
A paisagem dos grandes modelos de linguagem (LLMs) está evoluindo a uma velocidade impressionante. Os modelos estão se tornando mais poderosos, capazes e, o mais importante, mais acessíveis. A equipe do Qwen revelou recentemente o Qwen3, sua última geração de LLMs, com desempenho impressionante em vários benchmarks, incluindo codificação, matemática e raciocínio geral. Com modelos de destaque como o Mixture-of-Experts (MoE) Qwen3-235B-A22B rivalizando com gigantes estabelecidos e até modelos densos menores como o Qwen3-4B competindo com modelos de 72B parâmetros da geração anterior, o Qwen3 representa um salto significativo para frente.
Um aspecto chave desse lançamento é a abertura de pesos de vários modelos, incluindo duas variantes MoE (Qwen3-235B-A22B e Qwen3-30B-A3B) e seis modelos densos variando de 0,6B a 32B parâmetros. Essa abertura convida desenvolvedores, pesquisadores e entusiastas a explorar, utilizar e construir sobre essas poderosas ferramentas. Embora APIs baseadas em nuvem ofereçam conveniência, o desejo de executar esses sofisticados modelos localmente está crescendo, impulsionado pela necessidade de privacidade, controle de custos, personalização e acessibilidade offline.
Felizmente, o ecossistema de ferramentas para a execução local de LLMs amadureceu significativamente. Duas plataformas de destaque que simplificam esse processo são Ollama e vLLM. Ollama fornece uma maneira incrivelmente amigável de começar a trabalhar com vários modelos, enquanto vLLM oferece uma solução de alta performance otimizada para throughput e eficiência, especialmente para modelos maiores. Este artigo irá guiá-lo na compreensão do Qwen3 e na configuração desses poderosos modelos em sua máquina local, usando tanto Ollama quanto vLLM.
Quer uma plataforma integrada, Tudo-em-Um, para sua Equipe de Desenvolvimento trabalhar junta com máxima produtividade?
Apidog atende todas as suas demandas e substitui o Postman a um preço muito mais acessível!
O que é Qwen 3 e Benchmarks
O Qwen3 representa a terceira geração de grandes modelos de linguagem (LLMs) desenvolvidos pela equipe do Qwen, lançados em abril de 2025. Esta iteração significa um avanço substancial em relação às versões anteriores, focando em capacidades aprimoradas de raciocínio, eficiência por meio de inovações arquitetônicas como Mixture-of-Experts (MoE), suporte multilíngue mais amplo e desempenho melhorado em uma ampla gama de benchmarks. O lançamento incluiu a abertura de pesos de vários modelos sob a licença Apache 2.0, promovendo acessibilidade para pesquisa e desenvolvimento.
Arquitetura do Modelo Qwen 3 e Variantes, Explicadas
A família Qwen3 abrange tanto modelos densos tradicionais quanto arquiteturas MoE esparsas, atendendo a orçamentos computacionais diversos e requisitos de desempenho.
Modelos Densos: Esses modelos utilizam todos os seus parâmetros durante a inferência. Os principais detalhes arquitetônicos incluem:
| Modelo | Camadas | Cabeças de Atenção (Consulta / Chave-Valor) | Vincular Embeddings de Palavras | Comprimento Máximo do Contexto |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Sim | 32.768 tokens (32K) |
| Qwen3-1.7B | 28 | 16 / 8 | Sim | 32.768 tokens (32K) |
| Qwen3-4B | 36 | 32 / 8 | Sim | 32.768 tokens (32K) |
| Qwen3-8B | 36 | 32 / 8 | Não | 131.072 tokens (128K) |
| Qwen3-14B | 40 | 40 / 8 | Não | 131.072 tokens (128K) |
| Qwen3-32B | 64 | 64 / 8 | Não | 131.072 tokens (128K) |
Nota: A Atenção por Consulta Agrupada (GQA) é empregada em todos os modelos, indicada pelo número diferente de cabeças de Consulta e Chave-Valor.
Modelos Mixture-of-Experts (MoE): Esses modelos aproveitam a esparsidade ativando apenas um subconjunto de "especialistas" Redes de Alimentação Direta (FFNs) para cada token durante a inferência. Isso permite uma contagem total de parâmetros elevada, mantendo os custos computacionais mais próximos dos modelos densos menores.
| Modelo | Camadas | Cabeças de Atenção (Consulta / Chave-Valor) | # Especialistas (Total / Ativados) | Comprimento Máximo do Contexto |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131.072 tokens (128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131.072 tokens (128K) |
Nota: Ambos os modelos MoE utilizam 128 especialistas no total, mas ativam apenas 8 por token, reduzindo significativamente a carga computacional em comparação a um modelo denso de tamanho equivalente.
Principais Características Técnicas do Qwen 3
Modos de Pensamento Híbrido: Uma característica distintiva do Qwen3 é sua capacidade de operar em dois modos distintos, controláveis pelo usuário:
- Modo de Pensamento (Padrão): O modelo realiza um raciocínio interno, passo a passo (estilo Cadeia de Pensamentos) antes de gerar a resposta final. Esse processo de pensamento latente é encapsulado, frequentemente marcado por tokens especiais (por exemplo, gerando conteúdo
<think>...</think>antes da resposta final ao usar configurações específicas do framework). Este modo melhora o desempenho em tarefas complexas que requerem dedução lógica, raciocínio matemático ou planejamento. Permite melhorias de desempenho escaláveis diretamente correlacionadas com o orçamento de raciocínio computacional alocado. - Modo Não-Pensante: O modelo gera uma resposta direta sem a fase explícita de raciocínio interno, otimizando para velocidade e custo computacional reduzido em consultas mais simples.
Os usuários podem alternar dinamicamente entre esses modos, potencialmente em uma base de turno a turno em conversas de múltiplos turnos, usando tags como/thinke/no_thinkem seus prompts (se o framework permitir), permitindo controle refinado sobre a troca entre latência/custo e profundidade de raciocínio.
Extensa Suporte Multilíngue: Os modelos Qwen3 são pré-treinados em um corpus diversificado que possibilita suporte para 119 idiomas e dialetos de famílias linguísticas principais (Indo-Europeia, Sino-Tibetana, Afro-Asiática, Austronésia, Dravídica, Turcomana, etc.), tornando-os adequados para uma ampla gama de aplicações globais.
Metodologia Avançada de Treinamento:
- Pré-treinamento: Os modelos foram pré-treinados em um conjunto de dados em larga escala que compreende trilhões de tokens. A fase final de pré-treinamento envolveu o uso de dados de longo contexto de alta qualidade para estender a janela de contexto efetiva para até 32K tokens inicialmente, com extensões adicionais para 128K para modelos maiores.
- Pós-treinamento: Um sofisticado pipeline de quatro estágios foi empregado para dotar os modelos de capacidades de seguimento de instruções, habilidades de raciocínio e o mecanismo de pensamento híbrido:
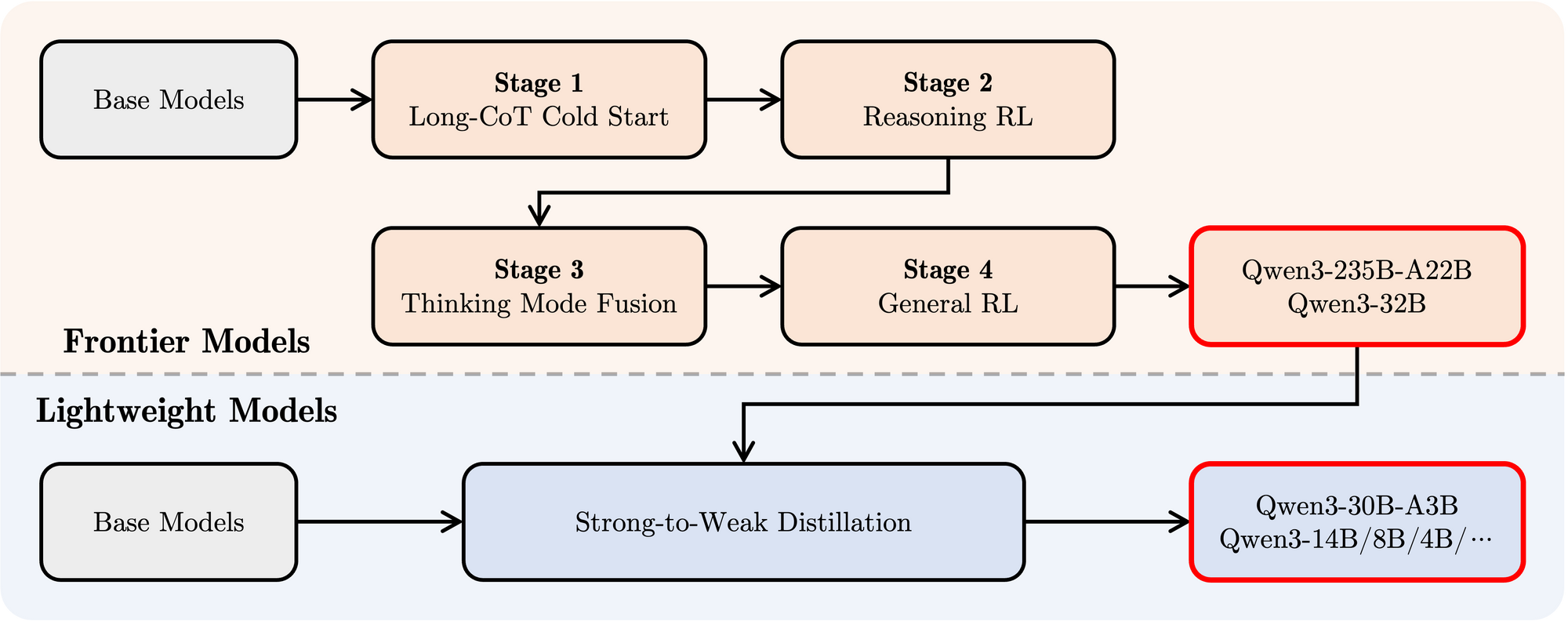
- Long CoT Cold Start: Ajuste fino supervisionado (SFT) em dados de cadeia de pensamento (CoT) longos e diversos, abrangendo matemática, codificação, raciocínio lógico e STEM para construir habilidades fundamentais de raciocínio.
- Aprendizado por Reforço (RL) baseado em Raciocínio: Aumentando os recursos computacionais para RL usando recompensas baseadas em regras para melhorar a exploração e exploração, especificamente para tarefas de raciocínio.
- Fusão do Modo de Pensamento: Integrando capacidades não-pensantes ajustando finamente o modelo aprimorado em raciocínio em uma mistura de dados de longa CoT e dados de ajuste de instruções padrão gerados pelo modelo da Fase 2. Isso combina raciocínio profundo com geração rápida de respostas.
- RL Geral: Aplicando RL em várias tarefas de domínio geral (seguimento de instruções, conformidade de formato, capacidades do agente) para refinar o comportamento geral e mitigar saídas indesejadas.
Desempenho de Benchmark do Qwen 3
O Qwen3 demonstra um desempenho altamente competitivo em comparação com outros modelos contemporâneos líderes:
MoE Flagship: O modelo Qwen3-235B-A22B alcança resultados comparáveis a modelos de ponta como DeepSeek-R1, Google's o1 e o3-mini, Grok-3 e Gemini-2.5-Pro em vários benchmarks que avaliam codificação, matemática e capacidades gerais.
MoE Menor: O modelo Qwen3-30B-A3B superou significativamente modelos como QwQ-32B, apesar de ativar apenas uma fração (3B vs 32B) dos parâmetros durante a inferência, destacando a eficiência da arquitetura MoE.
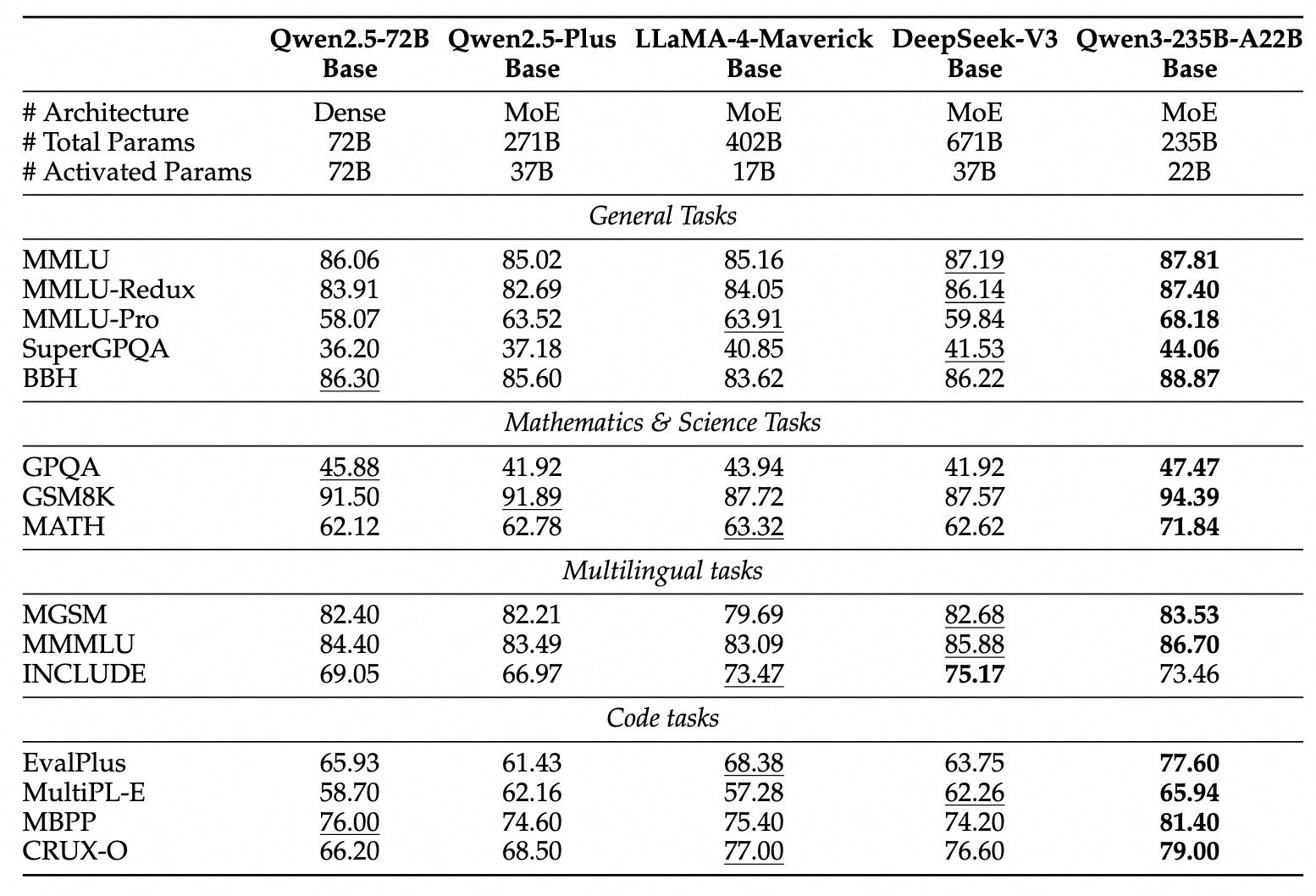
Modelos Densos: Devido a avanços arquitetônicos e de treinamento, os modelos densos do Qwen3 geralmente igualam ou superam o desempenho dos modelos densos maiores do Qwen2.5. Por exemplo:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(e rivaliza comQwen2.5-72B-Instructem alguns aspectos)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
Notavelmente, os modelos base densos do Qwen3 mostram melhorias de desempenho particularmente fortes sobre seus predecessores em STEM, codificação e tarefas de raciocínio.
Eficiência MoE: Os modelos base MoE do Qwen3 alcançam desempenho comparável a modelos densos significativamente maiores do Qwen2.5, ativando apenas ~10% dos parâmetros, resultando em economias substanciais tanto no treinamento quanto na computação de inferência.
Esses resultados de benchmark ressaltam a posição do Qwen3 como uma família de modelos de ponta, oferecendo alto desempenho e, particularmente com variantes MoE, eficiência computacional melhorada. Os modelos estão disponíveis através de plataformas padrão como Hugging Face, ModelScope e Kaggle, e são suportados por frameworks de implantação populares como Ollama, vLLM, SGLang, LMStudio e llama.cpp, facilitando sua integração em vários fluxos de trabalho e aplicações, incluindo execução local.
Como Executar Qwen 3 Localmente com Ollama
Ollama ganhou imensa popularidade por sua simplicidade em baixar, gerenciar e executar LLMs localmente. Ele abstrai grande parte da complexidade, fornecendo uma interface de linha de comando e um servidor API.
1. Instalação:
A instalação do Ollama é normalmente simples. Visite o site oficial do Ollama (ollama.com) e siga as instruções de download para o seu sistema operacional (macOS, Linux, Windows).
2. Baixando Modelos Qwen3:
Ollama mantém uma biblioteca de modelos prontamente disponíveis. Para executar um modelo Qwen3 específico, você usa o comando ollama run. Se o modelo não estiver presente localmente, o Ollama o baixa automaticamente. A equipe do Qwen disponibilizou várias variantes do Qwen3 diretamente na biblioteca do Ollama.
Você pode encontrar tags disponíveis do Qwen3 na página do Qwen3 no site do Ollama (por exemplo, ollama.com/library/qwen3). As tags comuns podem incluir:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(o modelo MoE menor)
Para executar o modelo de 4B parâmetros, por exemplo, basta abrir seu terminal e digitar:
ollama run qwen3:4b
Esse comando irá baixar o modelo (se necessário) e iniciar uma sessão interativa de chat.
3. Interagindo com o Modelo:
Uma vez que o comando ollama run esteja ativo, você pode digitar seus prompts diretamente no terminal. Ollama também inicia um servidor local (tipicamente em http://localhost:11434) que expõe uma API compatível com o padrão OpenAI. Você pode interagir com isso programaticamente usando ferramentas como curl ou várias bibliotecas de cliente em Python, JavaScript, etc.
4. Considerações de Hardware:
Executar LLMs localmente requer recursos substanciais.
- RAM: Mesmo modelos menores (0.6B, 1.7B) requerem vários gigabytes de RAM. Modelos maiores (8B, 14B, 32B, 30B-A3B) necessitam significativamente mais, frequentemente 16GB, 32GB ou até 64GB+, dependendo do nível de quantização utilizado pelo Ollama.
- VRAM (GPU): Para desempenho aceitável, uma GPU dedicada com ampla VRAM é altamente recomendada. O Ollama utiliza automaticamente GPUs compatíveis (NVIDIA, Apple Silicon). A quantidade de VRAM dita o maior modelo que você pode executar confortavelmente inteiramente na GPU, o que acelera significativamente a inferência.
- CPU: Embora o Ollama possa executar modelos na CPU, o desempenho será consideravelmente mais lento do que em uma GPU.
Ollama é excelente para começar rapidamente, desenvolvimento local, experimentação e aplicações de chat para um único usuário, especialmente em hardware de consumo (dentro dos limites).
Como Executar o Ollama Localmente com vLLM
vLLM é uma biblioteca de serviço de LLM de alto throughput que emprega otimizações como PagedAttention para melhorar significativamente a velocidade de inferência e a eficiência de memória, tornando-a ideal para aplicações exigentes e para atender modelos maiores. A equipe do vLLM oferece excelente suporte para novas arquiteturas, incluindo suporte Dia 0 para Qwen3 no seu lançamento.
1. Instalação:
Instale o vLLM usando pip. Normalmente, é recomendado usar um ambiente virtual:
pip install -U vllm
Certifique-se de ter os pré-requisitos necessários, tipicamente uma GPU NVIDIA compatível com o toolkit CUDA instalado. Consulte a documentação do vLLM para requisitos específicos.
2. Servindo Modelos Qwen3:
vLLM usa o comando vllm serve para carregar um modelo e lançar um servidor API compatível com OpenAI. A equipe do Qwen e a documentação do vLLM fornecem orientações sobre como executar o Qwen3.
Com base nas informações fornecidas e no uso comum do vLLM, aqui está como você pode servir o grande modelo Qwen3-235B MoE usando quantização FP8 (para redução do uso de memória) e paralelismo de tensor em 4 GPUs:
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
Vamos analisar esse comando:
Qwen/Qwen3-235B-A22B-FP8: Este é o identificador do modelo, provavelmente apontando para um repositório do Hugging Face.FP8indica o uso de quantização de ponto flutuante de 8 bits, reduzindo a pegada de memória do modelo em comparação a FP16 ou BF16, o que é crucial para um modelo tão grande.--enable-reasoning: Esta flag é vital para ativar as capacidades de pensamento híbrido do Qwen3 dentro do vLLM.--reasoning-parser deepseek_r1: A saída de pensamento do Qwen3 tem um formato específico. O vLLM requer um parser para lidar com isso. O post do blog indica que para o vLLM, o parserdeepseek_r1deve ser usado (enquanto o SGLang usa um parserqwen3). Isso garante que o vLLM possa interpretar corretamente e potencialmente separar os passos de pensamento da resposta final.--tensor-parallel-size 4: Isso instrui o vLLM a distribuir os pesos do modelo e a computação entre 4 GPUs. O paralelismo de tensor é essencial para executar modelos muito grandes para caber em uma única GPU. Você deve ajustar esse número com base nas GPUs disponíveis.
Você pode adaptar esse comando para outros modelos do Qwen3 (por exemplo, Qwen/Qwen3-30B-A3B ou Qwen/Qwen3-32B) e ajustar parâmetros como tensor-parallel-size com base no seu hardware.
3. Interagindo com o Servidor vLLM:
Uma vez que o vllm serve esteja em execução, ele hospeda um servidor API (default para http://localhost:8000) que espelha a especificação da API OpenAI. Você pode interagir com isso usando ferramentas padrão:
- curl:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # Use o nome do modelo que você serviu
"prompt": "Explique o conceito de Mixture-of-Experts em LLMs.",
"max_tokens": 150,
"temperature": 0.7
}'
- Cliente OpenAI para Python:
from openai import OpenAI
# Aponte para o servidor vLLM local
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # Use o nome do modelo que você serviu
prompt="Escreva uma história curta sobre um robô descobrindo música.",
max_tokens=200
)
print(completion.choices[0].text)
4. Desempenho e Casos de Uso:
vLLM brilha em cenários que requerem alto throughput (muitas requisições por segundo) e baixa latência. Suas otimizações o tornam adequado para:
- Construir aplicações movidas por LLMs locais.
- Atender modelos para múltiplos usuários simultaneamente.
- Implantar grandes modelos que necessitam de configurações multi-GPU.
- Ambientes de produção onde o desempenho é crítico.
Testando a API Local do Ollama com Apidog
Apidog é uma ferramenta de teste de API que combina bem com o modo API do Ollama. Permite que você envie solicitações, visualize respostas e depure sua configuração do Qwen 3 de forma eficiente.
Veja como usar o Apidog com o Ollama:
- Crie uma nova solicitação API:
- Endpoint:
http://localhost:11434/api/generate - Envie a solicitação e monitore a resposta na linha do tempo em tempo real do Apidog.
- Use a extração JSONPath do Apidog para analisar respostas automaticamente, um recurso que supera ferramentas como o Postman.


Respostas em Streaming:
- Para aplicações em tempo real, ative o streaming:
- O recurso Auto-Merge do Apidog consolida mensagens transmitidas, simplificando a depuração.
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "Escreva um poema sobre IA.", "stream": true}'

Esse processo garante que seu modelo funcione como esperado, tornando o Apidog uma adição valiosa.
Conclusão
O lançamento da poderosa e diversificada família de modelos Qwen3, combinado com ferramentas maduras de execução local como Ollama e vLLM, marca um momento emocionante para os profissionais de IA. Seja priorizando a simplicidade plug-and-play do Ollama para uso pessoal e experimentação ou as capacidades de serviço de alto desempenho do vLLM para construir aplicações robustas, executar LLMs de ponta localmente é mais viável do que nunca.
Ao trazer modelos como Qwen3-30B-A3B ou até mesmo os maiores variantes densos para seu próprio hardware, você ganha controle, privacidade e custo-benefício sem precedentes. Você pode aproveitar suas características avançadas, como pensamento híbrido e amplo suporte multilíngue, para projetos inovadores. À medida que os ecossistemas de hardware e software continuam a melhorar, o poder dos grandes modelos de linguagem se tornará cada vez mais democratizado, movendo-se de servidores em nuvem distantes diretamente para nossas máquinas locais. Experimente o Qwen3 usando Ollama e vLLM para vivenciar a vanguarda desta revolução local de IA.
Quer uma plataforma integrada, Tudo-em-Um, para sua Equipe de Desenvolvimento trabalhar junta com máxima produtividade?
Apidog atende todas as suas demandas e substitui o Postman a um preço muito mais acessível!