จะเกิดอะไรขึ้นหากคุณสามารถเปลี่ยนผู้ให้บริการ AI โดยไม่ต้องเขียนโค้ดใหม่แม้แต่บรรทัดเดียว? Venice API มอบสิ่งนั้นให้คุณได้ ด้วยเอนด์พอยต์ที่เข้ากันได้กับ OpenAI โดยไม่มีการเก็บข้อมูลเลย ตัวเลือกโมเดลที่ไม่ถูกเซ็นเซอร์ และสถาปัตยกรรมที่เน้นความเป็นส่วนตัวที่คุณควบคุมได้
API ของ AI ส่วนใหญ่บังคับให้คุณใช้ SDK เฉพาะของผู้ให้บริการ เก็บข้อมูลของคุณไว้สำหรับการฝึกโมเดล และคิดค่าบริการในอัตราที่สูงสำหรับฟังก์ชันพื้นฐาน คุณจะต้องเขียนแอปพลิเคชันใหม่เมื่อเปลี่ยนผู้ให้บริการ พร้อมท์ของคุณจะถูกนำไปฝึกโมเดลของคู่แข่ง และค่าใช้จ่ายของคุณจะเพิ่มขึ้นอย่างคาดเดาไม่ได้
Venice API ช่วยขจัดปัญหาเหล่านี้ มันเลียนแบบโครงสร้าง API ของ OpenAI ได้อย่างสมบูรณ์แบบ เพียงเปลี่ยน base URL โค้ดเดิมของคุณก็จะทำงานได้ทันที ข้อมูลของคุณจะยังคงเป็นส่วนตัว คุณสามารถเลือกจากโมเดลการชำระเงินได้หลายแบบ รวมถึงการวางเดิมพันด้วยคริปโต (crypto staking) และการชำระเงินแบบตามการใช้งาน (pay-as-you-go) ด้วยเครดิต USD
ต้องการแพลตฟอร์มแบบครบวงจรสำหรับทีมพัฒนาของคุณเพื่อทำงานร่วมกันด้วย ประสิทธิภาพสูงสุด หรือไม่?
Apidog ตอบสนองทุกความต้องการของคุณ และ มาแทนที่ Postman ในราคาที่ย่อมเยากว่ามาก!
การสร้างคีย์ API ของ Venice ของคุณ
1. ไปที่ venice.ai/settings/api
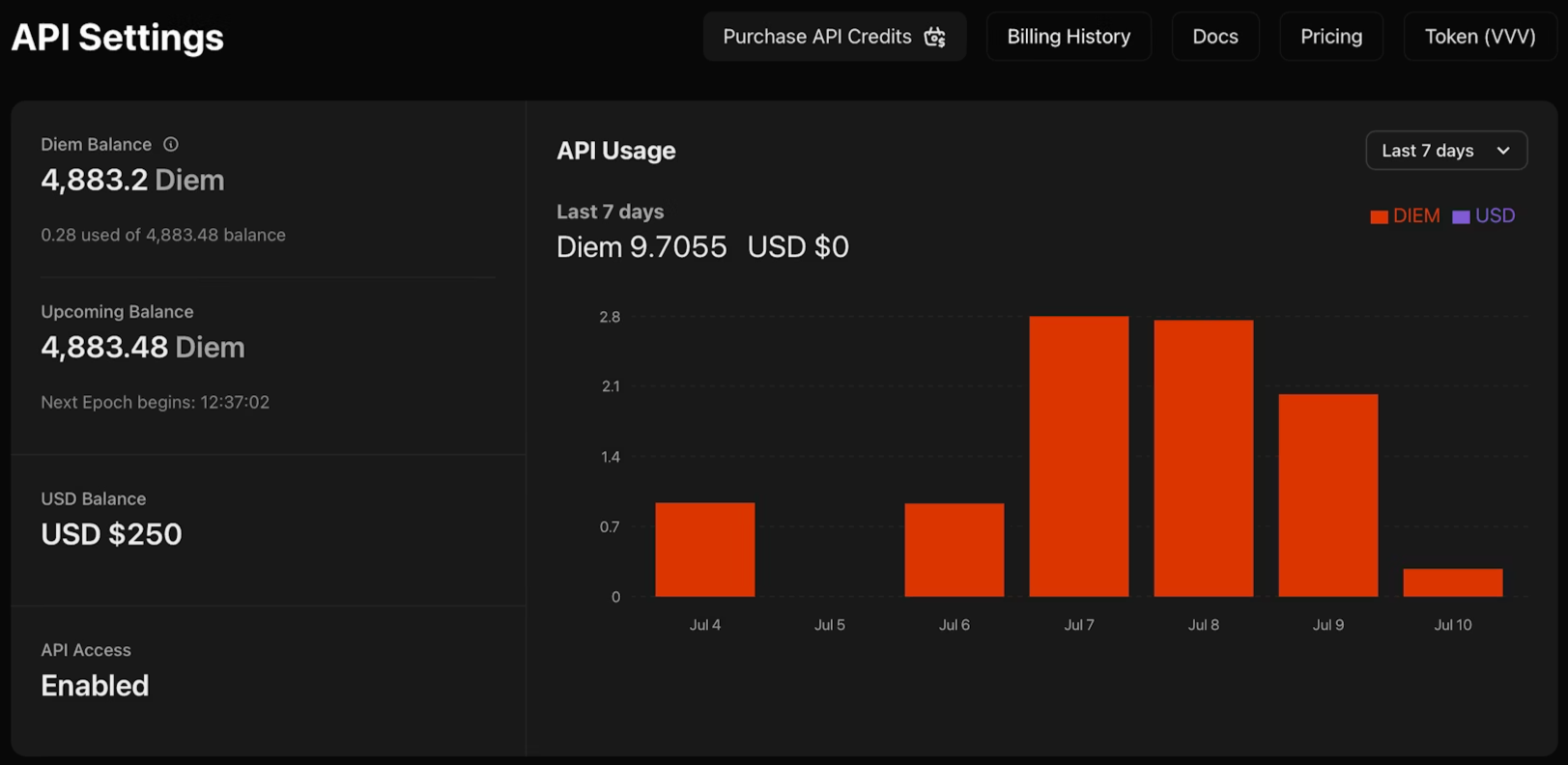
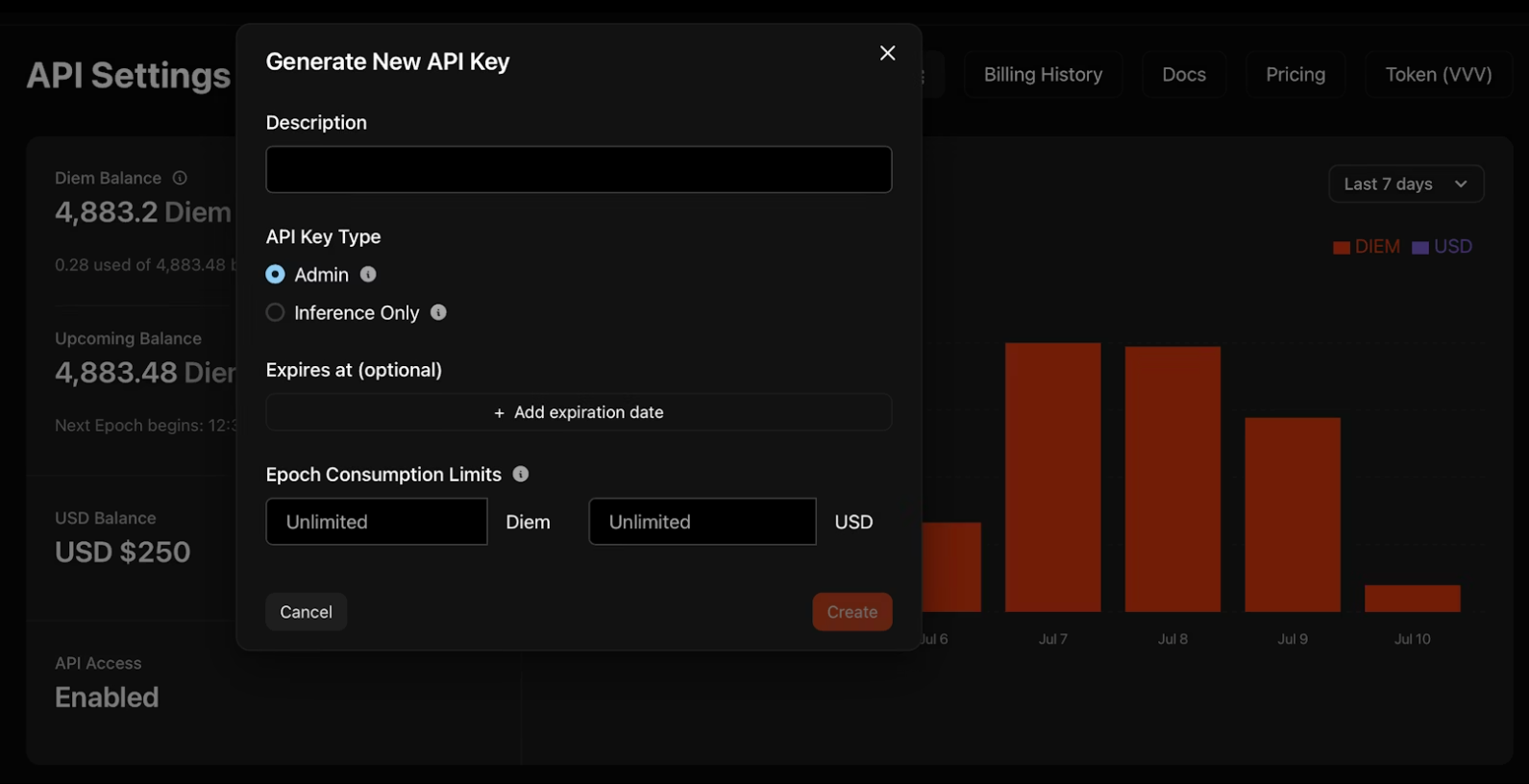
2. คลิก "Generate New API Key" (สร้างคีย์ API ใหม่) และกำหนดค่าข้อมูลประจำตัวของคุณ:
- คำอธิบาย: ตั้งชื่อคีย์ของคุณเพื่อการจัดการ
- ประเภท: คีย์ผู้ดูแลระบบ (Admin keys) ใช้จัดการคีย์อื่น ๆ โดยทางโปรแกรม; คีย์สำหรับอนุมานเท่านั้น (Inference-only keys) ใช้รันโมเดลเท่านั้น
- วันหมดอายุ: วันที่เลือกได้ซึ่งคีย์จะถูกปิดใช้งานโดยอัตโนมัติ
- ขีดจำกัดการใช้งาน: จำกัดการใช้ Diem หรือ USD รายวันเพื่อควบคุมค่าใช้จ่าย
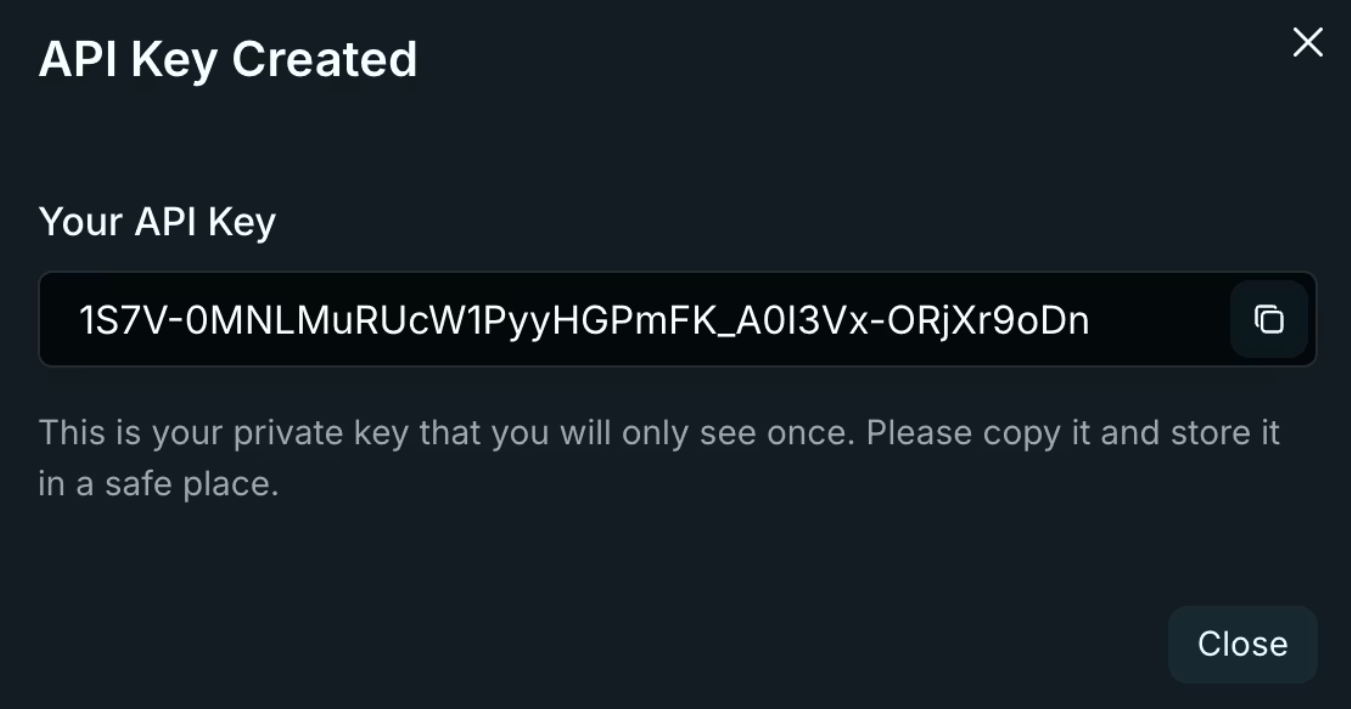
3. คัดลอกคีย์ของคุณทันที Venice จะแสดงคีย์เพียงครั้งเดียวเท่านั้น! เก็บไว้ในตัวแปรสภาพแวดล้อม ห้ามเก็บไว้ในที่เก็บโค้ดเด็ดขาด
export VENICE_API_KEY="your-key-here"
ข้อควรพิจารณาด้านความปลอดภัยของคีย์
คีย์ผู้ดูแลระบบ (Admin keys) ให้สิทธิ์การเข้าถึงบัญชี Venice ของคุณอย่างกว้างขวาง ปฏิบัติต่อคีย์เหล่านี้เหมือนข้อมูลรับรองระดับรูท—ใช้สำหรับการสคริปต์การหมุนเวียนคีย์และการจัดการทีม ห้ามใช้ในโค้ดแอปพลิเคชันเด็ดขาด คีย์สำหรับอนุมานเท่านั้น (Inference-only keys) จะจำกัดการทำงานเฉพาะการรันโมเดล ซึ่งช่วยลดความเสี่ยงหากคีย์รั่วไหล หมุนเวียนคีย์ทุกไตรมาสโดยใช้บันทึกกิจกรรมในแดชบอร์ดเพื่อระบุข้อมูลรับรองที่ไม่ได้ใช้งานแล้ว
การรับรองความถูกต้องและการกำหนดค่าพื้นฐานของ Venice API
Venice ใช้การรับรองความถูกต้องด้วย Bearer token มาตรฐาน ทุกคำขอต้องมีเฮดเดอร์สองรายการ:
Authorization: Bearer $VENICE_API_KEY
Content-Type: application/json
Base URL เป็นไปตามรูปแบบของ OpenAI อย่างแน่นอน:
import openai
import os
client = openai.OpenAI(
api_key=os.getenv("VENICE_API_KEY"),
base_url="https://api.venice.ai/api/v1"
)
การเปลี่ยนแปลงการกำหนดค่าเพียงครั้งเดียวนี้จะส่งผ่านการเรียก OpenAI SDK ที่มีอยู่ทั้งหมดของคุณผ่านโครงสร้างพื้นฐานของ Venice ไม่มีการเปลี่ยนแปลงเมธอด ไม่ต้องเขียนพารามิเตอร์ใหม่ โค้ดของคุณจะทำงานได้ทันที
ความเข้ากันได้ของ SDK
Venice รักษาความเข้ากันได้กับ SDK อย่างเป็นทางการของ OpenAI ในภาษา Python, TypeScript, Go, PHP, C#, Java และ Swift ไลบรารีของบุคคลที่สามที่สร้างขึ้นตามข้อกำหนดของ OpenAI ก็ทำงานได้โดยไม่ต้องแก้ไขเช่นกัน ทดสอบโค้ดเบสที่มีอยู่ของคุณกับ Venice โดยเปลี่ยนเฉพาะ base URL และคีย์ API เท่านั้น—หากคุณใช้การเติมข้อความแชทมาตรฐาน (chat completions), การสตรีม (streaming) หรือการเรียกฟังก์ชัน (function calling) การย้ายข้อมูลจะใช้เวลาเพียงไม่กี่นาที
การย้ายจาก OpenAI
การย้ายข้อมูลต้องมีการเปลี่ยนแปลงสามอย่าง: base URL, คีย์ API และชื่อโมเดล แทนที่ https://api.openai.com/v1 ด้วย https://api.venice.ai/api/v1 สลับคีย์ API ของ OpenAI ของคุณเป็นคีย์ของ Venice เปลี่ยนตัวระบุโมเดลจาก gpt-4 หรือ gpt-3.5-turbo เป็นสิ่งที่เทียบเท่าใน Venice เช่น qwen3-4b ทดสอบอย่างละเอียดก่อนนำไปใช้งานจริง ตรวจสอบว่าการตอบสนองแบบสตรีมมิ่งประมวลผลถูกต้อง ยืนยันว่า schema การเรียกฟังก์ชันถูกต้อง ตรวจสอบพารามิเตอร์การสร้างภาพตรงตามความต้องการของคุณ เลเยอร์ความเข้ากันได้ของ Venice จัดการกรณีพิเศษส่วนใหญ่ได้ แต่ก็มีความแตกต่างเล็กน้อยในการจัดรูปแบบข้อความแสดงข้อผิดพลาดและส่วนหัวการจำกัดอัตรา (rate limit headers)
เคล็ดลับมือโปร: ทดสอบเอนด์พอยต์ API ทั้งหมดของคุณอย่างละเอียดด้วย Apidog
เอนด์พอยต์และความสามารถหลักของ Venice API
Venice มีเอนด์พอยต์ที่แตกต่างกันเก้ารายการ ครอบคลุมการสร้างข้อความ รูปภาพ เสียง และวิดีโอ:
การสร้างข้อความ
/api/v1/chat/completions- AI แบบสนทนาพร้อมรองรับการสตรีม/api/v1/embeddings/generate- การฝังเวกเตอร์ (Vector embeddings) สำหรับแอปพลิเคชัน RAG
การประมวลผลภาพ
/api/v1/image/generate- การสร้างภาพจากข้อความ/api/v1/image/upscale- การเพิ่มความละเอียด/api/v1/image/edit- การแก้ไขและเติมภาพด้วย AI
เสียง
/api/v1/audio/speech- การสังเคราะห์เสียงพูดจากข้อความ/api/v1/audio/transcriptions- การแปลงเสียงพูดเป็นข้อความ
วิดีโอและตัวละคร
/api/v1/video/queue- การสร้างวิดีโอจากข้อความ/วิดีโอ/api/v1/characters/list- การจัดการบุคลิก AI
แต่ละเอนด์พอยต์จะรักษารูปแบบคำขอ/การตอบกลับที่เข้ากันได้กับ OpenAI ในกรณีที่เกี่ยวข้อง คุณสามารถใช้ตรรกะการแยกวิเคราะห์ (parsing logic) ที่มีอยู่ได้ซ้ำ
กลยุทธ์การเลือกเอนด์พอยต์
จับคู่เอนด์พอยต์กับความซับซ้อนของกรณีการใช้งานของคุณ การเติมข้อความแชท (chat completions) รองรับความต้องการในการสร้างข้อความส่วนใหญ่ เพิ่มการฝัง (embeddings) สำหรับการค้นหาเชิงความหมาย (semantic search) หรือไปป์ไลน์ RAG ใช้เอนด์พอยต์ภาพสำหรับเวิร์กโฟลว์สร้างสรรค์หรือการกลั่นกรองเนื้อหา เอนด์พอยต์เสียงช่วยให้สามารถเข้าถึงคุณสมบัติการช่วยการเข้าถึงหรืออินเทอร์เฟซเสียงได้ เริ่มต้นด้วยเอนด์พอยต์เดียว ตรวจสอบความถูกต้องของการผสานรวมของคุณ จากนั้นจึงขยายไปสู่เวิร์กโฟลว์แบบหลายโมดัล
การทำงานกับการตอบสนองแบบสตรีมมิ่ง
การสตรีมช่วยลดเวลาแฝงที่รับรู้ได้สำหรับแอปพลิเคชันแชท Venice ใช้ Server-Sent Events (SSE) ที่เหมือนกับการใช้งานของ OpenAI ประมวลผลเนื้อหาบางส่วนเมื่อมาถึง แทนที่จะรอการตอบสนองที่สมบูรณ์ จัดการการยุติการสตรีมโดยตรวจสอบข้อความ [DONE] ใช้งานตรรกะการเชื่อมต่อใหม่สำหรับการสตรีมที่ถูกขัดจังหวะ—จัดเก็บประวัติการสนทนาทางฝั่งไคลเอ็นต์และลองส่งคำขอที่ล้มเหลวใหม่ ตรวจสอบการใช้โทเค็นในส่วนของสตรีมเพื่อติดตามค่าใช้จ่ายแบบเรียลไทม์
พารามิเตอร์เฉพาะของ Venice API
นอกเหนือจากพารามิเตอร์มาตรฐานของ OpenAI แล้ว Venice ยังเพิ่มการควบคุมความสามารถผ่านออบเจกต์ venice_parameters:
{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Latest AI developments?"}],
"venice_parameters": {
"enable_web_search": "on",
"enable_web_citations": true,
"strip_thinking_response": false
}
}
การผสานรวมการค้นหาเว็บ
ตั้งค่า enable_web_search เป็น auto, on หรือ off auto ให้โมเดลตัดสินใจว่าจะใช้ข้อมูลปัจจุบันเพื่อปรับปรุงการตอบสนองเมื่อใด บังคับให้เป็น on สำหรับการสอบถามแบบเรียลไทม์เกี่ยวกับเหตุการณ์ล่าสุดหรือเทคโนโลยีที่เปลี่ยนแปลงอย่างรวดเร็ว จับคู่กับ enable_web_citations เพื่อส่งคืน URL แหล่งที่มา—ซึ่งจำเป็นสำหรับเครื่องมือวิจัยและการยืนยันข้อเท็จจริง
การควบคุมการใช้เหตุผล
โมเดลการให้เหตุผล เช่น DeepSeek R1 จะแสดงการคิดเป็นขั้นตอนโดยค่าเริ่มต้น ตั้งค่า strip_thinking_response เป็น true เพื่อส่งคืนเฉพาะคำตอบสุดท้าย ซึ่งช่วยลดการใช้โทเค็น ใช้ disable_thinking เพื่อข้ามการให้เหตุผลทั้งหมดสำหรับคำถามง่ายๆ
ไวยากรณ์ทางเลือก
ส่งพารามิเตอร์ผ่านส่วนต่อท้ายของโมเดลสำหรับการร้องขอที่กระชับ:
model="qwen3-4b:enable_web_search=on&enable_web_citations=true"
ลำดับชั้นของพารามิเตอร์
พารามิเตอร์เฉพาะของ Venice จะแทนที่ค่าเริ่มต้น แต่ยังคงเคารพการตั้งค่าที่ระบุอย่างชัดเจน หากคุณระบุ temperature: 0.5 ในออบเจกต์หลักและ enable_web_search: on ใน venice_parameters ทั้งสองจะถูกนำมาใช้พร้อมกัน ทดสอบการรวมกันของพารามิเตอร์แยกกันก่อนที่จะนำไปใช้จริง—พารามิเตอร์บางตัวอาจมีปฏิกิริยาที่ไม่คาดคิดกับโมเดลบางชนิด
ตัวอย่างการใช้งานจริงเมื่อใช้ Venice API
การเติมข้อความแชทขั้นพื้นฐาน
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Explain zero-knowledge proofs"}],
"stream": true
}'
การสตรีมทำงานเหมือนกับ OpenAI—ประมวลผลส่วน SSE เมื่อมาถึง
การเรียกฟังก์ชัน
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Weather in Tokyo?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
}]
}'
โมเดลของ Venice รองรับการเรียกฟังก์ชันแบบขนานและการบังคับใช้ schema เหมือนกับการใช้งานของ OpenAI
การสร้างภาพ
curl --request POST \
--url https://api.venice.ai/api/v1/image/generate \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "venice-sd35",
"prompt": "Cyberpunk cityscape at night, neon reflections",
"aspect_ratio": "16:9",
"resolution": "2K",
"hide_watermark": true
}'
อัตราส่วนภาพที่ใช้ได้คือ 1:1, 4:3, 16:9 และ 21:9 ตัวเลือกความละเอียดคือ 1K และ 2K
การปรับขนาดภาพให้คมชัดขึ้น
curl --request POST \
--url https://api.venice.ai/api/v1/image/upscale \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "upscale-sd35",
"image": "base64encodedimage..."
}'
การวิเคราะห์ภาพ
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-vl-235b-a22b",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "What architecture style is this?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}'
ส่งภาพเป็น base64 data URI หรือ HTTPS URL โมเดล Vision รองรับภาพหลายภาพต่อข้อความสำหรับงานเปรียบเทียบ
การสังเคราะห์เสียง
curl --request POST \
--url https://api.venice.ai/api/v1/audio/speech \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "tts-kokoro",
"input": "Welcome to Venice API",
"voice": "af_sky",
"response_format": "mp3"
}'
ตัวเลือกเสียงใช้คำนำหน้า: af_ (เสียงผู้หญิงอเมริกัน), am_ (เสียงผู้ชายอเมริกัน) และรูปแบบที่คล้ายกันสำหรับสำเนียงอื่น ๆ
รูปแบบการจัดการข้อผิดพลาด
Venice ส่งคืนรหัสสถานะ HTTP มาตรฐาน รหัส 401 บ่งชี้ว่าการรับรองความถูกต้องล้มเหลว—ตรวจสอบคีย์ API และเฮดเดอร์ของคุณ รหัส 429 บ่งชี้ถึงการจำกัดอัตรา (rate limiting); ให้ใช้ exponential backoff โดยเริ่มที่ 1 วินาที ข้อผิดพลาด 500 บ่งชี้ถึงปัญหาโครงสร้างพื้นฐานชั่วคราว; ให้ลองใหม่หลังจาก 5 วินาที แยกวิเคราะห์การตอบสนองข้อผิดพลาดสำหรับข้อความเฉพาะ—Venice มีเหตุผลความล้มเหลวโดยละเอียดในส่วนเนื้อหาการตอบสนอง
สถาปัตยกรรมข้อมูลและความเป็นส่วนตัวของ Venice API
นโยบายการไม่เก็บข้อมูลของ Venice ดำเนินการผ่านสถาปัตยกรรมทางเทคนิค ไม่ใช่แค่คำมั่นสัญญาทางกฎหมาย เบราว์เซอร์ของคุณจะจัดเก็บประวัติการสนทนาในเครื่องโดยใช้ IndexedDB เซิร์ฟเวอร์ของ Venice ประมวลผลพร้อมท์บน GPU ที่เห็นเฉพาะคำขอปัจจุบันเท่านั้น—ไม่มีประวัติการสนทนา ไม่มีข้อมูลเมตาประจำตัวผู้ใช้ ไม่มีข้อมูลคีย์ API
หลังจากสร้างการตอบสนองแล้ว เซิร์ฟเวอร์จะทิ้งพร้อมท์และผลลัพธ์ทันที ไม่มีสิ่งใดคงอยู่บนดิสก์หรือบันทึก ข้อมูลของคุณไม่เคยถูกนำไปฝึกโมเดล นี่คือความแตกต่างพื้นฐานจากบริการแบบรวมศูนย์ที่เก็บข้อมูลไว้สำหรับการตรวจจับการละเมิดและการปรับปรุงโมเดล
เพื่อความเป็นส่วนตัวเพิ่มเติม Venice ได้โฮสต์โมเดลส่วนใหญ่บนโครงสร้างพื้นฐานส่วนตัว แทนที่จะพึ่งพาผู้ให้บริการบุคคลที่สาม ตัวเลือกที่ไม่ถูกเซ็นเซอร์จะทำงานบนฮาร์ดแวร์ที่ Venice ควบคุม ทำให้มั่นใจได้ว่าจะไม่มีการกรองหรือบันทึกจากภายนอก
การตรวจสอบการไหลของข้อมูล
ตรวจสอบข้อกล่าวอ้างด้านความเป็นส่วนตัวของ Venice โดยการตรวจสอบการรับส่งข้อมูลเครือข่าย คำขอ API ตรงไปยัง api.venice.ai พร้อมการเข้ารหัส TLS ไม่มีสคริปต์วิเคราะห์ของบุคคลที่สามโหลดในเอกสาร ส่วนหัวการตอบกลับไม่แสดงคำสั่งแคชใดๆ—ยืนยันว่าไม่มีการเก็บข้อมูลทางฝั่งเซิร์ฟเวอร์ สำหรับแอปพลิเคชันที่ละเอียดอ่อน ให้ใช้การเข้ารหัสทางฝั่งไคลเอ็นต์ก่อนส่งพร้อมท์ แม้ว่าการทำเช่นนี้จะทำให้โมเดลไม่สามารถเข้าใจเนื้อหาได้ก็ตาม
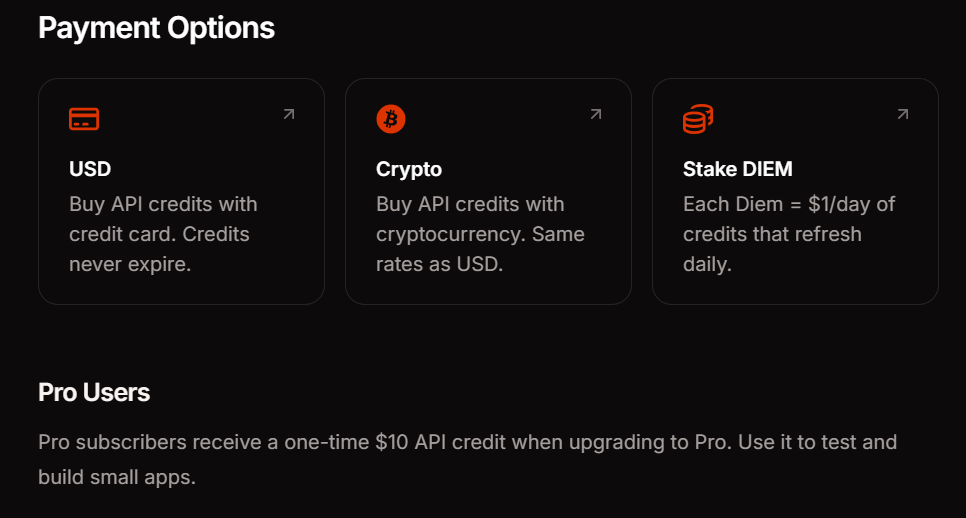
ตัวเลือกราคาและการชำระเงินของ Venice API
Venice เสนอ วิธีการชำระเงิน สามแบบเพื่อให้เข้ากับรูปแบบการใช้งานของคุณ การสมัครสมาชิก Pro มีค่าใช้จ่าย $18 ต่อเดือน และรวมเครดิต API $10 พร้อมพร้อมท์ไม่จำกัดในคุณสมบัติสำหรับผู้บริโภค การวางเดิมพัน DIEM (DIEM staking) ต้องซื้อโทเค็น VVV ซึ่งให้การจัดสรรการประมวลผลรายวันแบบถาวร—เหมาะสำหรับแอปพลิเคชันที่มีปริมาณการใช้งานสูงและสามารถคาดการณ์ได้ การชำระเงินแบบตามการใช้งาน (pay-as-you-go) ด้วย USD ช่วยให้คุณเติมเงินในบัญชีด้วยเงินดอลลาร์และใช้เครดิตได้ตามต้องการ เหมาะอย่างยิ่งสำหรับการทดลองและปริมาณงานที่เปลี่ยนแปลงได้
การเข้าถึง API ยังคงฟรีในช่วงเบต้า สิ่งนี้ช่วยให้คุณสามารถตรวจสอบรูปแบบการผสานรวมและประมาณการค่าใช้จ่ายก่อนที่จะตัดสินใจเลือกวิธีการชำระเงิน ตรวจสอบแดชบอร์ดการใช้งานของคุณเพื่อติดตามการใช้โทเค็นในเอนด์พอยต์และโมเดลต่างๆ
แนวทางการเลือกโมเดล
เลือกโมเดลตามความต้องการด้านความสามารถและข้อจำกัดด้านเวลาแฝง เริ่มต้นด้วย qwen3-4b สำหรับการสร้างต้นแบบและคำถามง่ายๆ—มันตอบสนองได้รวดเร็วและจัดการงานสร้างข้อความส่วนใหญ่ได้เพียงพอ อัปเกรดเป็นโมเดลขนาดใหญ่ขึ้น เช่น llama-3.3-70b หรือ deepseek-ai-DeepSeek-R1 เมื่อคุณต้องการการให้เหตุผลขั้นสูง การสร้างโค้ด หรือการทำตามคำสั่งที่ซับซ้อน งาน Vision ต้องการโมเดลหลายโมดัล เช่น qwen3-vl-235b-a22b การสร้างเสียงใช้โมเดลเสียงพูดเฉพาะทาง สอบถามเอนด์พอยต์ /api/v1/models โดยทางโปรแกรมเพื่อตรวจสอบความพร้อมใช้งานแบบเรียลไทม์—Venice จะหมุนเวียนโมเดลตามความต้องการและความจุของโครงสร้างพื้นฐาน
สรุป
Venice API ช่วยขจัดความยุ่งยากจากการผสานรวม AI คุณจะได้รับความเข้ากันได้กับ OpenAI โดยไม่ต้องถูกผูกมัด ได้ความเป็นส่วนตัวโดยไม่มีความซับซ้อนในการกำหนดค่า และราคาที่ยืดหยุ่นโดยไม่มีค่าใช้จ่ายที่ไม่คาดคิด วิธีการแทนที่แบบทันทีหมายความว่าคุณสามารถประเมิน Venice ควบคู่ไปกับผู้ให้บริการปัจจุบันของคุณโดยไม่ต้องเขียนโค้ดแอปพลิเคชันใหม่
เมื่อสร้างการผสานรวม API—ไม่ว่าจะเป็นการทดสอบเอนด์พอยต์ของ Venice การดีบักโฟลว์การรับรองความถูกต้อง หรือการจัดการการกำหนดค่าผู้ให้บริการหลายราย—ใช้ Apidog เพื่อปรับปรุงเวิร์กโฟลว์ของคุณให้มีประสิทธิภาพ มันจัดการการทดสอบ API แบบภาพ การสร้างเอกสาร และการทำงานร่วมกันของทีม เพื่อให้คุณสามารถมุ่งเน้นไปที่การส่งมอบฟังก์ชันการทำงานได้