
ElevenLabs chuyển văn bản thành giọng nói tự nhiên và hỗ trợ nhiều loại giọng, ngôn ngữ và phong cách khác nhau. API giúp dễ dàng nhúng giọng nói vào các ứng dụng, tự động hóa quy trình tường thuật hoặc xây dựng các trải nghiệm thời gian thực như trợ lý giọng nói. Nếu bạn có thể gửi một yêu cầu HTTP, bạn có thể tạo âm thanh trong vài giây.
nút
ElevenLabs API là gì?
ElevenLabs API cung cấp quyền truy cập theo chương trình vào các mô hình AI tạo, chuyển đổi và phân tích âm thanh. Nền tảng này ban đầu là một dịch vụ chuyển văn bản thành giọng nói nhưng đã mở rộng thành một bộ công cụ AI âm thanh hoàn chỉnh.
Các khả năng cốt lõi:
- Chuyển văn bản thành giọng nói (TTS): Chuyển đổi văn bản viết thành âm thanh nói với khả năng kiểm soát đặc điểm giọng nói, cảm xúc và nhịp độ.
- Chuyển giọng nói thành giọng nói (STS): Chuyển đổi một giọng nói sang giọng khác trong khi vẫn giữ nguyên ngữ điệu và thời gian ban đầu.
- Sao chép giọng nói: Tạo bản sao kỹ thuật số của bất kỳ giọng nói nào chỉ từ 60 giây âm thanh sạch.
- Lồng tiếng AI: Dịch và lồng tiếng nội dung âm thanh/video sang các ngôn ngữ khác nhau trong khi vẫn duy trì đặc điểm giọng nói của người nói.
- Hiệu ứng âm thanh: Tạo hiệu ứng âm thanh từ mô tả văn bản.
- Chuyển giọng nói thành văn bản: Chuyển đổi âm thanh thành văn bản với độ chính xác cao.
API hoạt động qua các giao thức HTTP và WebSocket tiêu chuẩn. Bạn có thể gọi nó từ bất kỳ ngôn ngữ nào, nhưng các SDK chính thức tồn tại cho Python và JavaScript/TypeScript với tính an toàn kiểu dữ liệu và hỗ trợ streaming được tích hợp sẵn.
Lấy Khóa API ElevenLabs
Trước khi thực hiện bất kỳ lệnh gọi API nào, bạn cần có khóa API. Dưới đây là cách lấy khóa:
Bước 1: Tạo một tài khoản miễn phí. Ngay cả gói miễn phí cũng bao gồm quyền truy cập API với 10.000 ký tự mỗi tháng.
Bước 2: Đăng nhập và điều hướng đến phần Profile + API Key. Bạn có thể tìm thấy phần này bằng cách nhấp vào biểu tượng hồ sơ của mình ở góc dưới bên trái, hoặc bằng cách đi trực tiếp đến cài đặt nhà phát triển.
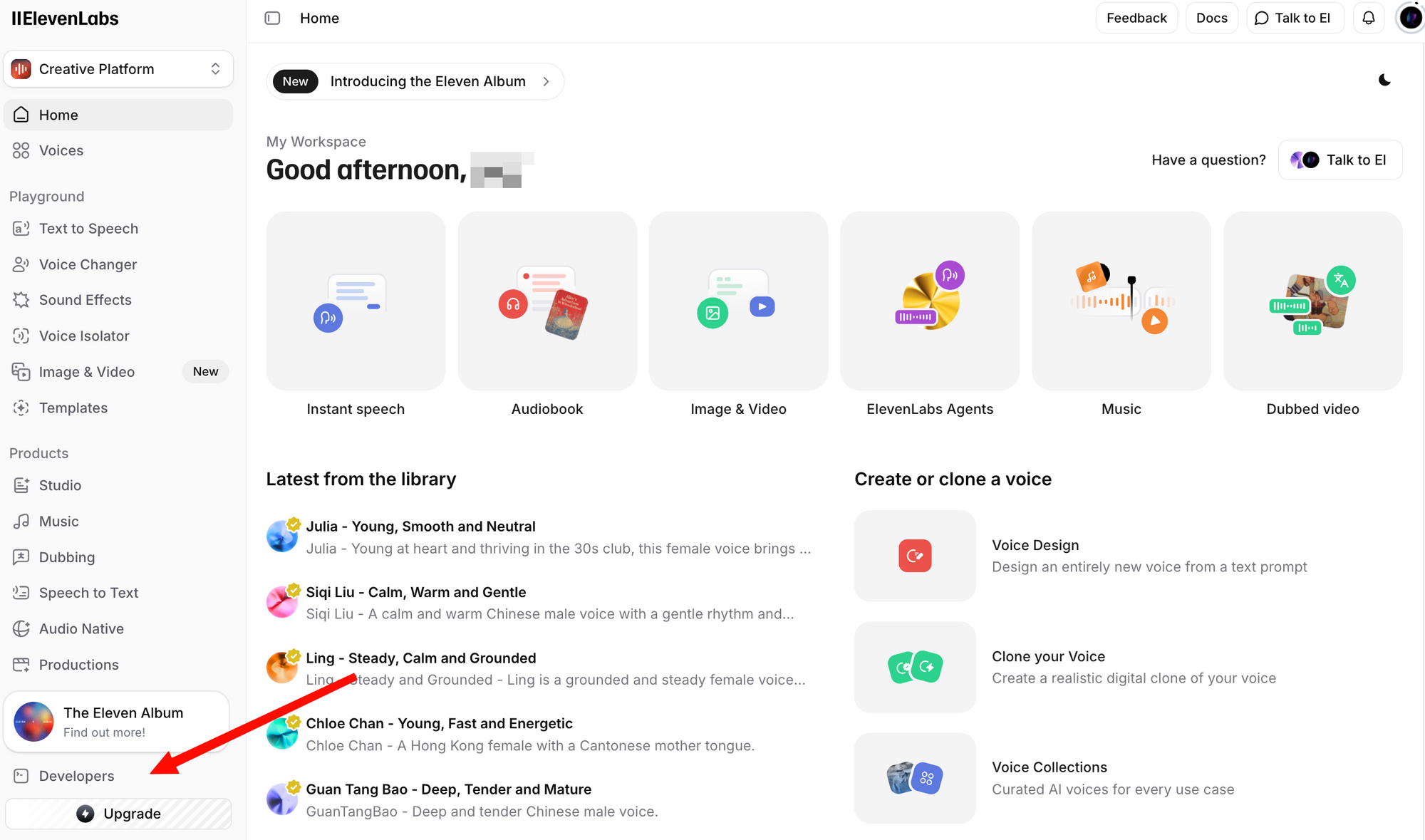
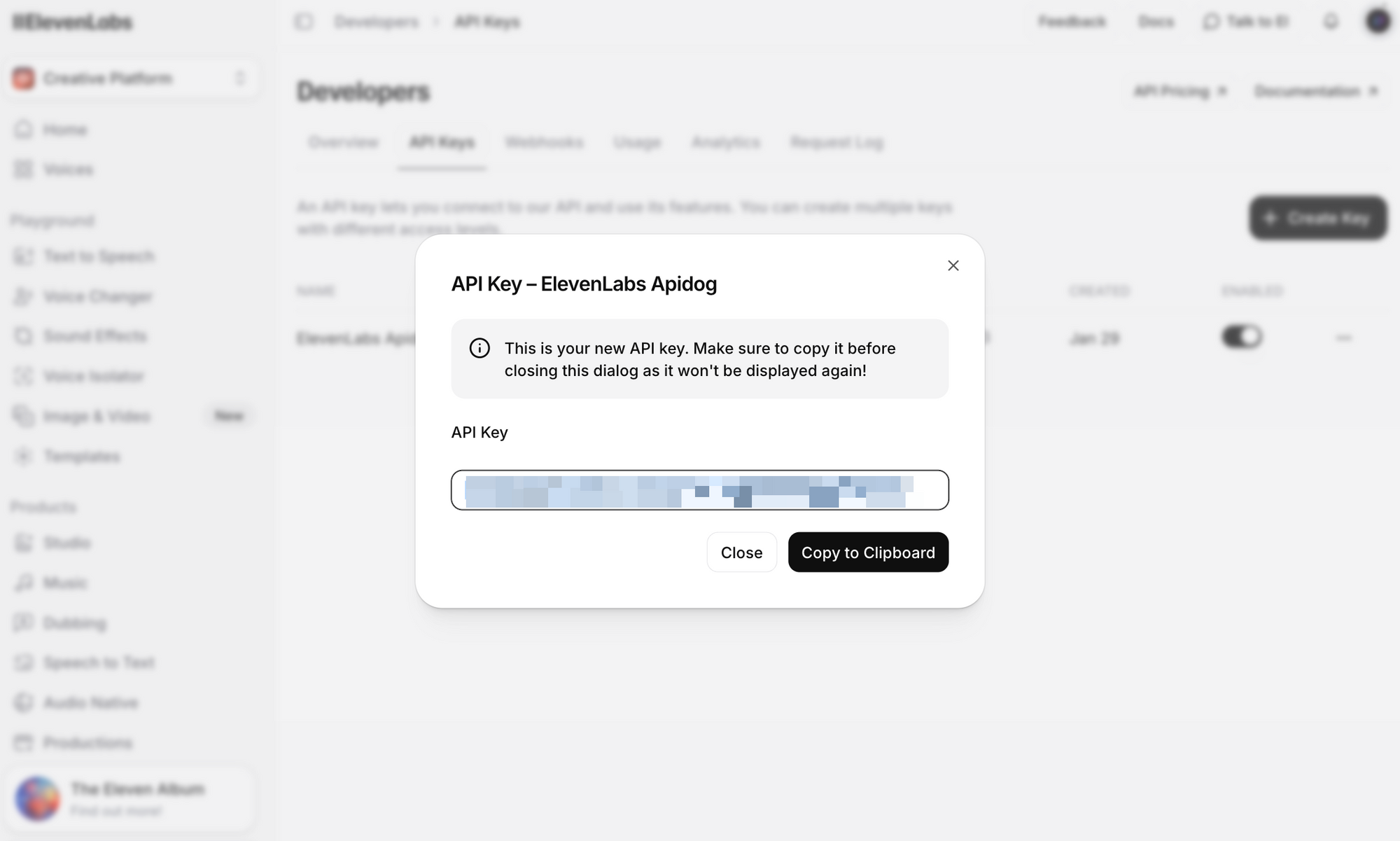
Bước 3: Nhấp vào Tạo Khóa API. Sao chép khóa và lưu trữ nó một cách an toàn—bạn sẽ không thể xem lại khóa đầy đủ nữa.
Lưu ý bảo mật quan trọng:
- Không bao giờ đưa khóa API của bạn vào kiểm soát phiên bản.
- Sử dụng biến môi trường hoặc trình quản lý bí mật trong môi trường sản xuất.
- Khóa API có thể được giới hạn trong các không gian làm việc cụ thể cho môi trường nhóm.
- Thay đổi khóa thường xuyên và thu hồi ngay lập tức các khóa bị xâm phạm.
Đặt nó làm biến môi trường cho các ví dụ trong hướng dẫn này:
# Linux/macOS
export ELEVENLABS_API_KEY="your_api_key_here"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="your_api_key_here"
Tổng quan về các Endpoint của ElevenLabs API
API được tổ chức xung quanh một số nhóm tài nguyên. Dưới đây là các endpoint được sử dụng phổ biến nhất:
| Endpoint | Phương thức | Mô tả |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | Chuyển đổi văn bản thành âm thanh giọng nói |
/v1/text-to-speech/{voice_id}/stream | POST | Truyền phát âm thanh khi nó được tạo |
/v1/speech-to-speech/{voice_id} | POST | Chuyển đổi giọng nói từ giọng này sang giọng khác |
/v1/voices | GET | Liệt kê tất cả các giọng nói có sẵn |
/v1/voices/{voice_id} | GET | Nhận chi tiết cho một giọng nói cụ thể |
/v1/models | GET | Liệt kê tất cả các mô hình có sẵn |
/v1/user | GET | Nhận thông tin tài khoản người dùng và mức sử dụng |
/v1/voice-generation/generate-voice | POST | Tạo một giọng nói ngẫu nhiên mới |
URL cơ sở: https://api.elevenlabs.io
Xác thực: Tất cả các yêu cầu đều cần tiêu đề xi-api-key:
xi-api-key: your_api_key_here
Chuyển văn bản thành giọng nói với cURL
Cách nhanh nhất để kiểm tra API là bằng lệnh cURL. Ví dụ này sử dụng giọng Rachel (ID: 21m00Tcm4TlvDq8ikWAM), một trong những giọng mặc định có sẵn trên tất cả các gói:
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Chào mừng bạn đến với ứng dụng của chúng tôi. Âm thanh này được tạo bằng ElevenLabs API.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
Nếu thành công, bạn sẽ nhận được tệp speech.mp3 với âm thanh đã tạo. Phát nó bằng bất kỳ trình phát media nào.
Phân tích yêu cầu:
- voice_id (trong URL): ID của giọng nói sẽ sử dụng. Mỗi giọng nói trong ElevenLabs đều có một ID duy nhất.
- text: Nội dung cần chuyển đổi thành giọng nói. Mô hình Flash v2.5 hỗ trợ tối đa 40.000 ký tự mỗi yêu cầu.
- model_id: Mô hình AI nào sẽ sử dụng.
eleven_flash_v2_5cung cấp sự cân bằng tốt nhất giữa tốc độ và chất lượng. - voice_settings: Các tham số tinh chỉnh tùy chọn (sẽ được trình bày chi tiết bên dưới).
Phản hồi trả về dữ liệu âm thanh thô. Định dạng mặc định là MP3, nhưng bạn có thể yêu cầu các định dạng khác bằng cách thêm tham số truy vấn output_format:
# Lấy âm thanh PCM thay vì MP3
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Xin chào thế giới", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
Sử dụng Python SDK
Python SDK chính thức đơn giản hóa việc tích hợp với các gợi ý kiểu, tính năng phát lại âm thanh tích hợp và hỗ trợ streaming.
Cài đặt
pip install elevenlabs
Để phát âm thanh trực tiếp qua loa của bạn, bạn cũng có thể cần mpv hoặc ffmpeg:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
Chuyển văn bản thành giọng nói cơ bản
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="ElevenLabs API giúp dễ dàng thêm đầu ra giọng nói chân thực vào bất kỳ ứng dụng nào.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # Giọng George
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
Lưu âm thanh vào tệp
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio = client.text_to_speech.convert(
text="Âm thanh này sẽ được lưu vào một tệp.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("Đã lưu âm thanh vào output.mp3")
Liệt kê các giọng nói có sẵn
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
response = client.voices.search()
for voice in response.voices:
print(f"Tên: {voice.name}, ID: {voice.voice_id}, Danh mục: {voice.category}")
Điều này in ra tất cả các giọng nói có sẵn trong tài khoản của bạn, bao gồm các giọng tạo sẵn, giọng đã sao chép và giọng cộng đồng mà bạn đã thêm.
Hỗ trợ Async
Đối với các ứng dụng sử dụng asyncio, SDK cung cấp AsyncElevenLabs:
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="your_api_key")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="Điều này được tạo ra một cách bất đồng bộ.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("Đã lưu âm thanh bất đồng bộ.")
asyncio.run(generate_speech())
Sử dụng JavaScript SDK
Node.js SDK chính thức (@elevenlabs/elevenlabs-js) cung cấp hỗ trợ TypeScript đầy đủ và hoạt động trong môi trường Node.js.
Cài đặt
npm install @elevenlabs/elevenlabs-js
Chuyển văn bản thành giọng nói cơ bản
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // ID giọng Rachel
{
text: "Xin chào từ ElevenLabs JavaScript SDK!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
Lưu vào tệp (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Âm thanh này sẽ được ghi vào một tệp bằng cách sử dụng luồng Node.js.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("Đã lưu âm thanh vào output.mp3");
Xử lý lỗi
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Đang kiểm tra xử lý lỗi.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`Lỗi API: ${error.message}, Trạng thái: ${error.statusCode}`);
} else {
console.error("Lỗi không mong muốn:", error);
}
}
SDK thử lại các yêu cầu thất bại tối đa 2 lần theo mặc định, với thời gian chờ 60 giây. Cả hai giá trị này đều có thể cấu hình được.
Truyền phát âm thanh theo thời gian thực
Đối với chatbot, trợ lý giọng nói hoặc bất kỳ ứng dụng nào mà độ trễ là yếu tố quan trọng, truyền phát cho phép bạn bắt đầu phát âm thanh trước khi toàn bộ phản hồi được tạo. Điều này rất quan trọng đối với AI đàm thoại, nơi người dùng mong đợi phản hồi gần như ngay lập tức.
Truyền phát Python
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio_stream = client.text_to_speech.stream(
text="Truyền phát cho phép bạn bắt đầu nghe âm thanh gần như ngay lập tức, mà không cần chờ đợi toàn bộ quá trình tạo hoàn tất.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Phát âm thanh đã truyền qua loa trong thời gian thực
stream(audio_stream)
Truyền phát JavaScript
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "Âm thanh này được truyền phát theo thời gian thực với độ trễ tối thiểu.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
Truyền phát WebSocket
Để có độ trễ thấp nhất, hãy sử dụng kết nối WebSocket. Điều này lý tưởng cho các tác nhân giọng nói thời gian thực, nơi văn bản đến theo từng đoạn (ví dụ: từ một LLM):
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Gửi cấu hình ban đầu
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "your_api_key",
}))
# Gửi các đoạn văn bản khi chúng đến (ví dụ: từ một LLM)
text_chunks = [
"Xin chào! ",
"Đây là truyền phát ",
"qua WebSockets. ",
"Mỗi đoạn được gửi riêng biệt."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Báo hiệu kết thúc đầu vào
await ws.send(json.dumps({"text": ""}))
# Nhận các đoạn âm thanh
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("Đã lưu âm thanh WebSocket.")
asyncio.run(stream_tts_websocket())
Lựa chọn và quản lý giọng nói
ElevenLabs cung cấp hàng trăm giọng nói. Việc chọn đúng giọng rất quan trọng đối với trải nghiệm người dùng của ứng dụng của bạn.
Giọng nói mặc định
Những giọng nói này có sẵn trên tất cả các gói, bao gồm cả gói miễn phí:
| Tên giọng nói | ID giọng nói | Mô tả |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | Bình tĩnh, nữ trẻ |
| Drew | 29vD33N1CtxCmqQRPOHJ | Nam tròn trịa |
| Clyde | 2EiwWnXFnvU5JabPnv8n | Nhân vật cựu chiến binh |
| Paul | 5Q0t7uMcjvnagumLfvZi | Phóng viên thực địa |
| Domi | AZnzlk1XvdvUeBnXmlld | Nữ mạnh mẽ, quyết đoán |
| Dave | CYw3kZ02Hs0563khs1Fj | Nam người Anh đàm thoại |
| Fin | D38z5RcWu1voky8WS1ja | Nam người Ireland |
| Sarah | EXAVITQu4vr4xnSDxMaL | Nữ trẻ, dịu dàng |
Tìm ID giọng nói
Sử dụng API để tìm kiếm tất cả các giọng nói có sẵn:
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
Hoặc lọc theo danh mục (có sẵn, đã sao chép, đã tạo):
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# Liệt kê chỉ các giọng nói tạo sẵn
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
Bạn cũng có thể sao chép trực tiếp ID giọng nói từ trang web ElevenLabs: chọn một giọng nói, nhấp vào menu ba chấm và chọn Sao chép ID giọng nói.
Chọn mô hình phù hợp
ElevenLabs cung cấp nhiều mô hình, mỗi mô hình được tối ưu hóa cho các trường hợp sử dụng khác nhau:

# Liệt kê tất cả các mô hình có sẵn với chi tiết
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
models = client.models.list()
for model in models:
print(f"Mô hình: {model.name}")
print(f" ID: {model.model_id}")
print(f" Ngôn ngữ: {len(model.languages)}")
print(f" Tối đa ký tự: {model.max_characters_request_free_user}")
print()
Kiểm tra ElevenLabs API với Apidog
Trước khi viết mã tích hợp, việc kiểm tra các endpoint API một cách tương tác sẽ rất hữu ích. Apidog giúp việc này trở nên đơn giản—bạn có thể cấu hình các yêu cầu trực quan, kiểm tra phản hồi (bao gồm cả âm thanh) và tạo mã client sau khi bạn hài lòng.
nút
Bước 1: Thiết lập một dự án mới
Mở Apidog và tạo một dự án mới. Đặt tên là "ElevenLabs API" hoặc thêm các endpoint vào một dự án hiện có.
Bước 2: Cấu hình xác thực
Đi tới Project Settings > Auth và thiết lập một tiêu đề chung:
- Tên tiêu đề:
xi-api-key - Giá trị tiêu đề: khóa API ElevenLabs của bạn
Điều này tự động đính kèm xác thực vào mọi yêu cầu trong dự án.
Bước 3: Tạo yêu cầu chuyển văn bản thành giọng nói
Tạo một yêu cầu POST mới:
- URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - Nội dung (JSON):
{
"text": "Đang kiểm tra ElevenLabs API thông qua Apidog. Điều này giúp dễ dàng thử nghiệm với các giọng nói và cài đặt khác nhau.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
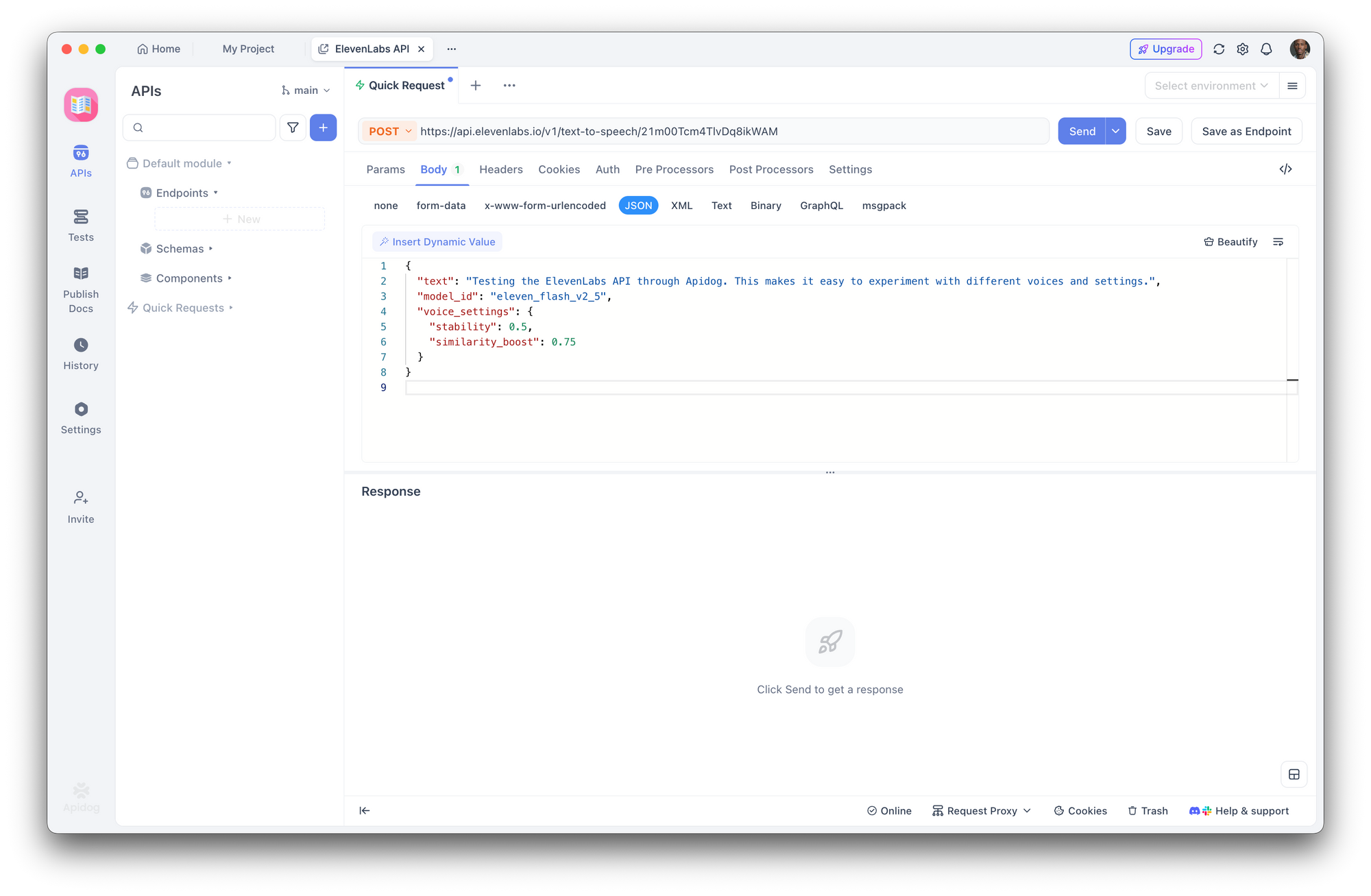
Nhấp vào Gửi. Apidog hiển thị các tiêu đề phản hồi và cho phép bạn tải xuống hoặc phát âm thanh trực tiếp.
Bước 4: Thử nghiệm với các tham số
Sử dụng giao diện của Apidog để nhanh chóng thay đổi ID giọng nói, thay đổi mô hình hoặc điều chỉnh cài đặt giọng nói mà không cần chỉnh sửa JSON thô. Lưu các cấu hình khác nhau dưới dạng các endpoint riêng biệt trong bộ sưu tập của bạn để dễ dàng so sánh.
Bước 5: Tạo mã client
Sau khi bạn đã xác nhận yêu cầu hoạt động, nhấp vào Tạo mã trong Apidog để nhận mã client sẵn sàng sử dụng bằng Python, JavaScript, cURL, Go, Java và nhiều ngôn ngữ khác. Điều này loại bỏ việc chuyển đổi thủ công từ tài liệu API sang mã hoạt động.
Hãy thử ngay bây giờ:Tải xuống Apidog miễn phí
Cài đặt giọng nói và tinh chỉnh
Cài đặt giọng nói cho phép bạn điều chỉnh cách giọng nói nghe. Các tham số này được gửi trong đối tượng voice_settings:
| Tham số | Phạm vi | Mặc định | Hiệu ứng |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | Cao hơn = nhất quán hơn, ít biểu cảm hơn. Thấp hơn = biến đổi hơn, nhiều cảm xúc hơn. |
similarity_boost | 0.0 - 1.0 | 0.75 | Cao hơn = gần với giọng nói gốc hơn. Thấp hơn = biến đổi hơn. |
style | 0.0 - 1.0 | 0.0 | Cao hơn = phong cách phóng đại hơn. Tăng độ trễ. Chỉ dành cho Multilingual v2. |
use_speaker_boost | boolean | true | Tăng cường sự tương đồng với người nói gốc. Tăng độ trễ nhỏ. |
Ví dụ thực tế:
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# Giọng kể chuyện: nhất quán, ổn định
narration = client.text_to_speech.convert(
text="Chương một. Đó là một ngày tháng Tư lạnh lẽo và sáng sủa.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# Giọng đàm thoại: biểu cảm, tự nhiên
conversational = client.text_to_speech.convert(
text="Ồ, wow, đó thực sự là một ý tưởng tuyệt vời! Để tôi nghĩ xem làm thế nào chúng ta có thể thực hiện nó.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
Hướng dẫn:
- Đối với sách nói và tường thuật, sử dụng độ ổn định cao hơn (0.7-0.9) để có cách thể hiện nhất quán.
- Đối với chatbot và AI đàm thoại, sử dụng độ ổn định thấp hơn (0.3-0.5) để có sự biến đổi tự nhiên.
- Đối với giọng nhân vật, thử nghiệm với
similarity_boostthấp hơn (0.4-0.6) để tạo ra các cá tính riêng biệt. - Tham số
stylechỉ hoạt động với Multilingual v2 và làm tăng độ trễ—hãy bỏ qua nó cho các ứng dụng thời gian thực.
Giá và giới hạn tốc độ của ElevenLabs API
ElevenLabs sử dụng hệ thống định giá dựa trên tín dụng. Dưới đây là bảng phân tích:
Khắc phục sự cố
| Lỗi | Nguyên nhân | Khắc phục |
|---|---|---|
| 401 Unauthorized | Khóa API không hợp lệ hoặc thiếu | Kiểm tra giá trị tiêu đề xi-api-key của bạn |
| 422 Unprocessable Entity | Nội dung yêu cầu không hợp lệ | Xác minh voice_id tồn tại và văn bản không trống |
| 429 Too Many Requests | Vượt quá giới hạn tốc độ | Thêm thời gian chờ lũy thừa (exponential backoff) hoặc nâng cấp gói của bạn |
| Âm thanh nghe như robot | Mô hình hoặc cài đặt sai | Thử Multilingual v2 với độ ổn định ở 0.5 |
| Lỗi phát âm | Vấn đề chuẩn hóa văn bản | Viết đầy đủ các số/từ viết tắt, hoặc sử dụng định dạng giống SSML |
Kết luận
ElevenLabs API cung cấp cho các nhà phát triển quyền truy cập vào một số công nghệ tổng hợp giọng nói chân thực nhất hiện nay. Cho dù bạn cần một vài dòng tường thuật hay một quy trình giọng nói thời gian thực đầy đủ, API đều có thể mở rộng từ các lệnh gọi cURL đơn giản đến các luồng WebSocket sản xuất.
Sẵn sàng thêm giọng nói chân thực vào ứng dụng của bạn chưa? Tải xuống Apidog để kiểm tra các endpoint của ElevenLabs API, thử nghiệm với cài đặt giọng nói và tạo mã client—tất cả đều miễn phí, không yêu cầu thẻ tín dụng.
nút