
Executar modelos de linguagem grandes como o Mistral 3 em sua máquina local oferece aos desenvolvedores controle incomparável sobre a privacidade dos dados, velocidade de inferência e customização. À medida que as cargas de trabalho de IA se tornam mais exigentes, a execução local torna-se essencial para prototipagem, teste e implantação de aplicativos offline. Além disso, ferramentas como o Ollama simplificam esse processo, permitindo que você aproveite as capacidades do Mistral 3 diretamente de seu desktop ou servidor.
Este guia fornece instruções passo a passo para instalar e executar variantes do Mistral 3 localmente. Focamos na série de código aberto Ministral 3, que se destaca em implantações de borda. Ao final, você otimizará o desempenho para tarefas do mundo real, garantindo respostas de baixa latência e eficiência de recursos.
Compreendendo o Mistral 3: A Potência de Código Aberto na IA
A Mistral AI continua a ultrapassar limites com seu último lançamento: Mistral 3. Desenvolvedores e pesquisadores elogiam esta família de modelos por equilibrar precisão, eficiência e acessibilidade. Ao contrário de gigantes proprietários, o Mistral 3 adota princípios de código aberto, sendo lançado sob a licença Apache 2.0. Essa medida capacita a comunidade a modificar, distribuir e inovar sem restrições.
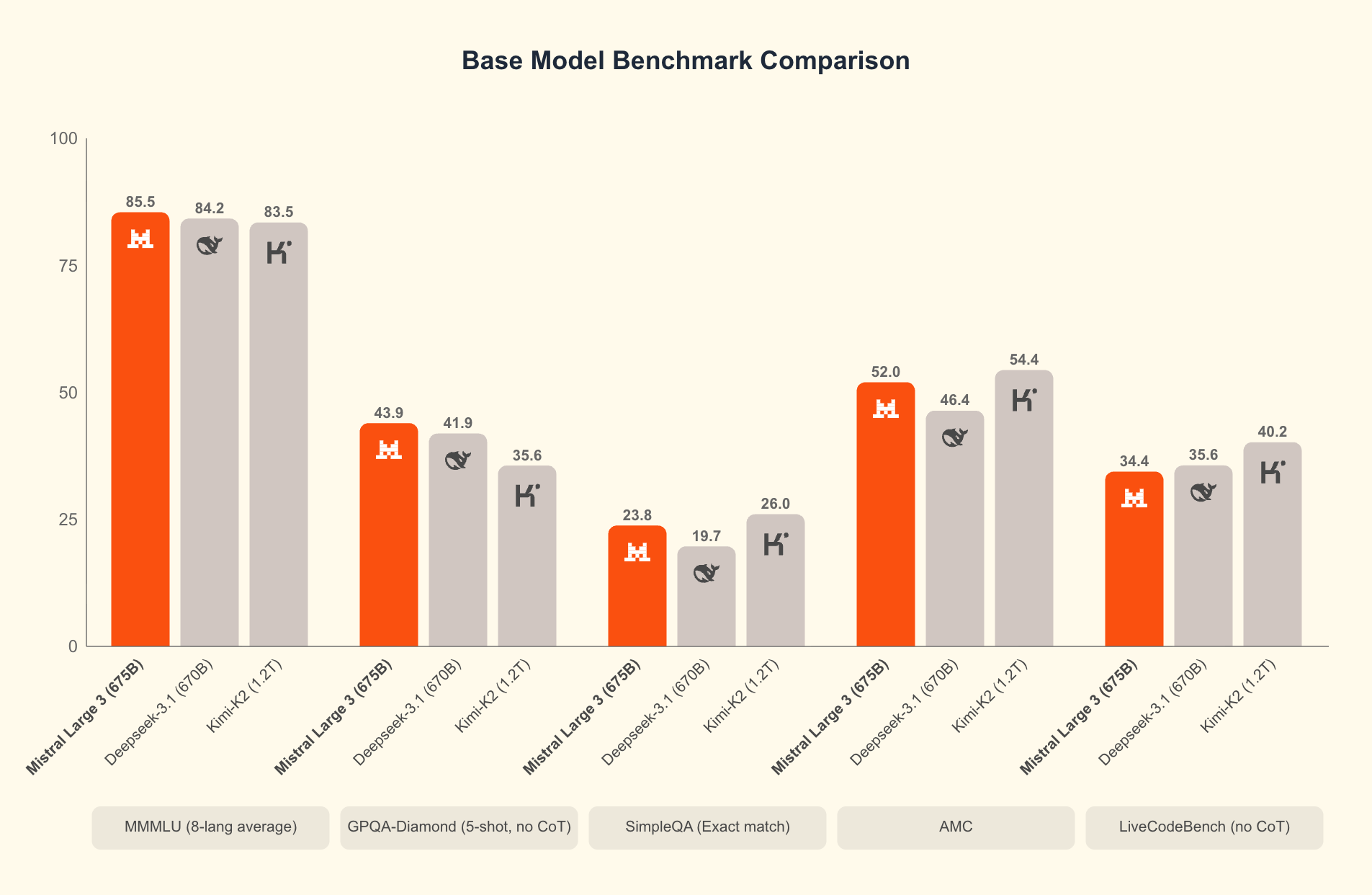
Em sua essência, o Mistral 3 compreende dois ramos principais: a série compacta Ministral 3 e o expansivo Mistral Large 3. Os modelos Ministral 3—disponíveis em tamanhos de parâmetros de 3B, 8B e 14B—visam ambientes com recursos limitados. Engenheiros os projetam para casos de uso local e de borda, onde cada watt e núcleo contam. Por exemplo, a variante 3B cabe confortavelmente em laptops com GPUs modestas, enquanto a 14B ultrapassa limites em configurações multi-GPU sem sacrificar a velocidade.
O Mistral Large 3, por outro lado, emprega uma arquitetura esparsa de mistura de especialistas com 41B parâmetros ativos e 675B no total. Este design ativa apenas especialistas relevantes por consulta, reduzindo significativamente a sobrecarga computacional. Os desenvolvedores acessam versões ajustadas por instruções para tarefas como assistência de codificação, resumo de documentos e tradução multilíngue. O modelo suporta mais de 40 idiomas nativamente, superando concorrentes em diálogos não ingleses.
O que diferencia o Mistral 3? Benchmarks revelam sua vantagem em cenários do mundo real. No conjunto de dados GPQA Diamond—um teste rigoroso de raciocínio científico—as variantes do Mistral 3 mantêm alta precisão mesmo com o aumento dos tokens de saída. Por exemplo, o modelo Ministral 3B Instruct mantém cerca de 35-40% de precisão até 20.000 tokens, rivalizando com modelos maiores como o Gemma 2 9B, utilizando menos recursos. Essa eficiência decorre de técnicas avançadas de quantização, como a compressão NVFP4, que reduz o tamanho do modelo sem degradar a qualidade da saída.
Além disso, o Mistral 3 integra recursos multimodais, processando imagens junto com texto para aplicações em resposta a perguntas visuais ou geração de conteúdo. O open-sourcing desses modelos promove uma rápida iteração; as comunidades já os ajustam para domínios especializados como análise jurídica ou escrita criativa. Como resultado, o Mistral 3 democratiza a IA de ponta, permitindo que startups e desenvolvedores individuais compitam com grandes empresas de tecnologia.

Transitando da teoria para a prática, a execução desses modelos localmente libera todo o seu potencial. As APIs de nuvem introduzem latência e custos, mas a inferência local oferece respostas em menos de um segundo. Em seguida, examinamos os pré-requisitos de hardware que tornam isso viável.
Por Que Executar o Mistral 3 Localmente? Benefícios Para Desenvolvedores e Ganhos de Eficiência
Desenvolvedores escolhem a execução local por várias razões convincentes. Primeiro, a privacidade é fundamental: dados sensíveis permanecem em sua máquina, evitando servidores de terceiros. Em setores regulamentados como saúde ou finanças, essa vantagem de conformidade prova ser inestimável. Segundo, a economia de custos acumula rapidamente. A alta eficiência do Mistral 3 significa que você evita taxas por token, ideal para testes de alto volume.
Além disso, as execuções locais aceleram a experimentação. Itere em prompts, ajuste hiperparâmetros ou encadeie modelos sem atrasos de rede. Benchmarks confirmam isso: em hardware de consumo, o Ministral 8B alcança 50-60 tokens por segundo, comparável a configurações de nuvem, mas com zero tempo de inatividade.
A eficiência define o apelo do Mistral 3. Os modelos são otimizados para inferência de baixo custo, como mostram os resultados do GPQA Diamond, onde as variantes do Ministral superam o Gemma 3 4B e 12B em precisão sustentada. Isso é importante para tarefas de contexto longo; à medida que as saídas se estendem para 20.000 tokens, a precisão cai minimamente, garantindo um desempenho confiável em chatbots ou geradores de código.
Além disso, o acesso de código aberto via plataformas como o Hugging Face permite a integração perfeita com ferramentas como o Apidog para prototipagem de API. Teste endpoints do Mistral 3 localmente antes de escalar, preenchendo a lacuna entre o desenvolvimento e a produção.
No entanto, o sucesso depende de uma configuração adequada. Com o hardware no lugar, você prossegue para a instalação. Esta preparação garante uma operação suave e maximiza o rendimento.
Requisitos de Hardware e Software para Implantação Local do Mistral 3
Antes de iniciar o Mistral 3, avalie as capacidades do seu sistema. As especificações mínimas incluem uma CPU moderna (Intel i7 ou AMD Ryzen 7) com 16 GB de RAM para o modelo 3B. Para as variantes 8B e 14B, aloque 32 GB de RAM e uma GPU NVIDIA com pelo menos 8 GB de VRAM—pense em uma RTX 3060 ou superior. Usuários de Apple Silicon se beneficiam da memória unificada; um M1 Pro com 16 GB lida com o 3B sem esforço, enquanto um M3 Max se destaca com o 14B.
As demandas de armazenamento variam: o modelo 3B ocupa ~2 GB quantizado, escalando para ~9 GB para o 14B. Use SSDs para carregamento mais rápido. Sistemas operacionais? Linux (Ubuntu 22.04) oferece o melhor desempenho, seguido por macOS Ventura+. O Windows 11 funciona via WSL2, embora o passthrough de GPU exija ajustes.
Em termos de software, Python 3.10+ forma a espinha dorsal. Instale o CUDA 12.1 para placas NVIDIA para habilitar a aceleração de GPU—essencial para latências abaixo de 100ms. Para execuções apenas de CPU, utilize bibliotecas como ONNX Runtime.
A quantização desempenha um papel fundamental aqui. O Mistral 3 suporta formatos de 4 bits e 8 bits, reduzindo a pegada de memória em 75% enquanto preserva 95% de precisão. Ferramentas como bitsandbytes lidam com isso automaticamente.
Uma vez equipado, a instalação segue um caminho direto. Recomendamos o Ollama por sua simplicidade, mas existem alternativas. Essa escolha simplifica o processo, levando-nos aos passos de configuração essenciais.
Instalando o Ollama: O Portal Para IA Local Sem Esforço
Ollama se destaca como a principal ferramenta para executar modelos de código aberto como o Mistral 3 localmente. Esta plataforma leve abstrai complexidades, fornecendo uma CLI e um servidor de API em um único pacote. Desenvolvedores apreciam seu suporte multiplataforma e detecção de GPU sem configuração.
Comece baixando o Ollama do site oficial (ollama.com). No Linux, execute:
curl -fsSL https://ollama.com/install.sh | sh
Este script instala binários e configura serviços. Verifique com ollama --version; espere uma saída como "ollama version 0.3.0". Para macOS, o instalador DMG lida com dependências, incluindo Rosetta para emulação Intel em ARM.
Usuários de Windows obtêm o EXE dos lançamentos do GitHub. Após a instalação, inicie via PowerShell: ollama serve. O Ollama demoniza em segundo plano, expondo uma API REST na porta 11434.
Por que Ollama? Ele extrai modelos de seu registro, incluindo o Ministral 3, com quantização embutida. Nenhuma clonagem manual do Hugging Face é necessária. Além disso, ele suporta Modelfiles para ajuste fino personalizado, alinhando-se com o ethos de código aberto do Mistral 3.
Com o Ollama pronto, você extrairá e executará os modelos em seguida. Este passo transforma sua configuração em uma estação de trabalho de IA funcional.
Baixando e Executando Modelos Ministral 3 com Ollama
A biblioteca do Ollama hospeda variantes do Ministral 3.
Comece listando as tags disponíveis:
ollama list
Para baixar o modelo 3B:
ollama pull ministral:3b-instruct-q4_0
Este comando busca ~2 GB, verificando a integridade via hashes. As barras de progresso acompanham o download, geralmente concluído em minutos em banda larga.
Inicie uma sessão interativa:
ollama run ministral-3
O Ollama carrega o modelo na memória, aquecendo os caches para consultas subsequentes. Digite prompts diretamente; por exemplo:
>> Explique o entrelaçamento quântico em termos simples.

O modelo responde em tempo real, aproveitando o ajuste por instrução para saídas coerentes. Saia com /bye.
Problemas comuns? Se ocorrer subutilização da GPU, defina a variável de ambiente OLLAMA_NUM_GPU=999. Para erros de OOM, diminua para uma quantização mais baixa como q3_K_M.
Além do básico, a API do Ollama permite acesso programático. Curl uma conclusão:
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "Escreva uma função Python para ordenar uma lista.",
"stream": false
}'
Esta resposta JSON inclui texto gerado, perfeito para integração com o Apidog durante o desenvolvimento de API.
A execução de modelos marca o início; a otimização eleva o desempenho. Consequentemente, voltamos nossa atenção para técnicas que extraem cada gota de eficiência do seu hardware.
Otimizando a Inferência do Mistral 3: Velocidade, Memória e Compromissos de Precisão
A eficiência define o sucesso da IA local. O design do Mistral 3 brilha aqui, mas ajustes amplificam os ganhos. Comece com a quantização: o Ollama usa Q4_0 por padrão, equilibrando tamanho e fidelidade. Para recursos ultrabaixos, experimente Q2_K—reduzindo a memória pela metade com um custo de perplexidade de 10%.
A orquestração da GPU é importante. Habilite a atenção flash via OLLAMA_FLASH_ATTENTION=1 para acelerações de 2x em contextos longos. O Mistral 3 suporta até 128K tokens; teste com prompts no estilo GPQA para verificar a precisão sustentada.
O processamento em lote aumenta o throughput. Use /api/generate do Ollama com vários prompts em paralelo, aproveitando clientes Python assíncronos. Por exemplo, programe um loop:
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["Prompt 1", "Prompt 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
Isso lida com mais de 10 consultas por segundo em configurações de vários núcleos.
O gerenciamento de memória evita trocas. Monitore com nvidia-smi; descarregue camadas para a CPU se a VRAM atingir o limite. Bibliotecas como vLLM se integram ao Ollama para processamento contínuo em lote, sustentando 100 tokens/segundo em A100s.
Ajuste de precisão? Ajuste fino com adaptadores LoRA em dados de domínio. A biblioteca PEFT do Hugging Face os aplica ao Ministral 3, exigindo ~1GB de espaço extra. Após o ajuste fino, exporte para o formato Ollama via ollama create.
Compare sua configuração com o GPQA Diamond. Avaliações de script para plotar a precisão versus tokens, espelhando os gráficos do Mistral. Variantes de alta eficiência como o Ministral 8B mantêm pontuações de 50%+, ressaltando sua vantagem sobre o Qwen 2.5 VL.
Essas otimizações o preparam para aplicações avançadas. Assim, exploramos integrações que estendem o alcance do Mistral 3.
Integrando o Mistral 3 com Ferramentas de Desenvolvimento: APIs e Além
O Mistral 3 local prospera em ecossistemas. Emparelhe-o com o Apidog para simular APIs com IA. Projete endpoints que consultam o Ollama, testam payloads e validam respostas—tudo offline.
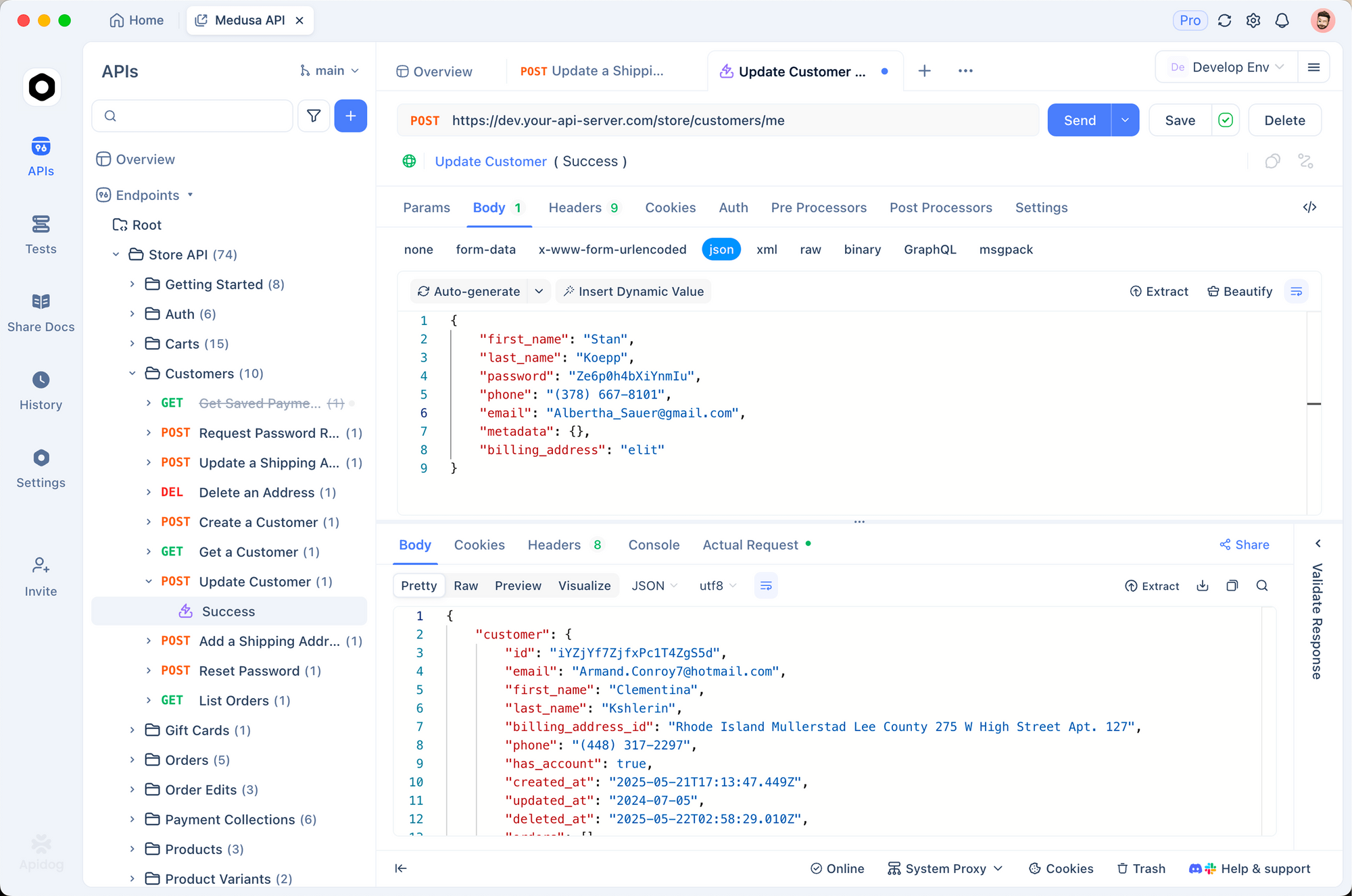
Por exemplo, crie uma rota POST /generate no Apidog, encaminhando para a API do Ollama. Importe coleções para modelos de prompt, garantindo que o Mistral 3 lide com solicitações multilíngues sem falhas.
Usuários do LangChain encadeiam o Mistral 3 com ferramentas:
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("Traduza {text} para o francês.")
chain = prompt | llm
print(chain.invoke({"text": "Olá mundo"}))
Essa configuração processa 50 consultas/minuto, ideal para pipelines RAG.
Dashboards do Streamlit visualizam saídas. Incorpore chamadas do Ollama em aplicativos para chats interativos, aproveitando o raciocínio do Mistral 3 para perguntas e respostas dinâmicas.
Considerações de segurança? Execute o Ollama atrás de proxies NGINX, limitando as taxas dos endpoints. Para produção, conteinerize com Docker:
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
Isso isola ambientes, escalando para Kubernetes.
À medida que os aplicativos evoluem, o monitoramento se torna fundamental. Ferramentas como o Prometheus rastreiam a latência, alertando sobre desvios da eficiência de base.
Em resumo, essas integrações transformam o Mistral 3 de um modelo autônomo em um motor versátil. No entanto, surgem desafios; abordá-los garante implantações robustas.
Solucionando Problemas Comuns em Execuções Locais do Mistral 3
Mesmo configurações otimizadas encontram obstáculos. A incompatibilidade de CUDA lidera a lista: verifique as versões com nvcc --version. Faça downgrade se surgirem conflitos, pois o Mistral 3 tolera 11.8+.
Falha no carregamento do modelo? Limpe o cache do Ollama: ollama rm ministral:3b-instruct-q4_0 e depois puxe novamente. Downloads corrompidos resultam de problemas de rede; use --insecure com moderação.
No macOS, a aceleração Metal é mais lenta que a CUDA. Force a CPU para estabilidade: OLLAMA_METAL=0. Usuários do Windows WSL habilitam drivers NVIDIA via wsl --update.
O superaquecimento afeta laptops; regule com nvidia-smi -pl 100 para limitar o consumo de energia. Para quedas de precisão, inspecione os prompts—o Ministral 3 se destaca em formatos de instrução.
Fóruns da comunidade no Reddit e Hugging Face resolvem 90% dos casos de borda. Registre erros com OLLAMA_DEBUG=1 para diagnósticos.
Com os obstáculos superados, o Mistral 3 entrega valor consistente. Por fim, refletimos sobre seu impacto mais amplo.
Conclusão: Aproveite o Mistral 3 Localmente para as Inovações de IA do Amanhã
O Mistral 3 redefine a IA de código aberto com sua combinação de poder e praticidade. Ao executá-lo localmente via Ollama, os desenvolvedores ganham velocidade, privacidade e controle de custos inatingíveis em outro lugar. Desde o download de modelos até o ajuste fino de integrações, este guia fornece passos acionáveis.
Experimente com ousadia: comece com a variante 3B, escale para 14B e compare com benchmarks. À medida que a Mistral AI itera, as execuções locais o mantêm à frente.
Pronto para construir? Baixe o Apidog gratuitamente e prototype APIs alimentadas pela sua configuração do Mistral 3. O futuro da IA eficiente começa em sua máquina—faça valer a pena.