
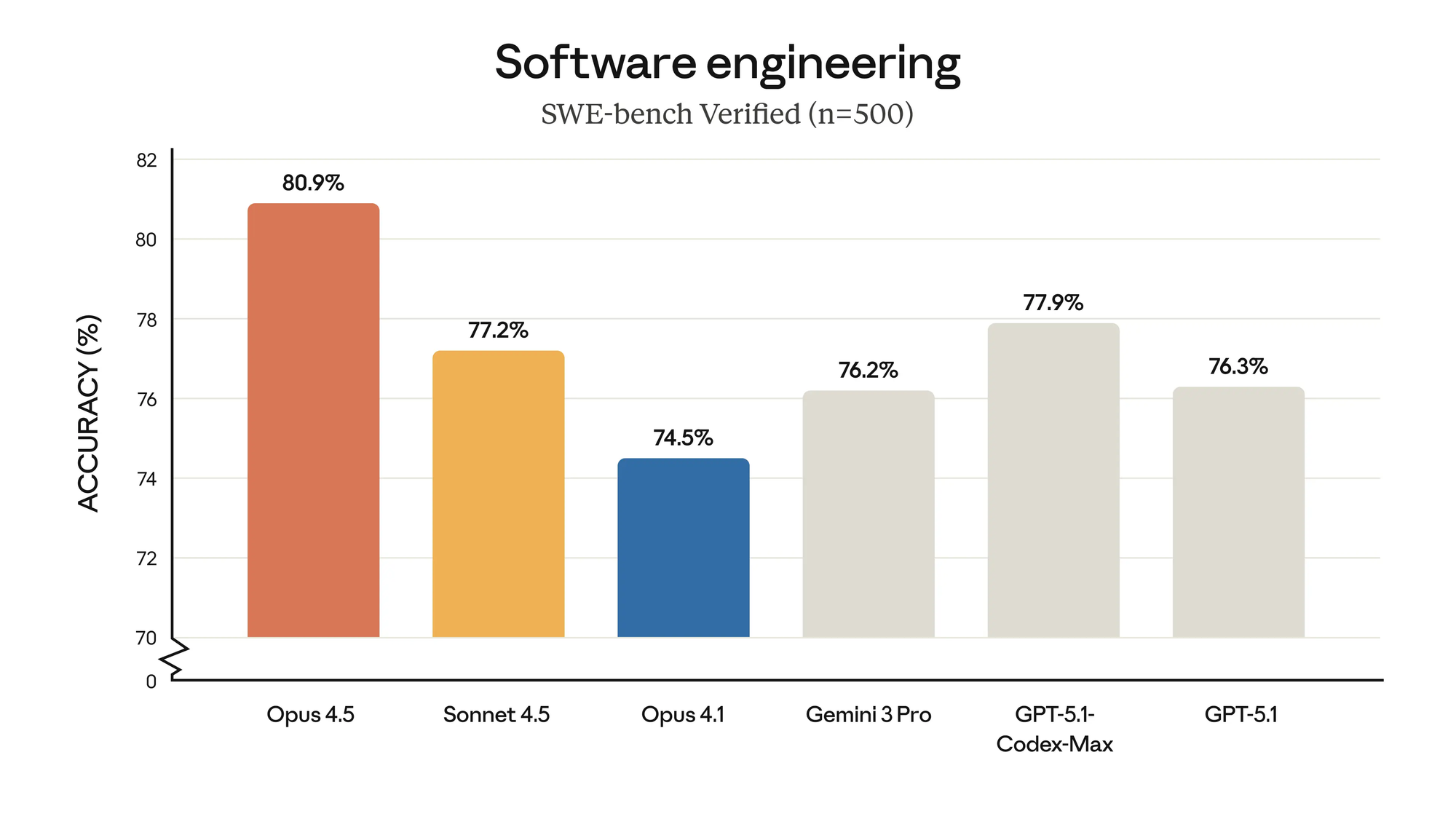
Anthropic engineers push boundaries with Claude Opus 4.5, a frontier model that redefines coding, agentic workflows, and enterprise productivity. This iteration slashes costs dramatically while boosting performance metrics across benchmarks like SWE-bench Verified, where it achieves 80.9%—outpacing Google's Gemini 3 Pro at 76.2% and OpenAI's GPT-5.1-Codex-Max at 77.9%. Developers now access state-of-the-art reasoning at a fraction of previous Opus expenses, enabling broader adoption in production environments.
However, effective integration demands precise cost management. Token-based pricing structures require careful calculation to avoid budget overruns, especially in high-volume API calls. For instance, a single complex query involving 100,000 input tokens and 50,000 output tokens incurs specific charges that scale with usage. Moreover, tools that streamline API testing and documentation prove essential for validating these implementations without inflating expenses.
Claude Opus 4.5: Model Overview and Architectural Advancements
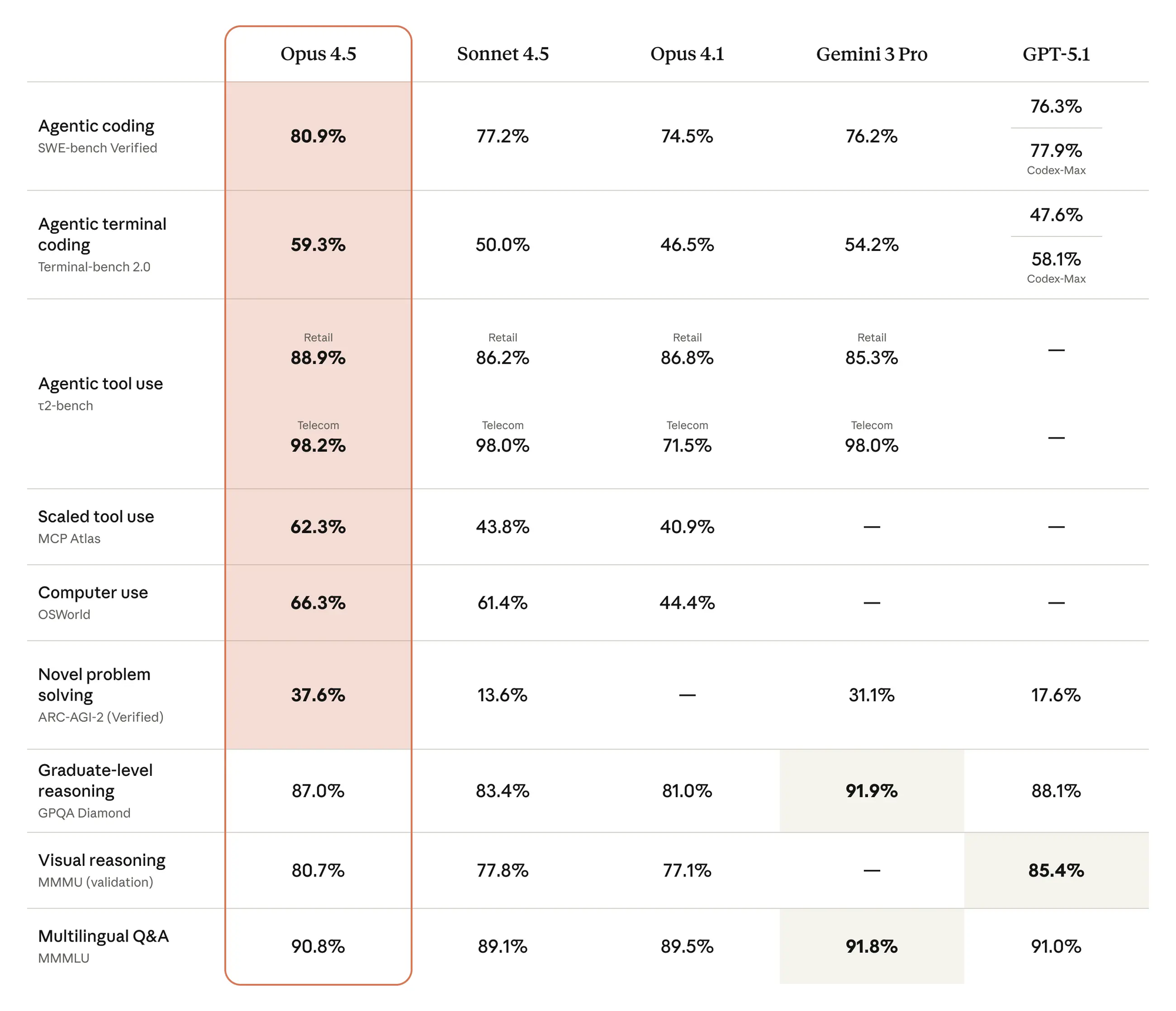
Anthropic positions Claude Opus 4.5 as the pinnacle of its 4.5 generation, succeeding Haiku 4.5 (October 2025) and Sonnet 4.5 (September 2025). Engineers designed this model for precision in ambiguous scenarios, where it reasons through tradeoffs and resolves multi-system bugs with human-like intuition. For example, on the τ-Bench agentic evaluation, Opus 4.5 creatively upgrades a cabin booking by modifying flight segments— a task that eludes rigid models.
From a technical standpoint, Opus 4.5 incorporates hybrid reasoning, blending standard responses with extended "thinking blocks" preserved across turns. This reduces token waste; the model consumes 76% fewer output tokens than Sonnet 4.5 on medium-effort SWE-bench tasks while matching or exceeding scores. Vision capabilities improve, enabling accurate analysis of spreadsheets and slides, while mathematics benchmarks show gains in multi-step proofs.
Availability spans Claude apps, the API (identifier: claude-opus-4-5-20251101), and cloud platforms like Amazon Bedrock, Google Vertex AI, and Microsoft Azure. Developers integrate it via RESTful endpoints, with context windows up to 200,000 tokens standard. However, these enhancements come at optimized costs, which we detail below. Consequently, teams shift from legacy models, balancing performance against Claude Opus 4.5 Pricing.
API Pricing Structure: Token-Based Costs for Claude Opus 4.5
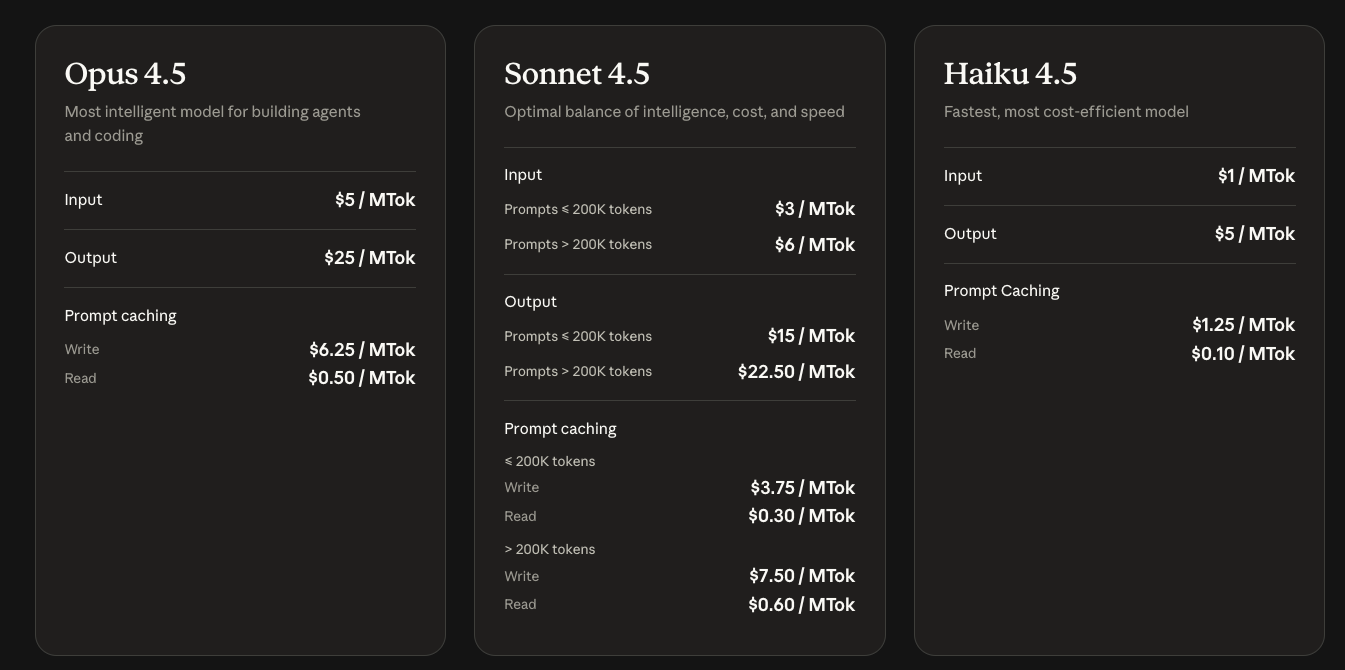
Anthropic bills API usage per million tokens, distinguishing input (prompts, context) from output (generated responses). For Claude Opus 4.5, rates stand at $5 per million input tokens and $25 per million output tokens—a 67% reduction from Opus 4's $15/$75 structure. This adjustment addresses enterprise feedback on prohibitive expenses, making frontier intelligence viable for routine tasks.
To illustrate, consider a developer querying Opus 4.5 for code refactoring. A 50,000-token prompt (input) and 20,000-token response (output) costs $0.25 (input) + $0.50 (output) = $0.75 total. Scale to 1,000 daily queries: expenses hit $750 monthly, excluding taxes or add-ons. Engineers mitigate this through prompt engineering—compacting contexts via summarization drops input by 30-50%.
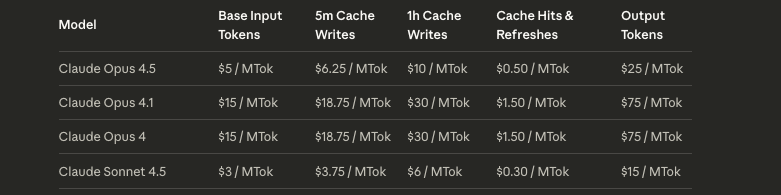
Prompt caching further optimizes Claude Opus 4.5 Pricing. Writes cost $6.25 per million tokens, reads $0.50 per million, with a 5-minute TTL (extendable). In agentic loops, cache repeated system prompts; a 10,000-token cache reused 100 times saves $0.60 per read versus full inputs. Batch processing offers 50% discounts on bulk jobs, ideal for data pipelines.
Usage limits apply: Free tiers cap at basic access, while API keys enforce rate limits (e.g., 50 requests per minute for Opus). Exceeding triggers throttling; monitor via the Anthropic console. Therefore, integrate monitoring hooks in your codebase to track token consumption dynamically.
| Component | Input Cost ($/MTok) | Output Cost ($/MTok) | Notes |
|---|---|---|---|
| Standard Usage | 5 | 25 | Base rate; scales linearly |
| Prompt Caching (Write) | 6.25 | N/A | One-time cost for persistent prompts |
| Prompt Caching (Read) | 0.50 | N/A | Per reuse; 5-min default TTL |
| Batch Processing | 2.50 (50% off) | 12.50 (50% off) | For asynchronous jobs >100 requests |
This table highlights core levers for cost control. As a result, developers forecast budgets accurately.
Subscription Plans: Accessing Claude Opus 4.5 Beyond Pure API
While API suits custom builds, Claude's subscription tiers bundle Opus 4.5 access with UI tools, removing per-token worries for interactive use. The Free plan ($0) limits to basic chats and Haiku/Sonnet models, excluding Opus. Pro ($20/month or $17/month annual) unlocks Opus 4.5, Claude Code, file execution, and unlimited projects—ideal for solo developers testing integrations.
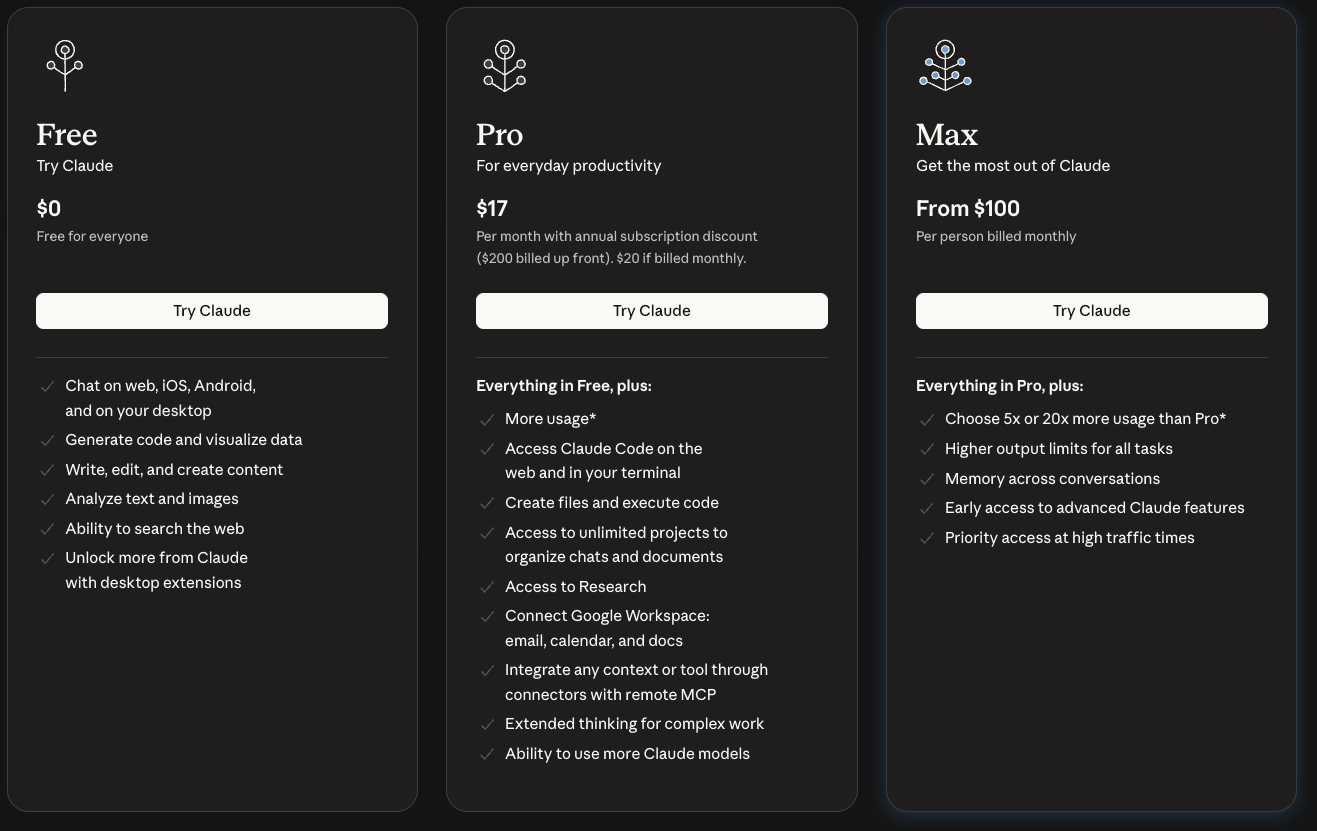
Max starts at $100/person/month, delivering 5x-20x Pro usage, conversation memory, and priority features like extended thinking. Team plans scale: Standard ($30/month/seat, min. 5) for collaboration; Premium ($150/month/seat) adds SSO, audit logs, and Opus caps removal. Enterprise customizes further with SCIM and compliance APIs.
Education discounts apply for universities, including API credits. Add-ons like Web Search ($10/1,000 searches) or Code Execution ($0.05/hour beyond 50 free hours) layer atop. Thus, subscriptions complement API for hybrid workflows, where UI prototyping informs backend scaling.
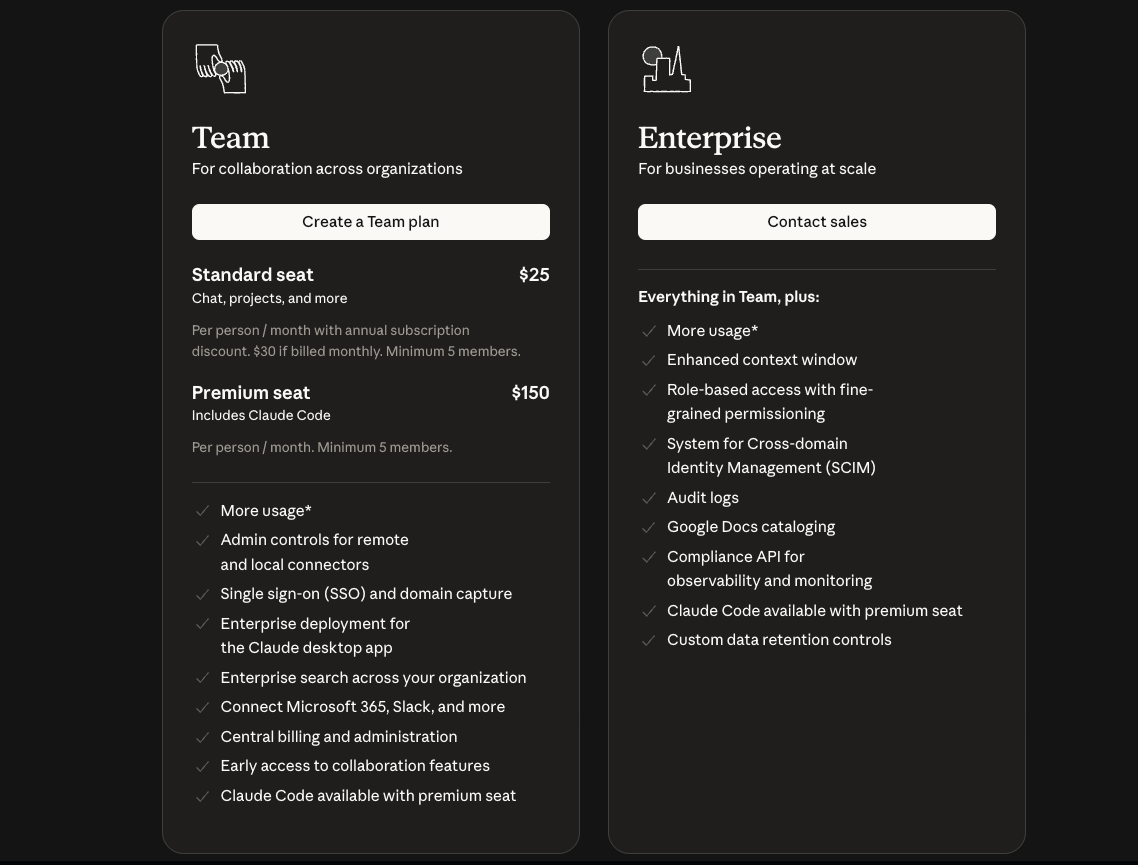
For API-heavy teams, blend plans: Use Pro for ideation, API for production. This hybrid minimizes Claude Opus 4.5 Pricing exposure.
Comparing Claude Opus 4.5 Pricing to Legacy Models and Competitors
Legacy Opus variants underscore the value shift. Opus 4.1 charged $15 input/$75 output per million tokens—five times Opus 4.5's input rate. Sonnet 4.5, at $3/$15 (≤200K tokens), serves mid-tier needs but lags in complex reasoning; Haiku 4.5 ($1/$5) prioritizes speed over depth.
Against competitors, Opus 4.5 undercuts premiums. OpenAI's GPT-5.1-Codex-Max estimates $10/$40, while Gemini 3 Pro hits $8/$32—yet Opus leads in coding efficiency, using fewer tokens overall. For a 1-million-token coding session, Opus costs $30 total versus $50+ for rivals, factoring 20% token savings.
| Model | Input ($/MTok) | Output ($/MTok) | SWE-bench Score | Token Efficiency Gain |
|---|---|---|---|---|
| Claude Opus 4.5 | 5 | 25 | 80.9% | Baseline |
| Claude Sonnet 4.5 | 3 | 15 | 72.5% | -20% (more tokens needed) |
| Opus 4.1 (Legacy) | 15 | 75 | 74.5% | -48% (higher consumption) |
| GPT-5.1-Codex-Max | ~10 | ~40 | 77.9% | +15% (less efficient) |
| Gemini 3 Pro | ~8 | ~32 | 76.2% | +10% (comparable) |
Benchmarks derive from verified sources; efficiency reflects relative output tokens for equivalent tasks. Accordingly, Opus 4.5 delivers superior ROI for compute-intensive applications.
Optimizing Costs: Technical Strategies for Claude Opus 4.5 Deployments
Developers implement safeguards to harness Opus 4.5 without fiscal surprises. First, tokenize prompts upfront: Libraries like tiktoken estimate costs pre-call. For instance, Python code snippets:
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base") # Approx for Claude
tokens = len(encoding.encode("Your prompt here"))
input_cost = (tokens / 1_000_000) * 5
This script flags overages early. Second, leverage context compaction: Opus 4.5's built-in tools summarize prior exchanges, trimming 40% off subsequent inputs.
Third, adopt Apidog for simulation. This platform mocks Claude endpoints, allowing unlimited tests sans real tokens. Design schemas, run assertions, and export cURL—directly tying to Claude Opus 4.5 Pricing validation. Free tier supports 100+ collections, scaling to enterprise.
Batch endpoints process asynchronously, halving rates for non-urgent jobs like data annotation. Monitor via Prometheus integrations, alerting at 80% budget thresholds. Finally, hybrid model routing—default to Sonnet 4.5, escalate to Opus—cuts averages by 60%.
These tactics ensure scalability. In turn, they transform potential pitfalls into efficiencies.
Real-World Applications: Calculating Claude Opus 4.5 Pricing in Production
Consider a fintech firm automating compliance reports. Daily, Opus 4.5 ingests 500,000 tokens of regulatory docs (input) and generates 200,000-token summaries (output). Monthly cost: (15M input tokens * $0.005) + (6M output * $0.025) = $75 + $150 = $225. Cache boilerplate prompts: Reuse saves $18/month.
In software engineering, a dev team debugs via 100 SWE-bench-style queries/week. At 10K input/5K output each, weekly: $2.50 input + $6.25 output = $8.75. Annualize to $455, offset by 20% productivity gains—Opus resolves bugs 2x faster than humans on internal exams.
For research agents, long-horizon tasks like market analysis chain 50 turns. Without compaction, 1M total tokens cost $30; with, $18. Apidog prototypes these chains, verifying flows pre-deployment.
Enterprise dashboards visualize: Input histograms reveal spikes, prompting optimizations. Thus, teams quantify value beyond raw Claude Opus 4.5 Pricing.
Future Implications: Evolving Economics of Frontier AI
Anthropic's repricing signals industry trends: Accessibility drives adoption, with Opus 4.5 revenue projected to double Q1 2025 figures. Expect further drops as compute efficiencies rise—Opus 4.5's token thriftiness sets precedents.
Regulations may cap per-user spends, emphasizing transparent billing. Developers prepare by auditing integrations now. In summary, Claude Opus 4.5 Pricing empowers innovation without barriers.


