
Os modelos Cogito, lançados pela DeepCogito, rapidamente ganharam atenção na comunidade de IA devido à sua notável capacidade de superar modelos estabelecidos como LLaMA e DeepSeek em várias escalas. Esses modelos de código aberto, que variam de 3B a 70B parâmetros, fornecem aos desenvolvedores uma ferramenta poderosa para explorar a superinteligência geral diretamente em suas máquinas locais.
O que você precisa saber sobre Cogito e Ollama
Cogito representa uma série de modelos de IA de código aberto desenvolvidos pela equipe da DeepCogito, com um foco claro em alcançar a superinteligência geral. Esses modelos utilizam uma técnica chamada destilação e amplificação iterativas (IDA), que aprimora iterativamente as capacidades de raciocínio do modelo, utilizando mais computação para chegar a melhores soluções e, em seguida, destilando esse processo nos parâmetros do modelo. Disponíveis em tamanhos como 3B, 8B, 14B, 32B e 70B, os modelos Cogito estão prontos para se expandir ainda mais com lançamentos de modelos de 109B e 400B parâmetros.

Por outro lado, Ollama é uma estrutura versátil que permite aos desenvolvedores executar LLMs localmente em suas máquinas, eliminando a necessidade de APIs baseadas em nuvem. Suportando várias plataformas como MacOS, Windows e Linux, o Ollama garante acessibilidade para uma ampla gama de usuários. Ao executar o Cogito localmente com o Ollama, você pode experimentar modelos avançados de IA no dispositivo, o que não só reduz custos, mas também aumenta a privacidade dos dados para aplicações sensíveis.

Por que executar o Cogito localmente?
Executar o Cogito localmente oferece várias vantagens para os desenvolvedores. Primeiro, elimina a dependência de APIs externas, o que reduz a latência e garante que seus dados permaneçam privados. Isso é particularmente importante para aplicações em que a segurança dos dados é uma prioridade. Além disso, os modelos Cogito demonstraram desempenho superior em comparação com concorrentes como o LLaMA 4 Scout, mesmo em escalas menores, tornando-os uma excelente escolha para tarefas de alto desempenho.

A execução local também é ideal para desenvolvedores que trabalham em ambientes com recursos limitados ou em áreas com acesso à internet restrito, pois permite operação contínua sem conectividade. Além disso, a interface simples de linha de comando do Ollama facilita o processo de gerenciamento e execução de vários modelos, incluindo o Cogito. Finalmente, uma configuração local permite iterações mais rápidas durante o desenvolvimento, especialmente ao testar integrações de API, que podem ser gerenciadas de forma eficiente usando ferramentas como o Apidog para projetar e depurar seus endpoints.
Pré-requisitos para executar o Cogito com Ollama
Antes de mergulhar no processo de configuração, certifique-se de que seu sistema atende aos requisitos necessários. Para modelos menores, como as versões de 3B ou 8B parâmetros, sua máquina deve ter pelo menos 16GB de RAM, enquanto modelos maiores como o de 70B podem exigir 64GB ou mais para funcionar sem problemas. Uma GPU compatível, como uma placa NVIDIA com suporte a CUDA, é altamente recomendada, pois acelera significativamente a inferência do modelo.
Você também precisará instalar o Python 3.8 ou superior, pois é uma dependência para a biblioteca Python do Ollama e outras ferramentas relacionadas.
Em seguida, baixe e instale o Ollama do seu site oficial ou do repositório do GitHub, seguindo as instruções específicas para o seu sistema operacional. O armazenamento é outro fator crítico—os modelos Cogito podem variar de alguns gigabytes para o modelo de 3B a mais de 100GB para o modelo de 70B, então, certifique-se de que seu sistema tenha espaço suficiente. Por fim, se você planeja integrar o Cogito com APIs, ter o Apidog instalado o ajudará a projetar e testar seus endpoints de API de forma eficiente, garantindo uma experiência de desenvolvimento tranquila.
Passo 1: Instale o Ollama em sua máquina
O primeiro passo para executar o Cogito localmente é instalar o Ollama em sua máquina. Comece visitando o site ou a página do GitHub do Ollama para baixar o instalador para o seu sistema operacional. Para usuários de MacOS e Windows, basta executar o instalador e seguir as instruções na tela para concluir a configuração. Se você estiver usando Linux, pode instalar o Ollama diretamente executando o comando:
curl -fsSL https://ollama.com/install.sh | sh no seu terminal.
Após a conclusão da instalação, abra um terminal e digite ollama --version para confirmar que o Ollama foi instalado corretamente.

Para garantir que o Ollama esteja em execução, execute ollama serve, que inicia o servidor local para gerenciamento de modelos. Essa etapa também configura a interface de linha de comando do Ollama, que você usará para puxar e executar modelos como o Cogito nos passos seguintes.
Passo 2: Puxe o modelo Cogito da biblioteca do Ollama
Com o Ollama instalado, o próximo passo é baixar o modelo Cogito. Abra seu terminal e execute o comando ollama pull cogito para buscar o modelo Cogito da biblioteca do Ollama.

Por padrão, esse comando puxa a versão mais recente do modelo Cogito, mas você pode especificar um tamanho específico usando uma tag, como ollama pull cogito:3b para o modelo de 3B parâmetros. Você pode explorar os tamanhos de modelos disponíveis em https://ollama.com/library/cogito.
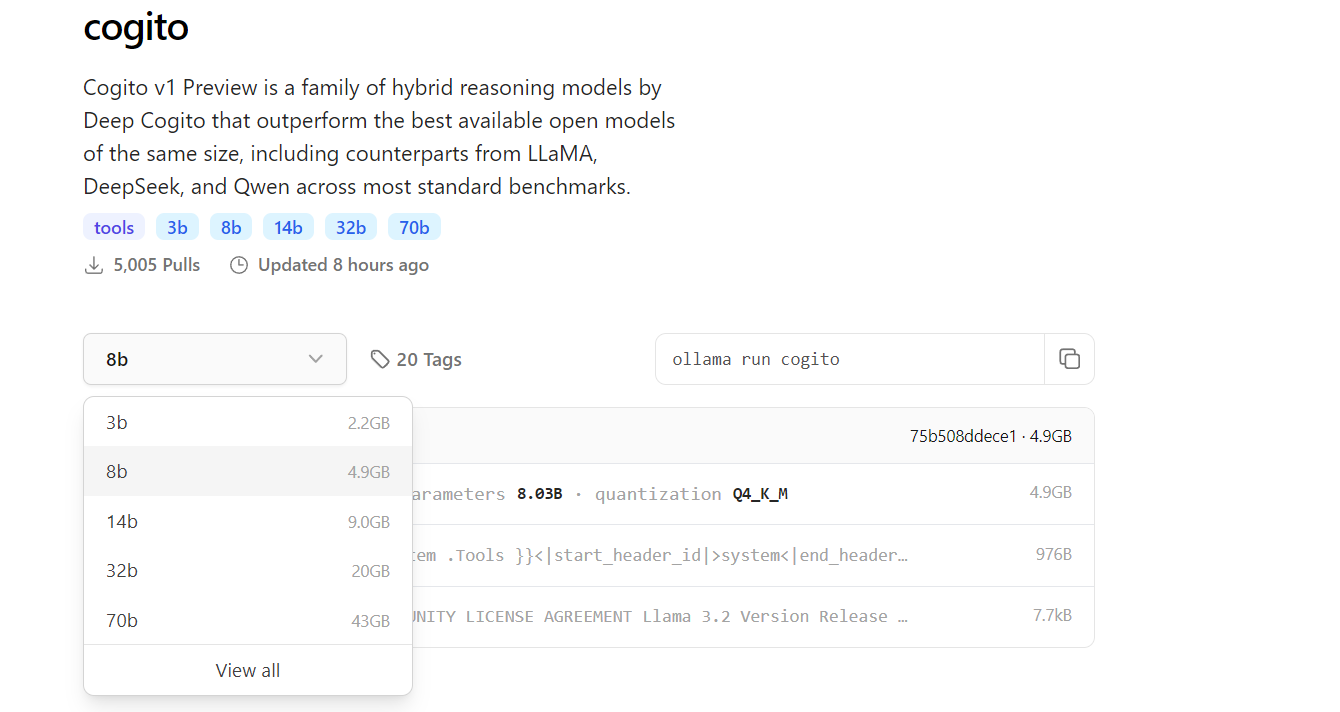
Dependendo da sua velocidade de internet e do tamanho do modelo, o processo de download pode levar algum tempo—espere cerca de 2.2GB para o modelo de 3B e até 43GB para o modelo de 70B. Depois que o download for concluído, verifique se o modelo está disponível em seu sistema executando ollama list, que exibirá todos os modelos instalados. Neste ponto, o Cogito está pronto para ser executado localmente, e você pode passar para o próximo passo.

Passo 3: Execute o Cogito localmente com o Ollama
Agora que o modelo foi baixado, você pode começar a executar o Cogito em sua máquina. No seu terminal, execute o comando ollama run cogito para iniciar o modelo Cogito.

Passo 4: Melhore os testes de API com o Apidog
O Cogito se destaca na geração de código de API, mas testar essas APIs é crucial. O Apidog simplifica esse processo:
Instale o Apidog:
Baixe e instale o Apidog de seu site oficial.
Teste a API gerada:
Pegue o endpoint Flask de antes. No Apidog:
- Crie uma nova requisição.
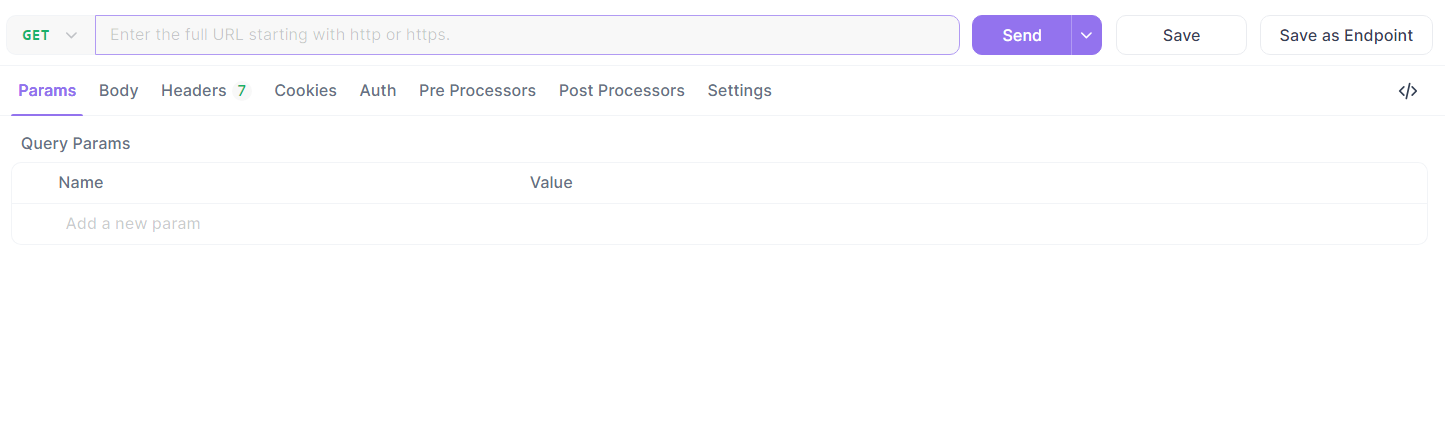
- Defina a URL como
http://localhost:5000/api/datae envie uma requisição GET.
- Verifique a resposta:
{"message": "Olá, Mundo!"}.
Automatize os testes:
Use a automação do Apidog para validar, garantindo que a saída do DeepCoder atenda às expectativas.
O Apidog preenche a lacuna entre a geração de código e a implantação, aumentando a produtividade.
Resolvendo Problemas Comuns
Executar o Cogito localmente pode apresentar desafios ocasionalmente, mas a maioria dos problemas pode ser resolvida com algumas verificações. Se o Ollama não iniciar, verifique se nenhum outro processo está utilizando a porta 11434—você pode finalizar o processo conflitante ou mudar a porta na configuração do Ollama. Para erros de “sem memória”, considere reduzir o tamanho do modelo ou aumentar o espaço de swap do seu sistema para acomodar modelos maiores. Se o modelo não responder, certifique-se de que você o puxou corretamente usando ollama pull cogito e que ele aparece na saída do ollama list. Tempos de inferência lentos geralmente indicam que você está executando apenas com CPU—verifique o suporte a GPU executando nvidia-smi para confirmar que o CUDA está ativo.
Ao usar o Apidog para integração de API, erros podem surgir de cargas JSON incorretas, então verifique duas vezes seu esquema no editor do Apidog. Para diagnósticos mais detalhados, revise os logs do Ollama em ~/.ollama/logs para identificar e resolver problemas rapidamente.
Conclusão
Executar o Cogito localmente com o Ollama abre um mundo de possibilidades para desenvolvedores que desejam explorar a superinteligência geral. Seguindo os passos descritos neste guia, você pode configurar o Cogito em sua máquina, otimizar seu desempenho e até mesmo integrá-lo em aplicações maiores usando APIs gerenciadas com o Apidog. Se você estiver construindo um sistema RAG, um assistente de codificação ou uma aplicação web, as capacidades avançadas do Cogito fazem dele uma ferramenta poderosa para inovação. À medida que a equipe da DeepCogito continua a lançar modelos maiores e refinar suas técnicas, o potencial para o desenvolvimento de IA local só crescerá, capacitando os desenvolvedores a criar soluções inovadoras.