
Se você já desejou poder fazer perguntas diretamente a um PDF ou manual técnico, este guia é para você. Hoje, vamos construir um sistema de Geração Aumentada por Recuperação (RAG) utilizando o DeepSeek R1, uma poderosa ferramenta de raciocínio de código aberto, e Ollama, a estrutura leve para execução de modelos de IA locais.
Pronto para potencializar seus testes de API? Não se esqueça de conferir Apidog! O Apidog funciona como uma plataforma única para criar, gerenciar e executar testes e servidores simulados, permitindo que você identifique gargalos e mantenha suas APIs confiáveis.
Em vez de equilibrar várias ferramentas ou escrever scripts extensos, você pode automatizar partes críticas do seu fluxo de trabalho, alcançar pipelines CI/CD suaves e passar mais tempo aperfeiçoando os recursos do seu produto.
Se isso soa como algo que poderia simplificar sua vida, experimente o Apidog!
Neste post, vamos explorar como o DeepSeek R1—um modelo que rivaliza o o1 da OpenAI em desempenho, mas custa 95% menos—pode potencializar seus sistemas RAG. Vamos detalhar por que os desenvolvedores estão se voltando para essa tecnologia e como você pode construir seu próprio pipeline RAG com ela.
Quanto Custa Este Sistema RAG Local?
| Componente | Custo |
|---|---|
| DeepSeek R1 1.5B | Gratuito |
| Ollama | Gratuito |
| PC com 16GB de RAM | $0 |
O modelo de 1.5B do DeepSeek R1 brilha aqui porque:
- Recuperação focada: Apenas 3 fragmentos de documento alimentam cada resposta
- Promoções rigorosas: "Eu não sei" evita alucinações
- Execução local: Zero latência em comparação com APIs em nuvem
O Que Você Vai Precisar
Antes de começarmos a codificar, vamos preparar nossas ferramentas:
1. Ollama
Ollama permite que você execute modelos como o DeepSeek R1 localmente.
- Baixe: https://ollama.com/
- Instale, então abra seu terminal e execute:
ollama run deepseek-r1 # Para o modelo de 7B (padrão)
2. Variantes do Modelo DeepSeek R1
O DeepSeek R1 vem em tamanhos que variam de 1.5B a 671B de parâmetros. Para esta demonstração, usaremos o modelo de 1.5B—perfeito para RAG leve:
ollama run deepseek-r1:1.5b
Dica profissional: Modelos maiores, como 70B, oferecem melhor raciocínio, mas exigem mais RAM. Comece pequeno e depois aumente!

Construindo o Pipeline RAG: Tutorial de Código
Etapa 1: Importar Bibliotecas
Usaremos:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
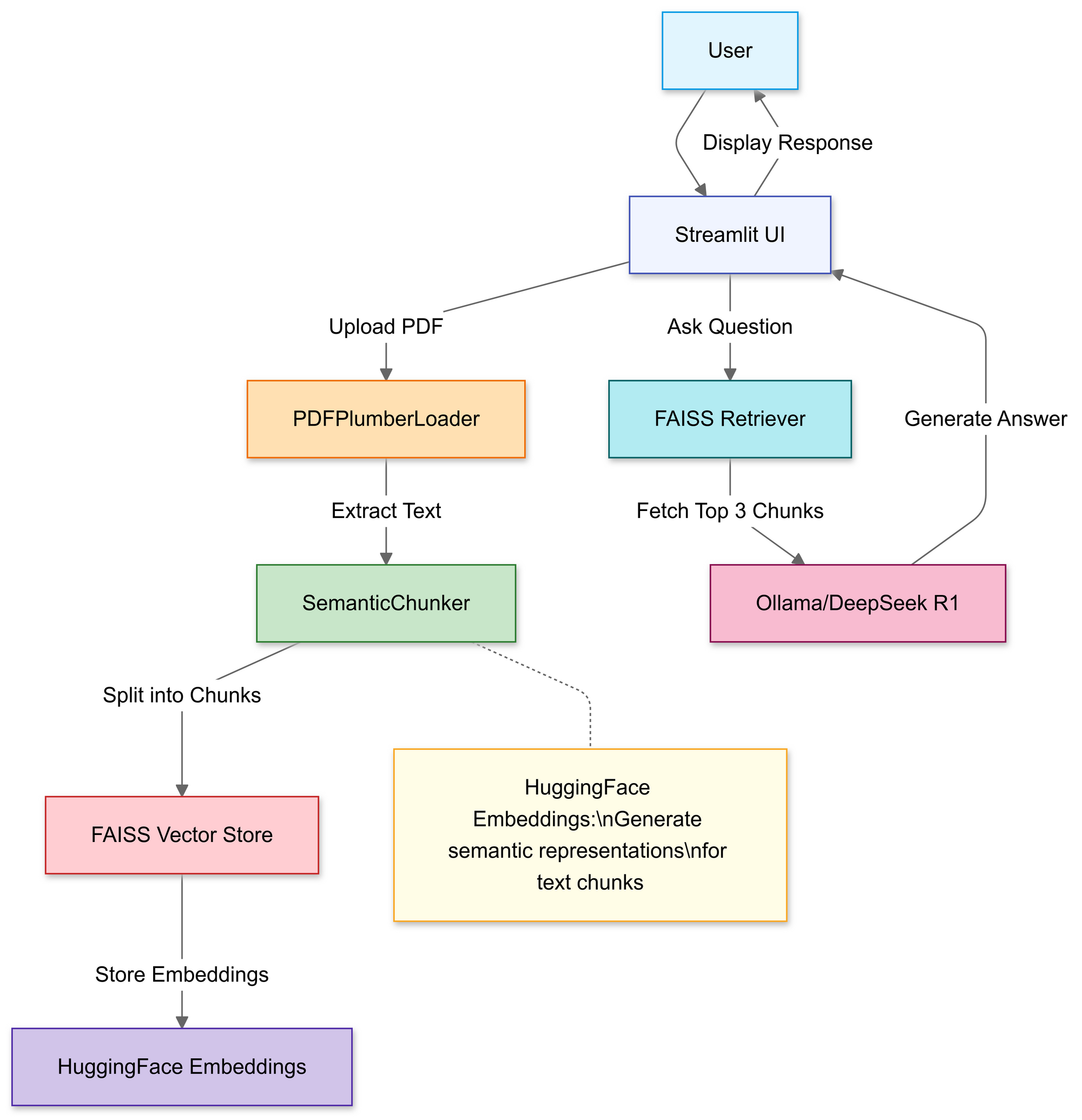
Etapa 2: Carregar e Processar PDFs
Nesta seção, você usa o carregador de arquivos do Streamlit para permitir que usuários selecionem um arquivo PDF local.
# Carregador de arquivos do Streamlit
uploaded_file = st.file_uploader("Carregue um arquivo PDF", type="pdf")
if uploaded_file:
# Salvar PDF temporariamente
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Carregar texto do PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
Uma vez carregado, a função PDFPlumberLoader extrai texto do PDF, preparando-o para a próxima etapa do pipeline. Essa abordagem é conveniente porque cuida da leitura do conteúdo do arquivo sem exigir uma análise manual extensa.
Etapa 3: Fracionar Documentos Estrategicamente
Queremos usar o RecursiveCharacterTextSplitter, o código divide o texto original do PDF em segmentos menores (chunks). Vamos explicar os conceitos de boa e má fracionamento aqui:
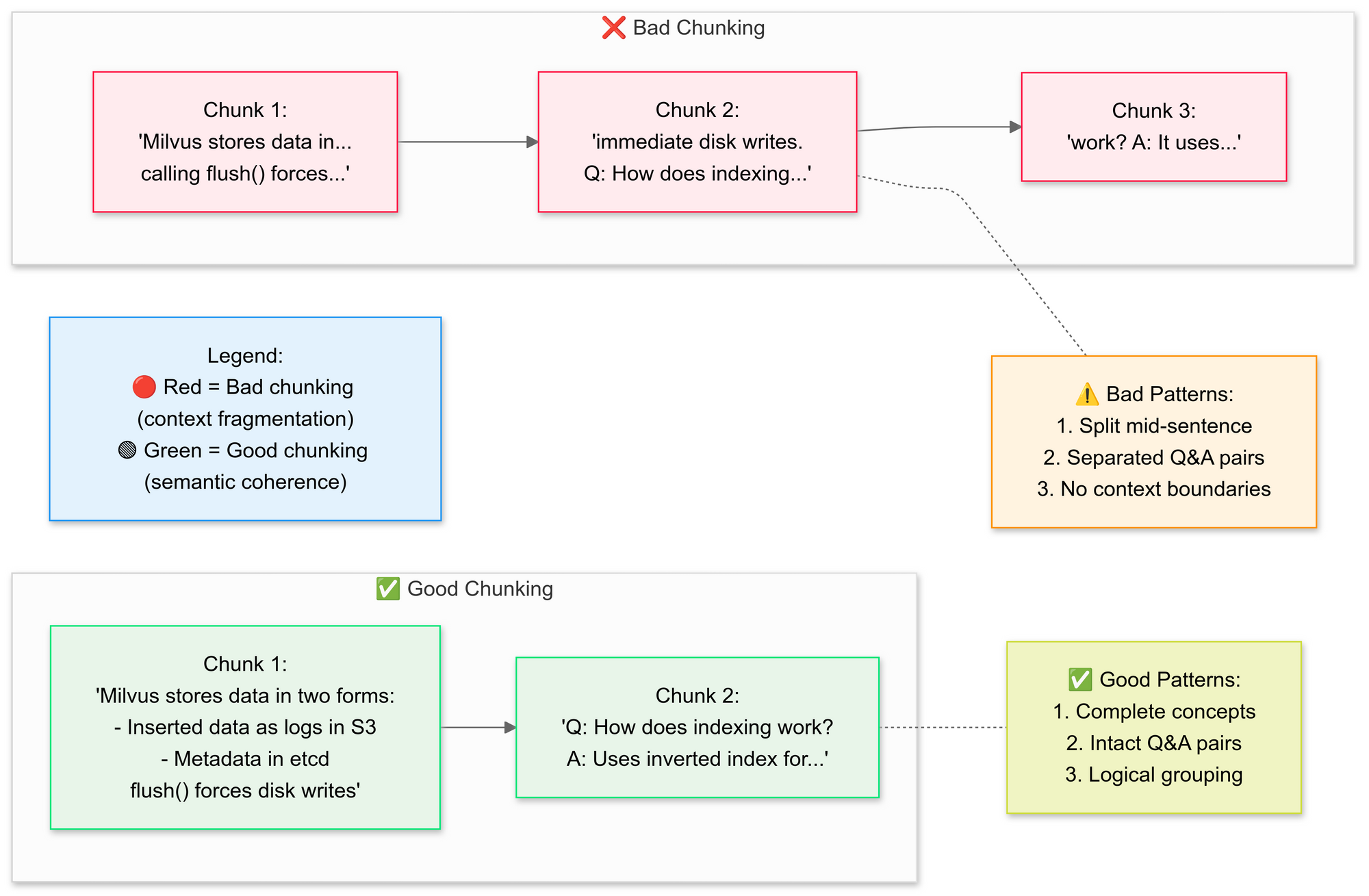
Por que fracionamento semântico?
- Agrupa frases relacionadas (por exemplo, "Como o Milvus armazena dados" permanece intacto)
- Evita dividir tabelas ou diagramas
# Dividir texto em segmentos semânticos
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
Essa etapa preserva o contexto ao sobrepor ligeiramente os segmentos, o que ajuda o modelo de linguagem a responder perguntas de forma mais precisa. Fragmentos de documento pequenos e bem definidos também tornam as buscas mais eficientes e relevantes.
Etapa 4: Criar uma Base de Conhecimento Pesquisável
Após a divisão, o pipeline gera embeddings vetoriais para os segmentos e os armazena em um índice FAISS.
# Gerar embeddings
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Conectar recuperador
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Buscar os 3 melhores chunks
Isso transforma o texto em uma representação numérica que é muito mais fácil de consultar. As consultas são executadas posteriormente contra esse índice para encontrar os segmentos mais contextualmente relevantes.
Etapa 5: Configurar DeepSeek R1
Aqui, você instancia uma cadeia RetrievalQA usando o Deepseek R1 1.5B como o LLM local.
llm = Ollama(model="deepseek-r1:1.5b") # Nosso modelo de 1.5B parâmetros
# Elaborar o template do prompt
prompt = """
1. Use SOMENTE o contexto abaixo.
2. Se estiver em dúvida, diga "Eu não sei".
3. Mantenha as respostas abaixo de 4 frases.
Contexto: {context}
Pergunta: {question}
Resposta:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
Esse template força o modelo a fundamentar as respostas no conteúdo do seu PDF. Ao envolver o modelo de linguagem com um recuperador vinculado ao índice FAISS, qualquer consulta feita através da cadeia buscará contexto no conteúdo do PDF, tornando as respostas ancoradas no material de origem.
Etapa 6: Montar a Cadeia RAG
Em seguida, você pode integrar as etapas de upload, fracionamento e recuperação em um pipeline coerente.
# Cadeia 1: Gerar respostas
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Cadeia 2: Combinar fragmentos de documento
document_prompt = PromptTemplate(
template="Contexto:\nconteúdo:{page_content}\nfonte:{source}",
input_variables=["page_content", "source"]
)
# Pipeline final RAG
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
Este é o núcleo do design RAG (Geração Aumentada por Recuperação), fornecendo ao grande modelo de linguagem um contexto verificado em vez de depender puramente de seu treinamento interno.
Etapa 7: Liberar a Interface Web
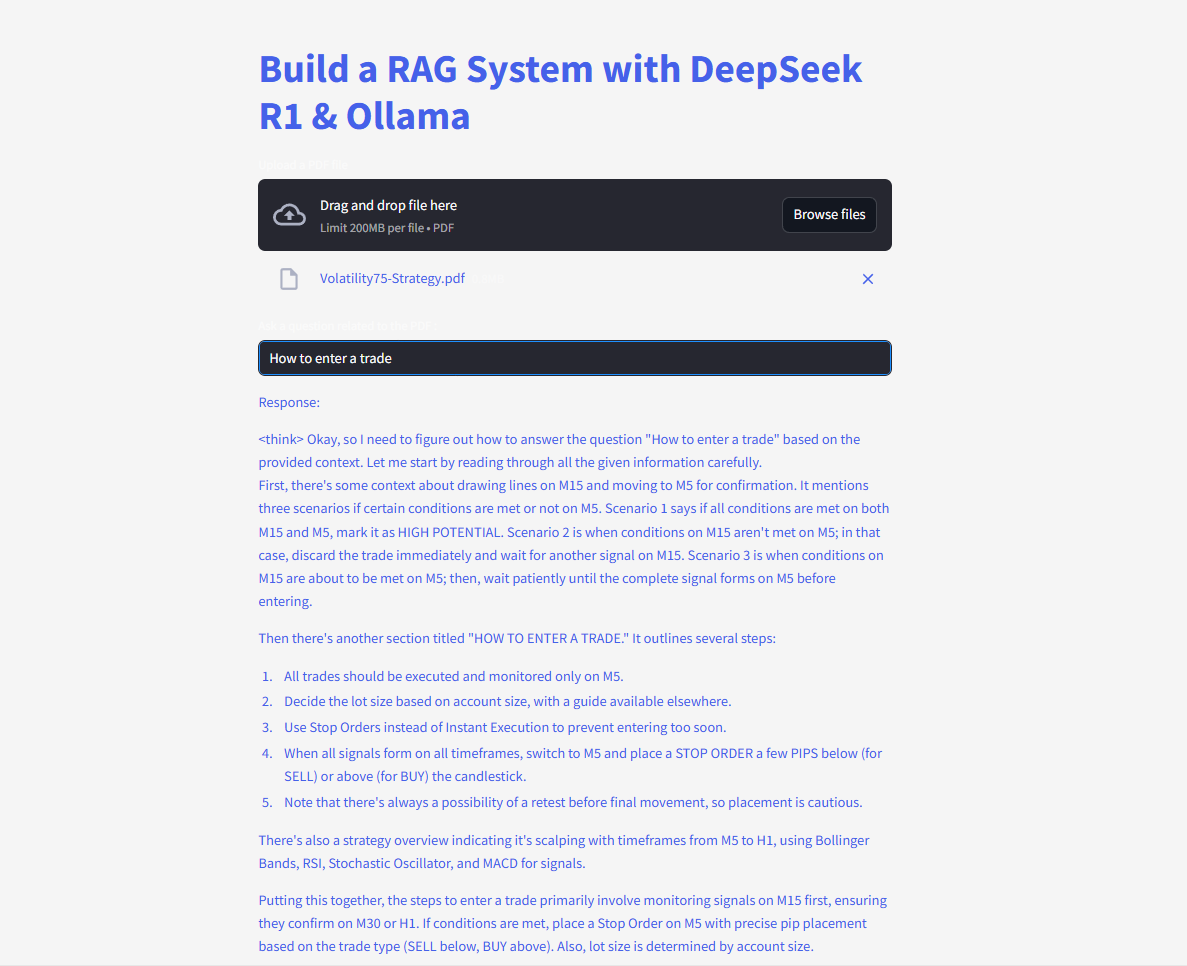
Finalmente, o código usa as funções de entrada de texto e escrita do Streamlit para que os usuários possam digitar perguntas e visualizar respostas imediatamente.
# UI do Streamlit
user_input = st.text_input("Faça uma pergunta ao seu PDF:")
if user_input:
with st.spinner("Pensando..."):
response = qa(user_input)["result"]
st.write(response)
Assim que o usuário insere uma consulta, a cadeia recupera os melhores chunks correspondentes, alimenta-os no modelo de linguagem e exibe uma resposta. Com a biblioteca langchain devidamente instalada, o código deve funcionar agora sem acionar o erro de módulo ausente.
Faça perguntas e envie consultas para obter respostas instantâneas!
Aqui está o código completo:
O Futuro do RAG com DeepSeek
Com recursos como auto-verificação e raciocínio multi-hop em desenvolvimento, o DeepSeek R1 está pronto para desbloquear aplicações RAG ainda mais avançadas. Imagine uma IA que não apenas responde a perguntas, mas debate sua própria lógica—autonomamente.