
Executar Gemma 3 localmente com Ollama oferece total controle sobre seu ambiente de IA sem depender de serviços em nuvem. Este guia te conduz na configuração do Ollama, no download do Gemma 3 e na execução dele na sua máquina.
Vamos começar.
Por que Rodar o Gemma 3 Localmente com o Ollama?
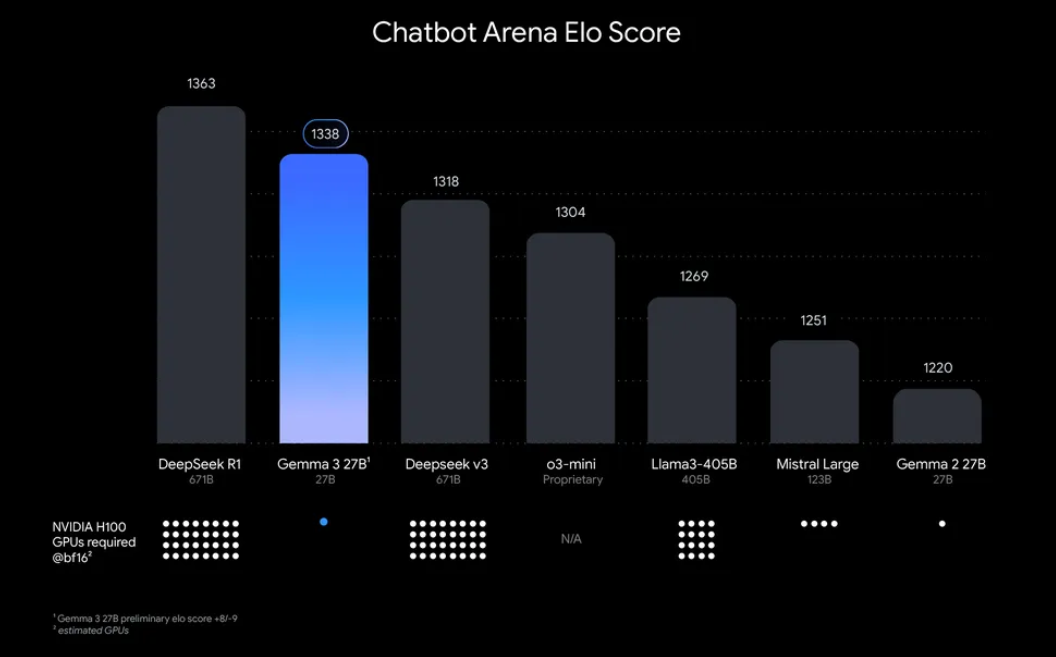
“Por que se preocupar em executar Gemma 3 localmente?” Bem, existem algumas razões convincentes. Para começar, a implantação local te dá controle total sobre seus dados e privacidade, sem a necessidade de enviar informações sensíveis para a nuvem. Além disso, é econômico, pois você evita taxas contínuas de uso de API. Além do mais, a eficiência do Gemma 3 significa que até o modelo 27B pode ser executado em uma única GPU, tornando-o acessível para desenvolvedores com hardware modesto.
Ollama, uma plataforma leve para executar grandes modelos de linguagem (LLMs) localmente, simplifica esse processo. Ele empacota tudo que você precisa — pesos do modelo, configurações e dependências — em um formato fácil de usar. Essa combinação de Gemma 3 e Ollama é perfeita para experimentar, criar aplicativos ou testar fluxos de trabalho de IA na sua máquina. Então, vamos arregaçar as mangas e começar!
O que Você Precisará para Executar o Gemma 3 com o Ollama
Antes de entrarmos na configuração, certifique-se de que você possui os seguintes pré-requisitos:
- Uma Máquina Compatível: Você precisará de um computador com GPU (preferencialmente NVIDIA para desempenho ideal) ou um CPU poderoso. O modelo 27B requer recursos significativos, mas versões menores, como 1B ou 4B, podem ser executadas em hardware menos potente.
- Ollama Instalado: Baixe e instale o Ollama, disponível para MacOS, Windows e Linux. Você pode obter no ollama.com.
- Habilidades Básicas de Linha de Comando: Você interagirá com o Ollama através do terminal ou prompt de comando.
- Conexão com a Internet: Inicialmente, você precisará baixar os modelos do Gemma 3, mas uma vez baixados, você pode executá-los offline.
- Opcional: Apidog para Testes de API: Se você planeja integrar o Gemma 3 com uma API ou testar suas respostas programaticamente, a interface intuitiva do Apidog pode economizar tempo e esforço.
Agora que você está equipado, vamos mergulhar no processo de instalação e configuração.
Guia Passo a Passo: Instalando o Ollama e Baixando o Gemma 3
1. Instale o Ollama na Sua Máquina
Ollama torna a implantação local de LLM uma tarefa fácil, e a instalação é direta. Veja como:
- Para MacOS/Windows: Visite ollama.com e baixe o instalador para seu sistema operacional. Siga as instruções na tela para completar a instalação.
- Para Linux (exemplo, Ubuntu): Abra seu terminal e execute o seguinte comando:
curl -fsSL https://ollama.com/install.sh | sh
Este script detecta automaticamente seu hardware (incluindo GPUs) e instala o Ollama.
Uma vez instalado, verifique a instalação executando:
ollama --version

Você deve ver o número da versão atual, confirmando que o Ollama está pronto para uso.
2. Baixe os Modelos do Gemma 3 Usando o Ollama
A biblioteca de modelos do Ollama inclui o Gemma 3, graças à sua integração com plataformas como Hugging Face e as ofertas de IA do Google. Para baixar o Gemma 3, use o comando ollama pull.
ollama pull gemma3

Para modelos menores, você pode usar:
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
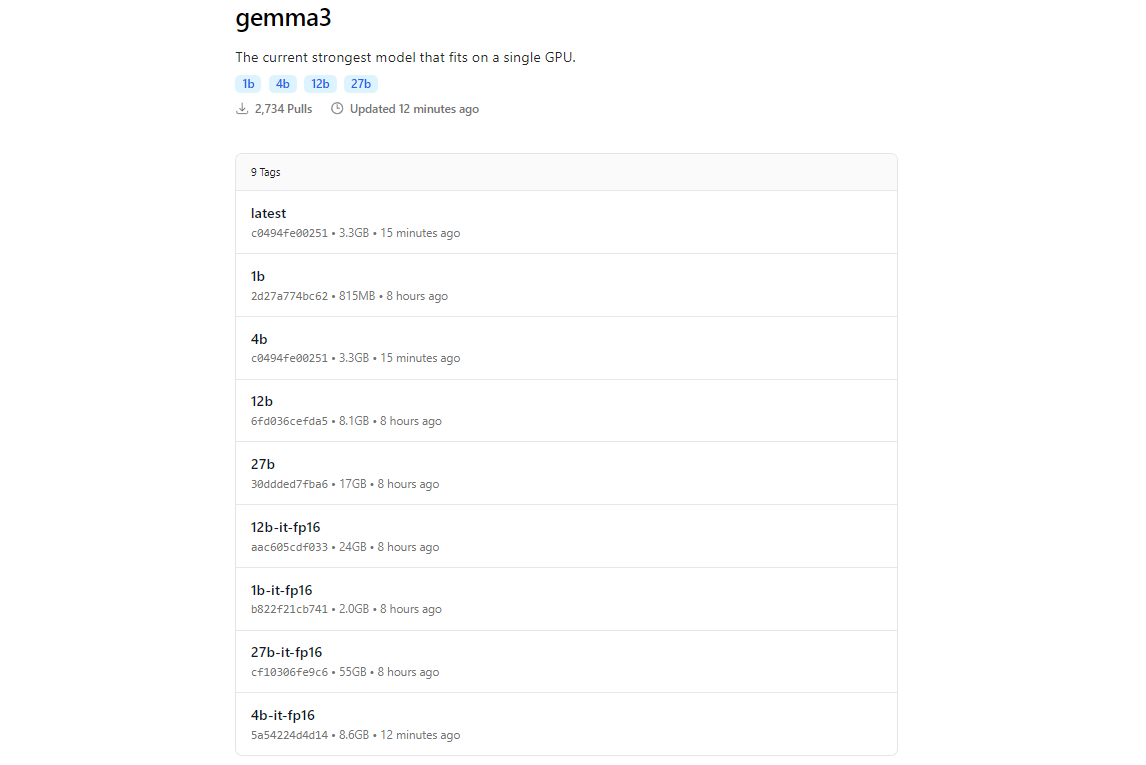
O tamanho do download varia de acordo com o modelo; espere que o modelo 27B seja de vários gigabytes, então certifique-se de ter espaço de armazenamento suficiente. Os modelos do Gemma 3 são otimizados para eficiência, mas ainda assim requerem hardware decente para as variantes maiores.
3. Verifique a Instalação
Uma vez baixado, verifique se o modelo está disponível listando todos os modelos:
ollama list

Você deve ver gemma3 (ou o tamanho que você escolheu) na lista. Se ele estiver lá, você está pronto para executar o Gemma 3 localmente!
Executando o Gemma 3 com o Ollama: Modo Interativo e Integração de API
Modo Interativo: Conversando com o Gemma 3
O modo interativo do Ollama permite que você converse com o Gemma 3 diretamente do terminal. Para começar, execute:
ollama run gemma3
Você verá um prompt onde pode digitar consultas. Por exemplo, tente:
Quais são as principais características do Gemma 3?
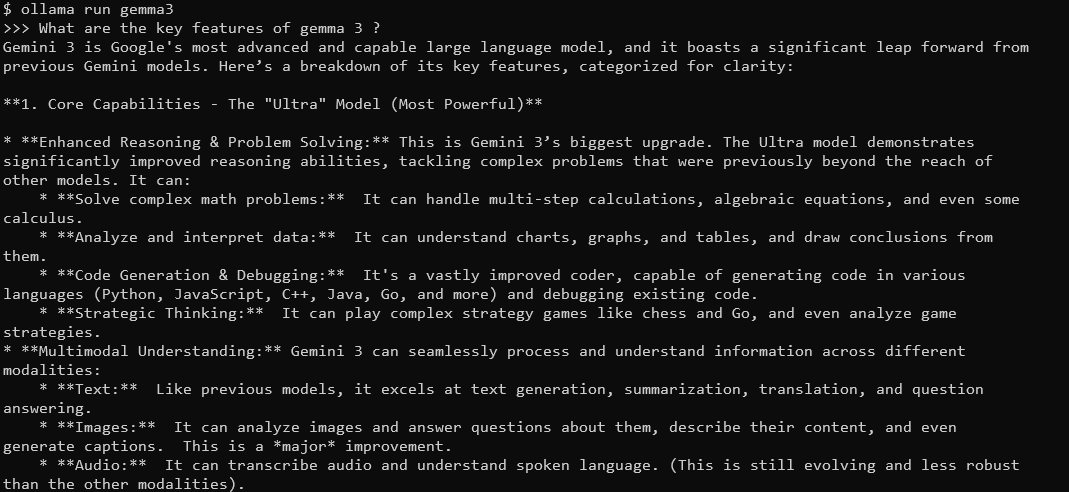
O Gemma 3, com sua janela de contexto de 128K e capacidades multimodais, responderá com respostas detalhadas e contextualizadas. Ele suporta mais de 140 idiomas e pode processar texto, imagens e até entradas de vídeo (para determinados tamanhos).
Para sair, digite Ctrl+D ou /bye.
Integrando o Gemma 3 com a API do Ollama
Se você deseja criar aplicativos ou automatizar interações, o Ollama fornece uma API que você pode usar. É aqui que o Apidog brilha; sua interface amigável ajuda você a testar e gerenciar solicitações de API de forma eficiente. Veja como começar:
Abrindo o Servidor do Ollama: Execute o seguinte comando para iniciar o servidor da API do Ollama:
ollama serve
Isso inicia o servidor em localhost:11434 por padrão.
Faça Solicitações de API: Você pode interagir com o Gemma 3 através de solicitações HTTP. Por exemplo, use curl para enviar um prompt:
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "Qual é a capital da França?"}'
A resposta incluirá a saída do Gemma 3, formatada como JSON.
Use Apidog para Testes: Baixe o Apidog gratuitamente e crie uma solicitação de API para testar as respostas do Gemma 3. A interface visual do Apidog permite que você insira o endpoint (http://localhost:11434/api/generate), defina o payload JSON e analise as respostas sem escrever código complexo. Isso é especialmente útil para depuração e otimização da sua integração.
Guia Passo a Passo para Usar o Teste SSE no Apidog
Vamos percorrer o processo de utilização do recurso de teste SSE otimizado no Apidog, completo com as novas melhorias de Auto-Merge. Siga estes passos para configurar e maximizar sua experiência de depuração em tempo real.
Passo 1: Crie uma Nova Solicitação de API
Comece lançando um novo projeto HTTP no Apidog. Adicione um novo endpoint e insira a URL para o endpoint da sua API ou modelo de IA. Este é o seu ponto de partida para testar e depurar seus fluxos de dados em tempo real.
Passo 2: Envie a Solicitação
Uma vez que seu endpoint esteja configurado, envie a solicitação de API. Observe cuidadosamente os cabeçalhos da resposta. Se o cabeçalho incluir Content-Type: text/event-stream, o Apidog reconhecerá e interpretará automaticamente a resposta como um fluxo SSE. Essa detecção é crucial para o processo subsequente de auto-montagem.

Passo 3: Monitore a Linha do Tempo em Tempo Real
Após a conexão SSE ser estabelecida, o Apidog abrirá uma visão de linha do tempo dedicada onde todos os eventos SSE recebidos são exibidos em tempo real. Esta linha do tempo atualiza continuamente conforme novos dados chegam, permitindo que você monitore o fluxo de dados com precisão. A linha do tempo não é apenas um despejo bruto de dados; é uma visualização cuidadosamente estruturada que ajuda você a ver exatamente quando e como os dados são transmitidos.
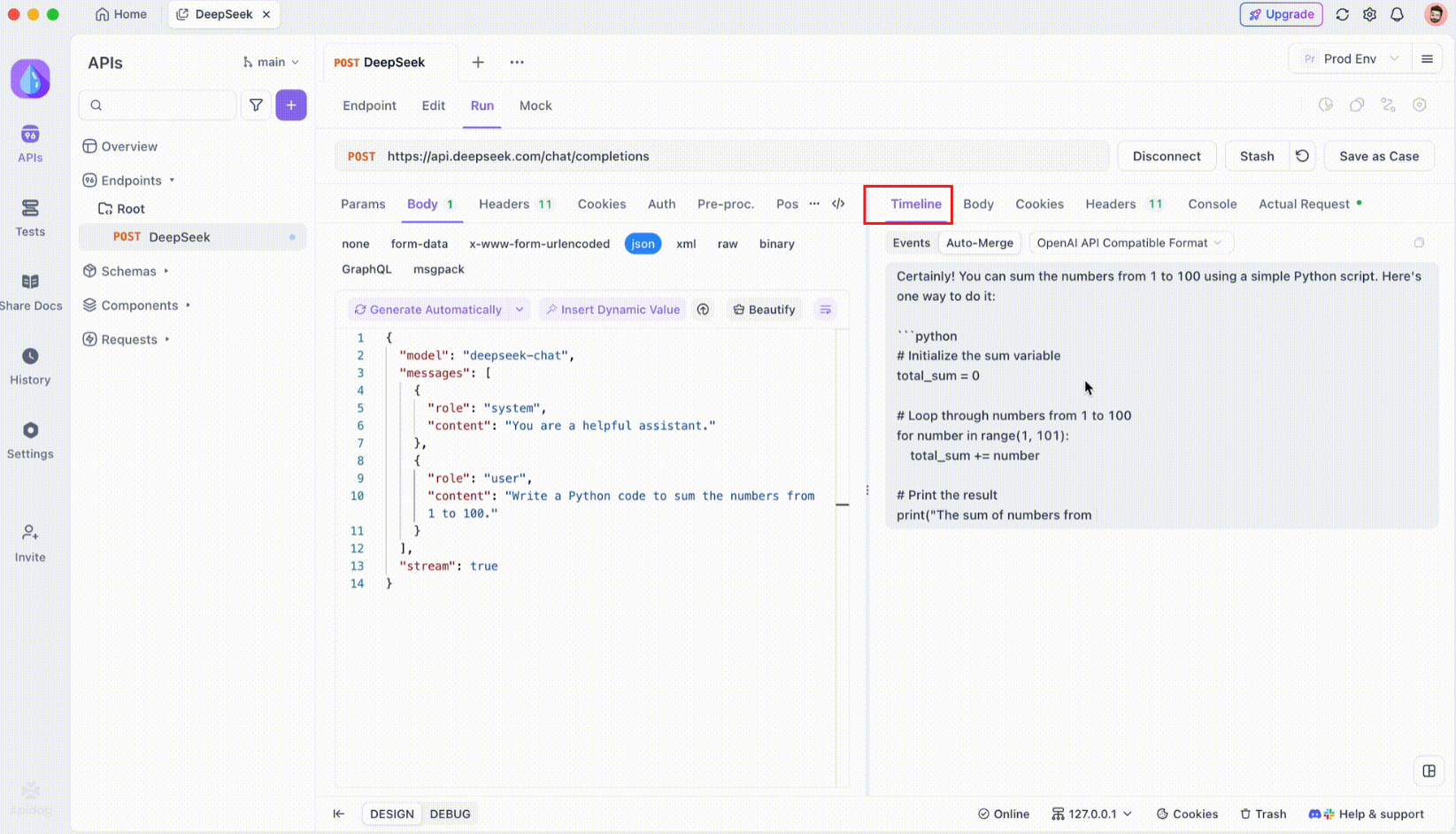
Passo 4: Mesclagem Automática de Mensagem
Aqui é onde a mágica acontece. Com as melhorias de Auto-Merge, o Apidog reconhece automaticamente formatos populares de modelos de IA e mescla respostas SSE fragmentadas em uma resposta completa. Esta etapa inclui:
- Reconhecimento Automático: O Apidog verifica se a resposta está em um formato suportado (OpenAI, Gemini ou Claude).
- Mesclagem de Mensagens: Se o formato for reconhecido, a plataforma combina automaticamente todos os fragmentos SSE, entregando uma resposta completa e contínua.
- Visualização Aprimorada: Para certos modelos de IA, como DeepSeek R1, a linha do tempo também exibe o processo de pensamento do modelo, oferecendo uma camada extra de insight sobre o raciocínio por trás da resposta gerada.
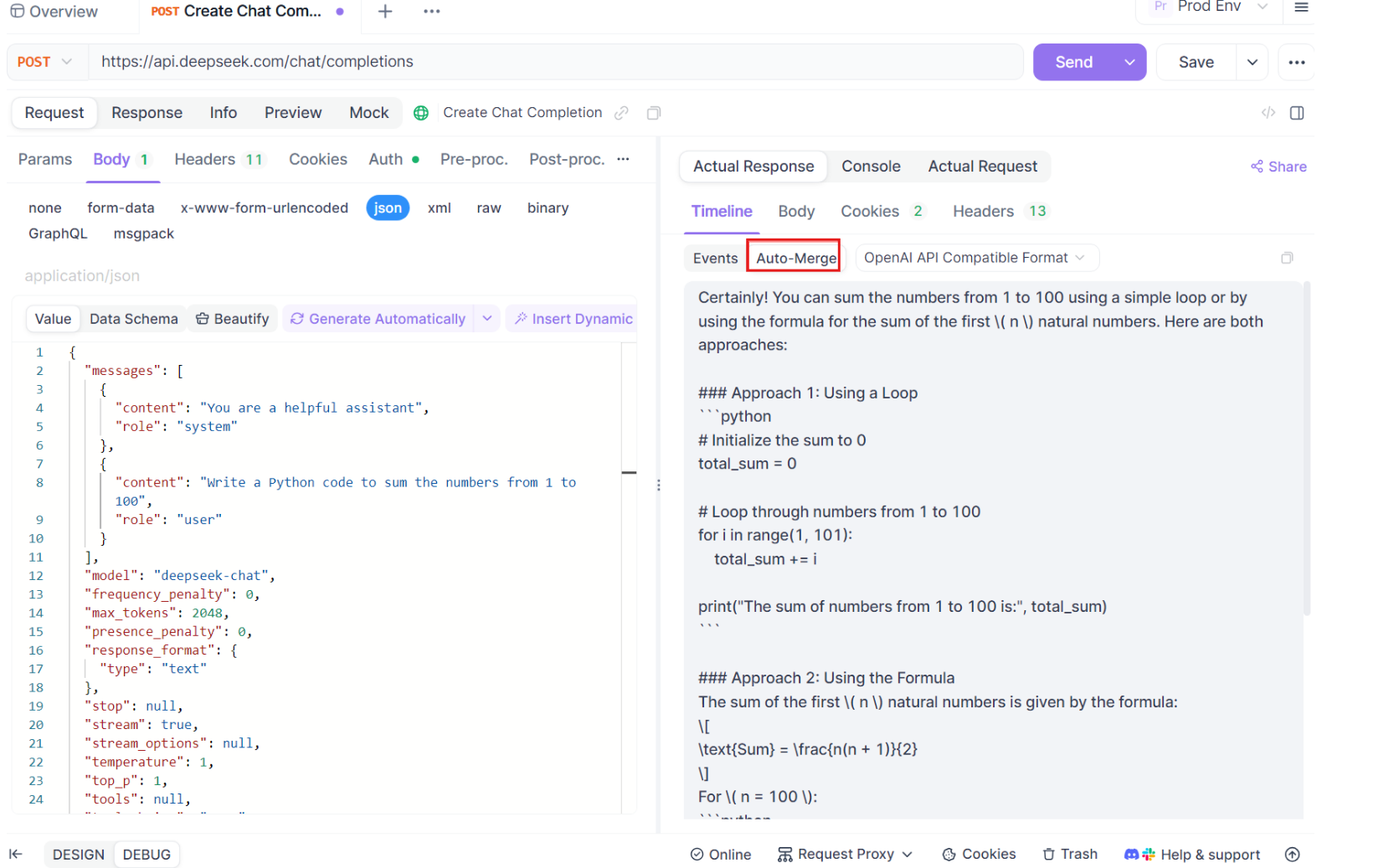
Este recurso é particularmente útil ao lidar com aplicações movidas por IA, garantindo que cada parte da resposta seja capturada e apresentada em sua totalidade, sem intervenção manual.
Passo 5: Configure as Regras de Extração JSONPath
Nem todas as respostas SSE se conformarão automaticamente aos formatos integrados. Ao lidar com respostas JSON que requerem extração personalizada, o Apidog permite que você configure regras JSONPath. Por exemplo, se sua resposta SSE bruta contiver um objeto JSON e você precisar extrair o campo content, você pode configurar uma configuração JSONPath da seguinte forma:
- JSONPath:
$.choices[0].message.content - Explicação:
$refere-se à raiz do objeto JSON.choices[0]seleciona o primeiro elemento do arraychoices.message.contentespecifica o campo de conteúdo dentro do objeto da mensagem.
Esta configuração instrui o Apidog sobre como extrair os dados desejados da sua resposta SSE, garantindo que até mesmo as respostas não padronizadas sejam tratadas de forma eficaz.
Conclusão
Executar o Gemma 3 localmente com o Ollama é uma maneira empolgante de aproveitar as avançadas capacidades de IA do Google sem sair da sua máquina. Desde a instalação do Ollama e o download do modelo até a interação através do terminal ou API, este guia percorreu cada etapa. Com suas características multimodais, suporte multilíngue e desempenho impressionante, o Gemma 3 é um divisor de águas para desenvolvedores e entusiastas de IA. Não se esqueça de usar ferramentas como o Apidog para testes e integração de API sem esforço — baixe gratuitamente hoje para aprimorar seus projetos com o Gemma 3!
Seja você experimentando com o modelo 1B em um laptop ou explorando os limites do modelo 27B em um equipamento GPU, você agora está pronto para explorar as possibilidades. Boas codificações, e vamos ver que coisas incríveis você cria com o Gemma 3!