
Introdução ao Llama 3.1 Instruct 405B
O Llama 3.1 da Meta Instruct 405B representa um grande avanço no campo dos grandes modelos de linguagem (LLMs). Como o nome sugere, este gigante possui impressionantes 405 bilhões de parâmetros, tornando-se um dos maiores modelos de IA disponíveis publicamente até hoje. Essa escala massiva se traduz em capacidades aprimoradas em uma ampla gama de tarefas, desde compreensão e geração de linguagem natural até raciocínio complexo e resolução de problemas.
Uma das características mais notáveis do Llama 3.1 405B é sua janela de contexto expandida de 128.000 tokens. Esse aumento substancial em relação às versões anteriores permite que o modelo processe e gere textos muito mais longos, abrindo novas possibilidades para aplicações como criação de conteúdo em formato longo, análise de documentos aprofundada e interações conversacionais prolongadas.
O modelo se destaca em áreas como:
- Resumo de texto e precisão
- Raciocínio e análise nuançados
- Capacidades multilíngues (suportando 8 idiomas)
- Geração e compreensão de código
- Potencial de ajuste fino específico para tarefas
Com sua natureza de código aberto, o Llama 3.1 405B está prestes a democratizar o acesso à tecnologia de IA de ponta, permitindo que pesquisadores, desenvolvedores e empresas aproveitem seu poder para uma ampla gama de aplicações.
Comparação de Provedores de API do Llama 3.1
Vários provedores de nuvem oferecem acesso aos modelos Llama 3.1 através de suas APIs. Vamos comparar algumas das opções mais proeminentes:
| Provedor | Preço (por milhão de tokens) | Velocidade de Saída | Latência | Principais Recursos |
|---|---|---|---|---|
| Together.ai | $7.50 (taxa combinada) | 70 tokens/segundo | Moderada | Velocidade de saída impressionante |
| Fireworks | $3.00 (taxa combinada) | Boa | 0.57 segundos (muito baixa) | Preços mais competitivos |
| Microsoft Azure | Varia conforme o nível de uso | Moderada | 0.00 segundos (quase instantâneo) | Menor latência |
| Replicate | $9.50 (tokens de saída) | 29 tokens/segundo | Mais alto que alguns concorrentes | Modelo de preços direto |
| Anakin AI | $9.90/mês (modelo Freemium) | Não especificado | Não especificado | Construtor de aplicativos de IA sem código |
- Together.ai: Oferece uma velocidade de saída impressionante de 70 tokens/segundo, tornando-se ideal para aplicações que requerem respostas rápidas. Seu preço é competitivo a $7.50 por milhão de tokens, equilibrando desempenho e custo.
- Fireworks: Destaca-se com os preços mais competitivos a $3.00 por milhão de tokens e muito baixa latência (0.57 segundos). Isso o torna uma excelente escolha para projetos sensíveis a custos que também requerem tempos de resposta rápidos.
- Microsoft Azure: Apresenta a menor latência (quase instantânea) entre os provedores, o que é crucial para aplicações em tempo real. No entanto, sua estrutura de preços varia conforme os níveis de uso, o que pode dificultar a estimativa de custos.
- Replicate: Oferece um modelo de preços direto a $9.50 por milhão de tokens de saída. Embora sua velocidade de saída (29 tokens/segundo) seja inferior à do Together.ai, ainda fornece um desempenho decente para muitos casos de uso.
- Anakin AI: A abordagem da Anakin AI difere significativamente dos outros provedores, focando na acessibilidade e personalização, em vez de métricas de desempenho bruto. Suporta múltiplos modelos de IA, incluindo GPT-3.5, GPT-4 e Claude 2 & 3, oferecendo flexibilidade em várias tarefas de IA. Começa com um modelo freemium, com planos a partir de $9.90/mês.
Como Fazer Chamadas de API para Modelos Llama 3.1 Usando Apidog
Para aproveitar o poder do Llama 3.1, você precisará fazer chamadas de API para o provedor escolhido. Embora o processo exato possa variar ligeiramente entre os provedores, os princípios gerais permanecem os mesmos.
Aqui está um guia passo a passo sobre como fazer chamadas de API usando Apidog:
- Abra o Apidog: Inicie o Apidog e crie uma nova solicitação.
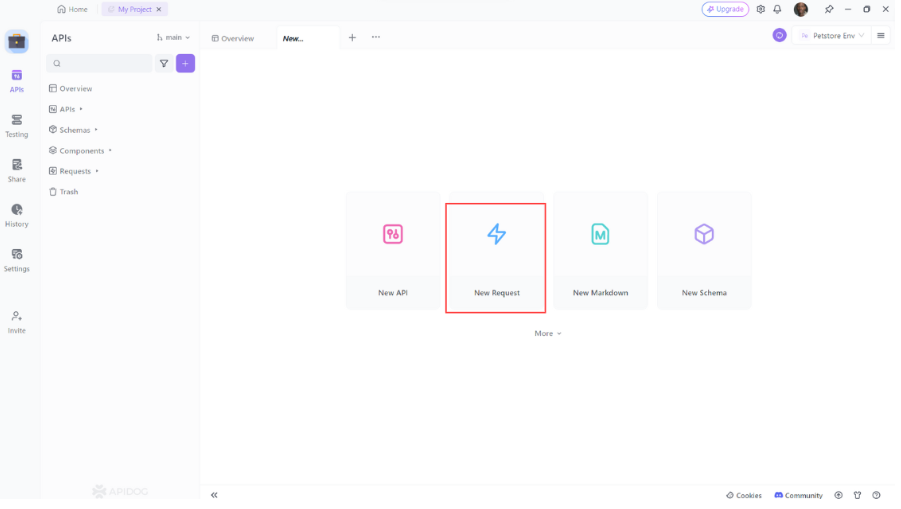
2. Selecione o Método HTTP: Escolha "GET" como método de solicitação ou "Post"
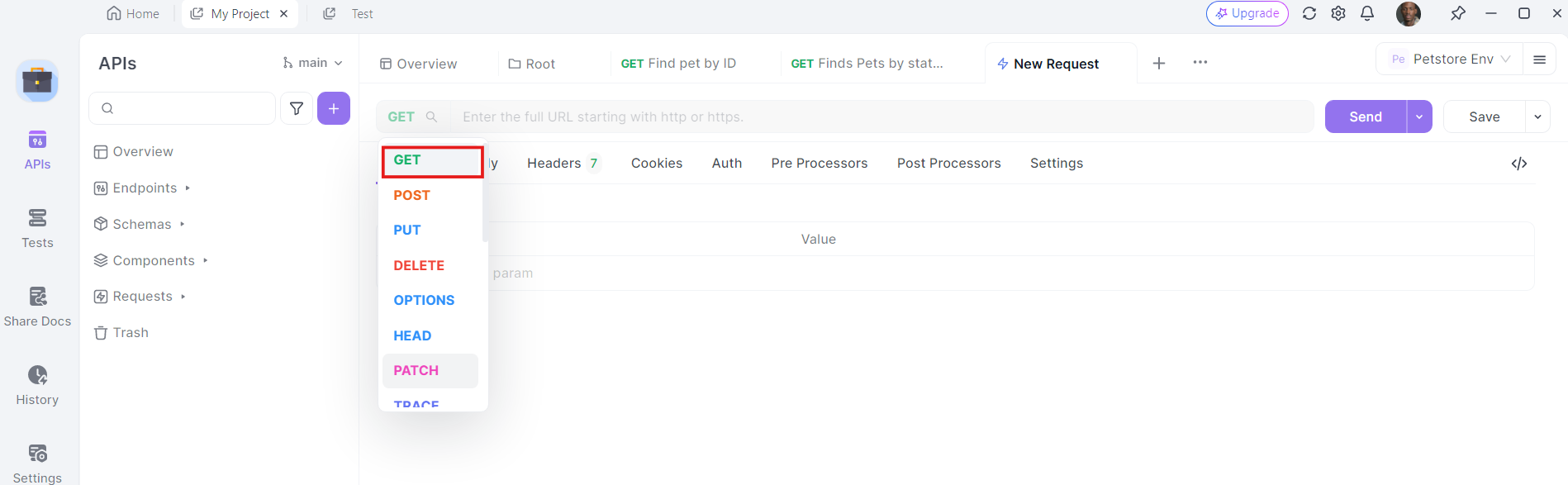
3. Insira a URL: No campo da URL, insira o endpoint para o qual você deseja enviar a solicitação GET.
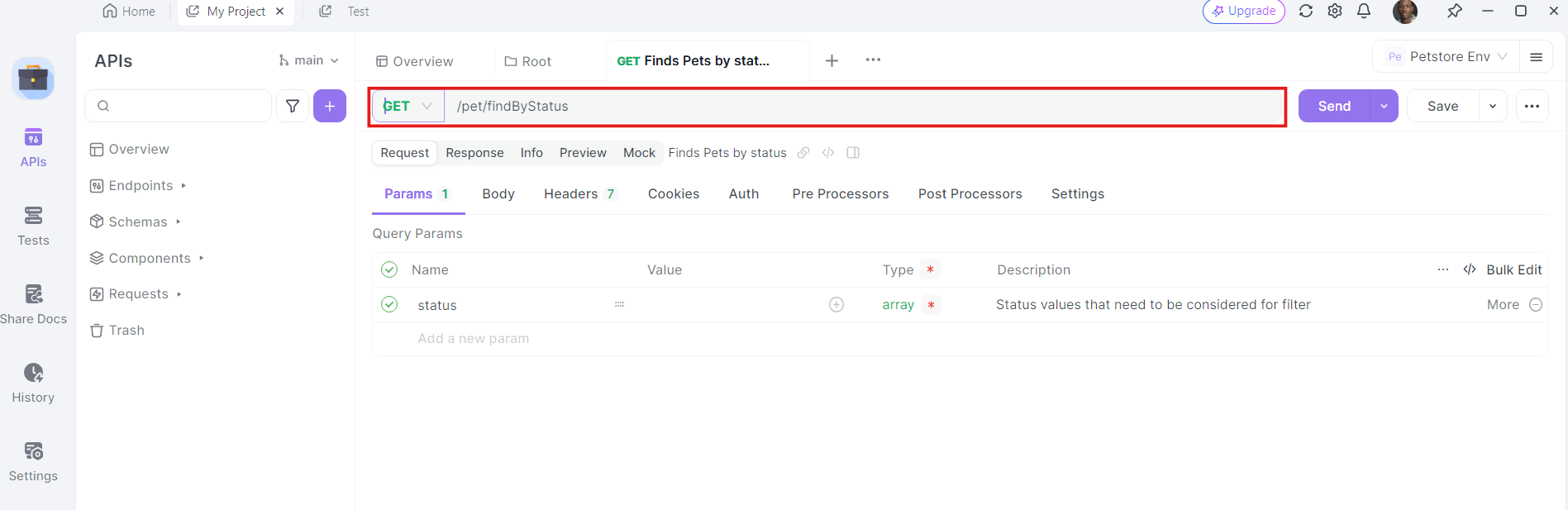
4. Adicione Cabeçalhos: Agora, é hora de adicionar os cabeçalhos necessários. Clique na aba "Cabeçalhos" no Apidog. Aqui, você pode especificar qualquer cabeçalho exigido pela API. Cabeçalhos comuns para solicitações GET podem incluir Authorization, Accept e User-Agent.
Por exemplo:
- Authorization:
Bearer YOUR_ACCESS_TOKEN - Accept:
application/json
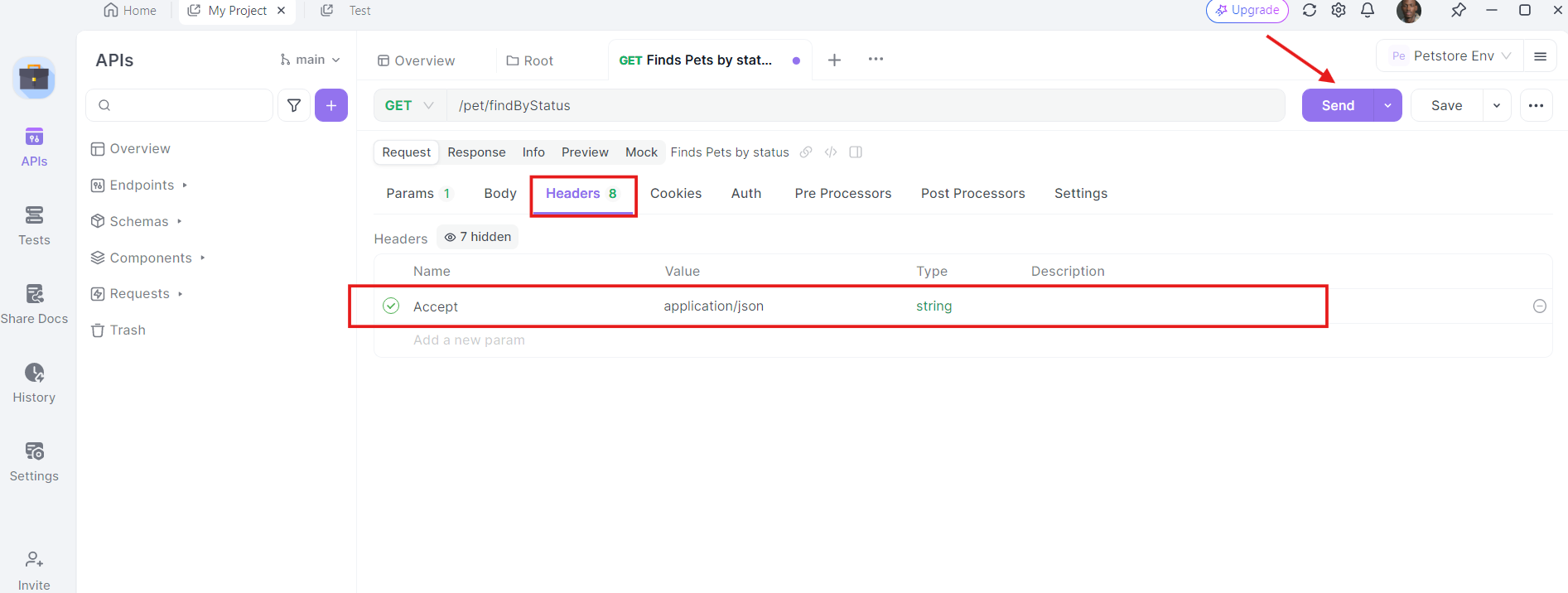
5. Envie a Solicitação e Inspecione a Resposta: Com a URL, parâmetros de consulta e cabeçalhos no lugar, você pode agora enviar a solicitação API. Clique no botão "Enviar" e o Apidog executará a solicitação. Você verá a resposta exibida na seção de resposta.
Uma vez que a solicitação é enviada, o Apidog exibirá a resposta do servidor. Você pode visualizar o código de status, cabeçalhos e corpo da resposta. Isso é valioso para depuração e verificação de que suas chamadas de API estão funcionando como esperado.
Melhores Práticas para Usar a API do Llama 3.1
Ao trabalhar com a API do Llama 3.1, mantenha estas melhores práticas em mente:
- Implemente Streaming: Para respostas mais longas, você pode querer implementar streaming para receber o texto gerado em partes em tempo real. Isso pode melhorar a experiência do usuário para aplicações que requerem feedback imediato.
- Respeite os Limites de Taxa: Esteja ciente e cumpra os limites de taxa estabelecidos pelo seu provedor de API para evitar interrupções no serviço.
- Implemente Cache: Para prompts ou consultas frequentemente usados, implemente um sistema de cache para reduzir chamadas à API e melhorar os tempos de resposta.
- Monitore o Uso: Acompanhe seu uso de API para gerenciar custos e garantir que você esteja dentro de sua cota alocada.
- Segurança: Nunca exponha sua chave de API em código do lado do cliente. Sempre faça chamadas de API de um ambiente de servidor seguro.
- Filtragem de Conteúdo: Implemente filtragem de conteúdo tanto nos prompts de entrada quanto nas saídas geradas para garantir o uso apropriado do modelo.
- Ajuste Fino: Considere ajustar o modelo em dados específicos do domínio se estiver trabalhando em aplicações especializadas.
- Versionamento: Acompanhe a versão específica do modelo Llama 3.1 que você está usando, pois atualizações podem afetar o comportamento e as saídas do modelo.
Casos de Uso no Mundo Real
Vamos olhar alguns casos de uso no mundo real onde a integração do Llama 3.1 com uma API pode ser transformadora:
1. Análise de Sentimentos
Se você está executando um projeto de análise de sentimentos, o Llama 3.1 pode ajudar a classificar textos como positivos, negativos ou neutros. Ao integrá-lo com uma API, você pode automatizar a análise de grandes volumes de dados, como avaliações de clientes ou postagens em redes sociais.
2. Chatbots
Construindo um chatbot? As capacidades de processamento de linguagem natural do Llama 3.1 podem aprimorar a compreensão e as respostas do seu chatbot. Ao usar uma API, você pode integrá-lo perfeitamente ao seu framework de chatbot e proporcionar interações em tempo real.
3. Reconhecimento de Imagens
Para projetos de visão computacional, o Llama 3.1 pode realizar tarefas de reconhecimento de imagens. Ao aproveitar uma API, você pode enviar imagens, obter classificações em tempo real e integrar os resultados em sua aplicação.
Soluções para Problemas Comuns
Às vezes, as coisas não saem como planejadas. Aqui estão alguns problemas comuns que você pode encontrar e como solucioná-los:
1. Erros de Autenticação
Se você está recebendo erros de autenticação, verifique sua chave de API e assegure-se de que esteja configurada corretamente no Apidog.
2. Problemas de Rede
Problemas de rede podem causar falhas nas chamadas de API. Certifique-se de que sua conexão com a internet esteja estável e tente novamente. Se o problema persistir, verifique a página de status do provedor de API para ver se há interrupções.
3. Limitação de Taxa
Os provedores de API geralmente aplicam limites de taxa para evitar abusos. Se você exceder o limite, precisará esperar antes de fazer mais solicitações. Considere implementar lógica de nova tentativa com backoff exponencial para lidar com a limitação de taxa de maneira tranquila.
Engenharia de Prompt com Llama 3.1 405B
Para obter os melhores resultados do Llama 3.1 405B, você precisará experimentar diferentes prompts e parâmetros. Considere fatores como:
- Engenharia de prompt: Elabore prompts claros e específicos para orientar a saída do modelo.
- Temperatura: Ajuste este parâmetro para controlar a aleatoriedade da saída.
- Max tokens: Defina um limite apropriado para o comprimento do texto gerado.
Conclusão
O Llama 3.1 405B representa um avanço significativo no campo dos grandes modelos de linguagem, oferecendo capacidades sem precedentes em um pacote de código aberto. Ao aproveitar o poder deste modelo através de APIs fornecidas por diversos provedores de nuvem, desenvolvedores e empresas podem desbloquear novas possibilidades em aplicações impulsionadas por IA.
O futuro da IA é aberto, e com ferramentas como o Llama 3.1 à nossa disposição, as possibilidades são limitadas apenas pela nossa imaginação e engenhosidade. Ao explorar e experimentar com este poderoso modelo, você não está apenas utilizando uma ferramenta – você está participando da revolução contínua da inteligência artificial, ajudando a moldar o futuro de como interagimos e aproveitamos a inteligência das máquinas.


