
Executar um LLM em sua máquina local tem várias vantagens. Primeiro, isso oferece controle total sobre seus dados, garantindo que a privacidade seja mantida. Em segundo lugar, você pode experimentar sem se preocupar com chamadas de API caras ou assinaturas mensais. Além disso, as implementações locais proporcionam uma maneira prática de aprender como esses modelos funcionam por trás das cortinas.
Além disso, quando você executa LLMs localmente, evita possíveis problemas de latência de rede e a dependência de serviços em nuvem. Isso significa que você pode construir, testar e iterar mais rapidamente, especialmente se estiver trabalhando em projetos que requerem uma integração estreita com sua base de código.
Entendendo LLMs: Uma Visão Rápida
Antes de mergulharmos nas nossas principais opções, vamos tocar brevemente no que é um LLM. Em termos simples, um modelo de linguagem grande (LLM) é um modelo de IA que foi treinado em vastas quantidades de dados textuais. Esses modelos aprendem os padrões estatísticos na linguagem, o que lhes permite gerar texto semelhante ao humano com base nos prompts que você fornece.
Os LLMs estão no cerne de muitas aplicações de IA modernas. Eles alimentam chatbots, assistentes de escrita, geradores de código e até agentes conversacionais sofisticados. No entanto, executar esses modelos — especialmente os maiores — pode ser intensivo em recursos. É por isso que ter uma ferramenta confiável para executá-los localmente é tão importante.
Usando ferramentas locais de LLM, você pode experimentar com esses modelos sem enviar seus dados para servidores remotos. Isso pode aumentar tanto a segurança quanto o desempenho. Ao longo deste tutorial, você notará que a palavra-chave “LLM” é enfatizada enquanto exploramos como cada ferramenta ajuda você a aproveitar esses poderosos modelos em seu próprio hardware.
Ferramenta #1: Llama.cpp
Llama.cpp é indiscutivelmente uma das ferramentas mais populares quando se trata de executar LLMs localmente. Criada por Georgi Gerganov e mantida por uma comunidade vibrante, esta biblioteca C/C++ é projetada para fazer inferência em modelos como LLaMA e outros com dependências mínimas.

Por que você vai adorar o Llama.cpp
- Leve e Rápido: Llama.cpp é projetado para velocidade e eficiência. Com configuração mínima, você pode executar modelos complexos mesmo em hardware modesto. Ele aproveita instruções avançadas da CPU, como AVX e Neon, significando que você obtém o máximo do desempenho do seu sistema.
- Suporte a Hardware Versátil: Se você está usando uma máquina x86, um dispositivo baseado em ARM ou até mesmo um Mac com Apple Silicon, o Llama.cpp tem suporte para você.
- Flexibilidade de Linha de Comando: Se você prefere o terminal em vez de interfaces gráficas, as ferramentas de linha de comando do Llama.cpp tornam simples carregar modelos e gerar respostas diretamente do seu shell.
- Comunidade e Código Aberto: Como um projeto de código aberto, ele se beneficia de contribuições contínuas e melhorias por desenvolvedores em todo o mundo.
Como Começar
- Instalação: Clone o repositório do GitHub e compile o código em sua máquina.
- Configuração do Modelo: Baixe seu modelo preferido (por exemplo, uma variante LLaMA quantizada) e use as utilidades de linha de comando fornecidas para iniciar a inferência.
- Personalização: Ajuste parâmetros como comprimento do contexto, temperatura e tamanho do feixe para ver como a saída do modelo varia.
Por exemplo, um comando simples pode parecer assim:
./main -m ./models/llama-7b.gguf -p "Me conte uma piada sobre programação" --temp 0.7 --top_k 100
Esse comando carrega o modelo e gera texto com base no seu prompt. A simplicidade dessa configuração é um grande ponto positivo para qualquer um que está começando com a inferência local de LLM.
Transicionando suavemente do Llama.cpp, vamos explorar outra ferramenta fantástica que adota uma abordagem ligeiramente diferente.
Ferramenta #2: GPT4All
GPT4All é um ecossistema de código aberto projetado pela Nomic AI que democratiza o acesso a LLMs. Um dos aspectos mais empolgantes do GPT4All é que ele é construído para rodar em hardware de consumo, seja em uma CPU ou uma GPU. Isso o torna perfeito para desenvolvedores que querem experimentar sem precisar de máquinas caras.
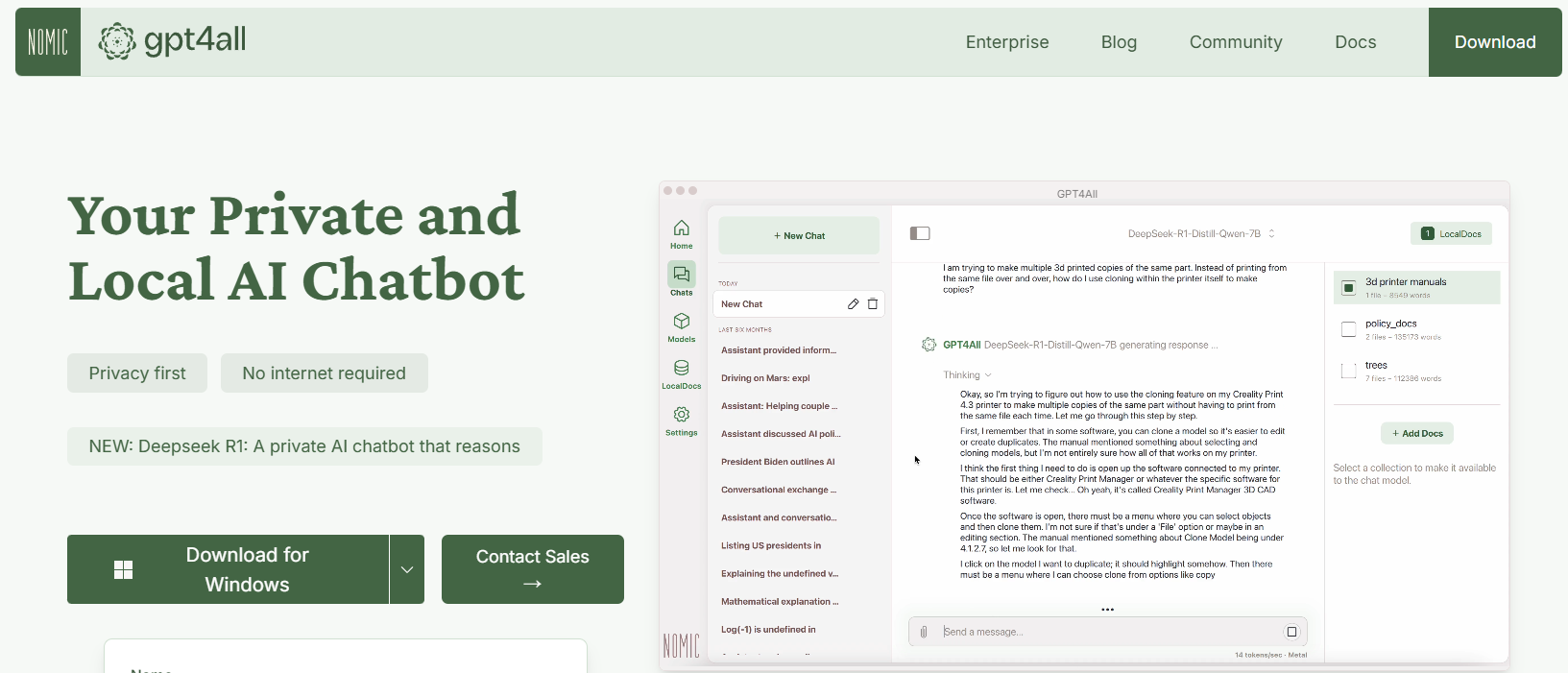
Principais Características do GPT4All
- A abordagem Local-Primeiro: O GPT4All é construído para rodar totalmente no seu dispositivo local. Isso significa que nenhum dado nunca sai da sua máquina, garantindo privacidade e tempos de resposta rápidos.
- Amigável ao Usuário: Mesmo se você é novo em LLMs, o GPT4All vem com uma interface simples e intuitiva que permite interagir com o modelo sem uma profunda expertise técnica.
- Leve e Eficiente: Os modelos no ecossistema GPT4All são otimizados para desempenho. Você pode executá-los em seu laptop, tornando-os acessíveis a um público mais amplo.
- Abertura e Orientação da Comunidade: Com sua natureza de código aberto, o GPT4All convida contribuições da comunidade, garantindo que ele permaneça atualizado com as últimas inovações.
Iniciando com GPT4All
- Instalação: Você pode baixar o GPT4All do seu site. O processo de instalação é simples, e binários pré-compilados estão disponíveis para Windows, macOS e Linux.
- Executando o Modelo: Uma vez instalado, basta iniciar o aplicativo e escolher entre uma variedade de modelos pré-ajustados. A ferramenta até oferece uma interface de chat, que é perfeita para experimentação casual.
- Personalização: Ajuste parâmetros como o comprimento da resposta do modelo e as configurações de criatividade para ver como a saída muda. Isso ajuda você a entender como os LLMs funcionam em diferentes condições.
Por exemplo, você pode digitar um prompt como:
Quais são alguns fatos divertidos sobre inteligência artificial?
E o GPT4All gerará uma resposta amigável e perspicaz — tudo isso sem precisar de conexão com a internet.
Ferramenta #3: LM Studio
Seguindo em frente, LM Studio é outra ferramenta excelente para executar LLMs localmente, particularmente se você está procurando uma interface gráfica que torna o gerenciamento de modelos muito fácil.
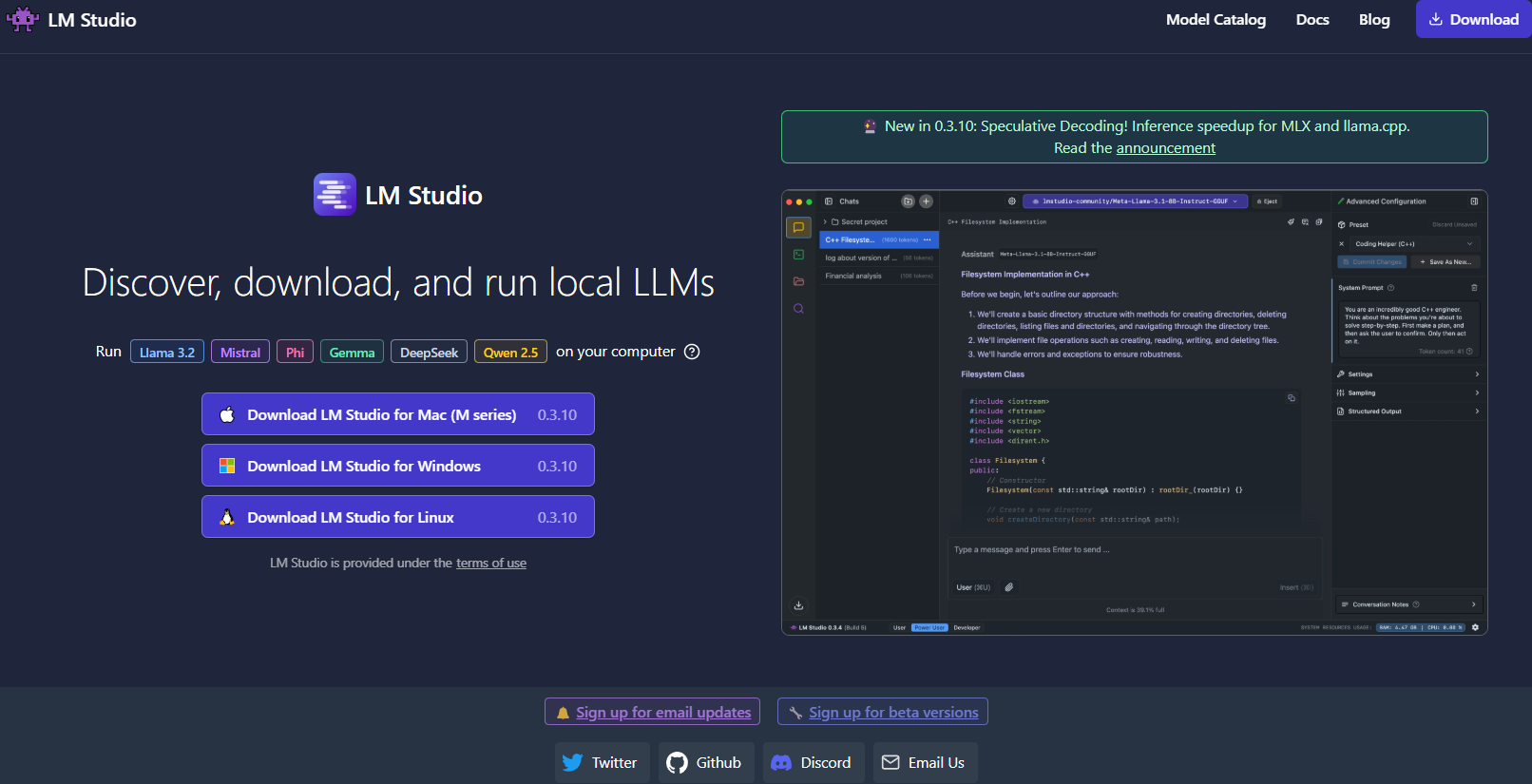
O que diferencia o LM Studio?
- Interface Intuitiva: O LM Studio fornece um aplicativo desktop elegante e amigável. Isso é ideal para aqueles que preferem não trabalhar apenas na linha de comando.
- Gerenciamento de Modelos: Com o LM Studio, você pode facilmente navegar, baixar e alternar entre diferentes LLMs. O aplicativo possui filtros e funcionalidades de busca embutidos, para que você possa encontrar o modelo perfeito para seu projeto.
- Configurações Personalizáveis: Ajuste parâmetros como temperatura, tokens máximos e janela de contexto diretamente da interface. Esse feedback imediato é perfeito para aprender como diferentes configurações afetam o comportamento do modelo.
- Compatibilidade Multiplataforma: O LM Studio funciona em Windows, macOS e Linux, tornando-o acessível a uma ampla variedade de usuários.
- Servidor de Inferência Local: Desenvolvedores também podem aproveitar seu servidor HTTP local, que imita a API da OpenAI. Isso torna a integração das capacidades de LLM em suas aplicações muito mais simples.
Como Configurar o LM Studio
- Download e Instalação: Acesse o site do LM Studio, baixe o instalador para o seu sistema operacional e siga as instruções de configuração.
- Inicie e Explore: Abra o aplicativo, explore a biblioteca de modelos disponíveis e selecione um que atenda às suas necessidades.
- Experimente: Use a interface de chat embutida para interagir com o modelo. Você também pode experimentar com múltiplos modelos simultaneamente para comparar desempenho e qualidade.
Imagine que você está trabalhando em um projeto de escrita criativa; a interface do LM Studio facilita a troca entre modelos e o ajuste da saída em tempo real. Seu feedback visual e facilidade de uso fazem dele uma escolha sólida para quem está começando ou para profissionais que precisam de uma solução local robusta.
Ferramenta #4: Ollama
Em seguida, temos Ollama, uma poderosa, mas simples ferramenta de linha de comando com foco em simplicidade e funcionalidade. O Ollama foi projetado para ajudar você a executar, criar e compartilhar LLMs sem a complicação de configurações complexas.
Por que escolher o Ollama?
- Implantação Fácil de Modelos: O Ollama empacota tudo o que você precisa — pesos de modelos, configuração e até dados — em uma única unidade portátil conhecida como "Modelfile". Isso significa que você pode rapidamente baixar e executar um modelo com configuração mínima.
- Capacidades Multimodais: Ao contrário de algumas ferramentas que se concentram apenas em texto, o Ollama suporta entradas multimodais. Você pode fornecer tanto texto quanto imagens como prompts, e a ferramenta gerará respostas que levam ambos em consideração.
- Disponibilidade Multiplataforma: O Ollama está disponível para macOS, Linux e Windows. É uma ótima opção para desenvolvedores que trabalham em diferentes sistemas.
- Eficiência de Linha de Comando: Para aqueles que preferem trabalhar no terminal, o Ollama oferece uma interface de linha de comando limpa e eficiente que permite uma rápida implantação e interação.
- Atualizações Rápidas: A ferramenta é frequentemente atualizada por sua comunidade, garantindo que você esteja sempre trabalhando com as últimas melhorias e recursos.
Configurando o Ollama
1. Instalação: Acesse o site do Ollama e baixe o instalador para o seu sistema operacional. A instalação é tão simples quanto executar alguns comandos no seu terminal.
2. Execute um Modelo: Uma vez instalado, use um comando como:
ollama run llama3
Este comando fará o download automático do modelo Llama 3 (ou qualquer outro modelo suportado) e iniciará o processo de inferência.
3. Experimente com Multimodalidade: Tente executar um modelo que suporte imagens. Por exemplo, se você tiver um arquivo de imagem pronto, pode arrastá-lo e soltá-lo em seu prompt (ou usar o parâmetro da API para imagens) para ver como o modelo responde.
O Ollama é particularmente atraente se você está procurando prototipar ou implantar LLMs localmente de forma rápida. Sua simplicidade não compromete o poder, tornando-o ideal tanto para iniciantes quanto para desenvolvedores experientes.
Ferramenta #5: Jan
Por último, mas não menos importante, temos Jan. Jan é uma plataforma local de código aberto que está ganhando popularidade entre aqueles que priorizam a privacidade dos dados e a operação offline. Sua filosofia é simples: permitir que os usuários executem poderosos LLMs completamente em seu próprio hardware, sem transferências de dados ocultas.
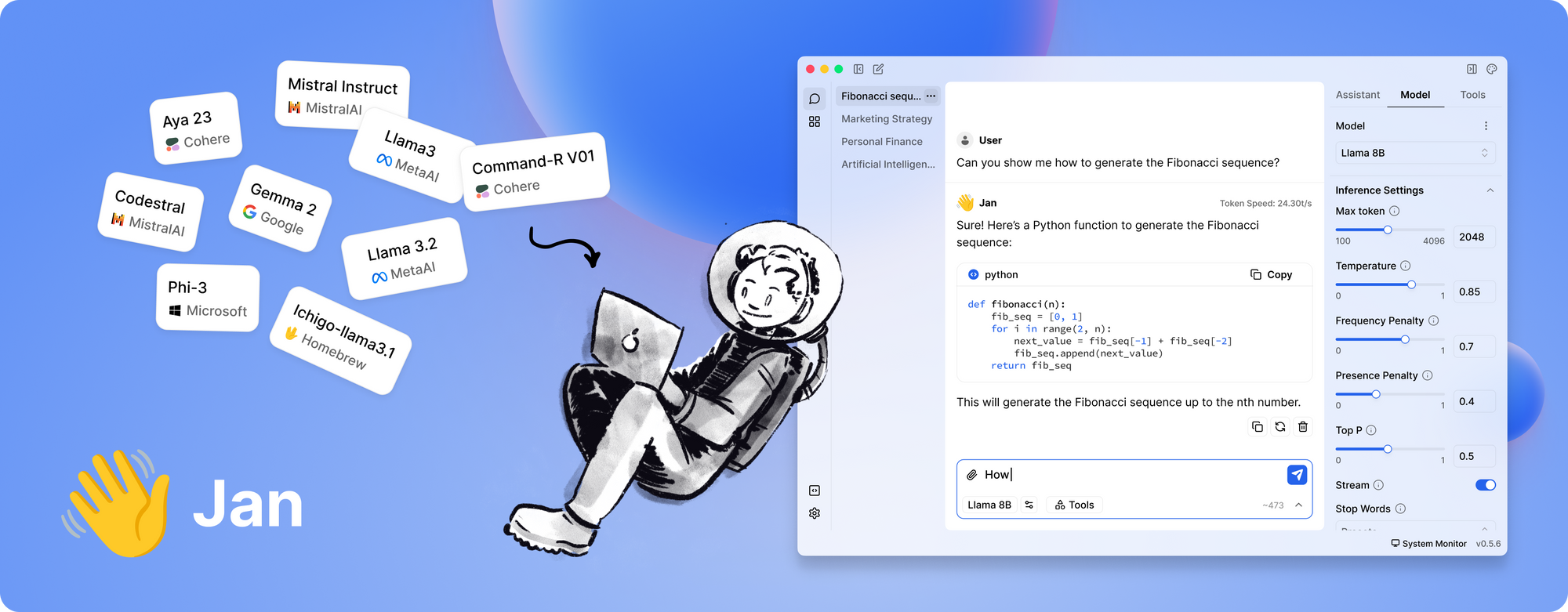
O que faz o Jan se destacar?
- Totalmente Offline: O Jan é projetado para operar sem uma conexão com a internet. Isso garante que todas as suas interações e dados permaneçam locais, aumentando a privacidade e segurança.
- Orientado ao Usuário e Extensível: A ferramenta oferece uma interface limpa e suporta uma estrutura de aplicativo/plugin. Isso significa que você pode facilmente estender suas capacidades ou integrá-lo com suas ferramentas existentes.
- Execução Eficiente de Modelos: O Jan é construído para lidar com uma variedade de modelos, incluindo aqueles ajustados para tarefas específicas. Ele é otimizado para ser executado mesmo em hardware modesto, sem comprometer o desempenho.
- Desenvolvimento Orientado pela Comunidade: Como muitas das ferramentas em nossa lista, o Jan é de código aberto e se beneficia de contribuições de uma comunidade dedicada de desenvolvedores.
- Sem Taxas de Assinatura: Ao contrário de muitas soluções baseadas em nuvem, o Jan é gratuito para uso. Isso o torna uma excelente escolha para startups, entusiastas e qualquer um que queira experimentar LLMs sem barreiras financeiras.
Como Começar com Jan
- Baixar e Instalar: Acesse o site oficial do Jan ou o repositório do GitHub. Siga as instruções de instalação, que são diretas e projetadas para fazer você iniciar rapidamente.
- Inicie e Personalize: Abra o Jan e escolha entre uma variedade de modelos pré-instalados. Se necessário, você pode importar modelos de fontes externas, como o Hugging Face.
- Experimente e Expanda: Use a interface de chat para interagir com seu LLM. Ajuste parâmetros, instale plugins e veja como o Jan se adapta ao seu fluxo de trabalho. Sua flexibilidade permite que você personalize sua experiência local com LLM às suas necessidades precisas.
Jan realmente incorpora o espírito da execução local de LLMs focada em privacidade. É perfeito para quem deseja uma ferramenta personalizável e sem complicações que mantém todos os dados em sua própria máquina.
Dica Profissional: Fluxo de Respostas de LLM Usando Depuração SSE
Se você está trabalhando com LLMs (Modelos de Linguagem Grande), a interação em tempo real pode melhorar bastante a experiência do usuário. Seja um chatbot entregando respostas ao vivo ou uma ferramenta de conteúdo atualizando dinamicamente à medida que os dados são gerados, o streaming é fundamental. Eventos Enviados pelo Servidor (SSE) oferecem uma solução eficiente para isso, permitindo que servidores enviem atualizações para os clientes por meio de uma única conexão HTTP. Ao contrário de protocolos bidirecionais como WebSockets, SSE é mais simples e direto, tornando-se uma ótima escolha para recursos em tempo real.
Depurar SSE pode ser desafiador. É aí que o Apidog entra. A função de depuração SSE do Apidog permite que você teste, monitore e solucione problemas de fluxos SSE com facilidade. Nesta seção, vamos explorar por que o SSE é importante para depurar APIs LLM e orientá-lo em um tutorial passo a passo sobre como usar o Apidog para configurar e testar conexões SSE.
Por que o SSE é importante para depurar APIs LLM
Antes de mergulharmos no tutorial, aqui está o porquê de o SSE ser uma ótima opção para depurar APIs LLM:
- Feedback em Tempo Real: SSE transmite dados à medida que são gerados, permitindo que os usuários vejam as respostas se desenrolarem naturalmente.
- Baixo Overhead: Ao contrário da consulta, o SSE usa uma única conexão persistente, minimizando o uso de recursos.
- Facilidade de Uso: SSE se integra perfeitamente a aplicativos da web, exigindo configuração mínima do lado do cliente.
Pronto para testar? Vamos configurar a depuração SSE no Apidog.
Tutorial Passo a Passo: Usando Depuração SSE no Apidog
Siga estas etapas para configurar e testar uma conexão SSE com o Apidog.
Passo 1: Criar um Novo Endpoint no Apidog
Crie um novo projeto HTTP no Apidog para testar e depurar solicitações de API. Adicione um endpoint com a URL do modelo de IA para o fluxo SSE — usando o DeepSeek neste exemplo. (DICA PROFISSIONAL: Clone o projeto de API do DeepSeek pronto do Hub de APIs do Apidog).
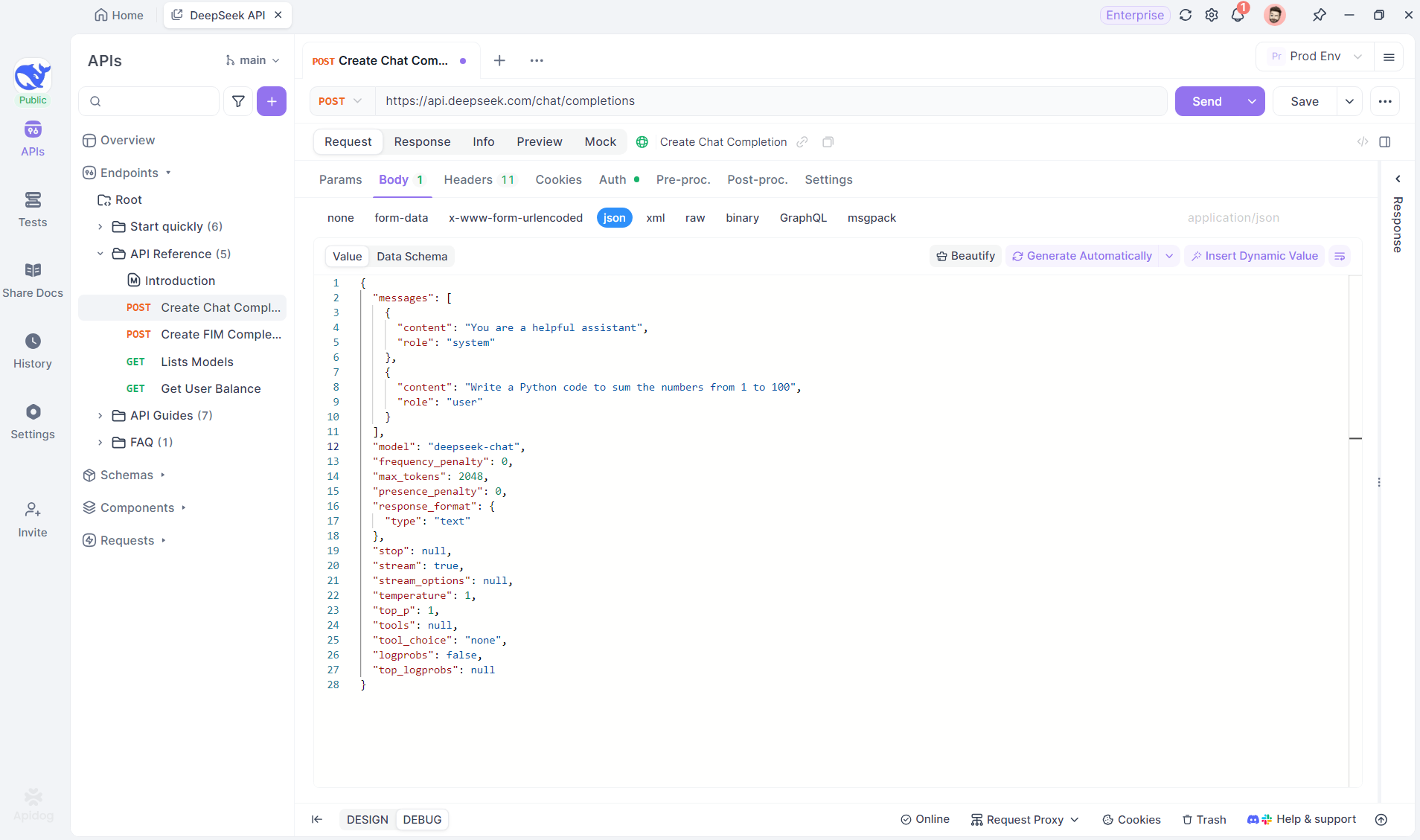
Passo 2: Enviar a Solicitação
Depois de adicionar o endpoint, clique em Enviar para enviar a solicitação. Se o cabeçalho da resposta incluir Content-Type: text/event-stream, o Apidog detectará o fluxo SSE, analisará os dados e os exibirá em tempo real.
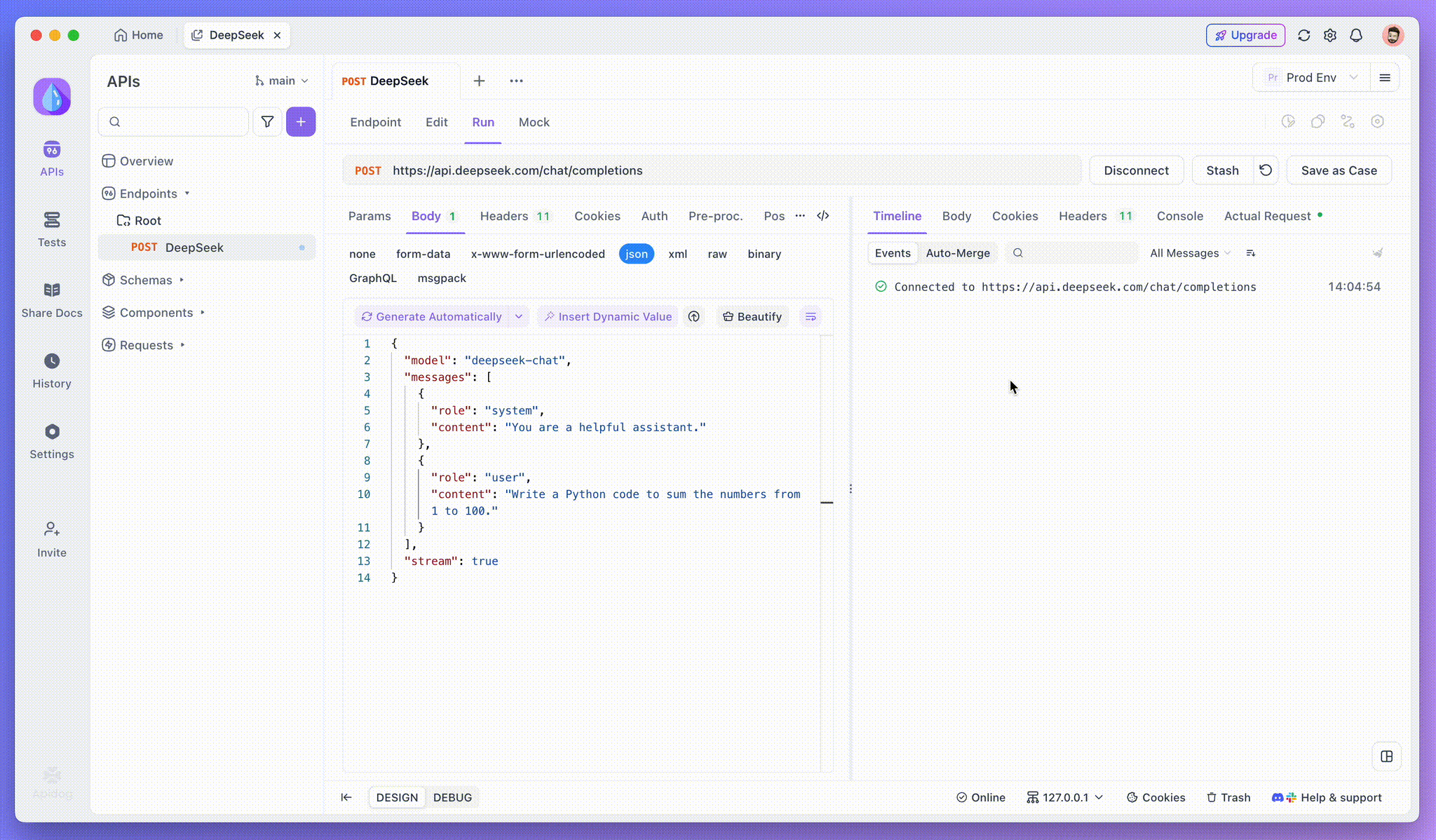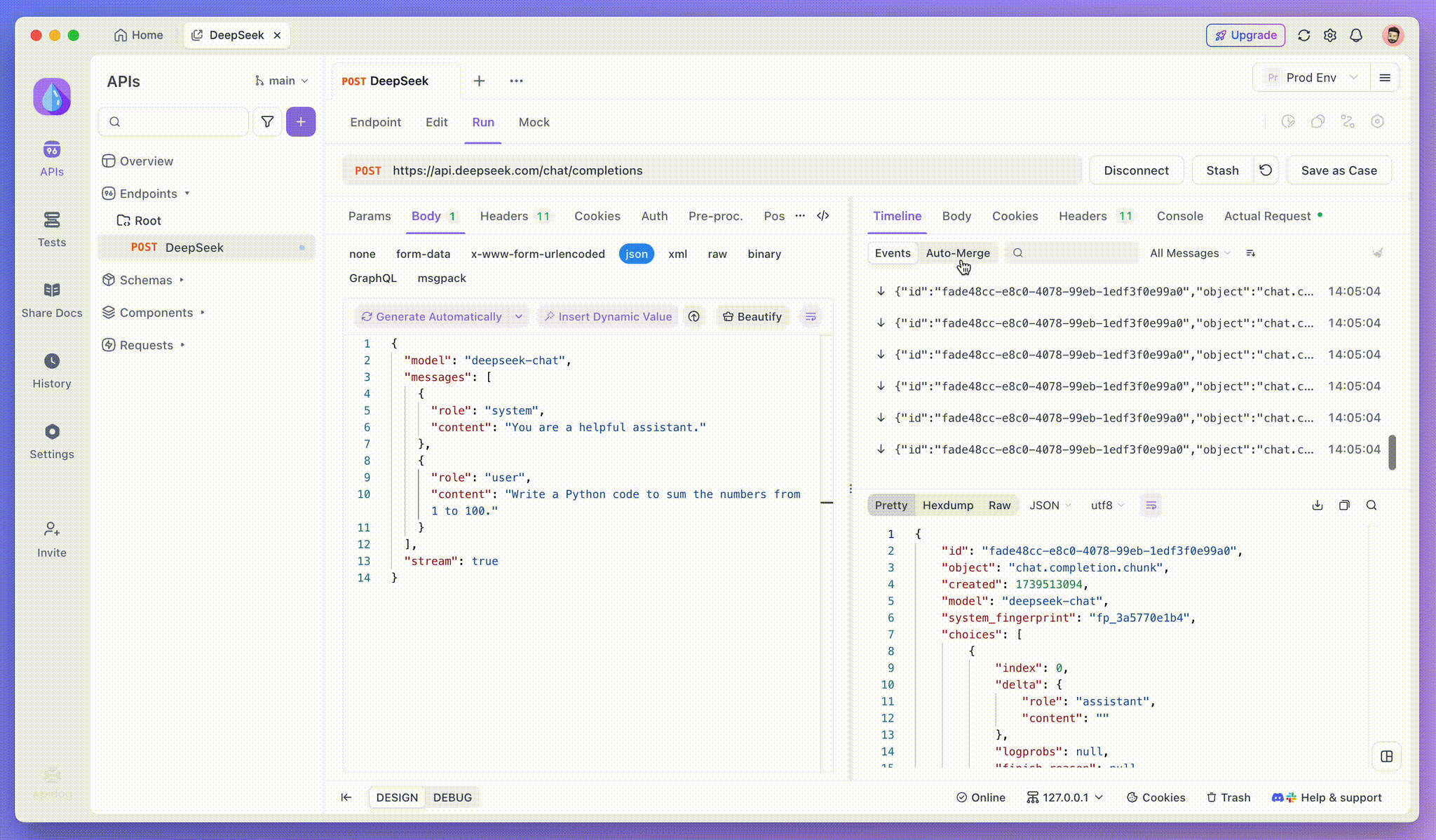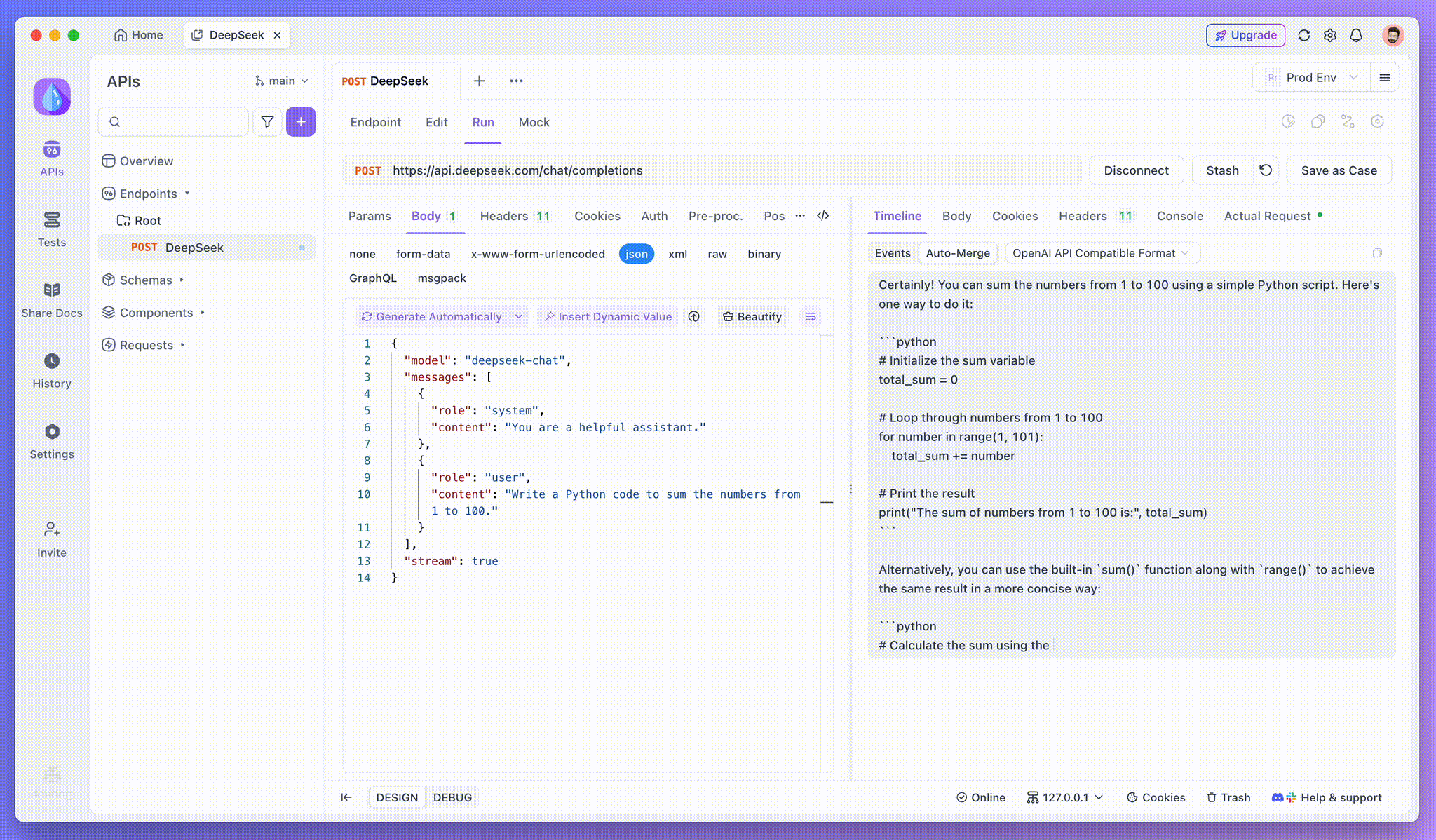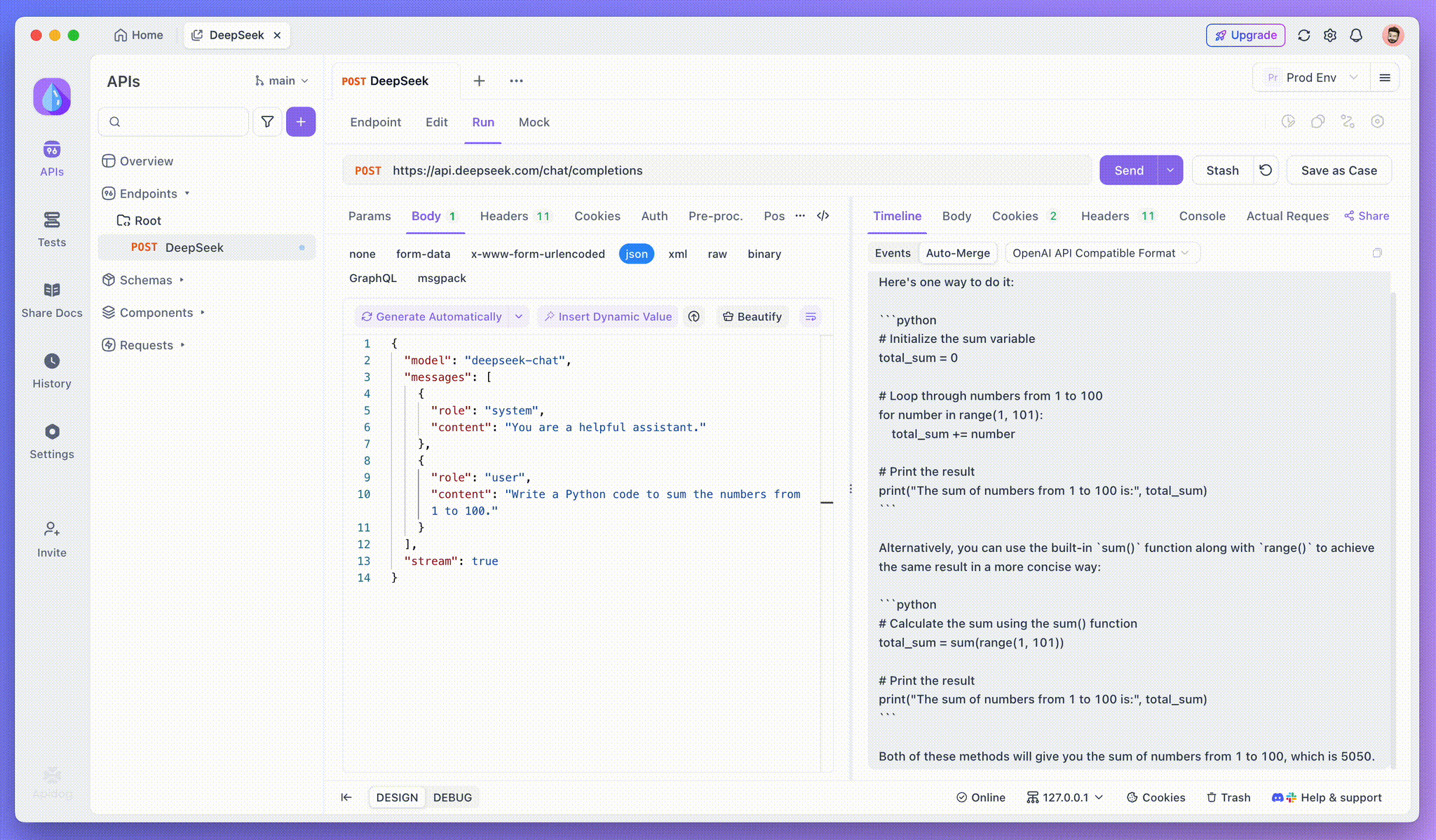
Passo 3: Ver Respostas em Tempo Real
A Visualização de Linha do Tempo do Apidog se atualiza em tempo real à medida que o modelo de IA transmite respostas, mostrando cada fragmento dinamicamente. Isso permite que você acompanhe o processo de pensamento da IA e obtenha insights sobre a geração de sua saída.
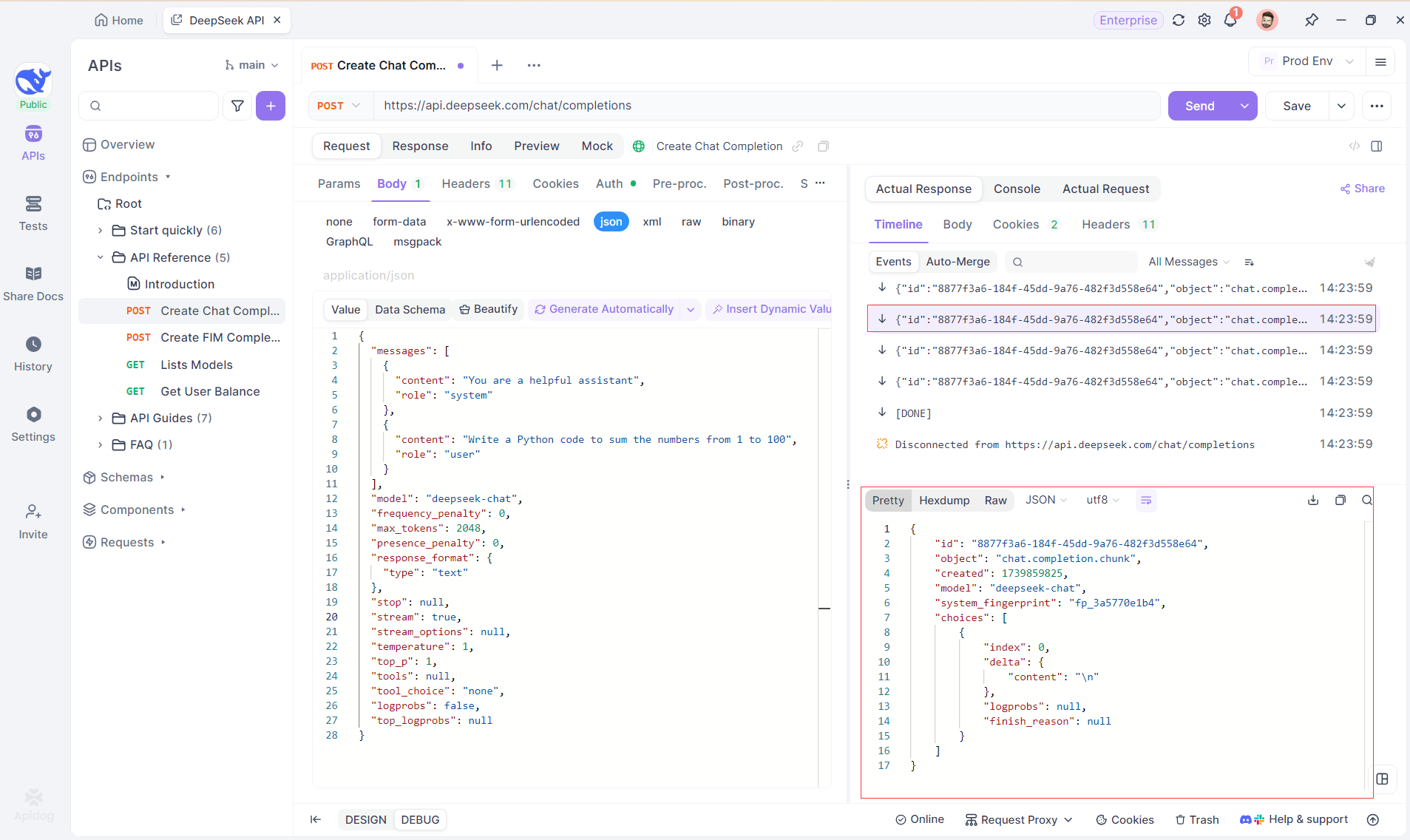
Passo 4: Visualizando a Resposta SSE em uma Resposta Completa
O SSE transmite dados em fragmentos, exigindo um tratamento extra. A função Auto-Merge do Apidog resolve isso combinando automaticamente fragmentos de respostas de IA de modelos como OpenAI, Gemini ou Claude em uma saída completa.
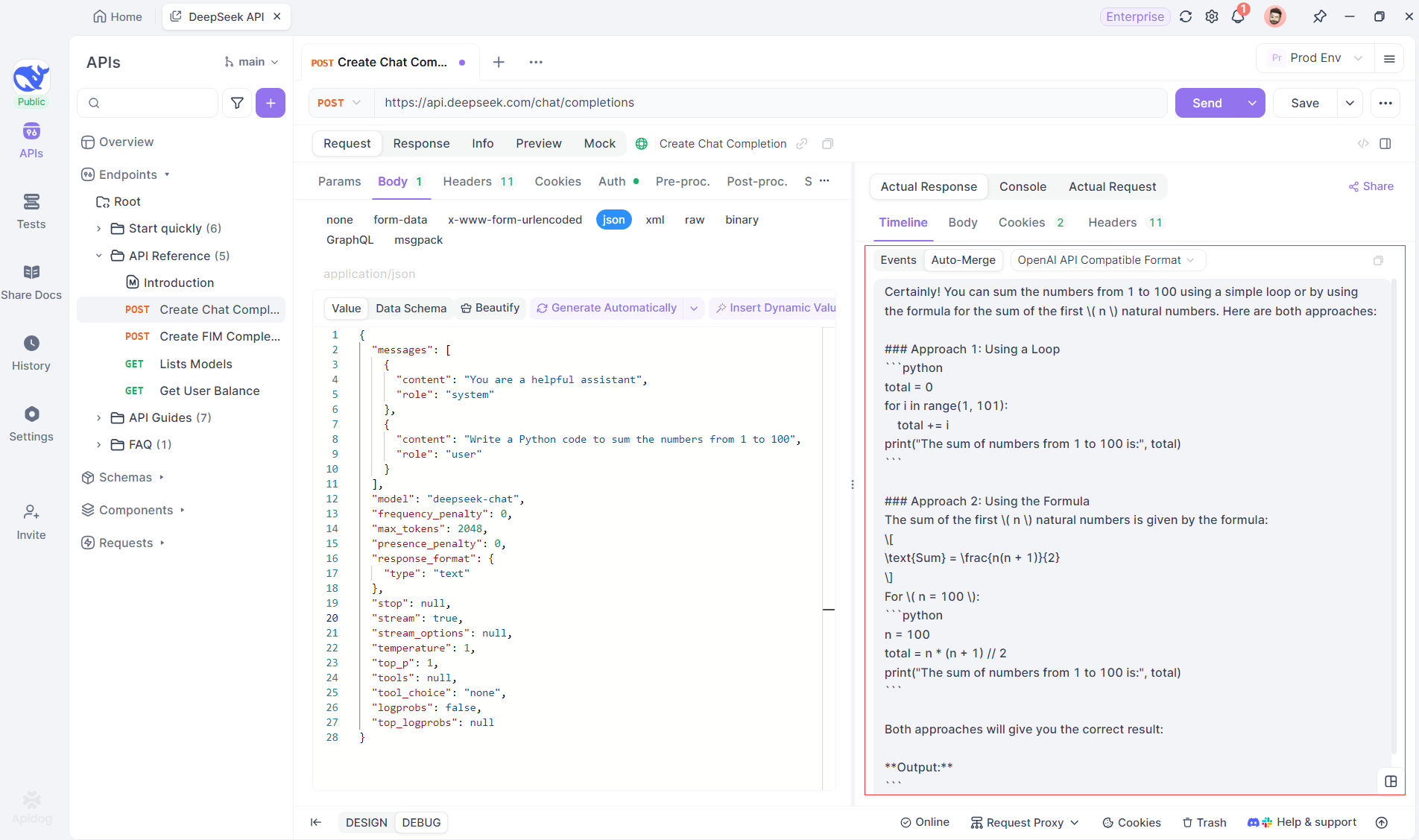
A função Auto-Merge do Apidog elimina o manuseio manual de dados, combinando automaticamente fragmentos de respostas de IA de modelos como OpenAI, Gemini ou Claude.
Para modelos de raciocínio como o DeepSeek R1, a Visualização de Linha do Tempo do Apidog mapeia visualmente o processo de pensamento da IA, facilitando a depuração e compreensão de como as conclusões são formadas.
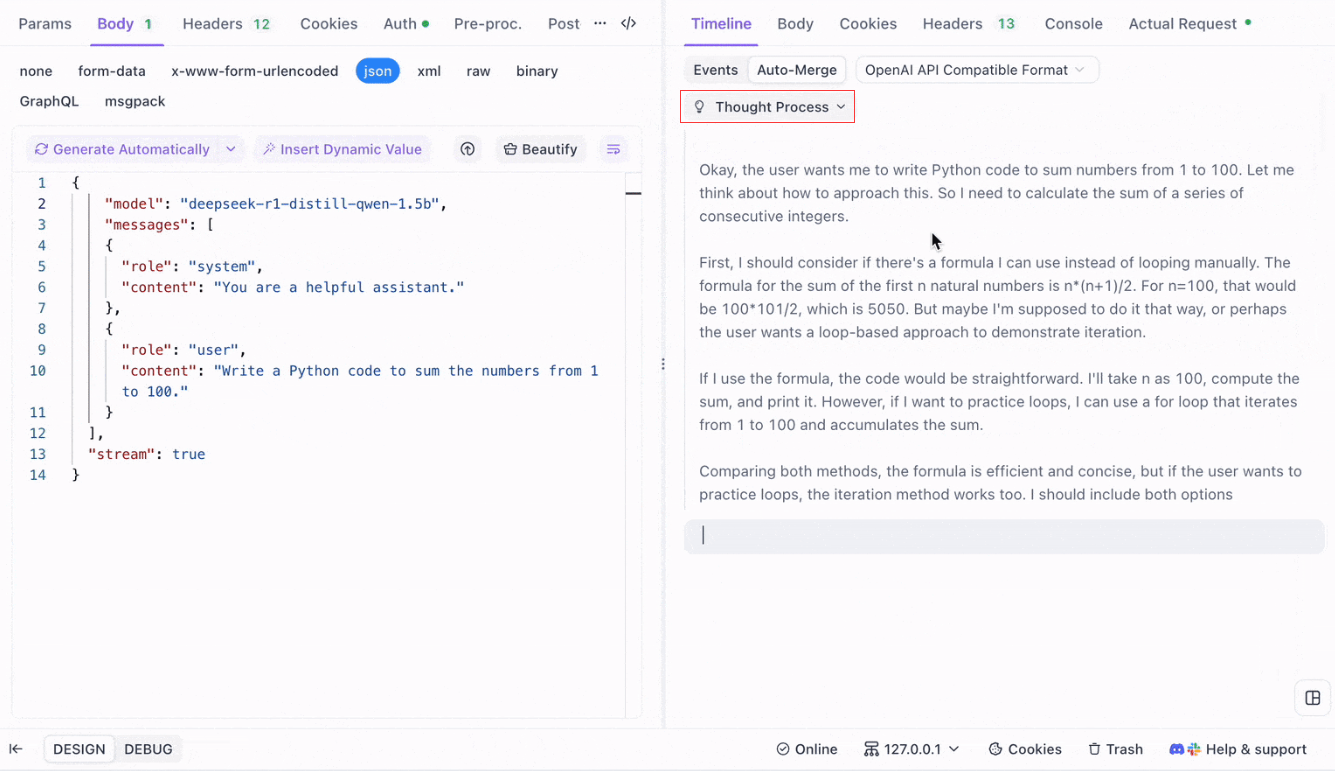
O Apidog reconhece e mescla automaticamente respostas de IA de:
- Formato da API OpenAI
- Formato da API Gemini
- Formato da API Claude
Quando uma resposta corresponde a esses formatos, o Apidog combina automaticamente os fragmentos, eliminando costura manual e agilizando a depuração SSE.
Conclusão e Próximos Passos
Cobrimos muito hoje! Para resumir, aqui estão as cinco ferramentas de destaque para executar LLMs localmente:
- Llama.cpp: Ideal para desenvolvedores que querem uma ferramenta leve, rápida e altamente eficiente de linha de comando com amplo suporte a hardware.
- GPT4All: Um ecossistema local que roda em hardware comum, oferecendo uma interface intuitiva e desempenho poderoso.
- LM Studio: Perfeito para aqueles que preferem uma interface gráfica, com fácil gerenciamento de modelos e extensas opções de personalização.
- Ollama: Uma ferramenta robusta de linha de comando com capacidades multimodais e empacotamento contínuo de modelos por meio de seu sistema "Modelfile".
- Jan: Uma plataforma focada em privacidade, de código aberto, que roda completamente offline, oferecendo uma estrutura extensível para integrar vários LLMs.
Cada uma dessas ferramentas oferece vantagens únicas, seja em desempenho, facilidade de uso ou privacidade. Dependendo dos requisitos do seu projeto, uma dessas soluções pode ser a escolha perfeita para suas necessidades. A beleza das ferramentas locais de LLM é que elas permitem que você explore e experimente sem se preocupar com vazamento de dados, custos de assinatura ou latência de rede.
Lembre-se de que experimentar com LLMs locais é um processo de aprendizado. Sinta-se à vontade para misturar e combinar essas ferramentas, testar várias configurações e ver qual se alinha melhor ao seu fluxo de trabalho. Além disso, se você estiver integrando esses modelos em suas próprias aplicações, ferramentas como o Apidog podem ajudar você a gerenciar e testar seus endpoints de API LLM usando Eventos Enviados pelo Servidor (SSE) de maneira perfeita. Não se esqueça de baixar o Apidog gratuitamente e elevar sua experiência de desenvolvimento local.
Próximos Passos
- Experimente: Escolha uma ferramenta da nossa lista e configure-a na sua máquina. Brinque com diferentes modelos e configurações para entender como as mudanças afetam a saída.
- Integre: Se você está desenvolvendo uma aplicação, use a ferramenta LLM local como parte do seu backend. Muitas dessas ferramentas oferecem compatibilidade com API (por exemplo, o servidor de inferência local do LM Studio), o que pode facilitar a integração.
- Contribua: A maioria desses projetos é de código aberto. Se você encontrar um bug, uma funcionalidade faltante ou simplesmente tiver ideias para melhorias, considere contribuir com a comunidade. Sua contribuição pode ajudar a tornar essas ferramentas ainda melhores.
- Aprenda Mais: Continue explorando o mundo dos LLMs lendo sobre tópicos como quantização de modelos, técnicas de otimização e engenharia de prompts. Quanto mais você entender, mais poderá aproveitar esses modelos ao máximo.
Agora, você deve ter uma base sólida para escolher a ferramenta LLM local certa para seus projetos. O cenário da tecnologia LLM está evoluindo rapidamente, e executar modelos localmente é um passo fundamental para construir soluções de IA privadas, escaláveis e de alto desempenho.
À medida que você experimenta essas ferramentas, descobrirá que as possibilidades são infinitas. Se você está trabalhando em um chatbot, um assistente de código ou uma ferramenta criativa personalizada, os LLMs locais podem oferecer a flexibilidade e o poder que você precisa. Aproveite a jornada e boas codificações!