E se você pudesse trocar de provedor de IA sem reescrever uma única linha de código? A Venice API oferece exatamente isso: endpoints compatíveis com OpenAI com retenção de dados zero, opções de modelo não censuradas e uma arquitetura que prioriza a privacidade que você controla.
A maioria das APIs de IA o força a usar SDKs específicos do fornecedor, retém seus dados para treinamento de modelos e cobra taxas premium por recursos básicos. Você reescreve seu aplicativo ao trocar de provedor. Seus prompts treinam modelos concorrentes. Seus custos escalam de forma imprevisível.
A Venice API elimina esses pontos de atrito. Ela espelha exatamente a estrutura da API da OpenAI, basta mudar a URL base e seu código existente funciona imediatamente. Seus dados permanecem privados. Você escolhe entre vários modelos de pagamento, incluindo staking de cripto e créditos USD pay-as-you-go.
Quer uma plataforma integrada e completa para sua equipe de desenvolvedores trabalhar em conjunto com máxima produtividade?
Apidog entrega todas as suas demandas e substitui o Postman por um preço muito mais acessível!
Gerando sua Chave de API da Venice
1. Navegue até venice.ai/settings/api.
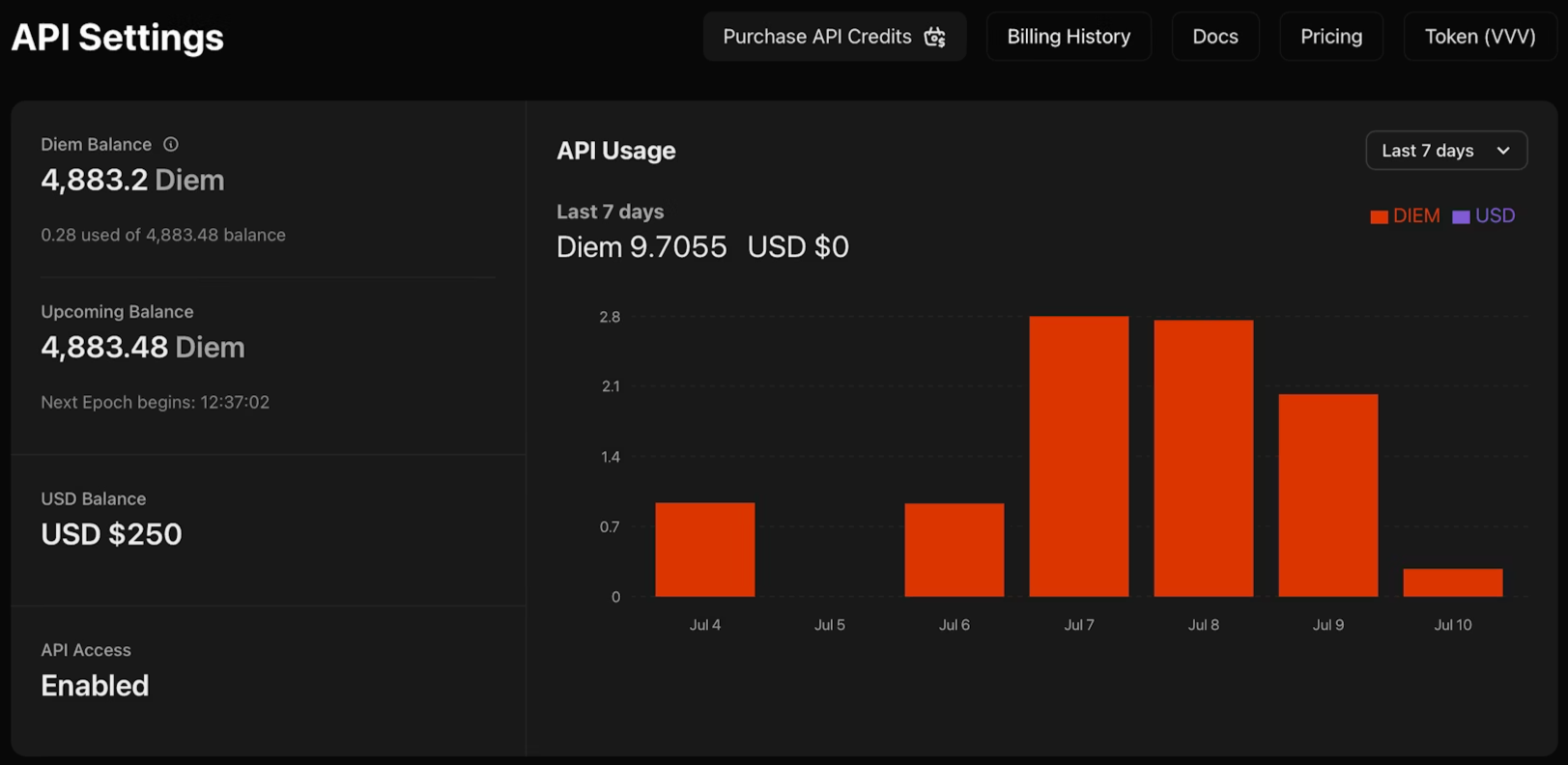
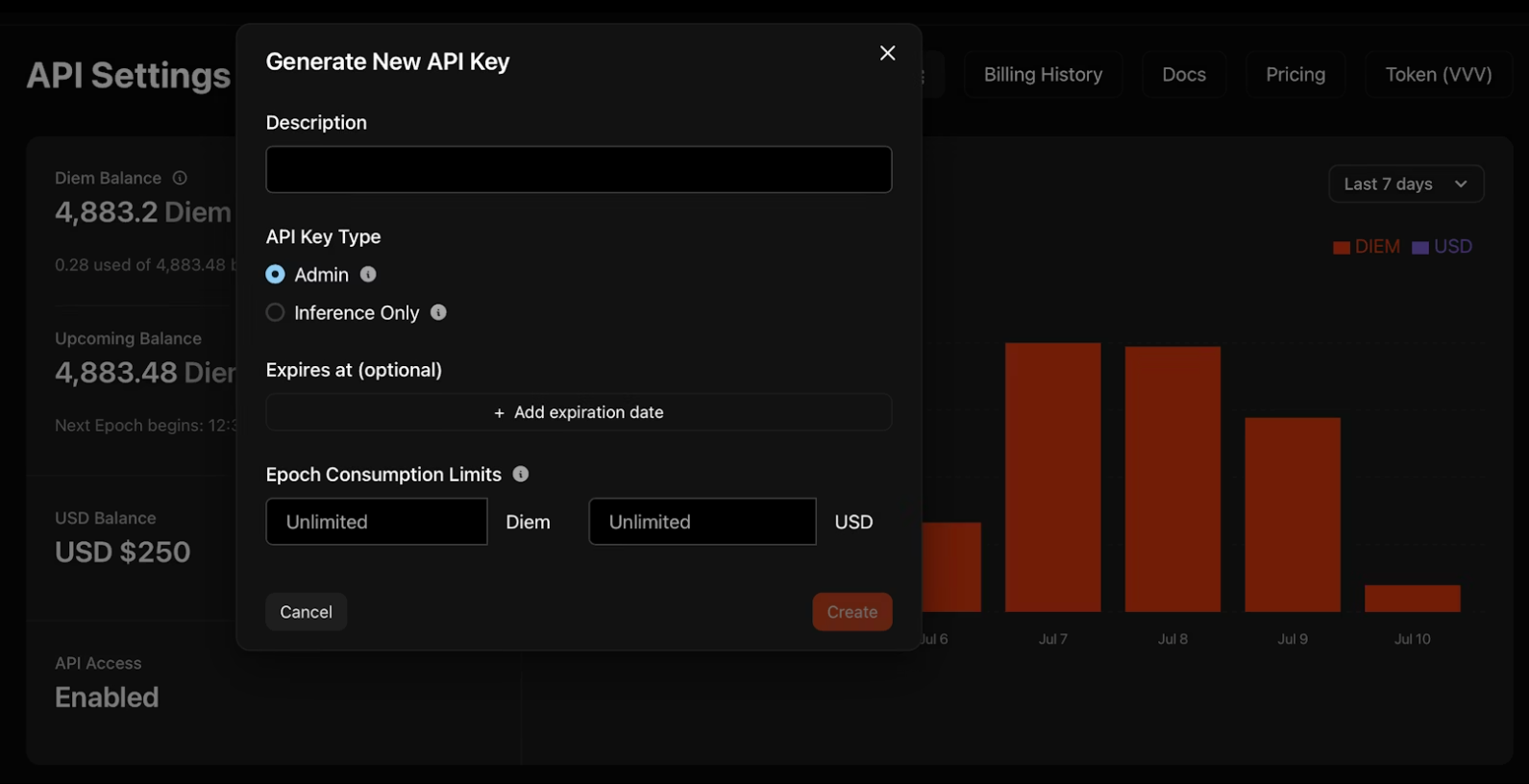
2. Clique em "Gerar Nova Chave de API" e configure suas credenciais:
- Descrição: Nomeie sua chave para organização
- Tipo: Chaves de administrador gerenciam outras chaves programaticamente; chaves somente de inferência executam modelos exclusivamente
- Expiração: Data opcional em que a chave é desativada automaticamente
- Limites de Consumo: Limites diários de Diem ou USD para controlar os gastos
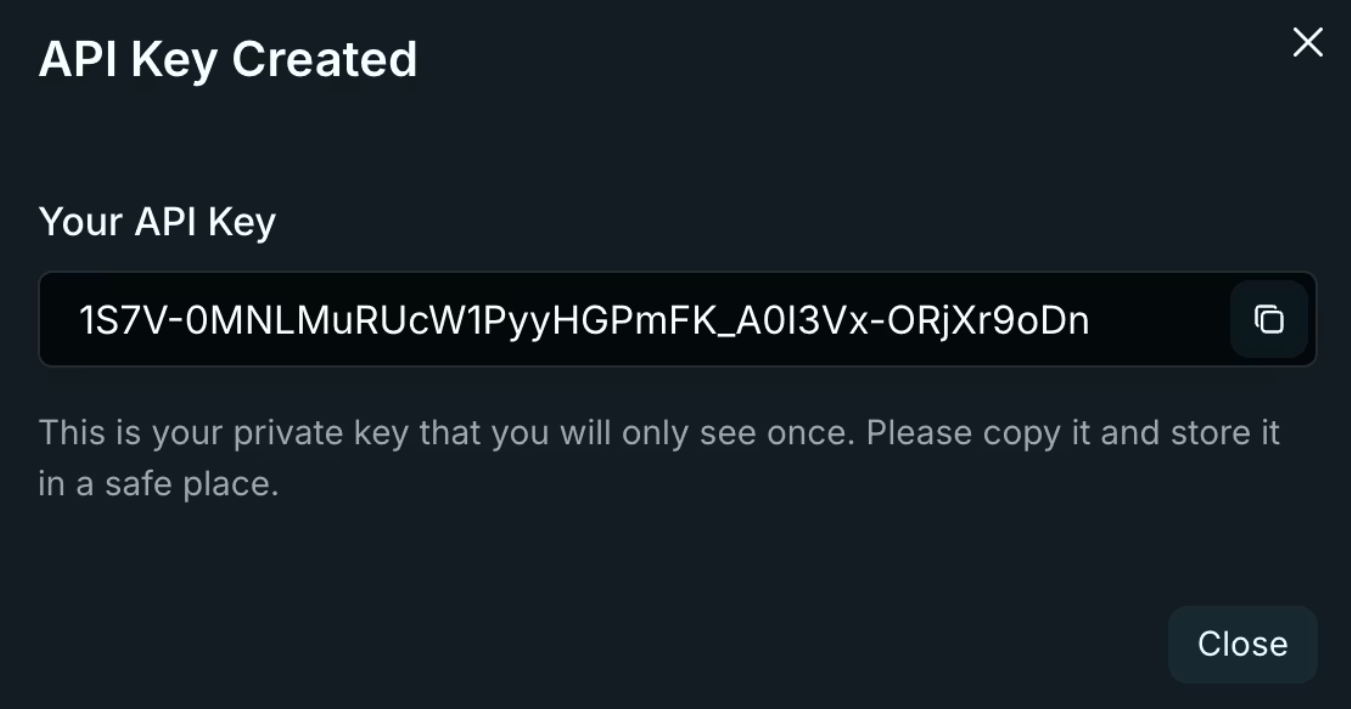
3. Copie sua chave imediatamente. A Venice a exibe apenas uma vez! Armazene-a em variáveis de ambiente, nunca em repositórios de código.
export VENICE_API_KEY="sua-chave-aqui"
Considerações de Segurança da Chave
As chaves de administrador fornecem amplo acesso à sua conta Venice. Trate-as como credenciais de root — use-as para scripts de rotação de chaves e gerenciamento de equipe, nunca em código de aplicativo. As chaves somente de inferência restringem as operações à execução de modelos, limitando a exposição se vazarem. Gire as chaves trimestralmente usando os logs de atividade do painel para identificar credenciais obsoletas.
Autenticação e Configuração Base da API da Venice
A Venice usa autenticação padrão de token Bearer. Cada requisição exige dois cabeçalhos:
Authorization: Bearer $VENICE_API_KEY
Content-Type: application/json
A URL base segue exatamente o padrão da OpenAI:
import openai
import os
client = openai.OpenAI(
api_key=os.getenv("VENICE_API_KEY"),
base_url="https://api.venice.ai/api/v1"
)
Essa única alteração de configuração roteia todas as suas chamadas existentes do SDK da OpenAI através da infraestrutura da Venice. Sem alterações de método. Sem reescritas de parâmetros. Seu código funciona imediatamente.
Compatibilidade de SDK
A Venice mantém compatibilidade com os SDKs oficiais da OpenAI para Python, TypeScript, Go, PHP, C#, Java e Swift. Bibliotecas de terceiros construídas na especificação da OpenAI também funcionam sem modificação. Teste sua base de código existente contra a Venice alterando apenas a URL base e a chave de API — se você usa preenchimentos de chat padrão, streaming ou chamada de função, a migração leva minutos.
Migrando da OpenAI
A migração requer três alterações: URL base, chave de API e nome do modelo. Substitua `https://api.openai.com/v1` por `https://api.venice.ai/api/v1`. Troque sua chave de API da OpenAI pela sua chave Venice. Altere os identificadores de modelo de `gpt-4` ou `gpt-3.5-turbo` para equivalentes Venice como `qwen3-4b`. Teste completamente antes da implantação em produção. Verifique se as respostas de streaming são processadas corretamente. Confirme se os esquemas de chamada de função são validados. Verifique se os parâmetros de geração de imagem correspondem aos seus requisitos. A camada de compatibilidade da Venice lida com a maioria dos casos extremos, mas existem diferenças sutis na formatação de mensagens de erro e nos cabeçalhos de limite de taxa.
Dica Profissional: Teste todos os seus endpoints de API completamente com Apidog.
Endpoints e Recursos Principais da API da Venice
A Venice oferece nove endpoints distintos cobrindo geração de texto, imagem, áudio e vídeo:
Geração de Texto
/api/v1/chat/completions- IA conversacional com suporte a streaming/api/v1/embeddings/generate- Embeddings vetoriais para aplicações RAG
Processamento de Imagem
/api/v1/image/generate- Geração de texto para imagem/api/v1/image/upscale- Aprimoramento de resolução/api/v1/image/edit- Inpainting e modificação impulsionados por IA
Áudio
/api/v1/audio/speech- Síntese de texto para fala/api/v1/audio/transcriptions- Conversão de fala para texto
Vídeo e Personagens
/api/v1/video/queue- Geração de texto/vídeo para vídeo/api/v1/characters/list- Gerenciamento de persona de IA
Cada endpoint mantém formatos de requisição/resposta compatíveis com OpenAI, quando aplicável. Você reutiliza a lógica de análise existente.
Estratégia de Seleção de Endpoint
Correlacione os endpoints com a complexidade do seu caso de uso. As conclusões de chat atendem à maioria das necessidades de geração de texto. Adicione embeddings para pesquisa semântica ou pipelines RAG. Use os endpoints de imagem para fluxos de trabalho criativos ou moderação de conteúdo. Os endpoints de áudio permitem recursos de acessibilidade ou interfaces de voz. Comece com um endpoint, valide sua integração e, em seguida, expanda para fluxos de trabalho multimodais.
Trabalhando com Respostas de Streaming
O streaming reduz a latência percebida para aplicativos de chat. A Venice usa Server-Sent Events (SSE) idênticos à implementação da OpenAI. Processe o conteúdo parcial à medida que ele chega, em vez de esperar por respostas completas. Lide com o término do stream verificando mensagens `[DONE]`. Implemente lógica de reconexão para streams interrompidos — armazene o histórico da conversa no lado do cliente e tente novamente as requisições falhas. Monitore o uso de tokens em pedaços de stream para rastrear os custos em tempo real.
Parâmetros Específicos da API da Venice
Além dos parâmetros padrão da OpenAI, a Venice adiciona controles de capacidade através do objeto venice_parameters:
{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Últimos desenvolvimentos de IA?"}],
"venice_parameters": {
"enable_web_search": "on",
"enable_web_citations": true,
"strip_thinking_response": false
}
}
Integração de Pesquisa Web
Defina `enable_web_search` para `auto`, `on` ou `off`. O modo auto permite que o modelo decida quando as informações atuais melhoram as respostas. Force `on` para consultas em tempo real sobre eventos recentes ou tecnologias em rápida mudança. Emparelhe com `enable_web_citations` para retornar URLs de origem — essencial para ferramentas de pesquisa e verificação factual.
Controle de Raciocínio
Modelos de raciocínio como DeepSeek R1 mostram o pensamento passo a passo por padrão. Defina `strip_thinking_response` como `true` para retornar apenas as respostas finais, reduzindo o consumo de tokens. Use `disable_thinking` para ignorar o raciocínio completamente para consultas simples.
Sintaxe Alternativa
Passe parâmetros via sufixo do modelo para requisições concisas:
model="qwen3-4b:enable_web_search=on&enable_web_citations=true"
Hierarquia de Parâmetros
Os parâmetros específicos da Venice substituem os padrões, mas respeitam as configurações explícitas. Se você especificar `temperature: 0.5` no objeto raiz e `enable_web_search: on` em `venice_parameters`, ambos se aplicam simultaneamente. Teste as combinações de parâmetros isoladamente antes de implantar em produção — alguns parâmetros interagem de forma imprevisível com certos modelos.
Exemplos Práticos de Implementação ao Usar a API da Venice
Conclusão Básica de Chat
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Explique provas de conhecimento zero"}],
"stream": true
}'
O streaming funciona de forma idêntica ao OpenAI — processe os chunks SSE à medida que chegam.
Chamada de Função
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Clima em Tóquio?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obter clima para a localização",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
}]
}'
Os modelos da Venice suportam chamadas de função paralelas e aplicação de esquema, assim como a implementação da OpenAI.
Geração de Imagem
curl --request POST \
--url https://api.venice.ai/api/v1/image/generate \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "venice-sd35",
"prompt": "Paisagem urbana cyberpunk à noite, reflexos de néon",
"aspect_ratio": "16:9",
"resolution": "2K",
"hide_watermark": true
}'
As proporções de aspecto disponíveis incluem 1:1, 4:3, 16:9 e 21:9. As opções de resolução são 1K e 2K.
Aprimoramento de Imagem
curl --request POST \
--url https://api.venice.ai/api/v1/image/upscale \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "upscale-sd35",
"image": "base64encodedimage..."
}'
Análise de Visão
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-vl-235b-a22b",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "Qual estilo arquitetônico é este?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}'
Passe imagens como URIs de dados base64 ou URLs HTTPS. Modelos de visão aceitam várias imagens por mensagem para tarefas de comparação.
Síntese de Áudio
curl --request POST \
--url https://api.venice.ai/api/v1/audio/speech \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "tts-kokoro",
"input": "Bem-vindo à API da Venice",
"voice": "af_sky",
"response_format": "mp3"
}'
As opções de voz usam prefixos: `af_` (mulher americana), `am_` (homem americano) e padrões semelhantes para outros sotaques.
Padrões de Tratamento de Erros
A Venice retorna códigos de status HTTP padrão. 401 indica falhas de autenticação — verifique sua chave de API e cabeçalhos. 429 sinaliza limitação de taxa; implemente um recuo exponencial começando em 1 segundo. Erros 500 sugerem problemas temporários de infraestrutura; tente novamente após 5 segundos. Analise as respostas de erro para mensagens específicas — a Venice inclui motivos detalhados de falha no corpo da resposta.
Privacidade e Arquitetura de Dados da API da Venice
A política de retenção zero de dados da Venice opera através da arquitetura técnica, não apenas de promessas legais. Seu navegador armazena o histórico da conversa localmente usando IndexedDB. Os servidores da Venice processam os prompts em GPUs que veem apenas a requisição atual — sem histórico de conversa, sem metadados de identidade do usuário, sem informações da chave de API.
Após gerar uma resposta, os servidores descartam o prompt e a saída imediatamente. Nada persiste em disco ou logs. Seus dados nunca treinam modelos. Isso difere fundamentalmente dos serviços centralizados que retêm dados para detecção de abuso e melhoria do modelo.
Para privacidade adicional, a Venice hospeda a maioria dos modelos em infraestrutura privada, em vez de depender de provedores terceirizados. Opções não censuradas são executadas em hardware controlado pela Venice, garantindo nenhuma filtragem ou registro externo.
Verificação do Fluxo de Dados
Audite as alegações de privacidade da Venice monitorando o tráfego de rede. As requisições de API vão diretamente para `api.venice.ai` com criptografia TLS. Não há scripts de análise de terceiros carregados na documentação. Os cabeçalhos de resposta não mostram diretivas de cache — confirmando a não retenção no lado do servidor. Para aplicativos sensíveis, implemente criptografia no lado do cliente antes de enviar prompts, embora isso impeça o modelo de entender o conteúdo.
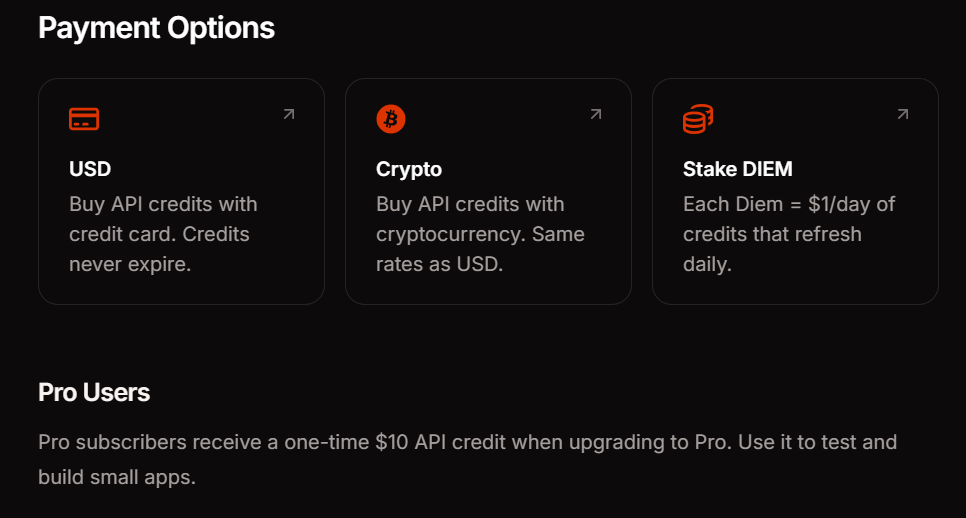
Opções de Preços e Pagamento da API da Venice
A Venice oferece três métodos de pagamento para corresponder aos seus padrões de uso. A assinatura Pro custa US$ 18 mensais e inclui US$ 10 em créditos de API mais prompts ilimitados em recursos de consumo. O staking de DIEM exige a compra de tokens VVV que fornecem alocações diárias permanentes de computação — ideal para aplicações de alto volume com tráfego previsível. O pagamento por uso em USD permite que você financie sua conta com dólares e consuma créditos conforme necessário, perfeito para experimentação e cargas de trabalho variáveis.
O acesso à API atualmente permanece gratuito durante a fase beta. Isso permite validar padrões de integração e estimar custos antes de se comprometer com um método de pagamento. Monitore seu painel de uso para rastrear o consumo de tokens em endpoints e modelos.
Diretrizes de Seleção de Modelo
Escolha modelos com base nos requisitos de capacidade e restrições de latência. Comece com `qwen3-4b` para prototipagem e consultas simples — ele responde rapidamente e lida adequadamente com a maioria das tarefas de geração de texto. Atualize para modelos maiores como `llama-3.3-70b` ou `deepseek-ai-DeepSeek-R1` quando precisar de raciocínio avançado, geração de código ou seguir instruções complexas. Tarefas de visão requerem modelos multimodais como `qwen3-vl-235b-a22b`. A geração de áudio usa modelos de fala especializados. Consulte o endpoint `/api/v1/models` programaticamente para verificar a disponibilidade em tempo real — a Venice rotaciona os modelos com base na demanda e capacidade da infraestrutura.
Conclusão
A API da Venice remove o atrito da integração de IA. Você obtém compatibilidade com OpenAI sem o aprisionamento, privacidade sem a complexidade de configuração e preços flexíveis sem contas surpresa. A abordagem de substituição direta significa que você pode avaliar a Venice ao lado de seu provedor atual sem reescrever o código do aplicativo.
Ao construir integrações de API — seja testando endpoints da Venice, depurando fluxos de autenticação ou gerenciando múltiplas configurações de provedores — use Apidog para otimizar seu fluxo de trabalho. Ele lida com testes visuais de API, geração de documentação e colaboração em equipe para que você possa se concentrar na entrega de recursos.