
No mundo em rápida evolução da inteligência artificial, a capacidade de transmitir respostas de Modelos de Linguagem Grande (LLMs) em tempo real tornou-se essencial para aprimorar as interações do usuário e melhorar o desempenho geral da aplicação. Uma das melhores maneiras de alcançar isso é através de Eventos Enviados pelo Servidor (SSE), uma tecnologia robusta baseada no protocolo HTTP que fornece um canal de comunicação unidirecional entre o servidor e o cliente. Neste artigo, vamos explorar como o SSE funciona, como ele pode ser usado para transmitir respostas de LLMs e como ferramentas como Apidog podem simplificar a depuração e melhorar a eficiência de desenvolvimento.
O Que São Eventos Enviados pelo Servidor (SSE)?
Eventos Enviados pelo Servidor são uma tecnologia de comunicação em tempo real leve, baseada no protocolo HTTP. Com o SSE, um servidor estabelece uma conexão contínua e unidirecional com o cliente. O servidor envia atualizações para o cliente sem a necessidade de o cliente solicitar repetidamente novos dados. Isso torna o SSE ideal para transmissão de conteúdo dinâmico, como atualizações em tempo real, notificações ao vivo e, no caso de modelos de IA, respostas contínuas de LLMs.
A beleza do SSE reside em sua simplicidade e baixo custo. Diferente dos WebSockets, que permitem comunicação bidirecional, o SSE é projetado para cenários em que o servidor precisa enviar dados continuamente para o cliente. Isso é particularmente útil ao transmitir conteúdo gerado por IA em tempo real, pois o cliente pode ver o processo de pensamento do modelo se desenrolar à medida que gera cada parte da resposta.
Como o SSE Funciona na Transmissão de LLMs
Ao usar LLMs, especialmente com modelos complexos como DeepSeek R1, as respostas frequentemente chegam em partes fragmentadas. Com o SSE, cada um desses fragmentos é enviado como um "evento" separado no fluxo. Isso permite que desenvolvedores e usuários finais testemunhem todo o processo em tempo real. À medida que o servidor envia cada evento, o cliente é atualizado imediatamente, garantindo que os usuários recebam as informações mais atualizadas disponíveis.
Benefícios do Uso do SSE para Respostas de Modelos de IA
- Entrega de Dados em Tempo Real: O SSE permite que o cliente receba atualizações imediatamente à medida que são geradas, sem qualquer atraso.
- Comunicação Eficiente: O servidor envia dados apenas quando novos eventos ocorrem, reduzindo solicitações desnecessárias e melhorando a eficiência do sistema.
- Implementação do Lado do Cliente Simplificada: Com o SSE, os clientes não precisam de lógica complexa para lidar com atualizações de dados contínuas, uma vez que elas são recebidas e exibidas automaticamente.
Configurando a Depuração SSE com Apidog
Para começar com a depuração SSE usando Apidog, certifique-se de que você está usando a versão 2.6.49 ou superior. Apidog oferece uma plataforma amigável para trabalhar com APIs, facilitando o manuseio de conexões SSE e a depuração dos fluxos de dados em tempo real de LLMs como DeepSeek R1.
Passo 1: Criar um Novo Endpoint no Apidog
Comece criando um novo projeto HTTP no Apidog. Isso permite que você configure um espaço de trabalho para testar e depurar suas solicitações de API. Uma vez que seu projeto esteja configurado, adicione um novo endpoint inserindo a URL do modelo de IA. É daqui que o fluxo SSE será originado. Neste exemplo, usaremos DeepSeek como o modelo de IA. (DICA PROFISSIONAL: Você pode clonar o projeto de API DeepSeek pronto para uso no Hub de APIs do Apidog).
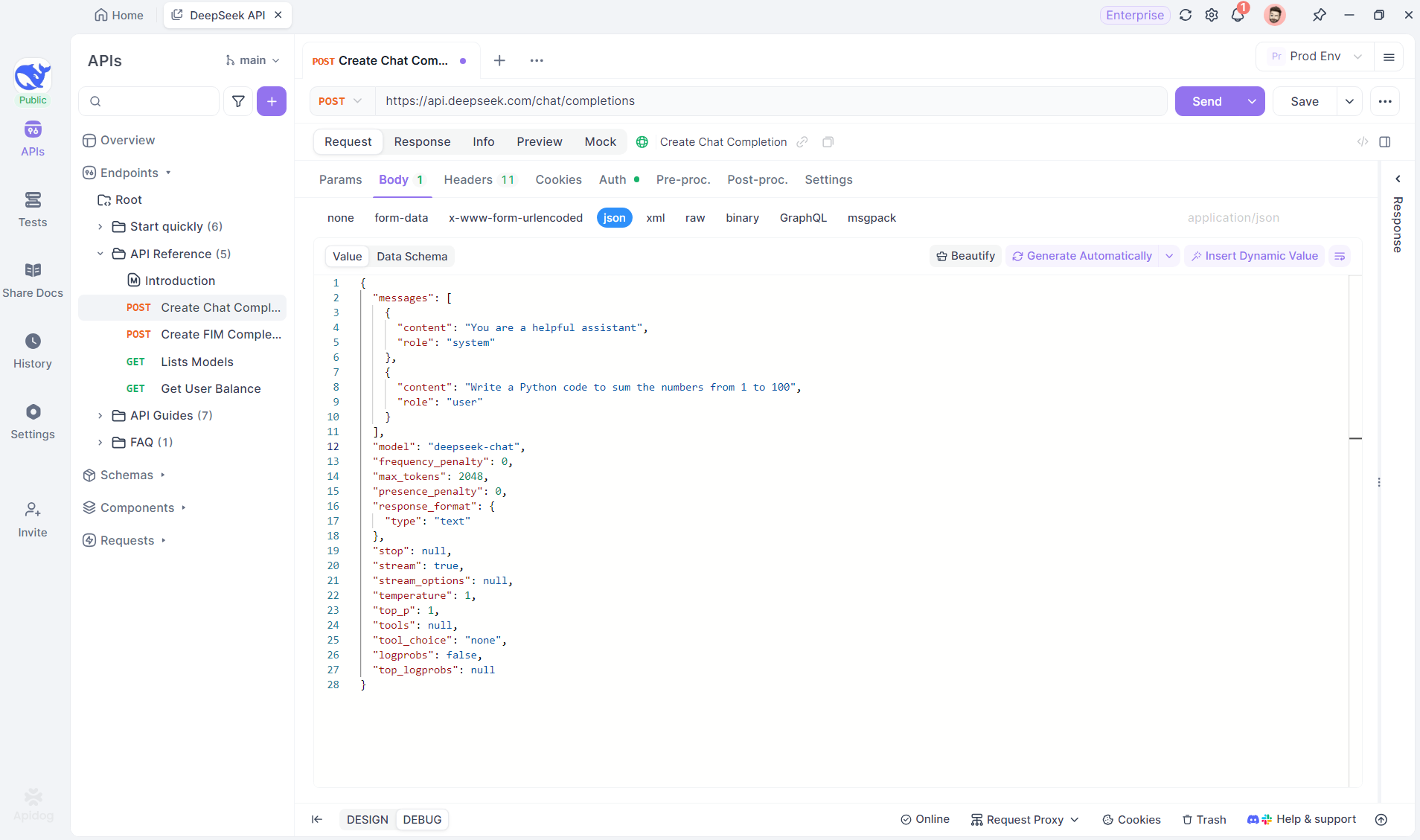
Passo 2: Enviar a Solicitação
Após adicionar o endpoint, envie a solicitação ao servidor clicando em Enviar no canto superior direito. Se o cabeçalho de resposta do servidor incluir Content-Type: text/event-stream, o Apidog reconhecerá automaticamente que os dados estão sendo transmitidos via SSE. O sistema inteligente do Apidog analisará essa resposta e a exibirá no painel de respostas, permitindo que você veja o fluxo em tempo real à medida que está sendo gerado.
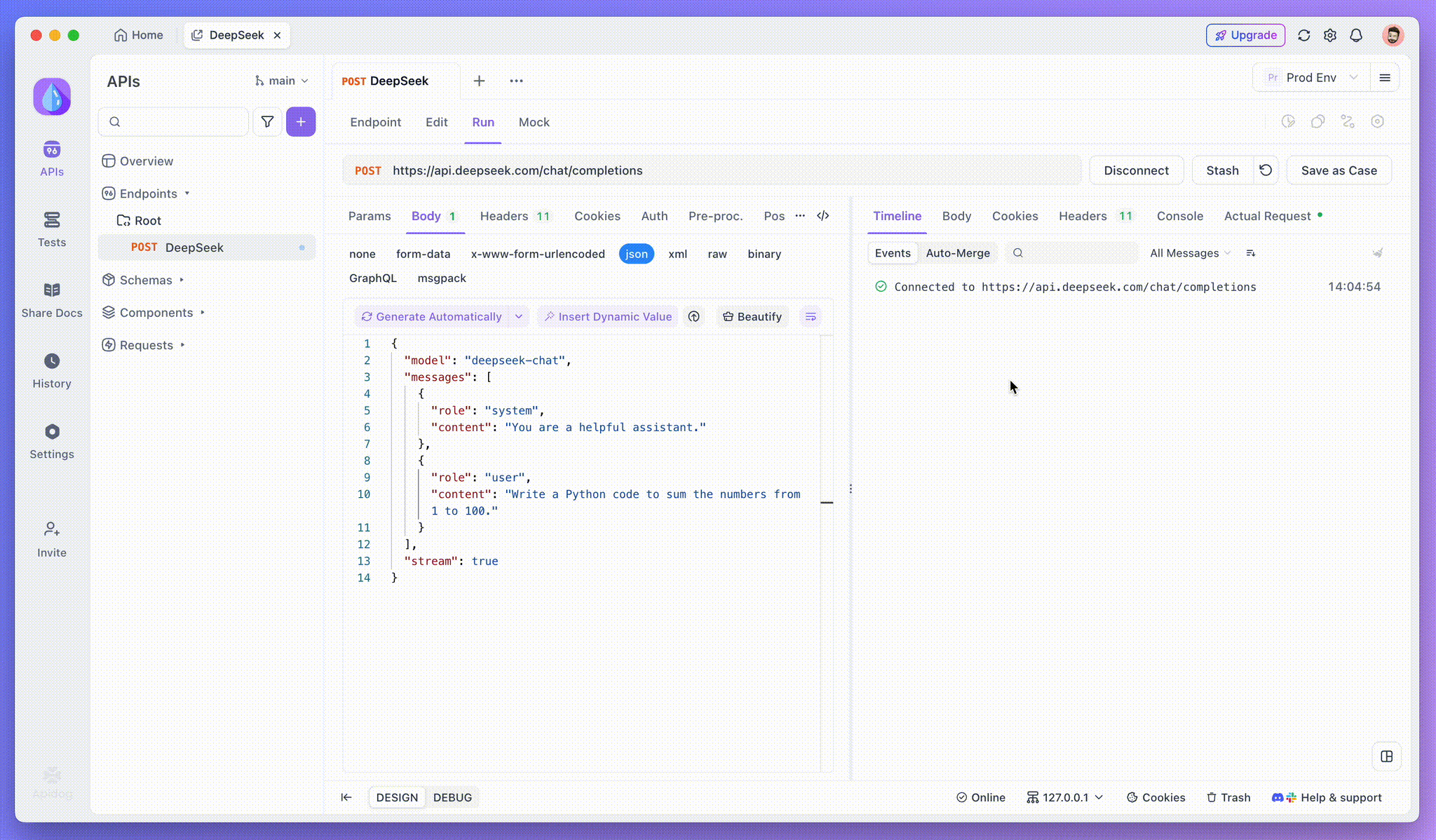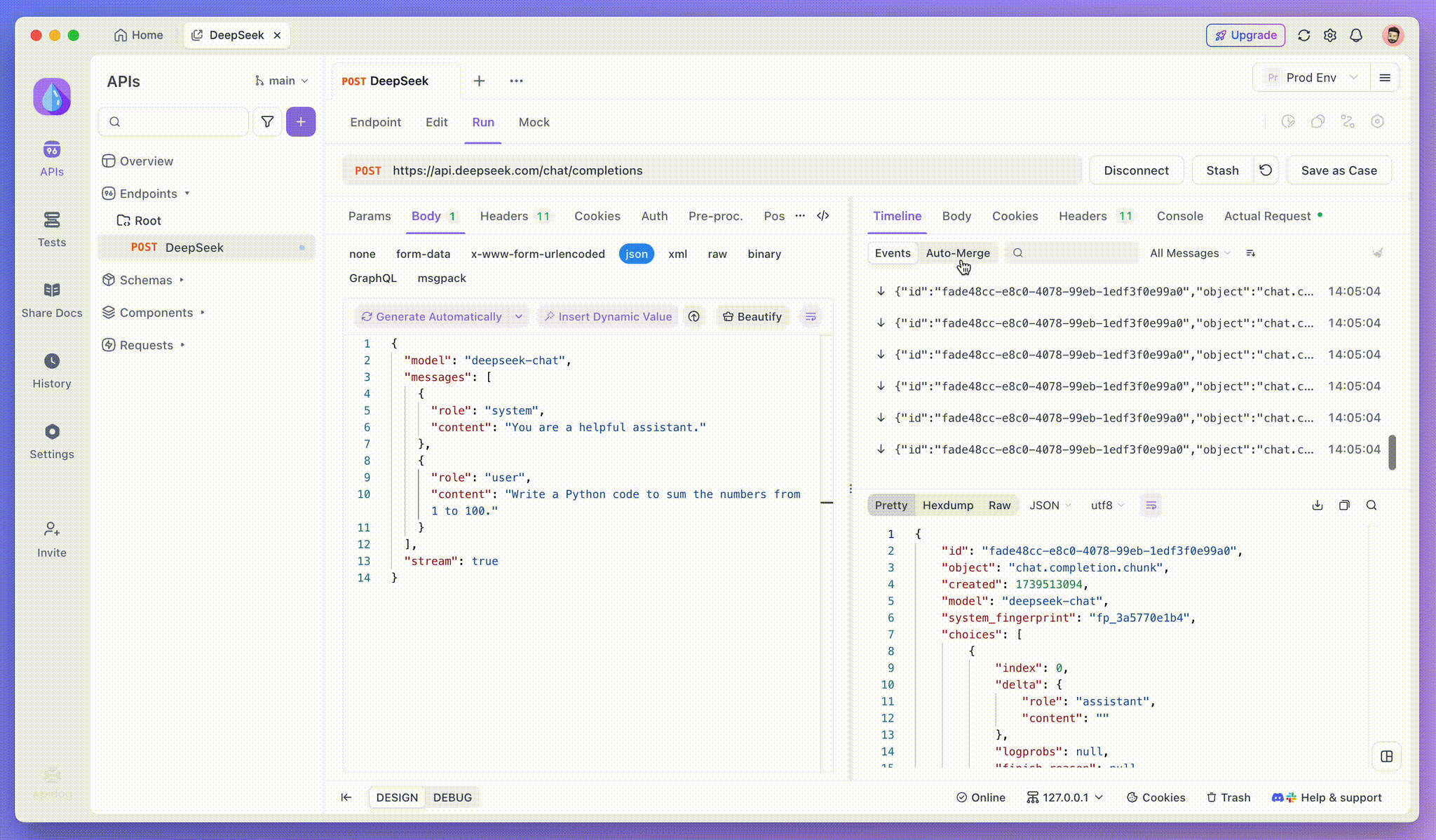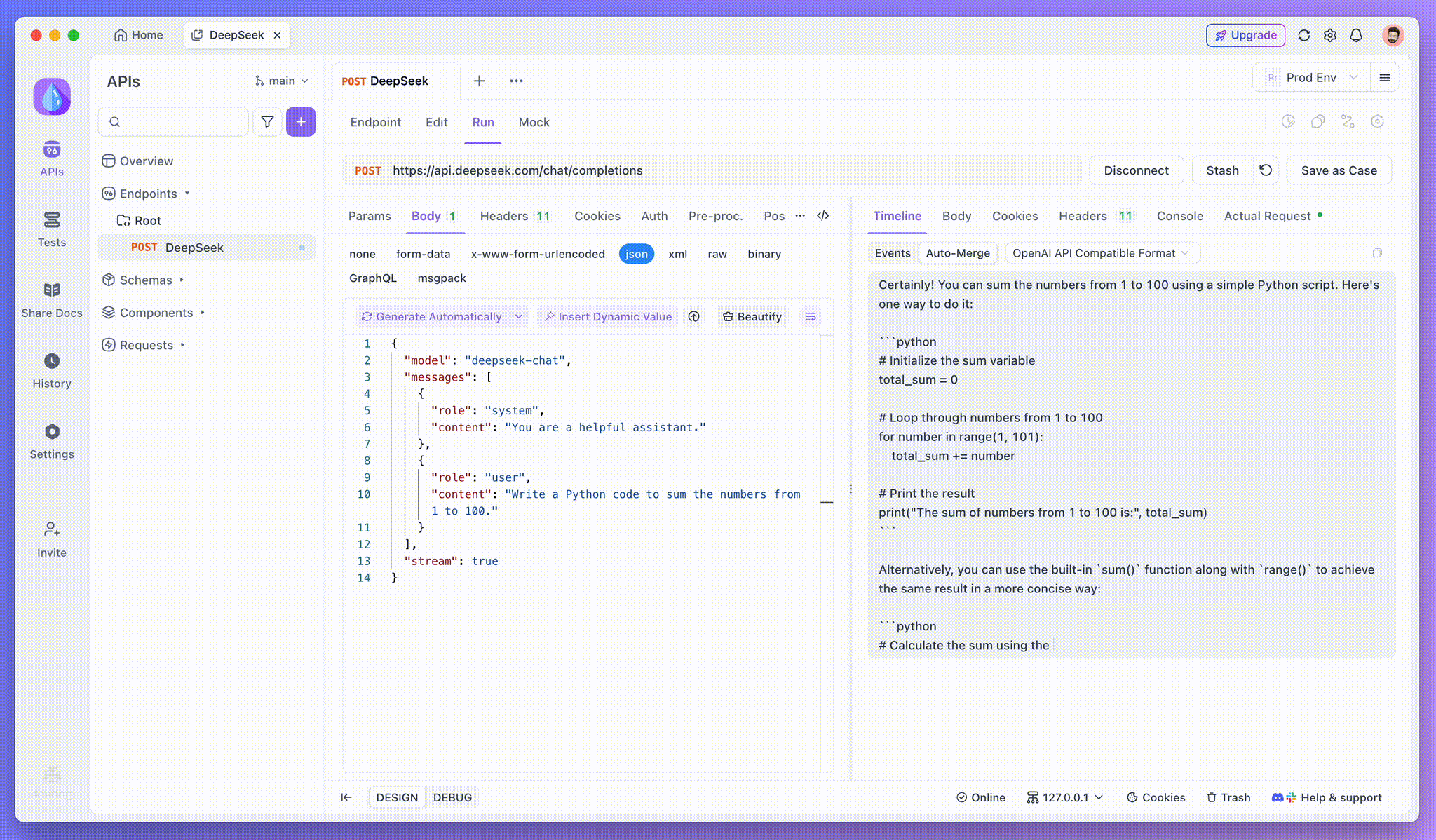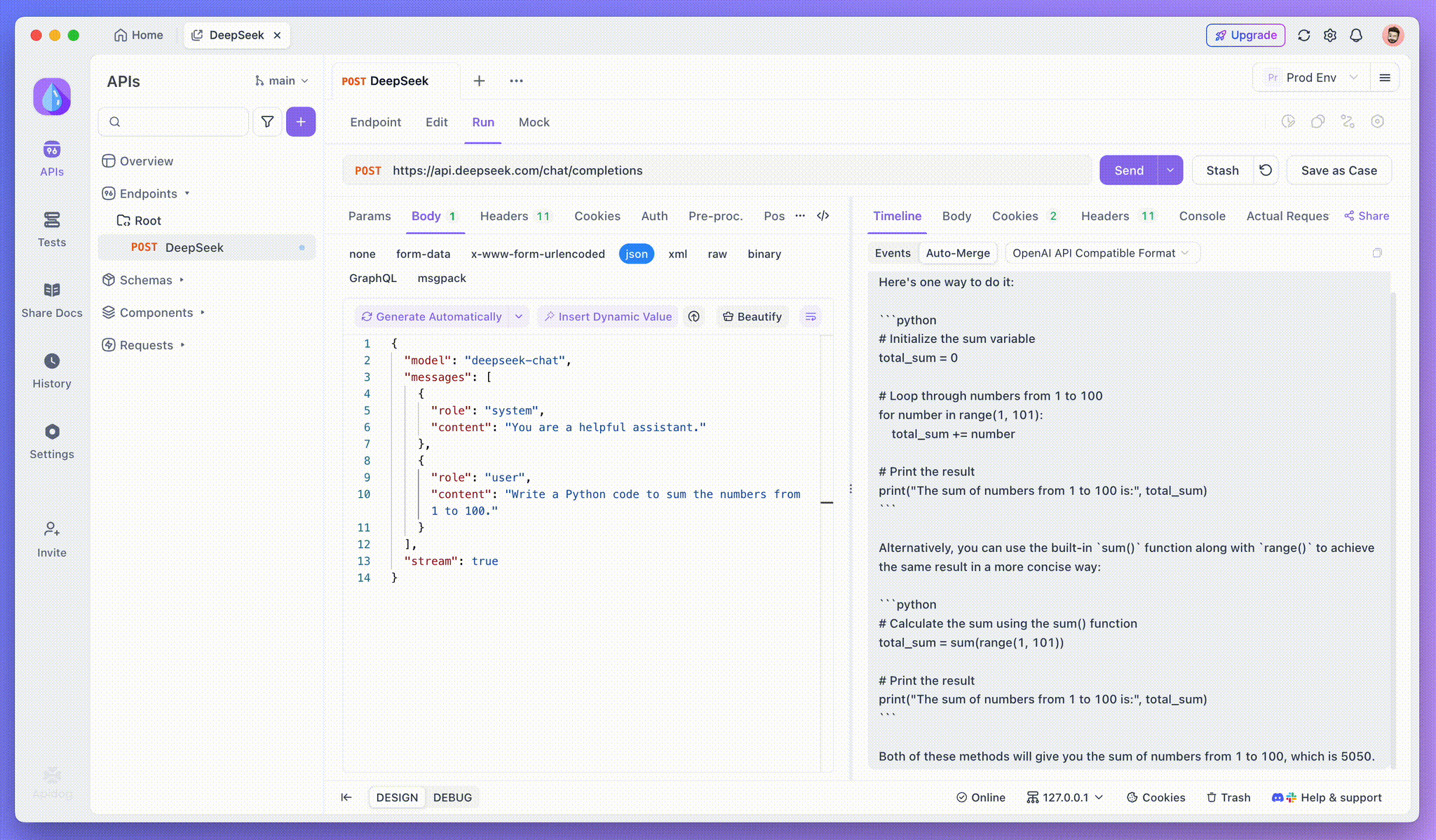
Passo 3: Visualizar Respostas em Tempo Real
A Visualização da Linha do Tempo do Apidog é onde a mágica acontece. À medida que o modelo de IA transmite suas respostas, a visualização da linha do tempo é atualizada dinamicamente, exibindo cada fragmento da resposta em tempo real. Essa visualização permite que você acompanhe a evolução do processo de pensamento da IA, proporcionando insights valiosos sobre como ela está gerando a saída final.
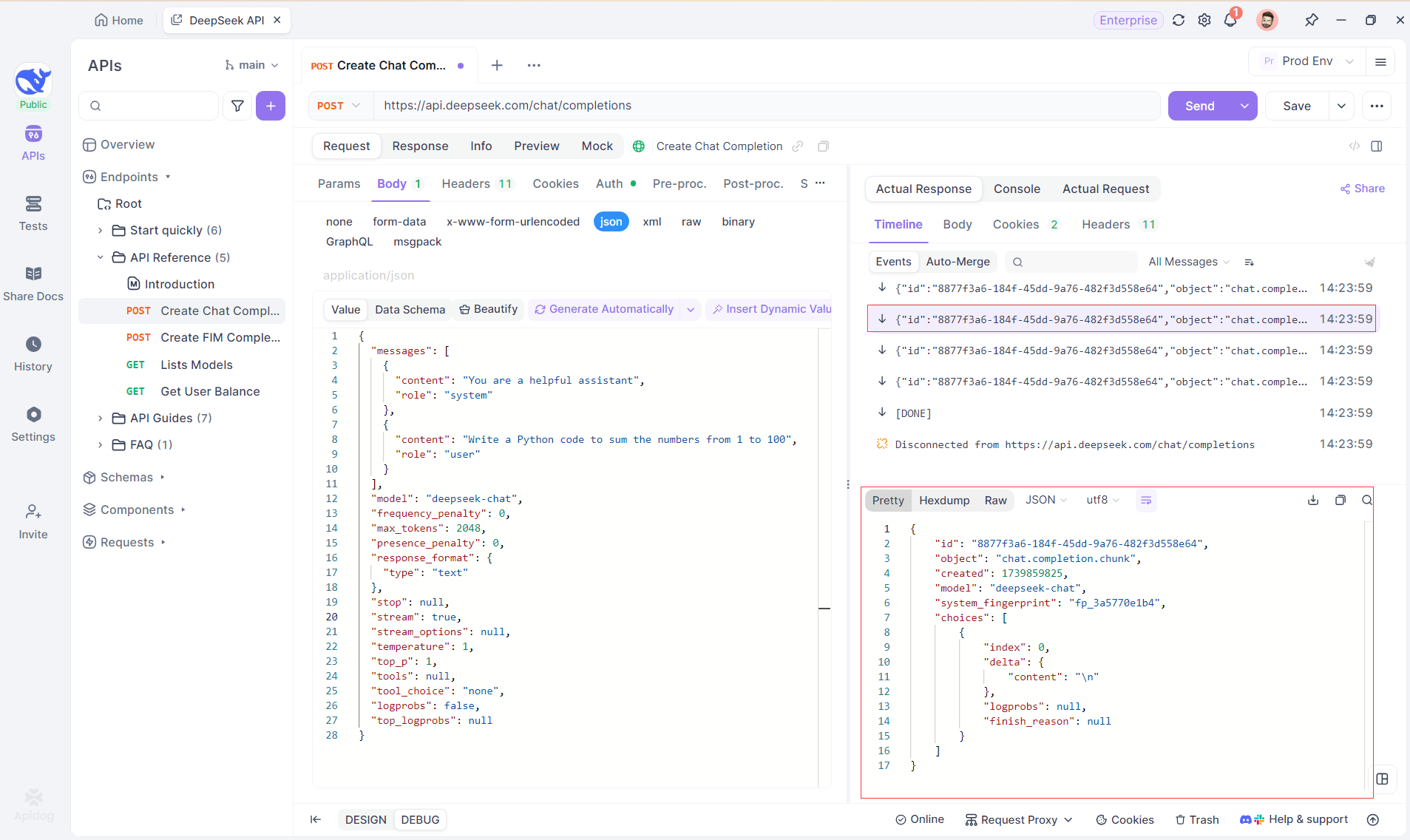
Passo 4: Visualizando a Resposta SSE em uma Resposta Completa
Embora o SSE forneça uma maneira poderosa de transmitir dados, muitas vezes requer manuseio adicional para lidar com respostas fragmentadas. O recurso Auto-Merge do Apidog foi projetado para abordar esse desafio. Ao transmitir respostas de IA, os dados frequentemente vêm em múltiplos fragmentos, especialmente com modelos como OpenAI, Gemini ou Claude. O Apidog automaticamente mescla esses fragmentos em uma resposta unificada e completa.
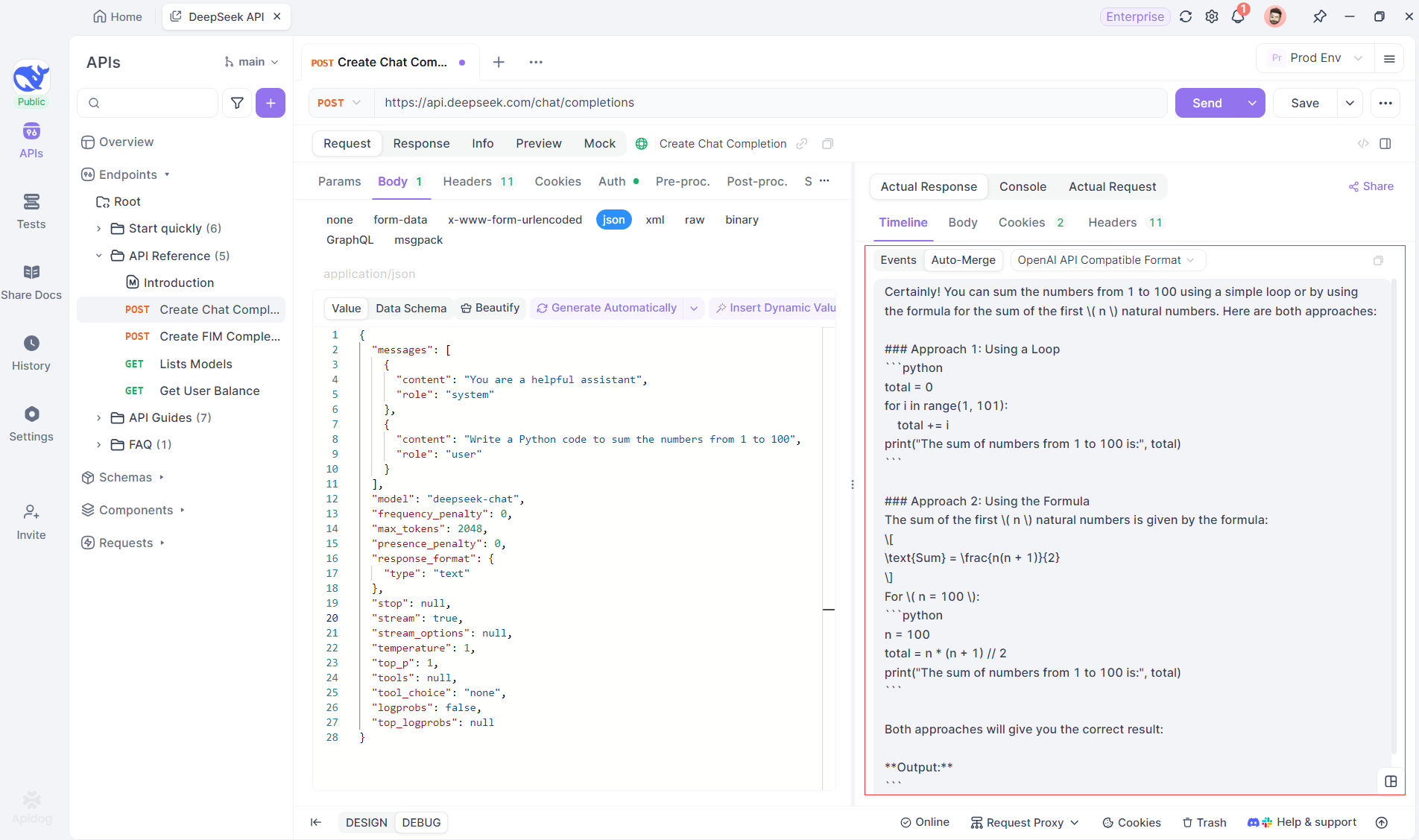
Esse recurso elimina a necessidade de manuseio manual de dados, permitindo que os desenvolvedores se concentrem em analisar a saída da IA em vez de lidar com as complexidades de mesclar mensagens fragmentadas.
Visualizando o Processo de Pensamento de Modelos de Raciocínio: Uma das características mais notáveis ao trabalhar com modelos de raciocínio como DeepSeek R1 é a capacidade do Apidog de exibir o processo de pensamento do modelo diretamente na visualização da Linha do Tempo.
À medida que a IA gera respostas, o Apidog não apenas mostra os dados da resposta, mas também fornece uma representação visual de como o modelo chegou a suas conclusões. Isso oferece uma maneira mais intuitiva de depurar e entender o raciocínio por trás das respostas da IA.
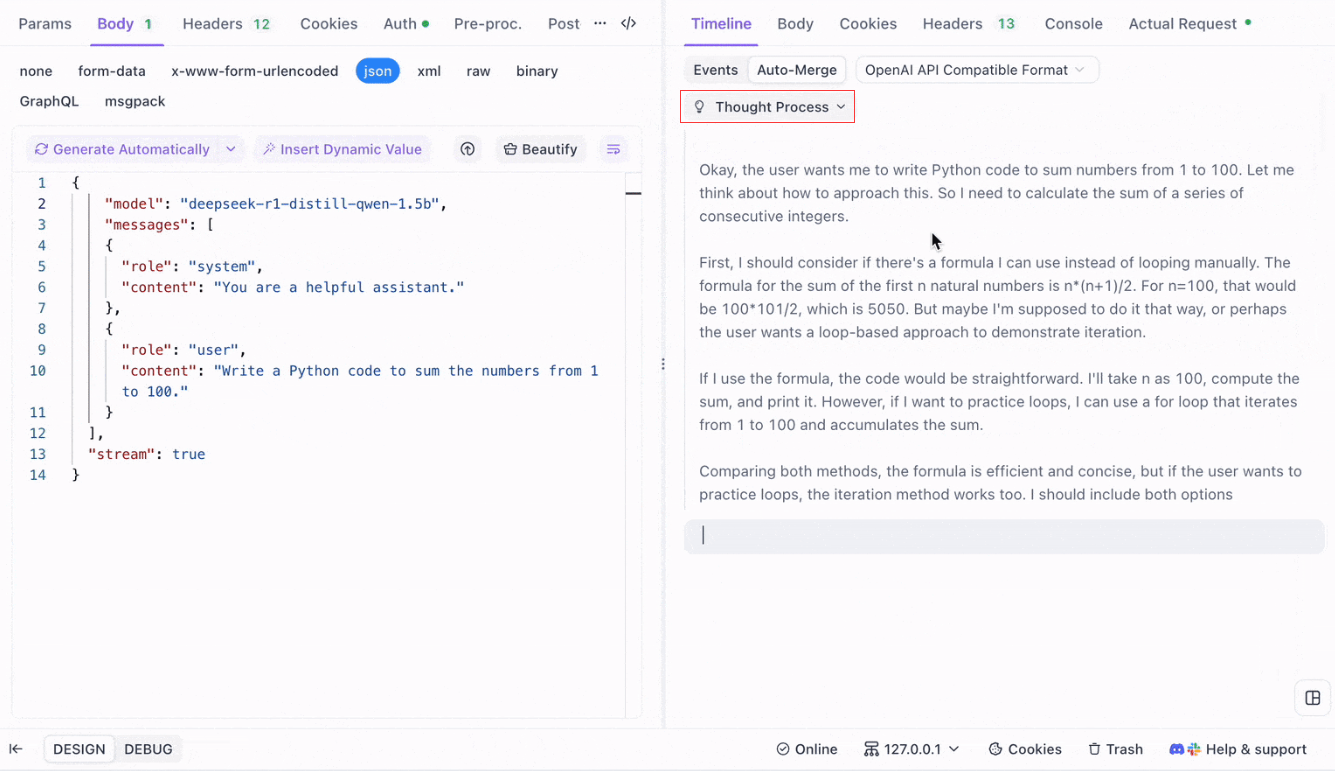
Formatos Suportados para Auto-Merge
O Apidog pode reconhecer automaticamente e mesclar respostas de vários formatos populares de modelos de IA:
- Formato da API OpenAI
- Formato da API Gemini
- Formato da API Claude
Quando a resposta do modelo de IA corresponde a qualquer um desses formatos, o Apidog mescla os fragmentos em uma resposta completa de forma contínua. Isso torna a depuração de respostas SSE mais eficiente, pois o desenvolvedor não precisa manualmente juntar as partes.
Por Que Usar o Auto-Merge para Depuração de LLM?
- Eficiência de Tempo: Os desenvolvedores podem evitar a tarefa tediosa de mesclar manualmente os fragmentos de resposta.
- Depuração Melhorada: Uma resposta unificada e completa permite uma análise mais clara do comportamento da IA.
- Insights Aprimorados: Visualizar o processo de pensamento do modelo adiciona uma camada extra de compreensão, particularmente para modelos complexos como DeepSeek R1.
Personalizando Regras de Depuração SSE no Apidog
Em alguns casos, o recurso Auto-Merge embutido pode não funcionar como esperado, especialmente ao lidar com modelos de IA personalizados ou formatos não padrão. O Apidog permite que você personalize a maneira como as respostas são tratadas usando Regras de Extração JSONPath ou Scripts de Pós-Processamento.
Configurando Regras de Extração JSONPath
Se a resposta SSE estiver em formato JSON, mas não atender às regras de reconhecimento embutidas para formatos como OpenAI, Claude ou Gemini, você pode configurar JSONPath para extrair o conteúdo necessário.
Por exemplo, considere a seguinte resposta SSE bruta:
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"H"},"logprobs":null,"finish_reason":"stop"}]}
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"i"},"logprobs":null,"finish_reason":"stop"}]}Para extrair o conteúdo do campo message.content, você configuraria JSONPath da seguinte forma: $.choices[0].message.content
Essa configuração puxará o conteúdo: Oi
Usando JSONPath, você pode personalizar como o Apidog lida com respostas, garantindo que sempre extraia os dados corretos.
Usando Scripts de Pós-Processamento para SSE Não JSON
Para respostas não JSON, o Apidog oferece a capacidade de usar Scripts de Pós-Processamento para manipular e extrair dados do fluxo SSE. Isso permite que você escreva scripts personalizados que lidam com formatos de dados específicos que não atendem às estruturas tradicionais do JSON.
Se você estiver lidando com um formato de modelo não suportado, também pode entrar em contato com o suporte técnico do Apidog para solicitar que o formato seja adicionado para suporte embutido.
Melhores Práticas para Transmitir Respostas de LLM com SSE
Ao transmitir respostas de LLM usando SSE, existem várias melhores práticas a serem lembradas para garantir uma depuração suave e eficiente:
- Tratar Fragmentação com Graça: Sempre antecipe que as respostas do modelo de IA podem vir em múltiplos fragmentos e use o recurso
Auto-Mergepara simplificar esse processo. - Testar com Diferentes Modelos de IA: Use modelos como OpenAI, Gemini e DeepSeek R1 para explorar o comportamento de diferentes formatos e garantir que sua configuração possa lidar com vários tipos de resposta.
- Usar a Visualização da Linha do Tempo para Depuração: Aproveite a visualização da Linha do Tempo do Apidog para obter uma análise em tempo real, passo a passo, de como as respostas evoluem, especialmente para modelos de IA complexos.
- Personalizar para Formatos Não Padrão: Se necessário, use JSONPath ou Scripts de Pós-Processamento para lidar com formatos SSE não padrão ou para ajustar o processo de extração de dados.
Conclusão: Aprimorando a Transmissão de LLM com SSE
Eventos enviados pelo servidor fornecem um mecanismo poderoso para transmitir respostas em tempo real de modelos de IA, particularmente ao lidar com LLMs grandes e complexos. Ao usar as ferramentas de depuração SSE do Apidog, incluindo o recurso Auto-Merge e visualização aprimorada, os desenvolvedores podem simplificar o processo de lidar com respostas fragmentadas e obter insights mais profundos sobre o comportamento do modelo. Seja depurando respostas de modelos populares como OpenAI ou trabalhando com soluções de IA personalizadas, o Apidog garante que você possa rastrear, mesclar e analisar dados SSE de maneira eficiente e perspicaz.