
Em 13 de abril de 2025, a SkyworkAI lançou a série Skywork-OR1 (Open Reasoner 1), composta por três modelos: Skywork-OR1-Math-7B, Skywork-OR1-7B-Preview e Skywork-OR1-32B-Preview.
- Esses modelos são treinados usando aprendizado por reforço baseado em regras em grande escala, focando especificamente em capacidades de raciocínio matemático e de código.
- Eles são construídos sobre arquiteturas distiladas da DeepSeek: as variantes de 7B usam DeepSeek-R1-Distill-Qwen-7B como base, enquanto o modelo de 32B se baseia no DeepSeek-R1-Distill-Qwen-32B.
Quer uma plataforma integrada e All-in-One para sua equipe de desenvolvedores trabalhar junta com máxima produtividade?
Apidog atende a todas as suas demandas e substitui o Postman a um preço muito mais acessível!

Skywork-OR1-32B: Mais do que Apenas um Modelo de Raciocínio Open Source
O modelo Skywork-OR1-32B-Preview possui 32,8 bilhões de parâmetros e utiliza o tipo de tensor BF16 para precisão numérica. O modelo é distribuído no formato safetensors e é baseado na arquitetura Qwen2. Segundo o repositório do modelo, ele mantém a mesma arquitetura do modelo base DeepSeek-R1-Distill-Qwen-32B, mas com treinamento especializado para tarefas de raciocínio matemático e de programação.
Vamos analisar algumas informações técnicas básicas das famílias de modelos da Skywork:
Skywork-OR1-32B-Preview
- Número de parâmetros: 32,8 bilhões
- Modelo base: DeepSeek-R1-Distill-Qwen-32B
- Tipo de tensor: BF16
- Especialização: Raciocínio de propósito geral
- Desempenho principal:
- AIME24: 79,7 (Avg@32)
- AIME25: 69,0 (Avg@32)
- LiveCodeBench: 63,9 (Avg@4)
O modelo de 32B demonstra uma melhoria de 6,8 pontos no AIME24 e 10,0 pontos no AIME25 em relação ao seu modelo base. Ele atinge eficiência de parâmetros ao entregar desempenho comparável ao DeepSeek-R1 de 671B de parâmetros, usando apenas 4,9% dos parâmetros.
Skywork-OR1-Math-7B
- Número de parâmetros: 7,62 bilhões
- Modelo base: DeepSeek-R1-Distill-Qwen-7B
- Tipo de tensor: BF16
- Especialização: Raciocínio matemático
- Desempenho principal:
- AIME24: 69,8 (Avg@32)
- AIME25: 52,3 (Avg@32)
- LiveCodeBench: 43,6 (Avg@4)
O modelo supera significativamente o DeepSeek-R1-Distill-Qwen-7B em tarefas matemáticas (69,8 vs. 55,5 no AIME24 e 52,3 vs. 39,2 no AIME25), demonstrando a eficácia da abordagem de treinamento especializado.
Skywork-OR1-7B-Preview
- Número de parâmetros: 7,62 bilhões
- Modelo base: DeepSeek-R1-Distill-Qwen-7B
- Tipo de tensor: BF16
- Especialização: Raciocínio de propósito geral
- Desempenho principal:
- AIME24: 63,6 (Avg@32)
- AIME25: 45,8 (Avg@32)
- LiveCodeBench: 43,9 (Avg@4)
Embora apresente menor especialização matemática que a variante Math-7B, esse modelo oferece um desempenho mais equilibrado entre tarefas matemáticas e de programação.
Conjunto de Dados de Treinamento do Skywork-OR1-32B
O conjunto de dados de treinamento do Skywork-OR1 contém:
- 110.000 problemas matemáticos diversificados e verificáveis
- 14.000 questões de programação
- Todos provenientes de conjuntos de dados open-source
Pipeline de Processamento de Dados
- Estimativa de Dificuldade Baseada no Modelo: Cada problema é avaliado quanto à dificuldade em relação às capacidades atuais do modelo, permitindo treinamento direcionado.
- Avaliação de Qualidade: Filtragem rigorosa é aplicada antes do treinamento para garantir a qualidade do conjunto de dados.
- Filtragem Offline e Online: Um processo em duas etapas é implementado para:
- Remover exemplos subótimos antes do treinamento (offline)
- Ajustar dinamicamente a seleção de problemas durante o treinamento (online)
- Amostragem por Rejeição: Essa técnica é usada para controlar a distribuição dos exemplos de treinamento, ajudando a manter uma curva de aprendizado otimizada.
Pipeline Avançado de Treinamento por Reforço
Os modelos utilizam uma versão personalizada do GRPO (Generative Reinforcement via Policy Optimization) com várias melhorias técnicas:
- Pipeline de Treinamento Multifásico: O treinamento avança por fases distintas, cada uma construindo sobre capacidades adquiridas anteriormente. O repositório do GitHub inclui um gráfico que mostra as pontuações do AIME24 em relação às etapas de treinamento, demonstrando melhorias claras em cada fase.
- Controle Adaptativo de Entropia: Essa técnica ajusta dinamicamente a relação exploração-explotação durante o treinamento, incentivando uma exploração mais ampla enquanto mantém a estabilidade da convergência.
- Fork Personalizado do Framework VERL: Os modelos são treinados usando uma versão modificada do projeto VERL, especialmente adaptada para tarefas de raciocínio.
Leia o artigo completo aqui.
Benchmarks do Skywork-OR1-32B
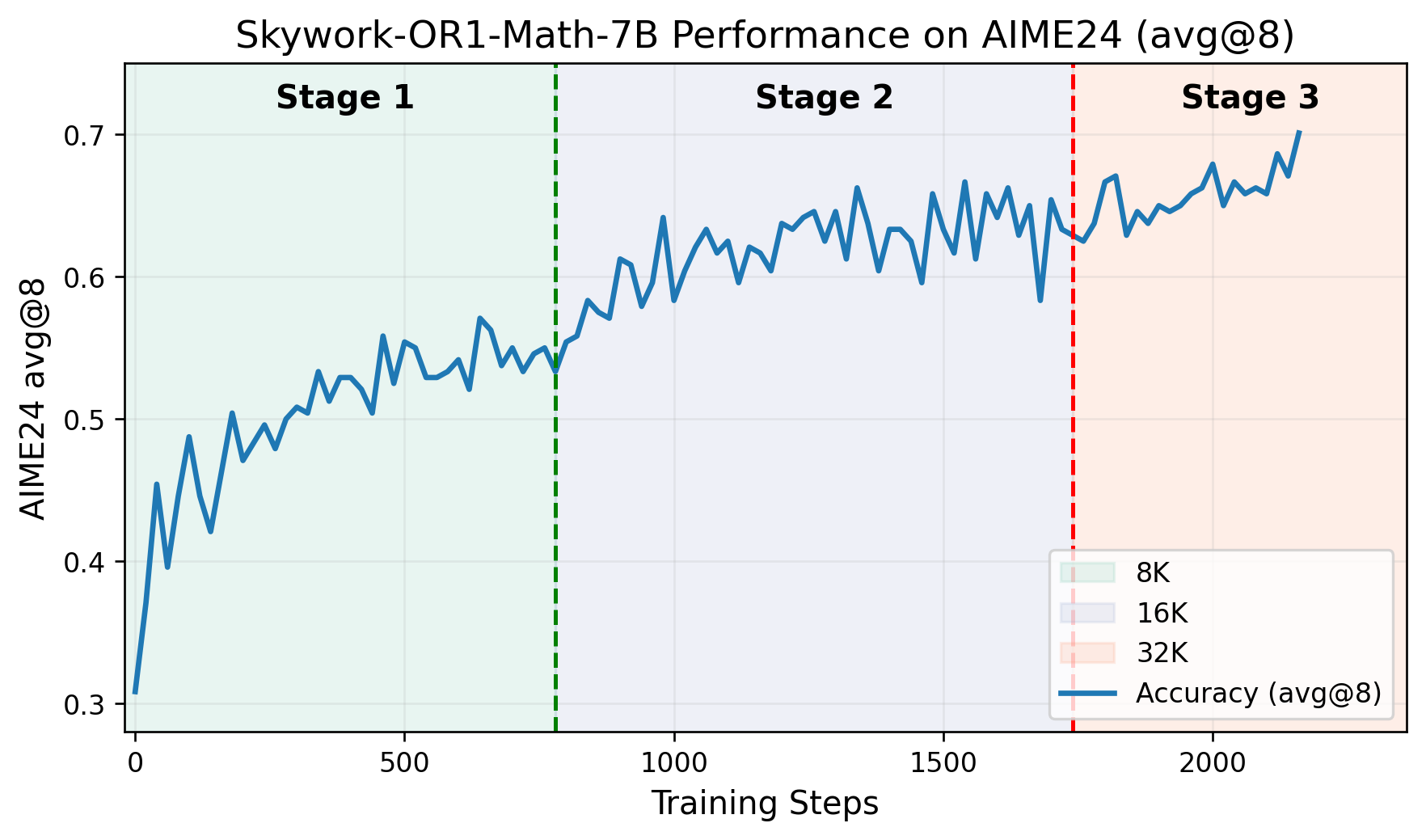
Especificações técnicas:
- Número de parâmetros: 32,8 bilhões
- Tipo de tensor: BF16
- Formato do modelo: Safetensors
- Família de arquitetura: Qwen2
- Modelo base: DeepSeek-R1-Distill-Qwen-32B
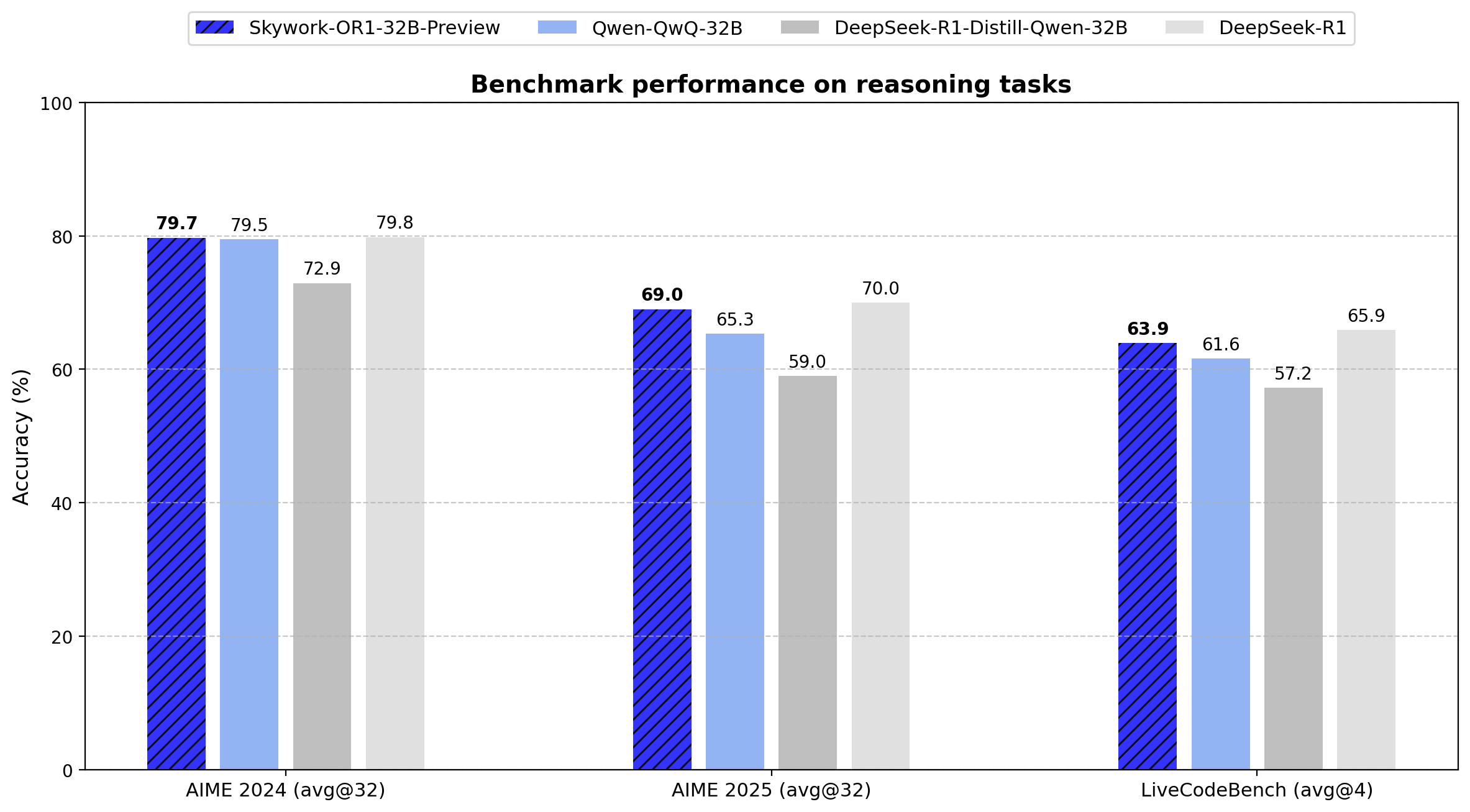
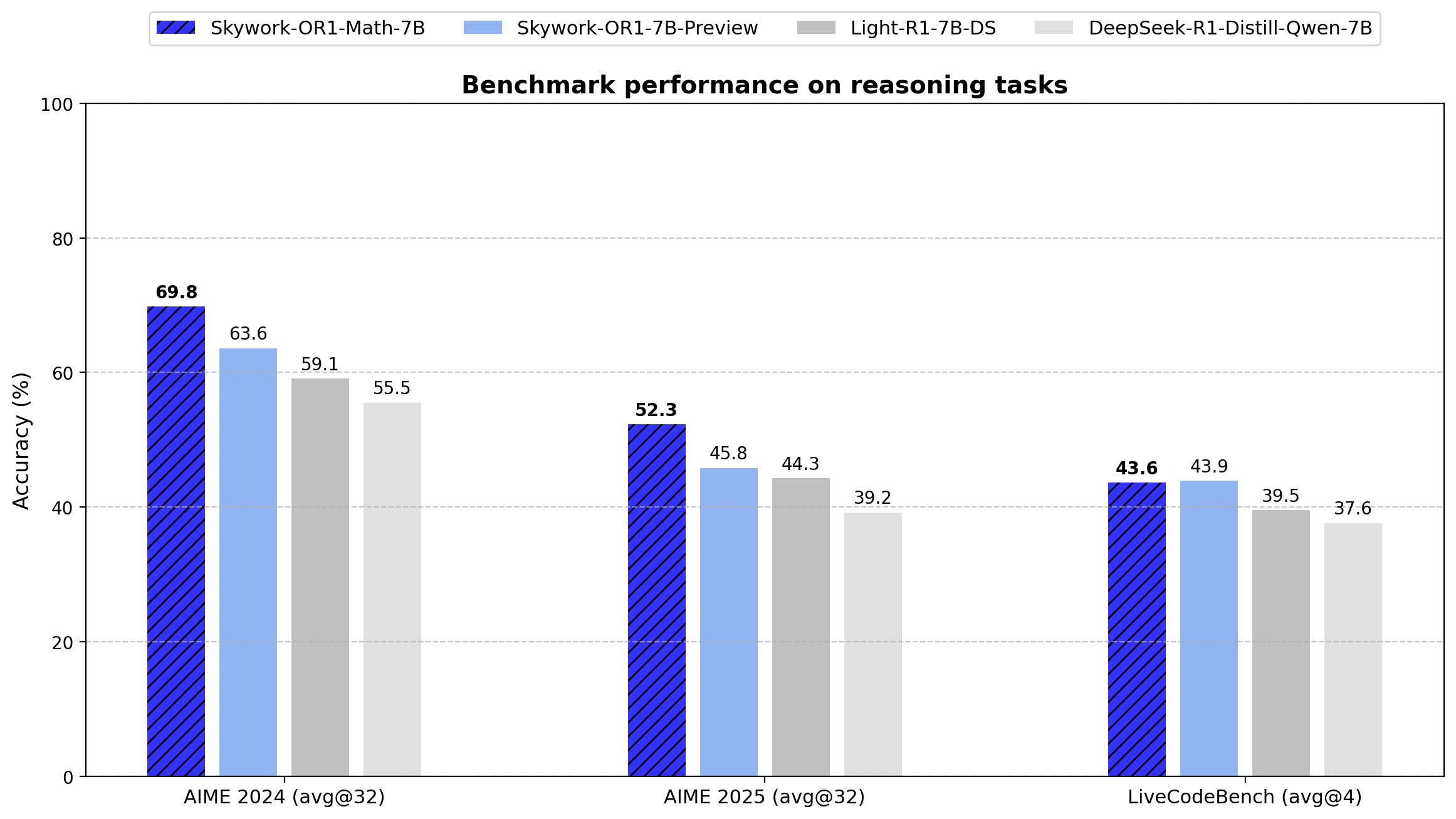
A série Skywork-OR1 introduz Avg@K como sua métrica de avaliação principal, em vez do tradicional Pass@1. Essa métrica calcula o desempenho médio em múltiplas tentativas independentes (32 para os testes AIME, 4 para o LiveCodeBench), reduzindo a variância e fornecendo uma medida mais confiável de consistência no raciocínio.
Abaixo estão os resultados exatos de benchmarks para todos os modelos da série:
Os dados mostram que o Skywork-OR1-32B-Preview apresenta desempenho quase igual ao DeepSeek-R1 (79,7 vs. 79,8 no AIME24, 69,0 vs. 70,0 no AIME25 e 63,9 vs. 65,9 no LiveCodeBench), mesmo tendo 20 vezes menos parâmetros (671B vs. 32,8B).
Como Testar os Modelos Skywork-OR1
Acesse os model cards no Hugging Face dos modelos:



Para executar os scripts de avaliação, siga os passos abaixo:
Ambiente Docker:
docker pull whatcanyousee/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te2.0-megatron0.11.0-v0.0.6
docker run --runtime=
Configuração do Ambiente Conda:
conda create -n verl python==3.10
conda activate verl
pip3 install torch==2.4.0 --index-url <https://download.pytorch.org/whl/cu124>
pip3 install flash-attn --no-build-isolation
git clone <https://github.com/SkyworkAI/Skywork-OR1.git>
cd Skywork-OR1
pip3 install -e .
Reprodução da Avaliação AIME24:
MODEL_PATH=Skywork/Skywork-OR1-32B-Preview \\\\\\\\
DATA_PATH=or1_data/eval/aime24.parquet \\\\\\\\
SAMPLES=32 \\\\\\\\
TASK_NAME=Aime24_Avg-Skywork_OR1_Math_7B \\\\\\\\
bash ./or1_script/eval/eval_32b.sh
Avaliação AIME25:
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\\\\\
DATA_PATH=or1_data/eval/aime25.parquet \\\\\\\\
SAMPLES=32 \\\\\\\\
TASK_NAME=Aime25_Avg-Skywork_OR1_Math_7B \\\\\\\\
bash ./or1_script/eval/eval_7b.sh
Avaliação LiveCodeBench:
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\\\\\
DATA_PATH=or1_data/eval/livecodebench/livecodebench_2408_2502.parquet \\\\\\\\
SAMPLES=4 \\\\\\\\
TASK_NAME=LiveCodeBench_Avg-Skywork_OR1_Math_7B \\\\\\\\
bash ./or1_script/eval/eval_7b.sh
Os modelos atuais da Skywork-OR1 estão marcados como versões "Preview", com lançamentos finais programados para dentro de duas semanas após o anúncio inicial. Os desenvolvedores informaram que documentação técnica adicional será lançada, incluindo:
- Um relatório técnico detalhado sobre a metodologia de treinamento.
- O conjunto de dados Skywork-OR1-RL-Data.
- Scripts de treinamento adicionais.
O repositório no GitHub observa que os scripts de treinamento estão "sendo organizados e estarão disponíveis em 1-2 dias".
 SkyworkAI
SkyworkAIConclusão: Avaliação Técnica do Skywork-OR1-32B
O modelo Skywork-OR1-32B-Preview representa um avanço significativo em modelos de raciocínio eficientes em parâmetros. Com 32,8 bilhões de parâmetros, ele alcança métricas de desempenho quase idênticas ao modelo DeepSeek-R1 de 671 bilhões em vários benchmarks.
Embora ainda não verificado, esses resultados indicam que, para aplicações práticas que exigem capacidades avançadas de raciocínio, o Skywork-OR1-32B-Preview oferece uma alternativa viável a modelos significativamente maiores, com requisitos computacionais substancialmente reduzidos.
Além disso, a natureza open-source desses modelos, junto com seus scripts de avaliação e dados de treinamento futuros, fornece recursos técnicos valiosos para pesquisadores e profissionais que trabalham com capacidades de raciocínio em modelos de linguagem.
Quer uma plataforma integrada e All-in-One para sua equipe de desenvolvedores trabalhar junta com máxima produtividade?
Apidog atende a todas as suas demandas e substitui o Postman a um preço muito mais acessível!