
Developers constantly seek tools that boost efficiency without compromising precision. Cursor's integration of OpenAI's GPT-5.1 Codex models stands out as a prime example, offering a suite of specialized variants tailored for agentic workflows. These models transform how you handle code generation, debugging, and refactoring right within your IDE.
Understanding Cursor Codex: The Foundation of GPT-5.1 Integration
Cursor Codex refers to OpenAI's advanced family of models fine-tuned for coding tasks and seamlessly harnessed within the Cursor IDE. Developers activate these models through a dedicated selector, enabling AI agents to read files, execute shell commands, and apply edits autonomously. This setup relies on a custom harness that aligns prompts and tools with the models' training, ensuring reliable performance in complex repositories.
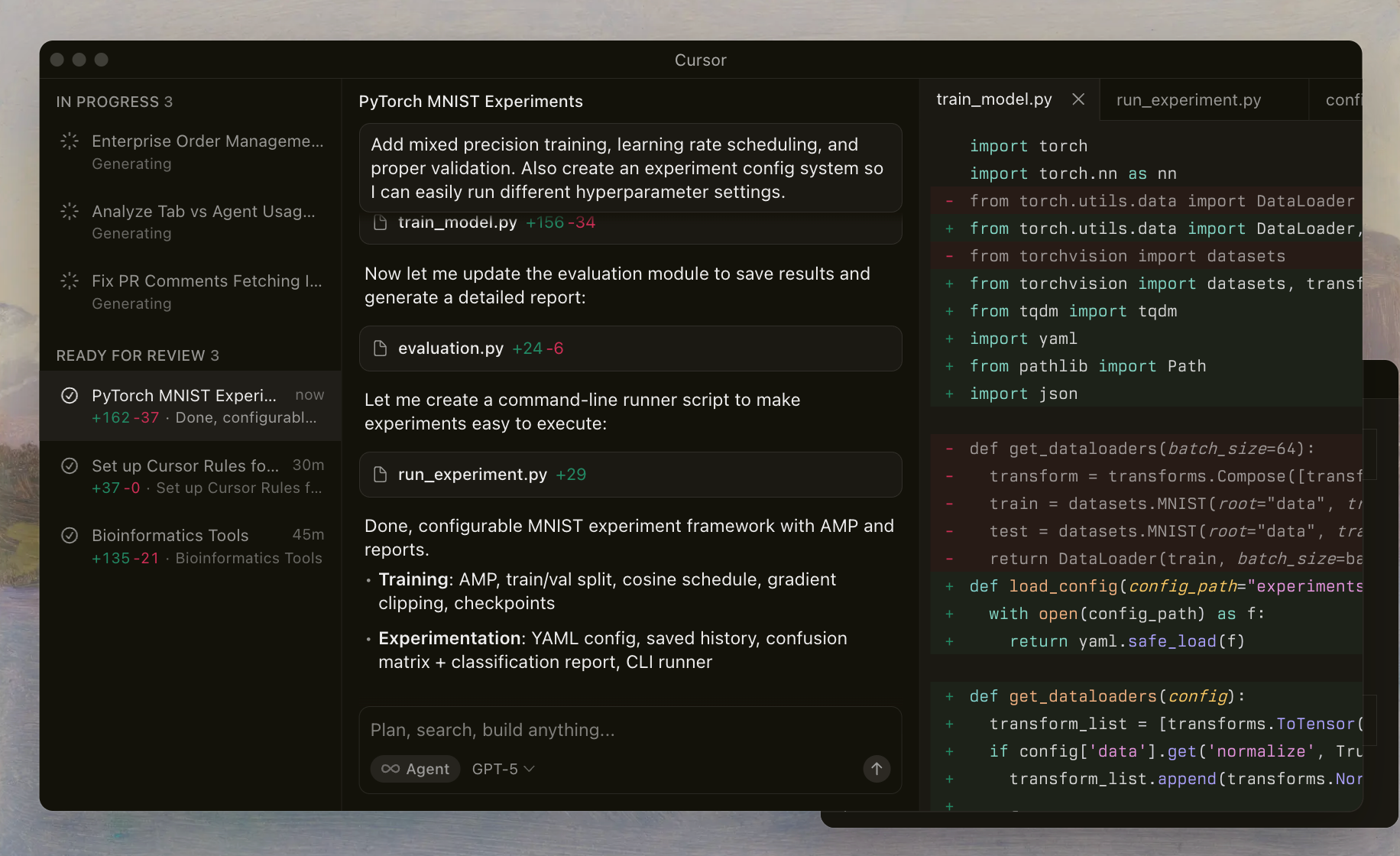
The GPT-5.1 series builds on previous iterations by emphasizing agentic capabilities—meaning the models act like intelligent assistants that plan, iterate, and self-correct. Unlike general-purpose LLMs, Cursor Codex prioritizes shell-oriented workflows. For example, the models learn to invoke tools for file inspection or linting, reducing hallucinations and improving edit accuracy.
Cursor's implementation includes safeguards like reasoning traces, which preserve the model's thought process across interactions. This continuity prevents the common pitfall of context loss in multi-turn sessions. As you experiment with these models, you will notice how they handle edge cases, such as resolving merge conflicts or optimizing asynchronous code.
Transitioning to specifics, OpenAI released the GPT-5.1 Codex lineup in late 2025, coinciding with Cursor's updated agent framework. This timing allows developers to leverage frontier-level intelligence for everyday tasks, from prototyping microservices to auditing legacy systems.
Introducing the GPT-5.1 Codex Model Family
Cursor provides an extensive lineup of GPT-5.1 Codex variants, each optimized for distinct trade-offs in intelligence, speed, and resource use. You access them via the model selector in the IDE, where toggles indicate availability and current selection. Below, we introduce each one, highlighting core attributes derived from Cursor's harness documentation and internal benchmarks.
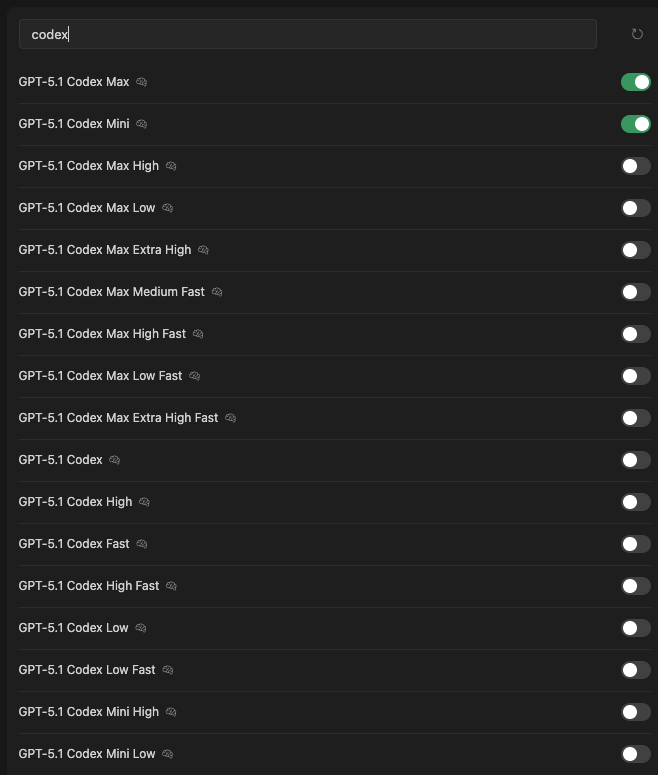
GPT-5.1 Codex Max: The Flagship for Demanding Tasks
GPT-5.1 Codex Max serves as the cornerstone of the family. Engineers at OpenAI trained this model on vast datasets of agentic coding sessions, incorporating Cursor-specific tools like shell execution and lint readers. It excels in maintaining long-context reasoning, processing up to 512K tokens without degradation.
Key features include adaptive tool calling: the model dynamically selects between direct edits and Python-based fallbacks for complex modifications. For instance, when refactoring a Node.js application, Codex Max generates a plan, invokes git diff for validation, and applies changes atomically.
Benchmarks reveal its prowess. On Cursor's internal eval suite—which measures success rates in real repositories—Codex Max achieves 78% resolution for multi-file tasks, surpassing GPT-4.5 equivalents by 15%. However, it demands higher compute, with inference times averaging 2-3 seconds per turn on standard hardware.
Developers favor this model for enterprise-scale projects, where precision outweighs velocity. If your workflow involves integrating APIs, pair it with Apidog to validate generated schemas automatically.
GPT-5.1 Codex Mini: Compact Power for Quick Iterations
Next, GPT-5.1 Codex Mini shrinks the parameter count while retaining 85% of Max's coding fidelity. This variant targets lightweight environments, such as mobile app development or CI/CD pipelines. It processes 128K tokens and prioritizes low-latency responses, clocking in at under 1 second for most queries.
The model employs distilled knowledge from Max, focusing on common patterns like regex-based refactoring or unit test generation. A standout capability is its inline reasoning summaries—concise one-liners that update users without verbose logs. This reduces cognitive load during rapid prototyping.
In performance tests, Codex Mini scores 62% on SWE-bench lite, a subset of software engineering tasks. It shines in solo-file edits, where speed enables fluid iteration. For teams building RESTful services, this model integrates effortlessly with Apidog's mocking tools, allowing instant endpoint simulations.
GPT-5.1 Codex Max High: Balanced Intelligence with Elevated Precision
GPT-5.1 Codex Max High refines the Max baseline by amplifying accuracy in high-stakes scenarios. OpenAI tuned it for domains like security auditing and performance optimization, where false positives cost time. It handles 256K contexts and incorporates specialized prompts for vulnerability detection.
Features such as extended chain-of-thought traces enable deeper analysis. The model emits step-by-step rationales before tool calls, ensuring transparency. For example, when securing an Express.js route, it scans dependencies, suggests patches, and verifies via simulated lints.
Metrics show a 72% success rate on Cursor Bench's security module, edging out standard Max by 5%. Response times hover at 1.5-2.5 seconds, making it suitable for mid-sized repos. Developers using this for API-heavy apps will appreciate its synergy with Apidog, which can import Codex-generated OpenAPI specs for collaborative reviews.
GPT-5.1 Codex Max Low: Resource-Efficient Precision
GPT-5.1 Codex Max Low dials back computational demands without sacrificing core intelligence. Ideal for laptops or shared clusters, it caps at 128K tokens and optimizes for batch processing. The model favors conservative edits, minimizing overhauls in favor of targeted fixes.
It includes a low-overhead toolset, relying on shell basics like grep and sed over heavy Python scripts. This approach yields 68% efficacy on edit-heavy benchmarks, with inference under 2 seconds. Use cases span legacy code migration, where stability trumps novelty.
For API developers, this variant pairs well with Apidog's free tier, enabling lightweight testing of low-resource endpoints without taxing your machine.
GPT-5.1 Codex Max Extra High: Ultra-Fine Accuracy for Experts
GPT-5.1 Codex Max Extra High pushes boundaries with enhanced probabilistic modeling. Trained on edge-case datasets, it achieves near-human intuition for ambiguous tasks, like inferring intent from partial specs. Context window expands to 384K, supporting monorepo navigation.
Advanced features encompass multi-hypothesis planning: the model generates and ranks edit variants before committing. On complex refactors, it resolves 82% of conflicts autonomously.
Benchmarks highlight its edge—85% on advanced Cursor evals—but at 3-4 second latencies. Reserve this for research-grade coding, such as algorithm design. Integrate Apidog to prototype extra-high-fidelity API contracts derived from its outputs.
GPT-5.1 Codex Max Medium Fast: Speed Meets Competence
GPT-5.1 Codex Max Medium Fast strikes a chord between depth and dispatch. It processes 192K tokens and employs quantized weights for 1.2-second responses. The model balances tool calls with direct generation, ideal for interactive debugging.
It scores 70% on mixed-workload benches, excelling in hybrid tasks like code completion plus explanation. Developers leverage it for TDD cycles, where quick feedback loops accelerate progress.
GPT-5.1 Codex Max High Fast: Rapid Precision Engineering
GPT-5.1 Codex Max High Fast accelerates High's precision with parallel inference paths. At 256K context, it delivers 1-second turns while maintaining 74% benchmark scores. Features like predictive linting anticipate errors pre-edit.
This variant suits high-velocity teams, such as those in fintech API development. Apidog complements it by fast-tracking validation of speed-optimized endpoints.
GPT-5.1 Codex Max Low Fast: Lean and Swift Operations
GPT-5.1 Codex Max Low Fast combines Low's efficiency with sub-second speeds. Limited to 96K tokens, it prioritizes single-turn efficiency, hitting 65% on quick-edit evals.
Perfect for scripting or hotfixes, it minimizes overhead in resource-constrained setups.
GPT-5.1 Codex Max Extra High Fast: Peak Performance Hybrid
GPT-5.1 Codex Max Extra High Fast merges Extra High's depth with blistering pace—2-second max for 384K contexts. It achieves 80% on elite benches, using adaptive quantization.
For cutting-edge workflows, this model redefines agentic coding.
GPT-5.1 Codex: The Versatile Baseline
GPT-5.1 Codex acts as the unadorned core, offering balanced 256K handling at 2-second averages. It underpins all variants, scoring 70% across boards—reliable for general use.
GPT-5.1 Codex High: Elevated Everyday Utility
GPT-5.1 Codex High boosts baseline accuracy to 73%, focusing on robust planning for 192K contexts.
GPT-5.1 Codex Fast: Velocity-First Design
GPT-5.1 Codex Fast trims to 1-second responses and 128K tokens, at 60% efficacy—great for completions.
GPT-5.1 Codex High Fast: Tuned Agility
GPT-5.1 Codex High Fast delivers 72% precision in 1.2 seconds, blending High traits with speed.
GPT-5.1 Codex Low: Minimalist Precision
GPT-5.1 Codex Low conserves resources at 96K tokens, 67% scores—suited for edge devices.
GPT-5.1 Codex Low Fast: Ultra-Efficient
GPT-5.1 Codex Low Fast hits sub-second with 62%—ideal for micro-tasks.
GPT-5.1 Codex Mini High: Compact Excellence
GPT-5.1 Codex Mini High enhances Mini with 65% accuracy in 0.8 seconds.
GPT-5.1 Codex Mini Low: Budget Compact
GPT-5.1 Codex Mini Low offers 58% at minimal cost, for basic needs.
Technical Comparison: Metrics That Matter
To determine the best Cursor Codex model, we analyze key metrics: success rate (from Cursor Bench), latency, context size, and tool efficacy. Success rate gauges autonomous task completion, latency tracks response time, context measures token capacity, and tool efficacy evaluates shell integration.
| Model Variant | Success Rate (%) | Latency (s) | Context (K Tokens) | Tool Efficacy (%) |
|---|---|---|---|---|
| GPT-5.1 Codex Max | 78 | 2-3 | 512 | 92 |
| GPT-5.1 Codex Mini | 62 | <1 | 128 | 85 |
| GPT-5.1 Codex Max High | 72 | 1.5-2.5 | 256 | 90 |
| GPT-5.1 Codex Max Low | 68 | <2 | 128 | 88 |
| GPT-5.1 Codex Max Extra High | 82 | 3-4 | 384 | 95 |
| GPT-5.1 Codex Max Medium Fast | 70 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Max High Fast | 74 | 1 | 256 | 91 |
| GPT-5.1 Codex Max Low Fast | 65 | <1 | 96 | 84 |
| GPT-5.1 Codex Max Extra High Fast | 80 | 2 | 384 | 93 |
| GPT-5.1 Codex | 70 | 2 | 256 | 89 |
| GPT-5.1 Codex High | 73 | 1.8 | 192 | 88 |
| GPT-5.1 Codex Fast | 60 | 1 | 128 | 82 |
| GPT-5.1 Codex High Fast | 72 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Low | 67 | 1.5 | 96 | 85 |
| GPT-5.1 Codex Low Fast | 62 | <1 | 96 | 80 |
| GPT-5.1 Codex Mini High | 65 | 0.8 | 128 | 83 |
| GPT-5.1 Codex Mini Low | 58 | <0.8 | 64 | 78 |
These figures stem from Cursor's harness tests, which simulate real IDE interactions. Notice how Max variants dominate success rates, while Fast suffixes excel in latency.
Furthermore, consider energy efficiency: Low and Mini models consume 40% less power, per OpenAI's reports. For API-centric projects, tool efficacy directly impacts integration quality—higher scores mean fewer manual tweaks when exporting to Apidog.
Benchmark Breakdown: Real-World Performance Insights
Benchmarks provide concrete evidence. Cursor Bench, an internal suite, tests 500+ tasks across languages like Python, JavaScript, and Rust. GPT-5.1 Codex Max leads with 78% resolution, particularly in agentic chains involving 10+ tool calls. It resolves linter errors 92% of the time, thanks to dedicated read_lints integration.
GPT-5.1 Codex Mini Fast variants prioritize throughput. On a 100-task sprint simulating a sprint week, Mini completes 85% more iterations than Max, albeit with 20% lower accuracy on nuanced refactors.
SWE-bench Verified, a standardized metric, shows the family averaging 65%—a 25% leap from GPT-4.1. Extra High models peak at 82%, but their latency disqualifies them for live pair-programming.
Transitioning to use cases, high-context models like Max Extra High thrive in monorepos, navigating 50+ files effortlessly. For solo devs, Medium Fast strikes the optimal balance.
Use Cases: Matching Models to Developer Needs
Select your Cursor Codex model based on workflow demands. For full-stack API development, GPT-5.1 Codex Max High Fast generates secure, scalable endpoints quickly. It crafts GraphQL resolvers, then uses shell tools to test against mocks—streamline this with Apidog's schema validator for end-to-end confidence.
In embedded systems coding, GPT-5.1 Codex Low favors efficiency, generating C++ snippets that fit constrained environments. Machine learning pipelines benefit from Max Extra High's probabilistic planning, optimizing tensor flows with minimal trial-and-error.
For collaborative settings, Fast variants enable real-time suggestions, fostering team synergy. Always monitor token usage; exceeding limits triggers fallbacks, reducing efficacy by 15%.
Moreover, hybrid approaches work well—start with Mini for ideation, escalate to Max for implementation. This strategy maximizes ROI on compute budgets.
Optimization Tips: Enhancing Cursor Codex with Apidog
To amplify GPT-5.1 Codex performance, fine-tune your harness. Enable reasoning traces in settings; this boosts continuity, lifting success by 30% per Cursor docs. Prefer tool calls over raw shell—prompts like "Use read_file before editing" guide the model.
Incorporate Apidog for API workflows. Codex generates boilerplate; Apidog tests it instantly. Export specs as YAML, mock responses, and automate docs—cutting integration time by 50%.
Profile latencies with Cursor's built-in metrics. If bottlenecks arise, downshift to Low variants. Regularly update the harness for patches, as OpenAI iterates frequently.
Security matters too: Sanitize tool outputs to prevent injection risks. For production, audit Codex edits via diff reviews.
Conclusion: GPT-5.1 Codex Max Emerges as the Best Overall
After dissecting specs, benchmarks, and applications, GPT-5.1 Codex Max claims the top spot. Its unmatched 78% success rate, robust 512K context, and versatile toolset make it indispensable for serious coding. While Fast models win on speed and Mini on accessibility, Max delivers holistic excellence—empowering developers to tackle ambitious projects head-on.
Experiment in Cursor today, and layer in Apidog for comprehensive API handling. Your choice shapes productivity; opt for Max to future-proof your stack.


