
- Generating tests and documentation
Accuracy in this context refers to functional correctness, style adherence, security awareness, and project-fit quality. Tools with high accuracy produce code that:
- Compiles and runs as expected
- Passes tests
- Matches project conventions
- Avoids common bugs and security flaws
Codex does impress in many domains, but it’s not perfect, and understanding where it excels — and where it falls short — is crucial.
Codex's Core Accuracy Metrics and Benchmarks
Analyzing how accurate Codex is requires understanding benchmarks.
HumanEval and Pass Rates
On benchmarks like HumanEval, which test functional correctness of AI-generated code for programming problems:
- OpenAI Codex variants often achieve around 70–90% accuracy on straightforward tasks.
This means for many basic and medium-complexity tasks — like sorting algorithms, basic API handlers, and small utilities — Codex writes code that works on the first attempt, or after a few self-corrections.
Think of accurate generation here as “pass@1” — the chance the very first output meets the specification.
SWE-Bench and Verified Tasks
More practical engineering benchmarks such as SWE-Bench Verified test error correction and real-world code changes:
- GPT-5-Codex variants have scored roughly 74% on verified tasks — large, integrated fixes or improvements to existing code.
This is lower than the ideal “perfect code generator” mark, but noteworthy because these benchmarks require deep context and reasoning about code across files and modules.
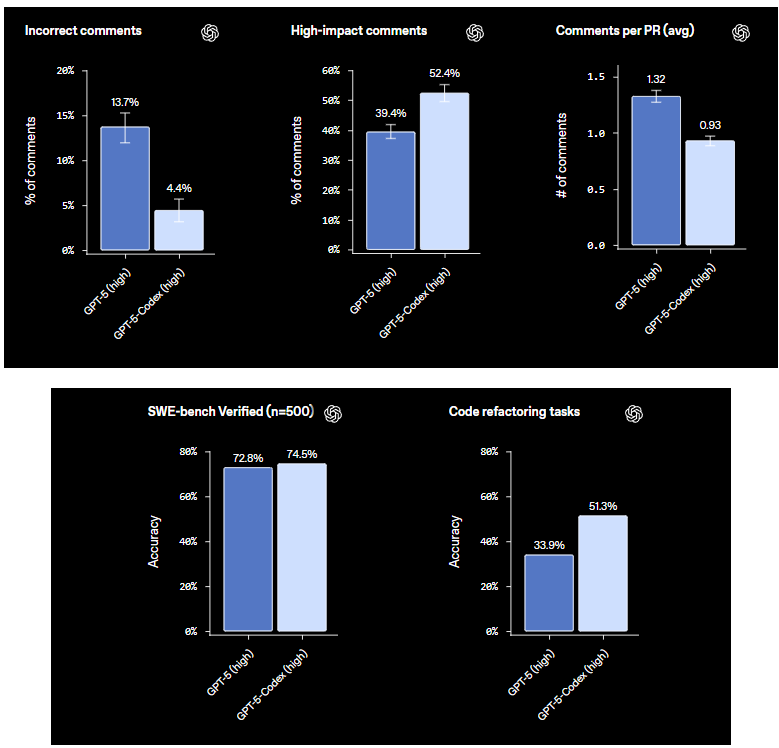
PR Review Accuracy
When used as a code reviewer:
- “Incorrect comments” can drop to ~4.4%
- “High-impact comments” — insightful, actionable suggestions — can reach ~50% or higher
This metric highlights something vital: Codex doesn’t just generate code — it can improve engineering workflows by aiding reviews with focused recommendations.
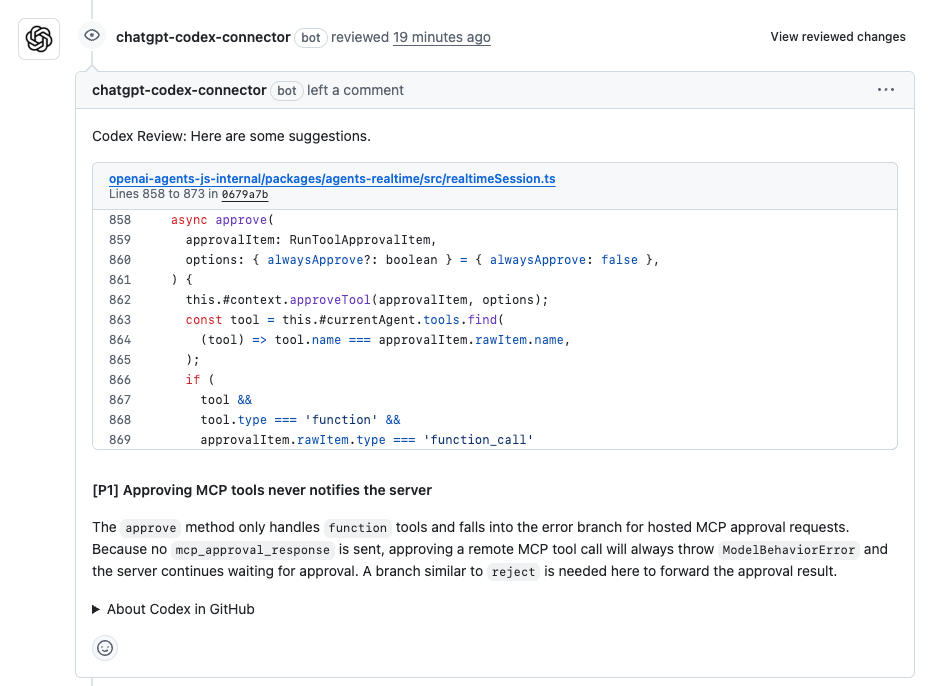
How Codex's Accuracy Varies by Task
Codex’s performance isn’t uniform across all tasks. The nature of the task influences how reliable its outputs are.
Simple Function Generation
For basic functions (e.g., FizzBuzz, sorting, small utilities):
- Codex often delivers correct code on the first pass
- Accuracy here is usually above 80%
These tasks are highly repetitive and well-represented in training data.
Complex Algorithms and Multi-File Tasks
When problems involve deeper logic or multiple modules:
- Accuracy drops compared to simple code
- It still provides high-quality starting points, but may require human refinement
From benchmarks and engineering reports, well-structured prompts and high-reasoning modes improve outcomes. (blog.dalyaitools.com)
Web Applications and End-to-End Systems
Generating code for full stacks — e.g., frontend component + backend API + database integration — shows:
- Good accuracy (~75-80%) in scaffolding and structure
- Less accuracy (~60-70%) on edge cases and business-specific logic
For example, generating a React component or express route with correct handlers and validations tends to work; ensuring every API edge case is covered may need human edits.
Games and Interactive Applications
On creative tasks like simple game code:
- Codex can reliably generate workable prototypes
- Accuracy for core logic is high, but complete production-ready code usually needs refinement
One test of Tic-Tac-Toe with AI opponent generated functioning code in most cases.
What Affects Codex’s Accuracy?
Understanding what influences accuracy helps you craft prompts and workflows for better results.
Prompt Quality and Specificity
Clear, precise prompts yield more accurate code. For example:
Generate an Express.js API route to create and validate a user with bcrypt hashing
This type of prompt gives structure, context, and constraints.
Context Window and Multi-File Awareness
Codex performs more accurately when:
- Long context windows are provided
- Related files are included or referenced
It struggles when crucial context (e.g., central schema definitions) is missing.
Iterative Refinement
Modern Codex versions can:
- Run tests on generated code
- Detect failures
- Iterate until passing
This boosts accuracy significantly compared to single-shot generation.
Codex Limitations: When Accuracy Drops
No AI generation tool is flawless. Common pitfalls include:
Novel or Niche Libraries
If the task involves bleeding-edge tech or rare libraries:
- Codex may hallucinate APIs
- It may output incorrect imports or functions
Human review is essential in these cases.
Security Weaknesses
Generated code can contain insecure patterns, especially if:
- You don’t specify security constraints
- The training data has insecure code examples
For example, without being prompted to enforce parameterized queries, AI might generate SQL concatenation – a known risk (read more about this at Grokipedia).
Business Logic Specificity
Tasks requiring deep domain knowledge or idiosyncratic logic often produce:
- Partial or incorrect implementations
- Logic that needs significant refinement
What are Some of The Best Practices to Improve Codex Accuracy?
To get the best outcomes from Codex:
- Write precise prompts: Include required libraries, constraints, and expectations.
- Supply context: Provide related files and interfaces when possible.
- Iterate and validate: Use test suites to verify output.
- Combine tools: Generate tests (see below), then refine code before commit.
- Review manually: Always enforce code standards and security checks.
Where Does Apidog Fit in Your Workflow?
When generating code for services and APIs, API correctness is just as important as code structure.
Apidog complements Codex by enabling developers to:
- Test API endpoints generated or scaffolded by Codex
- Generate structured API test cases automatically
- Perform API contract testing, ensuring your routes behave as expected
- Integrate API tests into CI/CD pipelines
This tight integration ensures the code your AI generates works correctly in deployed environments. You can get started with Apidog for free to validate API behavior as you refine Codex-generated code.

Frequently Asked Questions
Q1. Is Codex code always correct?
Not always — accuracy depends on task complexity and context. Simple tasks often work well, but complex logic benefits from review.
Q2. Can Codex generate secure code?
It can generate secure patterns if prompted explicitly, but you should always verify security manually.
Q3. Does Codex work in all languages?
Yes — it supports many languages, but performance can vary based on training data coverage.
Q4. How does Codex compare to newer AI tools?
Benchmarks differ: some tools outperform Codex in specific benchmarks, but Codex remains solid for many tasks.
Q5. Should I trust Codex for production code?
Use it as an assistant — not an oracle. Always review, test, and refine outputs before production.
Conclusion
OpenAI Codex demonstrates compelling accuracy for generating code across a range of tasks — from simple functions to reviews and scaffolded applications. Benchmarks show success rates typically from roughly 70–90% for common tasks, with more nuanced performance on complex or project-wide changes.
However, Codex isn’t perfect. It is best used as a developer co-pilot: it accelerates code creation, proposes improvements, and solves routine problems — all while still requiring human oversight.
For API-driven development, pairing Codex with Apidog ensures that not only is your code accurate, but your APIs behave predictably as they interact with the rest of your system. Try Apidog for free to round out your AI-assisted development workflow.


