
Grandes modelos de linguagem (LLMs) como o Qwen3 estão revolucionando o cenário da IA com suas capacidades impressionantes em codificação, raciocínio e compreensão de linguagem natural. Desenvolvido pela equipe Qwen na Alibaba, o Qwen3 oferece modelos quantizados que permitem a implantação local eficiente, tornando-o acessível para desenvolvedores, pesquisadores e entusiastas executarem esses modelos poderosos em seu próprio hardware. Quer você esteja usando Ollama, LM Studio ou vLLM, este guia irá guiá-lo pelo processo de configuração e execução de modelos quantizados Qwen3 localmente.
Neste guia técnico, exploraremos o processo de configuração, seleção de modelos, métodos de implantação e integração de API. Vamos começar.
O Que São Modelos Quantizados Qwen3?
Qwen3 é a última geração de LLMs da Alibaba, projetada para alto desempenho em tarefas como codificação, matemática e raciocínio geral. Modelos quantizados, como aqueles nos formatos BF16, FP8, GGUF, AWQ e GPTQ, reduzem os requisitos computacionais e de memória, tornando-os ideais para implantação local em hardware de nível de consumidor.
A família Qwen3 inclui vários modelos:
- Qwen3-235B-A22B (MoE): Um modelo mixture-of-experts com formatos BF16, FP8, GGUF e GPTQ-int4.
- Qwen3-30B-A3B (MoE): Outra variante MoE com opções de quantização semelhantes.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): Modelos densos disponíveis nos formatos BF16, FP8, GGUF, AWQ e GPTQ-int8.
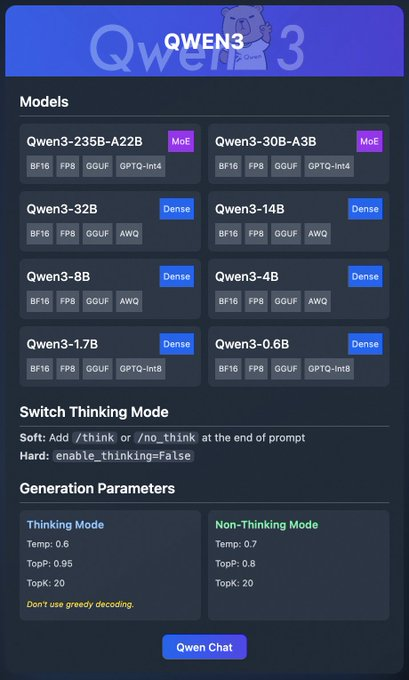
Esses modelos suportam implantação flexível através de plataformas como Ollama, LM Studio e vLLM, que abordaremos em detalhes. Além disso, o Qwen3 oferece recursos como "modo de pensamento" (thinking mode), que pode ser ativado para um melhor raciocínio, e parâmetros de geração para ajustar a qualidade da saída.
Agora que entendemos o básico, vamos passar para os pré-requisitos para executar o Qwen3 localmente.
Pré-requisitos para Executar o Qwen3 Localmente
Antes de implantar modelos quantizados Qwen3, certifique-se de que seu sistema atende aos seguintes requisitos:
Hardware:
- Uma CPU ou GPU moderna (GPUs NVIDIA são recomendadas para vLLM).
- Pelo menos 16GB de RAM para modelos menores como Qwen3-4B; 32GB ou mais para modelos maiores como Qwen3-32B.
- Armazenamento suficiente (por exemplo, Qwen3-235B-A22B GGUF pode exigir ~150GB).
Software:
- Um sistema operacional compatível (Windows, macOS ou Linux).
- Python 3.8+ para vLLM e interações com a API.
- Docker (opcional, para vLLM).
- Git para clonar repositórios.
Dependências:
- Instale as bibliotecas necessárias como
torch,transformersevllm(para vLLM). - Baixe os binários do Ollama ou LM Studio dos seus sites oficiais.
Com esses pré-requisitos atendidos, vamos prosseguir para baixar os modelos quantizados Qwen3.
Passo 1: Baixar Modelos Quantizados Qwen3
Primeiro, você precisa baixar os modelos quantizados de fontes confiáveis. A equipe Qwen fornece modelos Qwen3 no Hugging Face e no ModelScope
- Hugging Face: Coleção Qwen3
- ModelScope: Coleção Qwen3
Como Baixar do Hugging Face
- Visite a coleção Qwen3 no Hugging Face.
- Selecione um modelo, como o Qwen3-4B no formato GGUF para implantação leve.
- Clique no botão "Download" ou use o comando
git clonepara buscar os arquivos do modelo:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- Armazene os arquivos do modelo em um diretório, como
/models/qwen3-4b-gguf.
Como Baixar do ModelScope
- Navegue até a coleção Qwen3 no ModelScope.
- Escolha o modelo e o formato de quantização desejados (por exemplo, AWQ ou GPTQ).
- Baixe os arquivos manualmente ou use a API deles para acesso programático.
Uma vez que os modelos forem baixados, vamos explorar como implantá-los usando o Ollama.
Passo 2: Implantar Qwen3 Usando Ollama
Ollama oferece uma maneira amigável de executar LLMs localmente com configuração mínima. Ele suporta o formato GGUF do Qwen3, tornando-o ideal para iniciantes.
Instalar Ollama
- Visite o site oficial do Ollama e baixe o binário para o seu sistema operacional.
- Instale o Ollama executando o instalador ou seguindo as instruções da linha de comando:
curl -fsSL https://ollama.com/install.sh | sh
- Verifique a instalação:
ollama --version
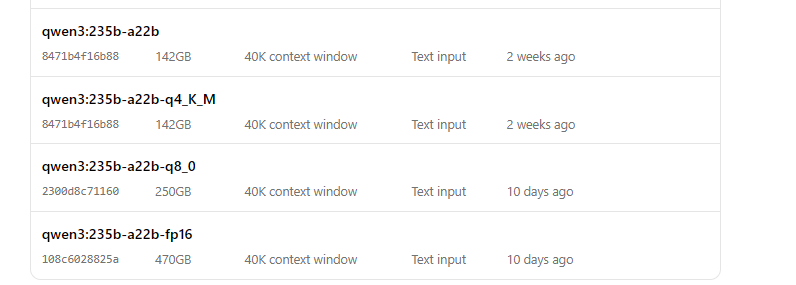
Executar Qwen3 com Ollama
- Inicie o modelo:
ollama run qwen3:235b-a22b-q8_0- Assim que o modelo estiver em execução, você pode interagir com ele via linha de comando:
>>> Hello, how can I assist you today?
O Ollama também fornece um endpoint de API local (geralmente http://localhost:11434) para acesso programático, que testaremos mais tarde usando o Apidog.
Em seguida, vamos explorar como usar o LM Studio para executar o Qwen3.
Passo 3: Implantar Qwen3 Usando LM Studio
O LM Studio é outra ferramenta popular para executar LLMs localmente, oferecendo uma interface gráfica para gerenciamento de modelos.
Instalar LM Studio
- Baixe o LM Studio do seu site oficial.
- Instale o aplicativo seguindo as instruções na tela.
- Inicie o LM Studio e certifique-se de que está em execução.
Carregar Qwen3 no LM Studio
No LM Studio, vá para a seção "Local Models".
Clique em "Add Model" e procure o modelo para baixá-lo:
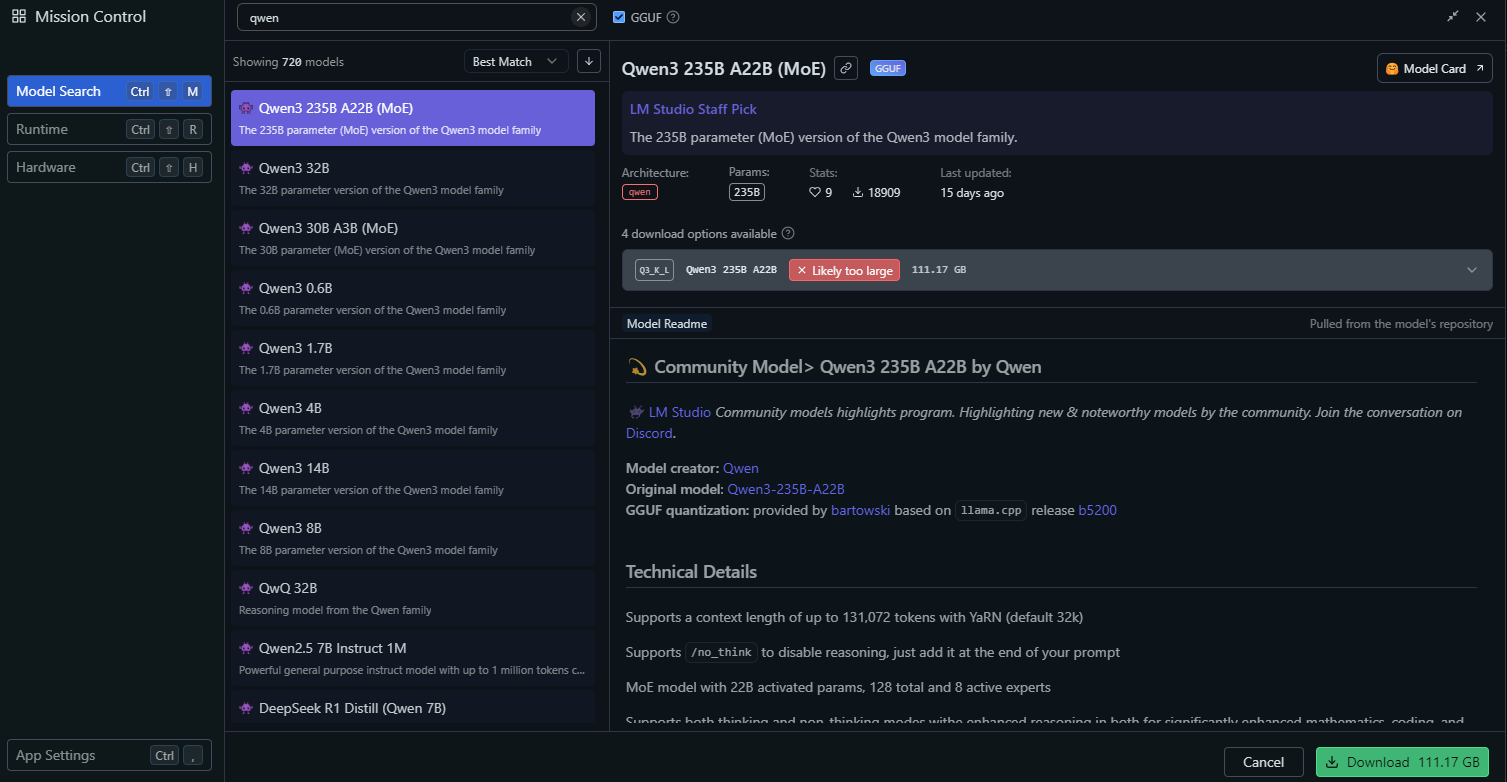
Configure as definições do modelo, como:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
Estas configurações correspondem aos parâmetros recomendados para o modo de pensamento (thinking mode) do Qwen3.
Inicie o servidor do modelo clicando em "Start Server". O LM Studio fornecerá um endpoint de API local (por exemplo, http://localhost:1234).
Interagir com Qwen3 no LM Studio
- Use a interface de chat integrada do LM Studio para testar o modelo.
- Alternativamente, acesse o modelo através do seu endpoint de API, que exploraremos na seção de teste de API.
Com o LM Studio configurado, vamos passar para um método de implantação mais avançado usando o vLLM.
Passo 4: Implantar Qwen3 Usando vLLM
vLLM é uma solução de serviço de alto desempenho otimizada para LLMs, suportando os modelos quantizados FP8 e AWQ do Qwen3. É ideal para desenvolvedores que constroem aplicações robustas.
Instalar vLLM
- Certifique-se de que o Python 3.8+ está instalado no seu sistema.
- Instale o vLLM usando pip:
pip install vllm
- Verifique a instalação:
python -c "import vllm; print(vllm.__version__)"
Executar Qwen3 com vLLM
Inicie um servidor vLLM com seu modelo Qwen3
# Load and run the model:
vllm serve "Qwen/Qwen3-235B-A22B"A flag --enable-thinking=False desativa o modo de pensamento (thinking mode) do Qwen3.
Assim que o servidor iniciar, ele fornecerá um endpoint de API em http://localhost:8000.
Configurar vLLM para Desempenho Ótimo
O vLLM suporta configurações avançadas, como:
- Tensor Parallelism: Ajuste
--tensor-parallel-sizecom base na sua configuração de GPU. - Context Length: O Qwen3 suporta até 32.768 tokens, o que pode ser definido via
--max-model-len 32768. - Generation Parameters: Use a API para definir
temperature,top_petop_k(por exemplo, 0.7, 0.8, 20 para o modo não-pensamento).
Com o vLLM em execução, vamos testar o endpoint da API usando o Apidog.
Passo 5: Testar a API do Qwen3 com Apidog
O Apidog é uma ferramenta poderosa para testar endpoints de API, tornando-o perfeito para interagir com seu modelo Qwen3 implantado localmente.
Configurar Apidog
- Baixe e instale o Apidog do site oficial.
- Inicie o Apidog e crie um novo projeto.
Testar API do Ollama
- Crie uma nova requisição de API no Apidog.
- Defina o endpoint para
http://localhost:11434/api/generate. - Configure a requisição:
- Método: POST
- Corpo (JSON):
{
"model": "qwen3-4b",
"prompt": "Hello, how can I assist you today?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- Envie a requisição e verifique a resposta.
Testar API do vLLM
- Crie outra requisição de API no Apidog.
- Defina o endpoint para
http://localhost:8000/v1/completions. - Configure a requisição:
- Método: POST
- Corpo (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Write a Python script to calculate factorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- Envie a requisição e verifique a saída.
O Apidog facilita a validação da sua implantação Qwen3 e garante que a API está funcionando corretamente. Agora, vamos ajustar o desempenho do modelo.
Passo 6: Ajustar o Desempenho do Qwen3
Para otimizar o desempenho do Qwen3, ajuste as seguintes configurações com base no seu caso de uso:
Modo de Pensamento (Thinking Mode)
O Qwen3 suporta um "modo de pensamento" (thinking mode) para raciocínio aprimorado, conforme destacado na imagem da postagem no X. Você pode controlá-lo de duas maneiras:
- Chave Suave (Soft Switch): Adicione
/thinkou/no_thinkao seu prompt.
- Exemplo:
Solve this math problem /think.
- Chave Rígida (Hard Switch): Desative o pensamento completamente no vLLM com
--enable-thinking=False.
Parâmetros de Geração
Ajuste os parâmetros de geração para uma melhor qualidade de saída:
- Temperature: Use 0.6 para o modo de pensamento ou 0.7 para o modo não-pensamento.
- Top-P: Defina para 0.95 (pensamento) ou 0.8 (não-pensamento).
- Top-K: Use 20 para ambos os modos.
- Evite a decodificação gulosa (greedy decoding), conforme recomendado pela equipe Qwen.
Experimente com essas configurações para alcançar o equilíbrio desejado entre criatividade e precisão.
Solução de Problemas Comuns
Ao implantar o Qwen3, você pode encontrar alguns problemas. Aqui estão soluções para problemas comuns:
O Modelo Falha ao Carregar no Ollama:
- Certifique-se de que o caminho do arquivo GGUF no
Modelfileestá correto. - Verifique se o seu sistema tem memória suficiente para carregar o modelo.
Erro de Tensor Parallelism no vLLM:
- Se você vir um erro como "output_size is not divisible by weight quantization block_n", reduza o
--tensor-parallel-size(por exemplo, para 4).
Requisição de API Falha no Apidog:
- Verifique se o servidor (Ollama, LM Studio ou vLLM) está em execução.
- Verifique novamente a URL do endpoint e o payload da requisição.
Ao resolver esses problemas, você pode garantir uma experiência de implantação tranquila.
Conclusão
Executar modelos quantizados Qwen3 localmente é um processo direto com ferramentas como Ollama, LM Studio e vLLM. Quer você seja um desenvolvedor construindo aplicações ou um pesquisador experimentando LLMs, o Qwen3 oferece a flexibilidade e o desempenho que você precisa. Seguindo este guia, você aprendeu como baixar modelos do Hugging Face e ModelScope, implantá-los usando vários frameworks e testar seus endpoints de API com o Apidog.
Comece a explorar o Qwen3 hoje e desbloqueie o poder dos LLMs locais para seus projetos!