
Anthropic advances artificial intelligence with the release of Claude Sonnet 4.5, a model that excels in coding, agent building, and complex reasoning tasks. Developers integrate this powerful tool through APIs, and platforms like Apidog simplify the process by providing robust testing and documentation features.
Anthropic positions Claude Sonnet 4.5 as the premier coding model globally, surpassing competitors in benchmarks for software engineering and agentic tasks. The company emphasizes its strengths in maintaining focus during extended operations, such as coding sessions lasting over 30 hours. Moreover, the model demonstrates substantial improvements in mathematical reasoning and computer usage, which developers leverage for real-world applications.
Transitioning to the core focus, Claude Sonnet 4.5 pricing maintains consistency with its predecessor, Claude Sonnet 4, to encourage widespread adoption. Anthropic sets API input at $3 per million tokens and output at $15 per million tokens for prompts up to 200,000 tokens. For larger prompts exceeding 200,000 tokens, rates adjust to $6 per million input tokens and $22.50 per million output tokens. This tiered approach accommodates varying project scales, allowing small teams to experiment without prohibitive costs while enabling enterprises to handle massive datasets.
Additionally, prompt caching enhances efficiency in Claude Sonnet 4.5 API usage. Developers cache prompts to reduce redundancy in repeated queries, with write costs at $3.75 per million tokens and read costs at $0.30 per million tokens for standard sizes. For extended caches beyond 200,000 tokens, these rates increase to $7.50 and $0.60, respectively. Such features prove invaluable for long-running agent tasks, where context management prevents token waste and lowers overall expenses.
Understanding Claude Sonnet 4.5 Features and Their Pricing Implications
Anthropic designs Claude Sonnet 4.5 to tackle frontier intelligence challenges, particularly in agentic coding and terminal interactions. The model achieves 77.2% on the SWE-bench Verified evaluation without parallel test-time compute, rising to 82.0% with it. This performance outpaces GPT-5 at 72.8% and earlier Claude variants. Developers benefit from these capabilities in building autonomous agents that execute multi-step processes, but pricing plays a crucial role in feasibility.
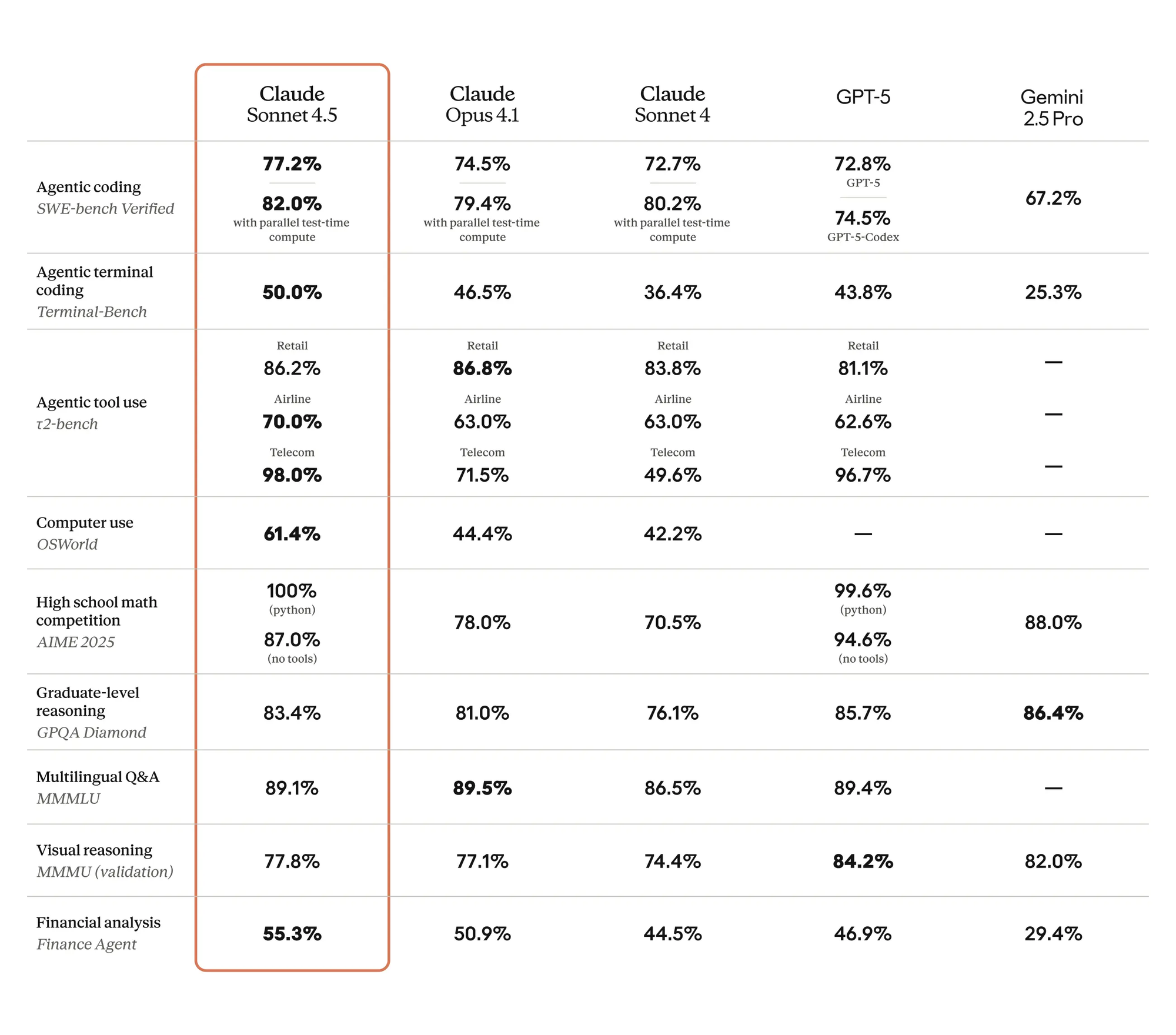
For instance, the model's agentic terminal coding score reaches 50.0%, a notable jump from Claude Sonnet 4's 36.4%. In practical terms, this means fewer iterations and lower token consumption during development, directly impacting costs. However, teams must monitor usage to stay within budgets, especially when integrating with tools like Apidog for API mocking and automated testing.
Furthermore, Claude Sonnet 4.5 excels in retail agent benchmarks at 86.2%, airline tasks at 70.0%, and telecommunications at 98.0%. These domain-specific strengths allow businesses to deploy AI for customer service or operational automation without escalating expenses. The pricing model supports this by keeping base rates affordable, encouraging experimentation across industries.
Shifting focus to computer use, the model scores 61.4% on OSWorld, up from 42.2% in Sonnet 4. This improvement enables seamless interactions with operating systems, files, and applications. Developers incorporate these features via the Claude API, where prompt caching minimizes costs for repetitive tasks like data analysis or file generation.
Benchmark Breakdown: How Claude Sonnet 4.5 Stacks Up
Anthropic provides comprehensive benchmarks to showcase Claude Sonnet 4.5's superiority. The following table illustrates key performance metrics against competitors:
This data highlights Claude Sonnet 4.5's leadership in coding and reasoning. Pricing remains unchanged from Sonnet 4, ensuring that these gains do not inflate costs for users. Consequently, developers achieve higher efficiency without additional financial burden.
In coding scenarios, the model's ability to handle complex agents reduces debugging time. For example, on agentic tasks, it outperforms Gemini 2.5 Pro by over double in terminal coding. This efficiency translates to fewer API calls, optimizing expenses under the $3/$15 token structure.
In mathematical benchmarks like AIME 2025, Claude Sonnet 4.5 reaches perfect scores with Python assistance. Educational institutions and researchers utilize this for advanced computations, where pricing scalability supports large-scale simulations.
API Pricing Deep Dive for Claude Sonnet 4.5
Anthropic structures Claude Sonnet 4.5 API pricing to balance performance and affordability. Base rates apply to standard usage: $3 per million input tokens and $15 per million output tokens. This model supports a 200,000-token context window, ideal for detailed prompts without fragmentation.
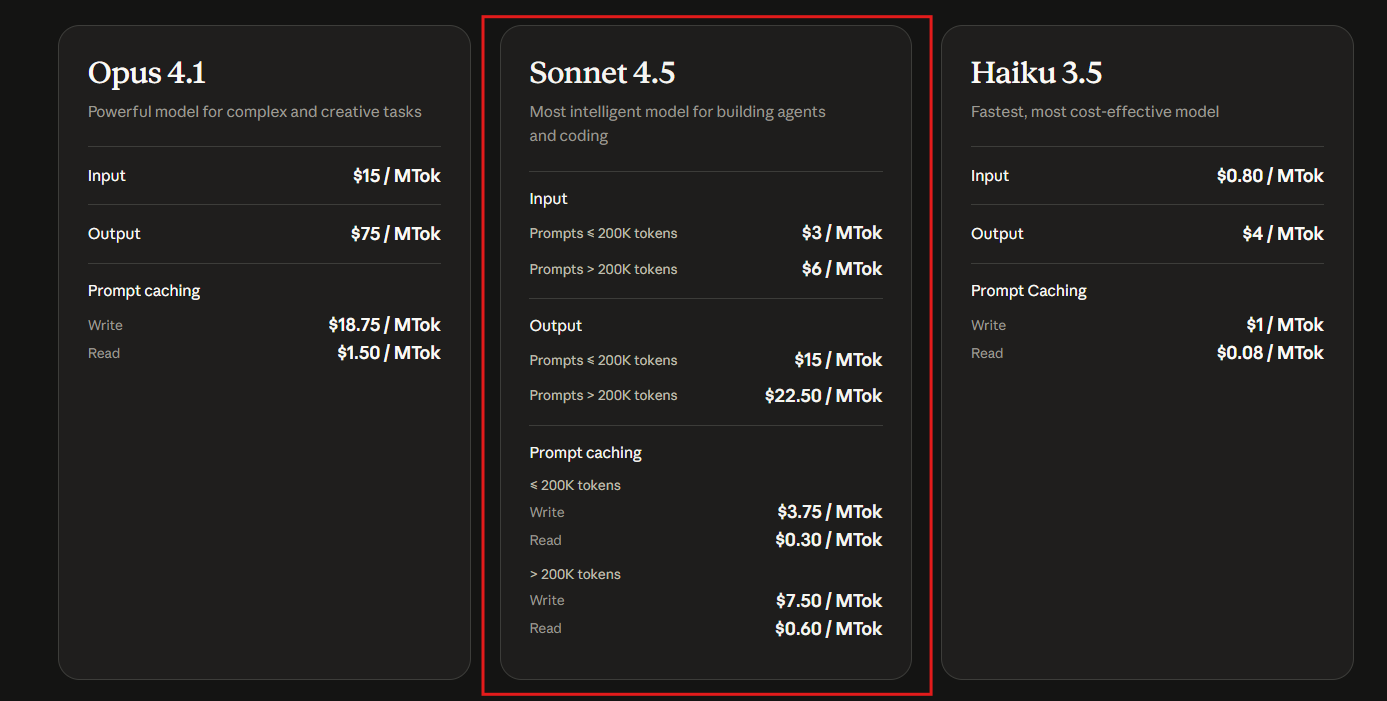
For extended contexts over 200,000 tokens, rates increase to $6 input and $22.50 output per million tokens. Developers manage this by optimizing prompts, perhaps using Apidog to simulate and refine API interactions before live deployment.
Prompt caching further refines costs. With a five-minute time-to-live, write operations cost $3.75 per million tokens, while reads are $0.30. Extended caching options, detailed in Anthropic's documentation, allow for hour-long durations, beneficial for persistent agent sessions.
Comparing to other models, Claude Sonnet 4.5 offers better value than Opus 4.1, which charges $15 input and $75 output. Haiku 3.5, at $0.80 input and $4 output, suits lighter tasks but lacks Sonnet 4.5's advanced reasoning.
In practice, a developer using Claude Sonnet 4.5 for code generation might incur costs based on prompt complexity. A 10,000-token input and 5,000-token output session costs $0.03 + $0.075 = $0.105. Scaling to thousands of queries, caching saves significantly.
Furthermore, integration platforms like Apidog enhance API management. Apidog supports mocking, testing, and documentation for Claude Sonnet 4.5 endpoints, ensuring compliance with rate limits. By downloading Apidog for free, teams debug integrations locally, avoiding unnecessary API calls and associated fees.
Consumer Pricing Plans and Access to Claude Sonnet 4.5
Anthropic offers various consumer plans for Claude Sonnet 4.5, though specific tiers lack model-exclusive pricing. Free users access basic features with usage limits, while Pro and Max plans unlock higher quotas and advanced tools like the VS Code extension.
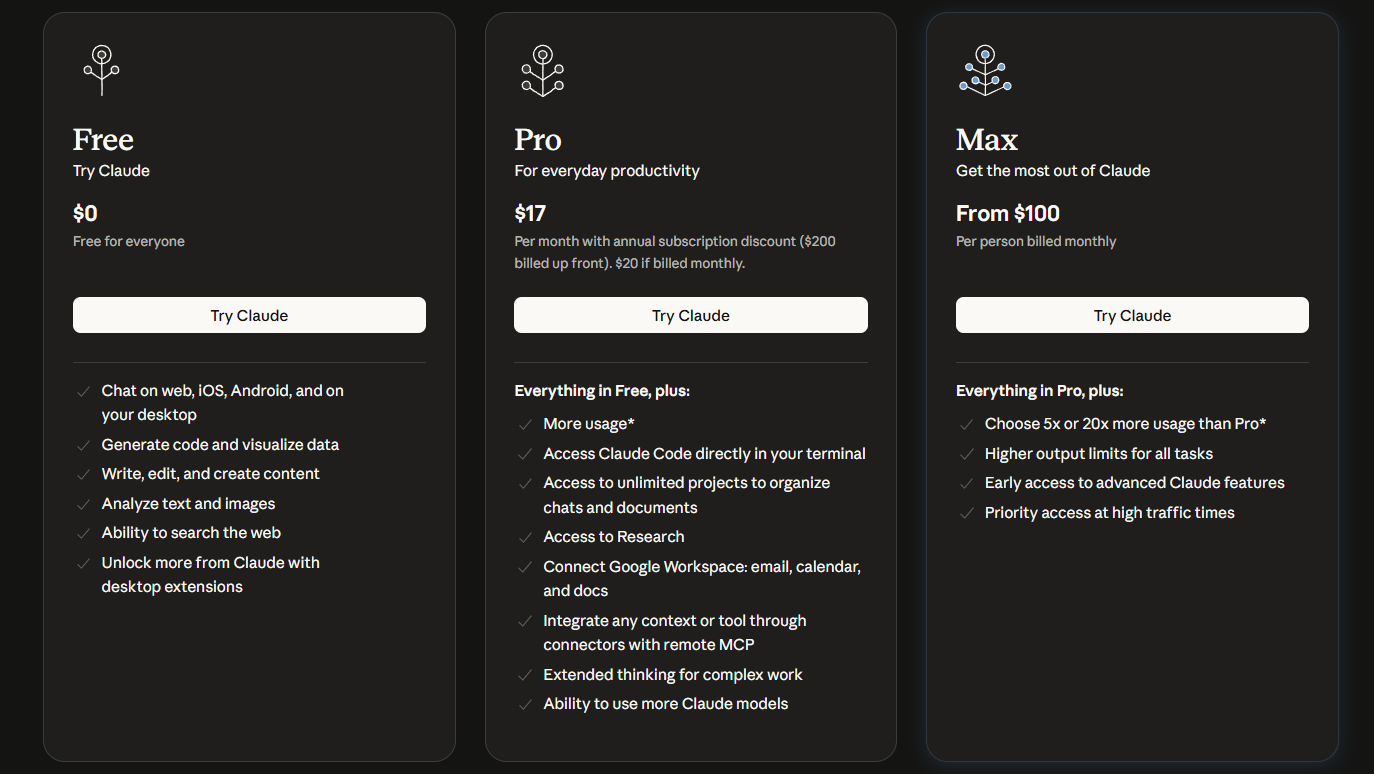
Team and Enterprise plans cater to collaborative environments, with customizable limits and priority support. Education plans provide discounted access for academic use, leveraging Sonnet 4.5's math prowess.
Users on paid plans gain previews like "Imagine with Claude," a research tool for dynamic software generation. Available temporarily to Max users, it demonstrates pricing's role in gating experimental features.
Integrating Claude Sonnet 4.5 with Apidog for Optimal Efficiency
Developers maximize Claude Sonnet 4.5's potential through seamless API integrations, where Apidog plays a pivotal role. Apidog facilitates design, debugging, and testing of API endpoints, ensuring compatibility with Sonnet 4.5's 200K context window.
For example, Apidog's mocking feature simulates responses, allowing cost-free validation before incurring token charges. Automated testing suites detect issues early, preventing expensive iterations.

Moreover, Apidog's documentation tools generate specs for Claude Sonnet 4.5 integrations, aiding team collaboration. By downloading Apidog for free, developers align their workflows with the model's pricing, focusing on innovation rather than overhead.
In agent development, Apidog handles memory tool integrations, testing context persistence without live API hits. This approach minimizes costs, especially for benchmarks like telecommunications agents at 98.0% efficiency.
Conclusion
In conclusion, Claude Sonnet 4.5 pricing democratizes advanced AI, supported by robust features and integrations like Apidog. Developers harness its power economically, driving forward technological progress.


