
O Tongyi DeepResearch da Alibaba redefine os agentes de IA autônomos com seu modelo Mixture of Experts (MoE) de 30 bilhões de parâmetros, ativando apenas 3 bilhões de parâmetros por token para uma pesquisa web eficiente e de alta fidelidade. Essa potência de código aberto supera benchmarks como o Humanity's Last Exam (32,9% vs. 24,9% do OpenAI o3) e o xbench-DeepSearch (75,0% vs. 67,0%), permitindo que desenvolvedores lidem com consultas complexas e de várias etapas — desde análise jurídica até itinerários de viagem — sem dependência de tecnologias proprietárias.
Engenheiros do Tongyi Lab projetaram este agente para enfrentar diretamente o raciocínio de longo prazo e o uso dinâmico de ferramentas. Consequentemente, ele supera modelos fechados na síntese do mundo real, tudo isso enquanto roda localmente via Hugging Face. Nesta análise técnica, dissecamos sua arquitetura esparsa, pipeline de dados automatizado, treinamento otimizado por RL, dominância em benchmarks e truques de implantação. Ao final, você verá como o Tongyi DeepResearch — e ferramentas como o Apidog — liberam a IA agêntica escalável para seus projetos.
Compreendendo o Tongyi DeepResearch: Conceitos Centrais e Inovações
O Tongyi DeepResearch redefine a IA agêntica focando na recuperação e síntese profunda de informações. Ao contrário dos modelos de linguagem grandes tradicionais (LLMs) que se destacam na geração de formato curto, este agente navega em ambientes dinâmicos como navegadores web para descobrir insights sutis. Especificamente, ele emprega uma arquitetura Mixture of Experts (MoE), onde os 30 bilhões de parâmetros completos ativam seletivamente apenas 3 bilhões por token. Essa eficiência permite um desempenho robusto em hardware com recursos limitados, mantendo uma alta consciência contextual de até 128 mil tokens.
Além disso, o modelo se integra perfeitamente com paradigmas de inferência que imitam a tomada de decisões humanas. No modo ReAct, ele percorre nativamente os passos de pensamento, ação e observação, contornando a engenharia de prompts pesada. Para tarefas mais exigentes, o modo Heavy ativa a estrutura IterResearch, que orquestra explorações paralelas de agentes para evitar sobrecarga de contexto. Como resultado, os usuários alcançam resultados superiores em cenários que exigem refinamento iterativo, como revisões de literatura acadêmica ou análise de mercado.
O que diferencia o Tongyi DeepResearch é seu compromisso com a abertura. Todo o stack — desde os pesos do modelo até o código de treinamento — reside em plataformas como Hugging Face e GitHub. Os desenvolvedores acessam a variante Tongyi-DeepResearch-30B-A3B diretamente, facilitando o ajuste fino para necessidades específicas de domínio. Além disso, sua compatibilidade com ambientes Python padrão reduz a barreira de entrada. Por exemplo, a instalação envolve um simples comando pip após configurar um ambiente Conda com Python 3.10.
Transitando para a utilidade prática, o Tongyi DeepResearch impulsiona aplicações que exigem saídas verificáveis. Na pesquisa jurídica, ele analisa estatutos e jurisprudência, citando fontes com precisão. Da mesma forma, no planejamento de viagens, ele constrói itinerários de vários dias cruzando dados em tempo real. Essas capacidades derivam de uma filosofia de design deliberada: priorizar o raciocínio agêntico em detrimento da mera previsão.
A Arquitetura do Tongyi DeepResearch: Eficiência Encontra Poder
Em sua essência, o Tongyi DeepResearch aproveita um design MoE esparso para equilibrar as demandas computacionais com o poder expressivo. O modelo ativa apenas um subconjunto de especialistas por token, roteando entradas dinamicamente com base na complexidade da consulta. Essa abordagem reduz a latência em até 90% em comparação com suas contrapartes densas, tornando-o viável para implantações de agentes em tempo real. Além disso, a janela de contexto de 128 mil tokens suporta interações estendidas, crucial para tarefas que envolvem longas cadeias de documentos ou pesquisas web encadeadas.
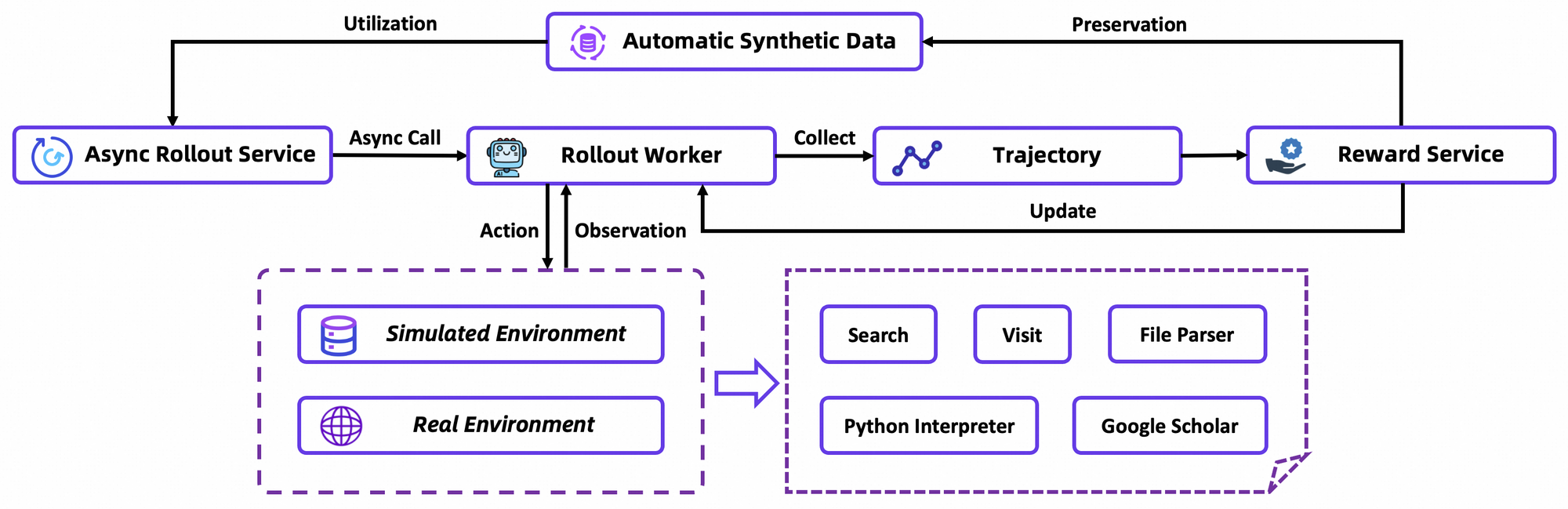
Os principais componentes arquitetônicos incluem um tokenizador personalizado otimizado para tokens agênticos — como prefixos de ação e delimitadores de observação — e um conjunto de ferramentas incorporado para navegação no navegador, recuperação e computação. A estrutura suporta a integração de aprendizado por reforço (RL) on-policy, onde os agentes aprendem com simulações em um ambiente estável. Consequentemente, o modelo exibe menos alucinações nas invocações de ferramentas, como evidenciado por suas altas pontuações em benchmarks de uso de ferramentas.
Além disso, o Tongyi DeepResearch incorpora memória de conhecimento ancorada em entidades, derivada da síntese de dados baseada em grafos. Esse mecanismo ancora as respostas a entidades factuais, melhorando a rastreabilidade. Por exemplo, durante uma consulta sobre avanços em computação quântica, o agente recupera e sintetiza artigos por meio de ferramentas semelhantes ao WebSailor, fundamentando as saídas em fontes verificáveis. Assim, a arquitetura não apenas processa informações, mas as curadoria ativamente.
Para ilustrar, considere o tratamento de entradas multimodais pelo modelo. Embora seja principalmente baseado em texto, extensões via repositório GitHub permitem a integração com analisadores de imagem ou executores de código. Os desenvolvedores configuram isso no script de inferência, especificando caminhos para conjuntos de dados no formato JSONL. Assim, a arquitetura promove a extensibilidade, convidando contribuições da comunidade de código aberto.
Síntese Automatizada de Dados: Impulsionando as Capacidades do Tongyi DeepResearch
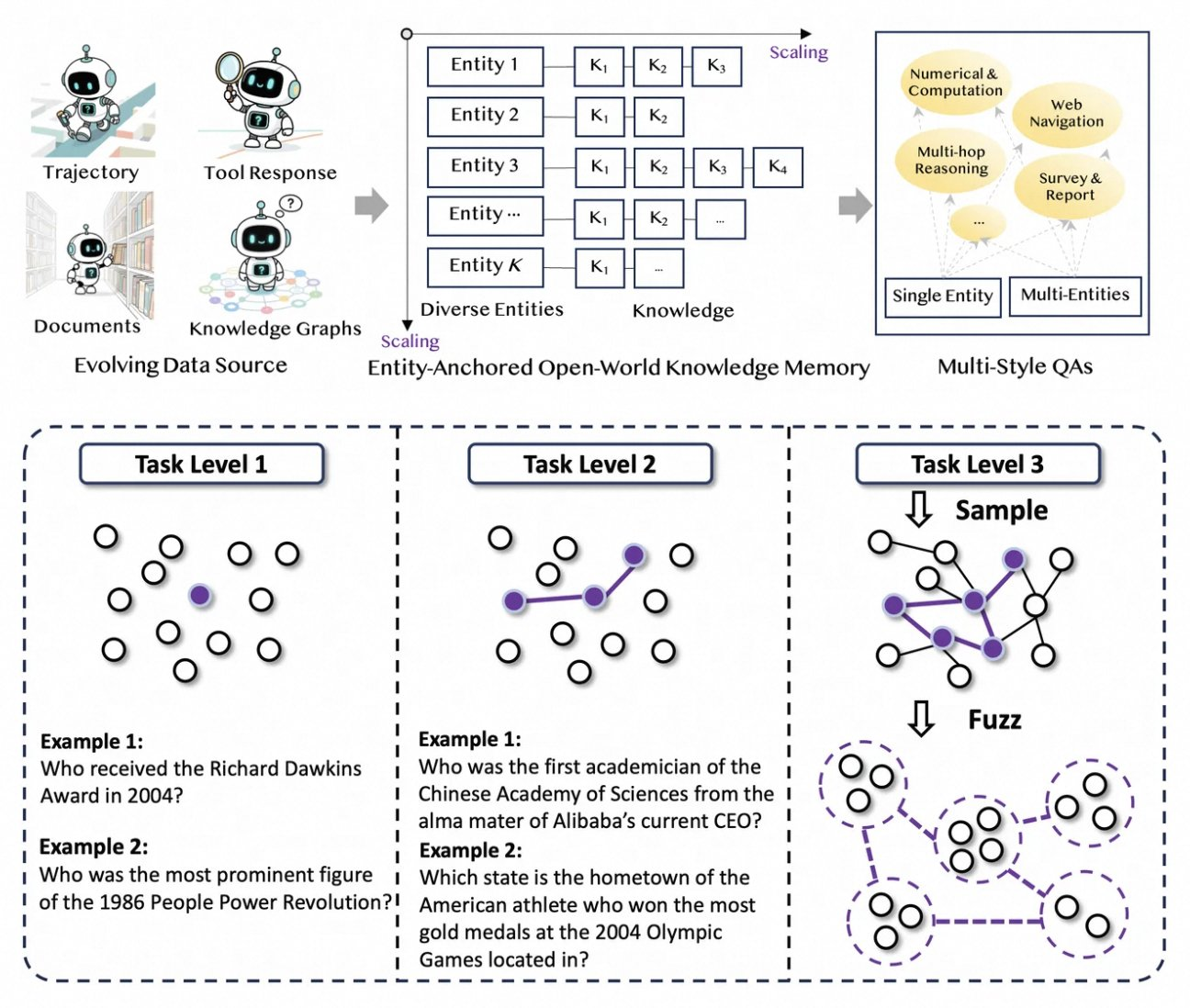
O Tongyi DeepResearch prospera em um pipeline de dados inovador e totalmente automatizado que elimina gargalos de anotação humana. O processo começa com o AgentFounder, um motor de síntese que reorganiza corpora brutos — documentos, rastreamentos web e grafos de conhecimento — em pares de QA ancorados em entidades. Esta etapa gera diversas trajetórias para o pré-treinamento contínuo (CPT), cobrindo cadeias de raciocínio, chamadas de ferramentas e árvores de decisão.
Em seguida, o pipeline aumenta a dificuldade por meio de atualizações iterativas. Para o pós-treinamento, ele emprega métodos baseados em grafos como o WebSailor-V2 para simular desafios "super-humanos", como perguntas de nível de doutorado modeladas via teoria dos conjuntos. Como resultado, o conjunto de dados abrange milhões de interações de alta fidelidade, garantindo que o modelo generalize em vários domínios. Notavelmente, essa automação escala linearmente com a computação, permitindo atualizações contínuas sem curadoria manual.
Além disso, o Tongyi DeepResearch incorpora dados multiestilo para robustez. Registros de síntese de ações capturam padrões de uso de ferramentas, enquanto pares de QA multiestágio refinam as habilidades de planejamento. Na prática, isso resulta em agentes que se adaptam a ambientes web ruidosos, filtrando efetivamente trechos irrelevantes. Para desenvolvedores, o repositório fornece scripts para replicar este pipeline, permitindo a criação de conjuntos de dados personalizados.
Ao priorizar a qualidade sobre a quantidade, a estratégia de síntese aborda armadilhas comuns no treinamento de agentes, como mudanças distribucionais. Consequentemente, modelos treinados dessa forma demonstram alinhamento superior com tarefas do mundo real, como visto em sua dominância em benchmarks.
Pipeline de Treinamento Ponta a Ponta: Do CPT à Otimização por RL
O treinamento do Tongyi DeepResearch se desenrola em um pipeline contínuo: CPT Agêntico, Ajuste Fino Supervisionado (SFT) e Aprendizado por Reforço (RL). Primeiro, o CPT expõe o modelo base a vastos dados agênticos, infundindo-o com priors de navegação web e sinais de frescor. Esta fase ativa capacidades latentes, como planejamento implícito, por meio da modelagem de linguagem mascarada em trajetórias.

Após o CPT, o SFT alinha o modelo a formatos instrucionais, usando simulações sintéticas para ensinar a formulação precisa de ações. Aqui, o modelo aprende a gerar ciclos ReAct coerentes, minimizando erros na análise de observações. Transitando suavemente, a etapa de RL emprega o Group Relative Policy Optimization (GRPO), um algoritmo on-policy personalizado.
O GRPO calcula gradientes de política em nível de token com estimativa de vantagem leave-one-out, reduzindo a variância em configurações não estacionárias. Ele também filtra amostras negativas de forma conservadora, estabilizando atualizações no simulador personalizado — um banco de dados offline da Wikipedia emparelhado com um sandbox de ferramentas. Simulações assíncronas via framework rLLM aceleram a convergência, alcançando o SOTA (State-of-the-Art) com computação modesta.
Em detalhes, o ambiente de RL simula interações de navegador fielmente, recompensando o sucesso em várias etapas em vez de ações únicas. Isso promove o planejamento de longo prazo, onde os agentes iteram sobre falhas parciais. Como nota técnica, a função de perda incorpora a divergência KL para conservadorismo, prevenindo o colapso de modo. Os desenvolvedores replicam isso por meio dos scripts de avaliação do repositório, comparando políticas personalizadas.
No geral, este pipeline marca um avanço: ele conecta o pré-treinamento à implantação sem silos, gerando agentes que evoluem por tentativa e erro.
Desempenho em Benchmarks: Como o Tongyi DeepResearch se Destaca
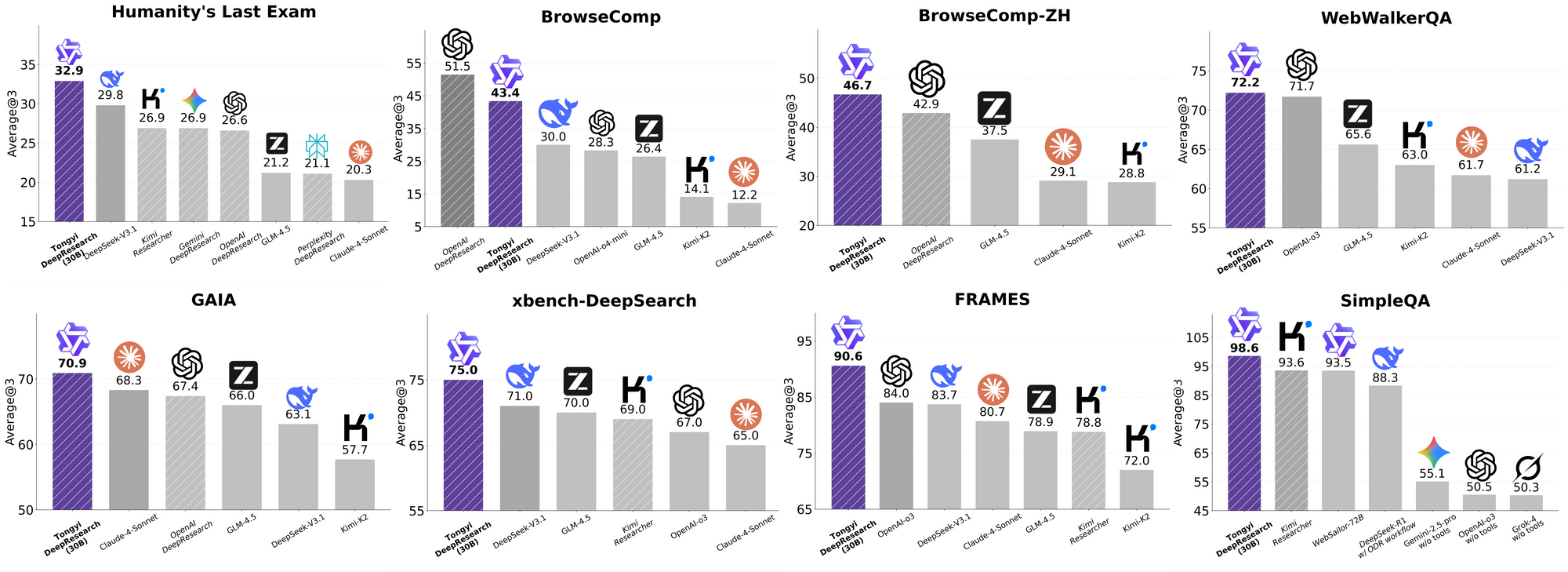
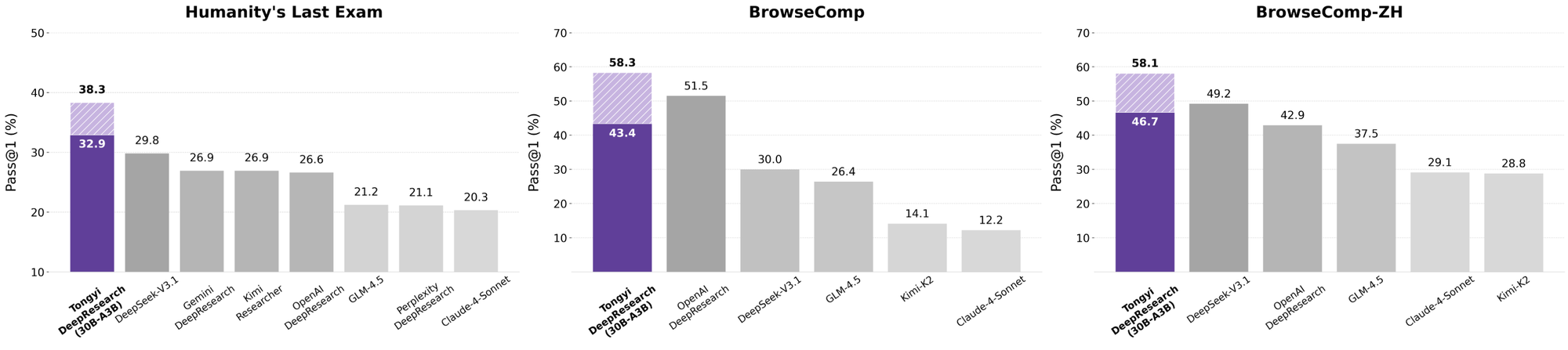
O Tongyi DeepResearch brilha em rigorosos benchmarks agênticos, validando seu design. No Humanity's Last Exam (HLE), um teste de raciocínio acadêmico, ele pontua 32,9 no modo ReAct — superando o o3 da OpenAI em 24,9. Essa lacuna se amplia no modo Heavy para 38,3, destacando a eficácia do IterResearch.
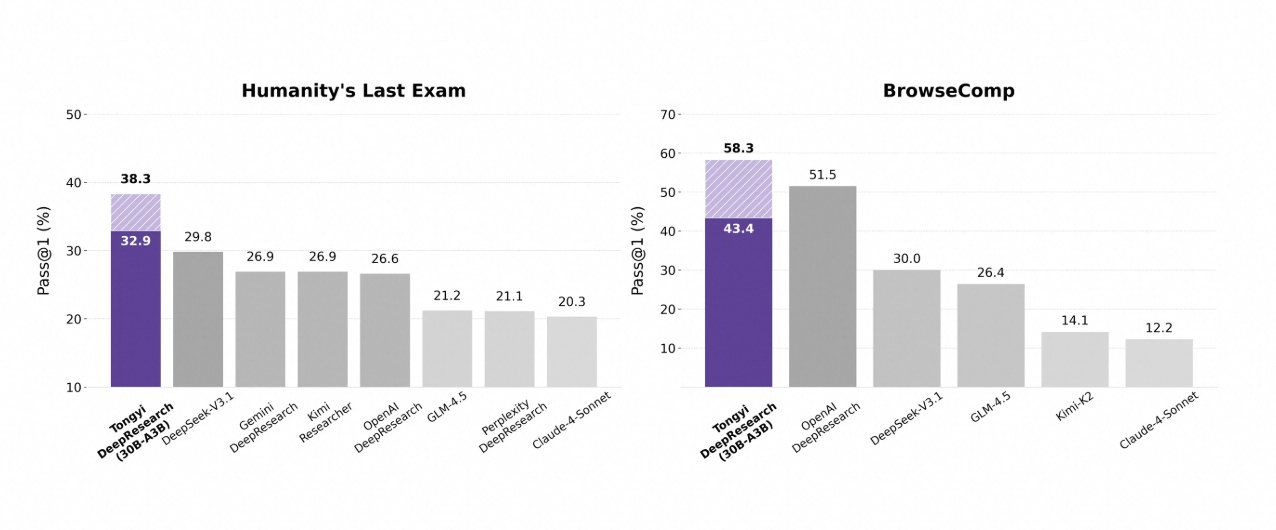
Da mesma forma, o BrowseComp avalia a busca complexa de informações; o Tongyi alcança 43,4 (EN) e 46,7 (ZH), ficando próximo dos 49,7 e 58,1 do o3, respectivamente, em eficiência. O benchmark xbench-DeepSearch, centrado no usuário para consultas profundas, mostra o Tongyi em 75,0 contra 67,0 do o3, sublinhando uma síntese de recuperação superior.
Outras métricas reforçam isso: FRAMES em 90,6 (vs. 84,0 do o3), GAIA em 70,9 e SimpleQA em 95,0. Um gráfico comparativo visualiza isso, com barras para o Tongyi DeepResearch superando Gemini, Claude e outros em HLE, BrowseComp, xbench, FRAMES e mais. Barras azuis indicam as lideranças do Tongyi, linhas de base cinzas mostram as deficiências dos concorrentes.
Esses resultados decorrem de otimizações direcionadas, como roteamento seletivo de especialistas para tarefas de busca. Assim, o Tongyi DeepResearch não apenas compete, mas lidera em IA agêntica de código aberto.
Comparando o Tongyi DeepResearch com Líderes da Indústria
Quando os desenvolvedores avaliam agentes de IA, as comparações revelam o verdadeiro valor. O Tongyi DeepResearch, com 30B-A3B, supera o o3 da OpenAI em HLE (32,9 vs. 24,9) e xbench (75,0 vs. 67,0), apesar da maior escala do o3. Contra o Gemini do Google, ele alcança 35,2 no BrowseComp-ZH, uma vantagem de 10 pontos.
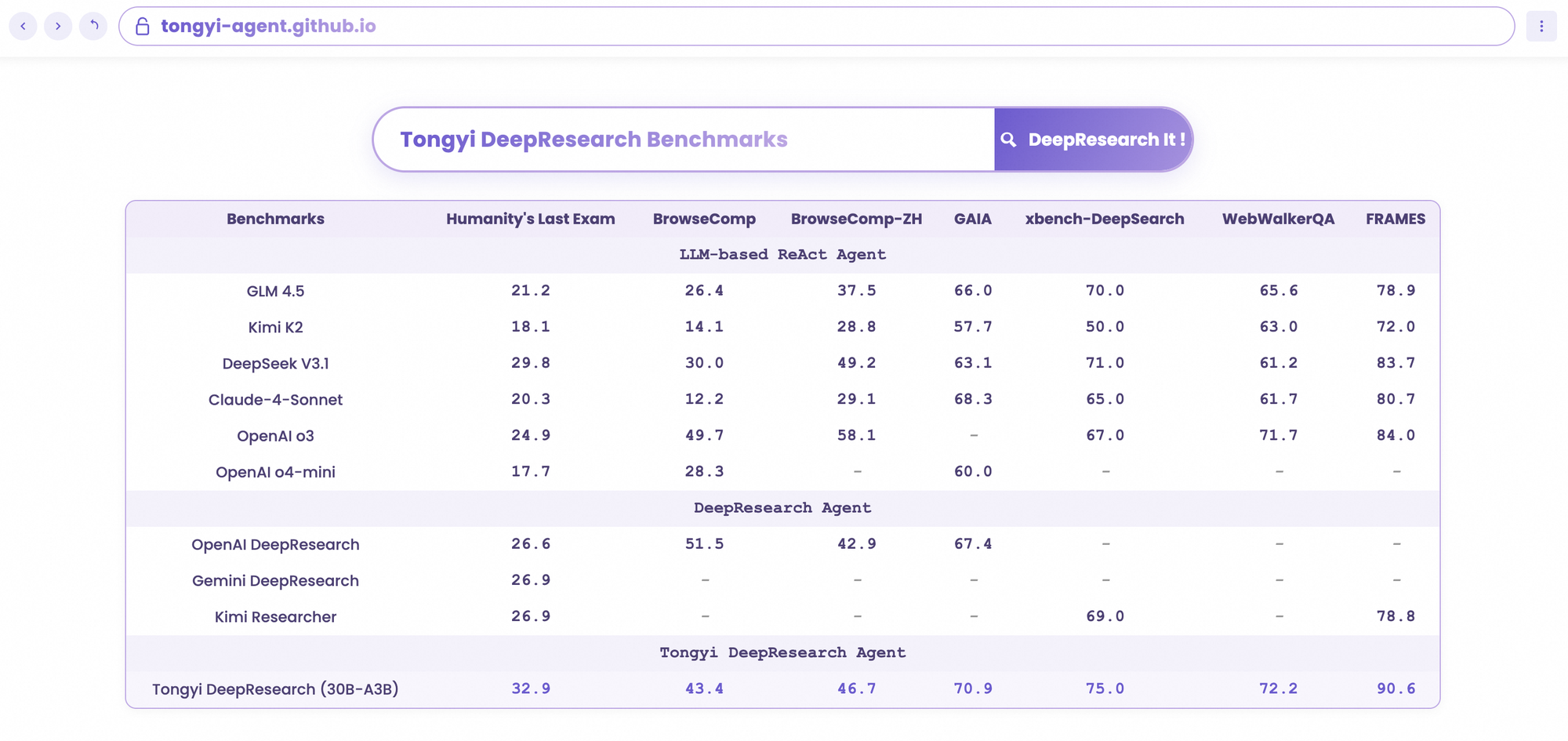
Modelos proprietários como o Claude 3.5 Sonnet ficam para trás no uso de ferramentas; os 90,6 do Tongyi no FRAMES ofuscam os 84,3 do Sonnet. Pares de código aberto, como variantes do Llama, ficam ainda mais para trás — por exemplo, 21,1 no HLE. A esparsidade MoE do Tongyi permite essa paridade, consumindo menos computação de inferência.
Além disso, a acessibilidade inclina a balança: enquanto o o3 exige créditos de API, o Tongyi roda localmente via Hugging Face. Para fluxos de trabalho com uso intenso de API, combine-o com o Apidog para simular endpoints, simulando chamadas de ferramentas de forma eficiente.
Em essência, o Tongyi DeepResearch democratiza o desempenho de elite, desafiando ecossistemas fechados.
Aplicações no Mundo Real: Tongyi DeepResearch em Ação
O Tongyi DeepResearch transcende os benchmarks, impulsionando um impacto tangível. No Gaode Mate, o aplicativo de navegação da Alibaba, ele planeja viagens complexas — consultando voos, hotéis e eventos em paralelo via modo Heavy. Os usuários recebem itinerários sintetizados com citações, reduzindo o tempo de planejamento em 70%.
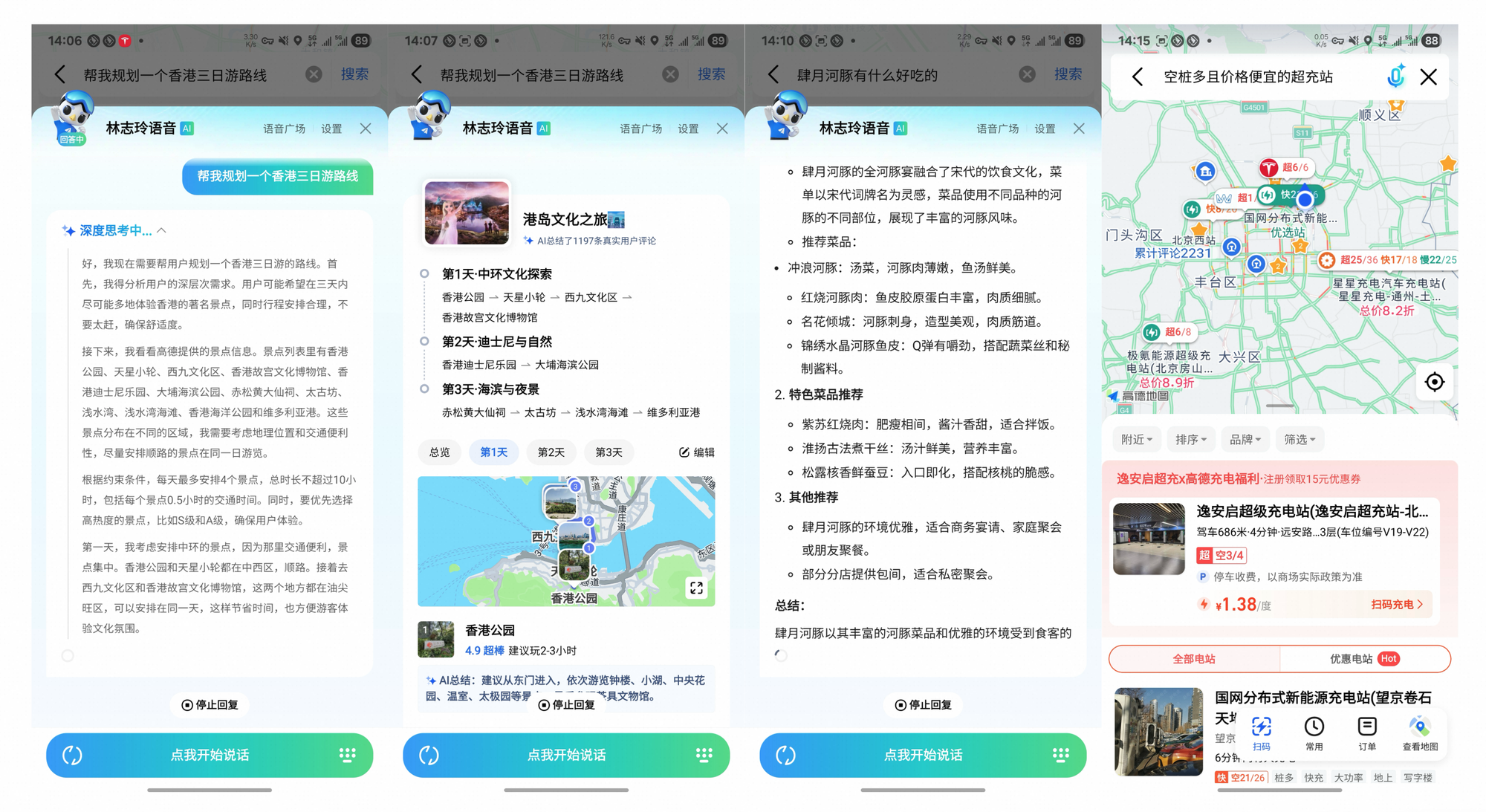
Da mesma forma, o Tongyi FaRui revoluciona a pesquisa jurídica. O agente analisa estatutos, faz referência cruzada a precedentes e gera resumos com links verificáveis. Profissionais verificam as saídas rapidamente, minimizando erros em domínios de alto risco.
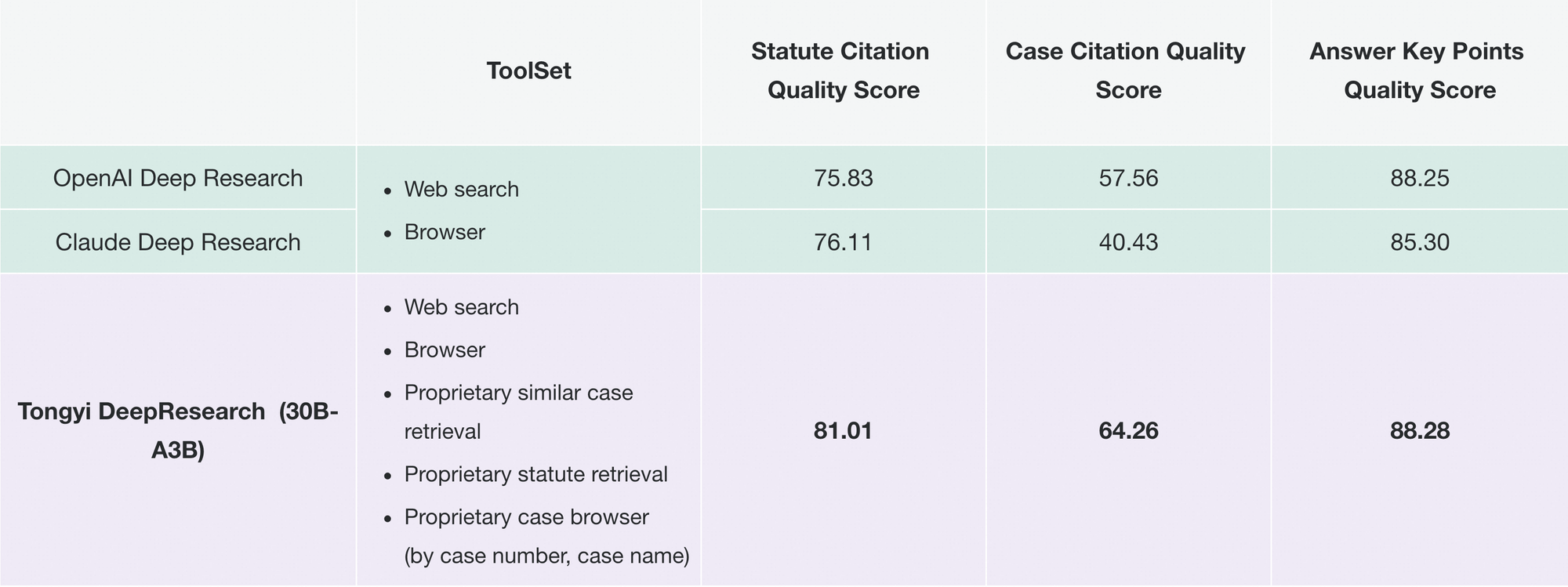
Além disso, empresas o adaptam para inteligência de mercado: extraindo dados de concorrentes, sintetizando tendências. A modularidade do repositório suporta tais extensões — adicione ferramentas personalizadas via configurações JSON.
À medida que a adoção cresce, o Tongyi DeepResearch se integra a ecossistemas como o LangChain, amplificando enxames de agentes. Para desenvolvedores de API, o Apidog complementa isso validando integrações pré-implantação.
Esses casos demonstram escalabilidade: de aplicativos de consumo a ferramentas B2B, o modelo oferece autonomia confiável.
Começando com o Tongyi DeepResearch: Um Guia para Desenvolvedores
Implemente o Tongyi DeepResearch sem esforço com seu repositório GitHub. Comece criando um ambiente Conda: conda create -n deepresearch python=3.10. Ative e instale: pip install -r requirements.txt.
Prepare os dados em eval_data/ como JSONL, com as chaves question e answer. Para arquivos, prefixe os nomes às perguntas e armazene em file_corpus/. Edite run_react_infer.sh para o caminho do modelo (por exemplo, URL do Hugging Face) e chaves de API para ferramentas.
Execute: bash run_react_infer.sh. As saídas são salvas nos caminhos especificados, prontas para análise.
Para o modo Heavy, configure os parâmetros do IterResearch no código — defina a contagem de agentes e as rodadas. Faça o benchmark via scripts em evaluation/, comparando com as linhas de base.
Solucione problemas com logs; problemas comuns como incompatibilidades de tokenizador são resolvidos por meio de verificações de tensor BF16. Para aprimorar, baixe o Apidog gratuitamente para simulação de API, testando endpoints de ferramentas sem chamadas ao vivo.
Esta configuração o equipa para prototipar agentes rapidamente.
Direções Futuras: Expandindo o Tongyi DeepResearch Ainda Mais
Olhando para o futuro, o Tongyi Lab visa a expansão do contexto além de 128 mil tokens, permitindo horizontes ultralongos como análises de livros inteiros. Eles planejam a validação em bases MoE maiores, investigando os limites de escalabilidade.
Melhorias de RL incluem rollouts parciais para eficiência e métodos off-policy para mitigar mudanças. Contribuições da comunidade poderiam integrar ferramentas de visão ou multilíngues, ampliando o escopo.
À medida que o código aberto evolui, o Tongyi DeepResearch ancorará avanços colaborativos, impulsionando as buscas por AGI.
Conclusão: Abrace a Era Tongyi DeepResearch
O Tongyi DeepResearch transforma a IA agêntica, combinando eficiência, abertura e destreza. Seus benchmarks, arquitetura e aplicativos o posicionam como líder, superando rivais como as ofertas da OpenAI. Desenvolvedores, aproveitem este poder — baixem o modelo, experimentem e integrem com o Apidog para APIs perfeitas.
Em um campo que avança rapidamente em direção à autonomia, o Tongyi DeepResearch acelera o progresso. Comece a construir hoje; os insights esperam por você.