
A série Qwen da Alibaba continua a expandir os limites dos grandes modelos de linguagem, e o Qwen3-Next-80B-A3B se destaca como um excelente exemplo de eficiência aliada a alto desempenho. Engenheiros e desenvolvedores buscam modelos que ofereçam raciocínio robusto sem a sobrecarga computacional de gigantes densos. Este modelo atende a essa demanda de frente, ostentando 80 bilhões de parâmetros, mas ativando apenas 3 bilhões por token. Consequentemente, as equipes alcançam velocidades de inferência mais rápidas e custos de treinamento reduzidos, tornando-o ideal para implantações no mundo real.
Nesta publicação, você explorará os componentes centrais do Qwen3-Next-80B-A3B, dissecando sua arquitetura inovadora, revisando dados de desempenho empíricos e dominando sua API por meio de etapas práticas. Além disso, você integrará ferramentas como o Apidog para aprimorar seu fluxo de trabalho. Ao final, você possuirá o conhecimento para implantar este modelo de forma eficaz em suas aplicações.
O que define o Qwen3-Next-80B-A3B? Principais recursos e inovações
O Qwen3-Next-80B-A3B surge da família Qwen da Alibaba como um modelo de Mistura de Especialistas (MoE) esparso, otimizado para velocidade e capacidade. Os desenvolvedores ativam apenas uma fração de seus parâmetros durante a inferência, o que se traduz em economias substanciais de recursos. Especificamente, este modelo emprega uma configuração MoE ultra-esparsa com 512 especialistas, roteando para 10 por token, juntamente com um especialista compartilhado. Como resultado, ele rivaliza com o desempenho de modelos mais densos, como o Qwen3-32B, enquanto consome muito menos energia.
Além disso, o modelo suporta a previsão de múltiplos tokens, uma técnica que acelera a decodificação especulativa. Esse recurso permite que o modelo gere vários tokens simultaneamente, aumentando o throughput nas etapas de decodificação. Os desenvolvedores apreciam isso para aplicações que exigem respostas rápidas, como chatbots ou ferramentas de análise em tempo real.
A série inclui variantes adaptadas a necessidades específicas: o modelo base para pré-treinamento geral, a versão de instrução para tarefas conversacionais ajustadas e a variante de pensamento para cadeias de raciocínio avançadas. Por exemplo, o Qwen3-Next-80B-A3B-Thinking se destaca na resolução de problemas complexos, superando modelos como o Gemini-2.5-Flash-Thinking em benchmarks. Além disso, ele lida com 119 idiomas, permitindo implantações multilíngues sem retreinamento.
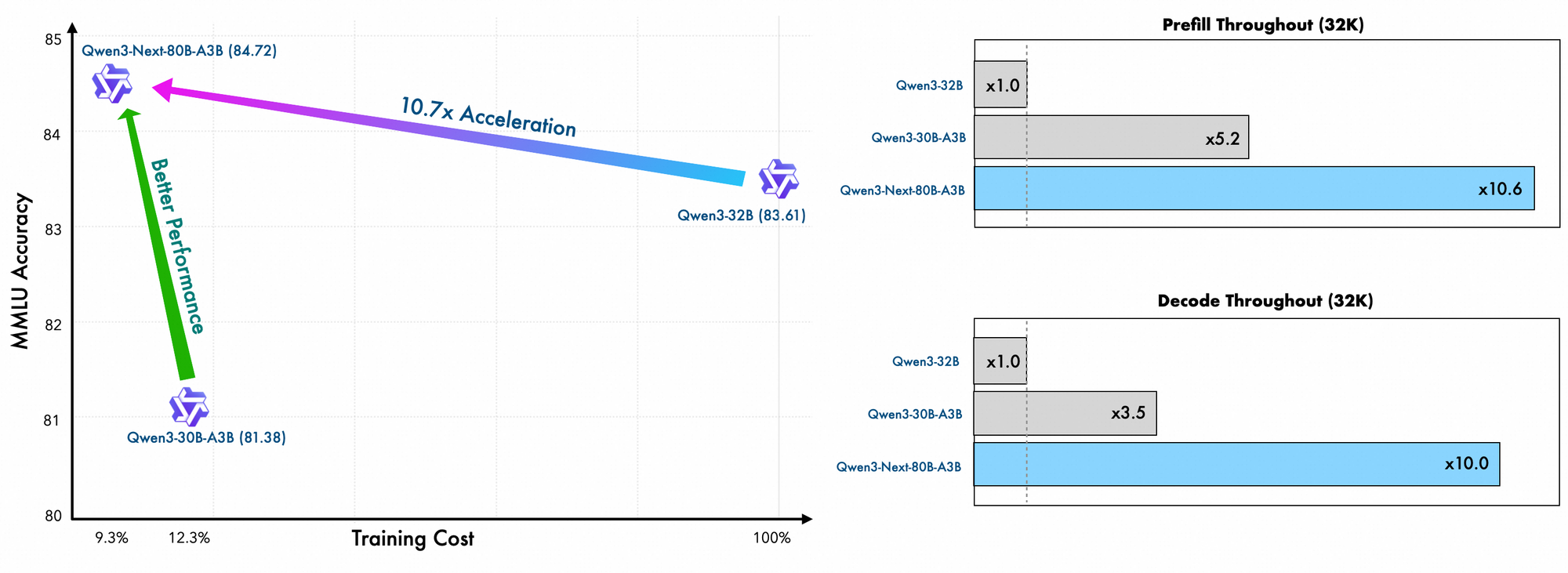
Detalhes do treinamento revelam eficiências adicionais. Os engenheiros da Alibaba pré-treinam este modelo usando métodos eficientes em escala, incorrendo em apenas 10% do custo em comparação com o Qwen3-32B. Eles utilizam um layout híbrido em 48 camadas com uma dimensão oculta de 2048, garantindo uma distribuição computacional equilibrada. Consequentemente, o modelo demonstra uma compreensão superior de contexto longo, mantendo a precisão além de 32K tokens, onde outros falham.
Na prática, esses recursos capacitam os desenvolvedores a escalar soluções de IA de forma econômica. Seja para construir mecanismos de busca corporativos ou geradores de conteúdo automatizados, o Qwen3-Next-80B-A3B fornece a espinha dorsal para aplicações inovadoras. Com base nessa fundação, a próxima seção examina os elementos arquitetônicos que tornam essas eficiências possíveis.
Dissecando a Arquitetura do Qwen3-Next-80B-A3B: Um Projeto Técnico
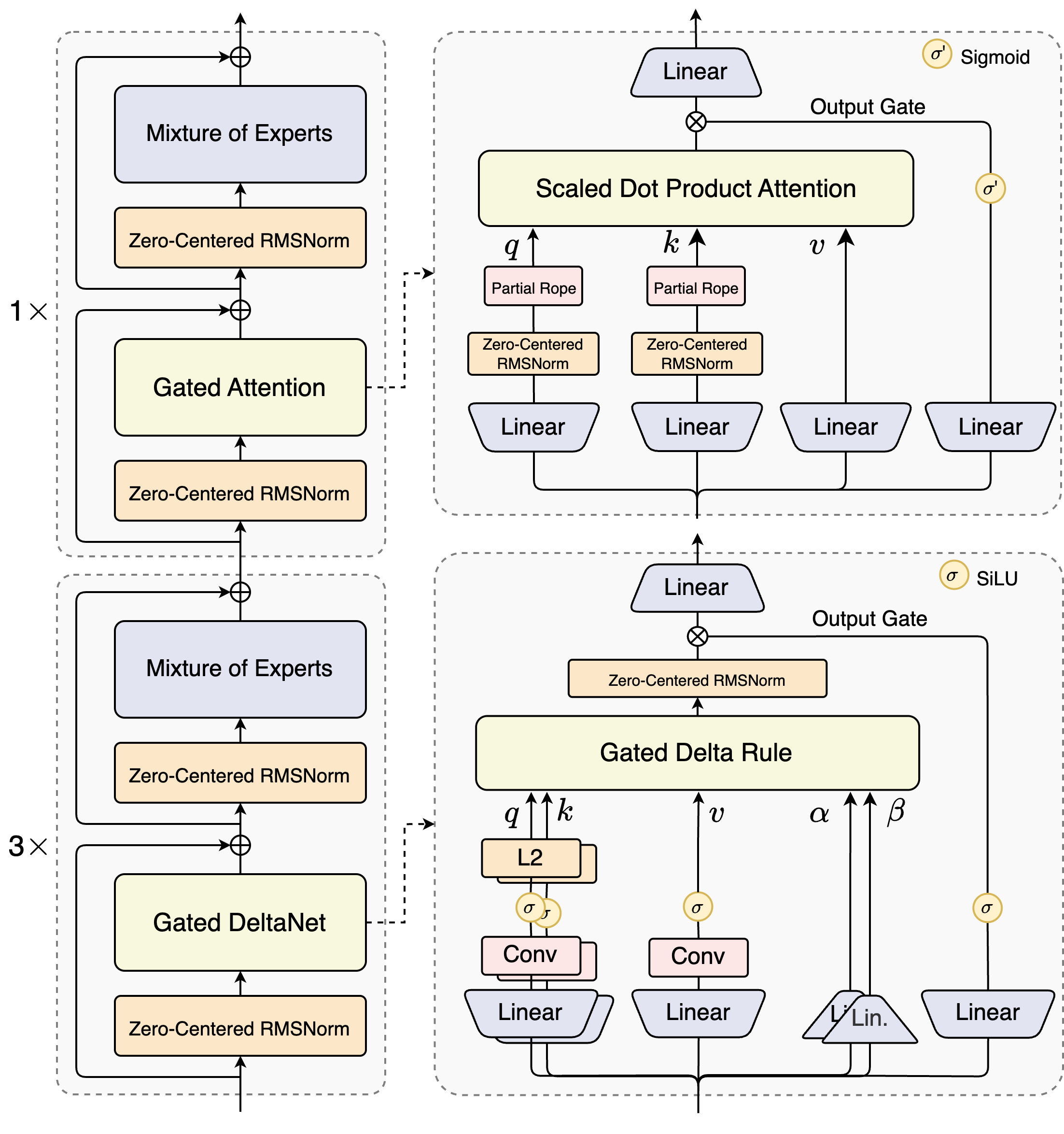
Os arquitetos do Qwen3-Next-80B-A3B introduzem um design híbrido que combina mecanismos de gating com técnicas avançadas de normalização. No seu cerne, encontra-se uma camada de Mistura de Especialistas (MoE), onde os especialistas se especializam em caminhos computacionais distintos. O modelo roteia as entradas dinamicamente, ativando um subconjunto para minimizar a sobrecarga. Por exemplo, o bloco de atenção com gating processa consultas, chaves e valores através de embeddings RoPE parciais e camadas RMSNorm centradas em zero, aumentando a estabilidade em sequências longas.
Considere o módulo de atenção de produto escalar escalado. Ele integra projeções lineares seguidas por portas de saída moduladas por ativações sigmoides. Essa configuração permite controle preciso sobre o fluxo de informações, prevenindo a diluição em espaços de alta dimensão. Além disso, o RMSNorm centrado em zero precede e segue essas operações, centrando as ativações em torno de zero para mitigar problemas de gradiente durante o treinamento.
O diagrama ilustra dois blocos primários: o superior foca na atenção com gating e atenção de produto escalar escalado, enquanto o inferior enfatiza o DeltaNet com gating. No caminho de atenção (expansão 1x), as entradas fluem através de um RMSNorm centrado em zero, e então para o núcleo de atenção com gating. Aqui, as projeções de consulta (q), chave (k) e valor (v) usam RoPE parcial para codificação posicional. Pós-atenção, outro RMSNorm e camadas lineares alimentam o MoE, que emprega uma saída com gating sigmoide.
Transitando para o caminho DeltaNet (expansão 3x), a arquitetura emprega uma regra Delta com gating para previsões refinadas. Ela apresenta normalização L2 em q e k, camadas convolucionais para extração de características locais e ativações SiLU para não-linearidade. A porta de saída, combinada com uma projeção linear, garante saídas de múltiplos tokens coerentes. O design deste bloco suporta a decodificação especulativa do modelo, onde ele prevê vários tokens à frente, verificados em passes subsequentes.
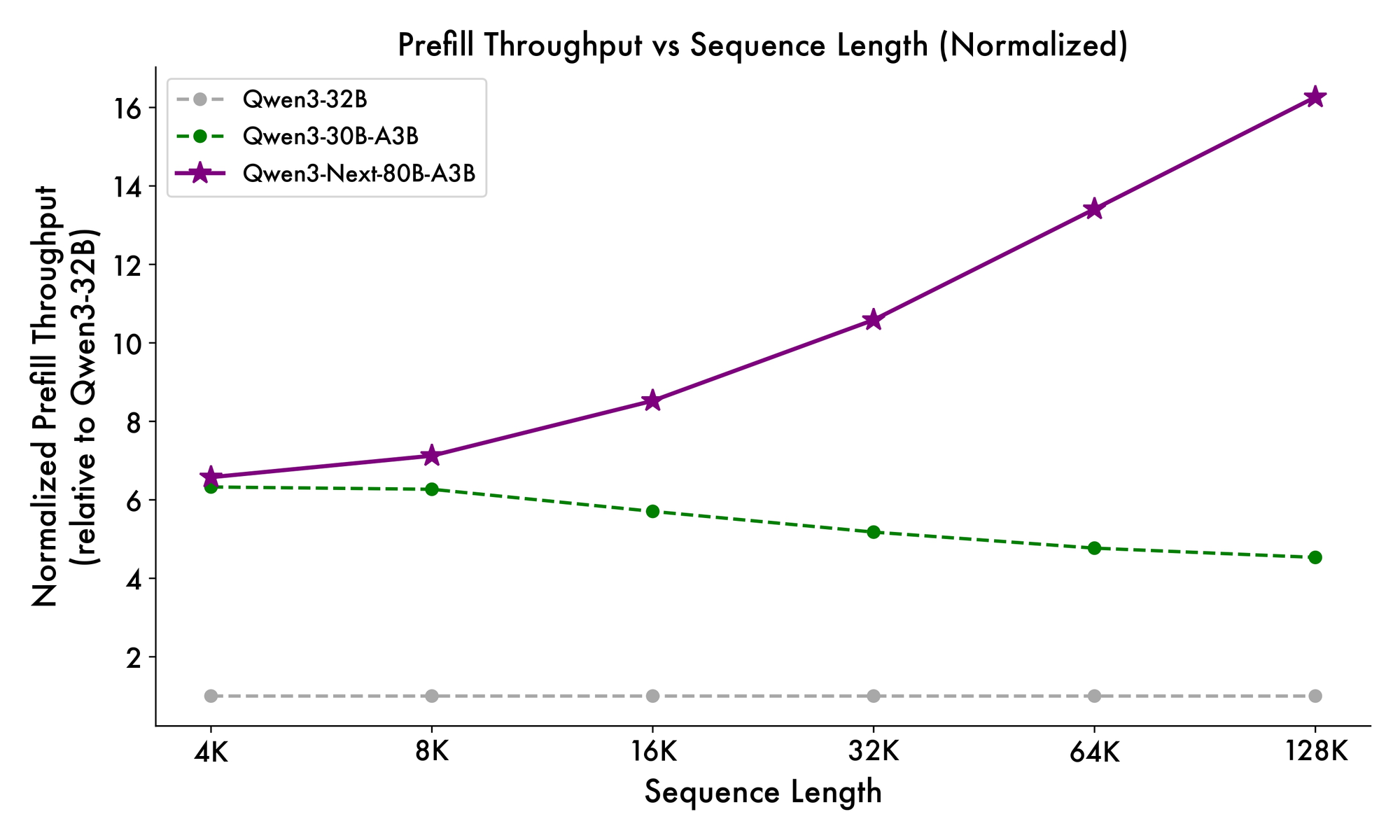
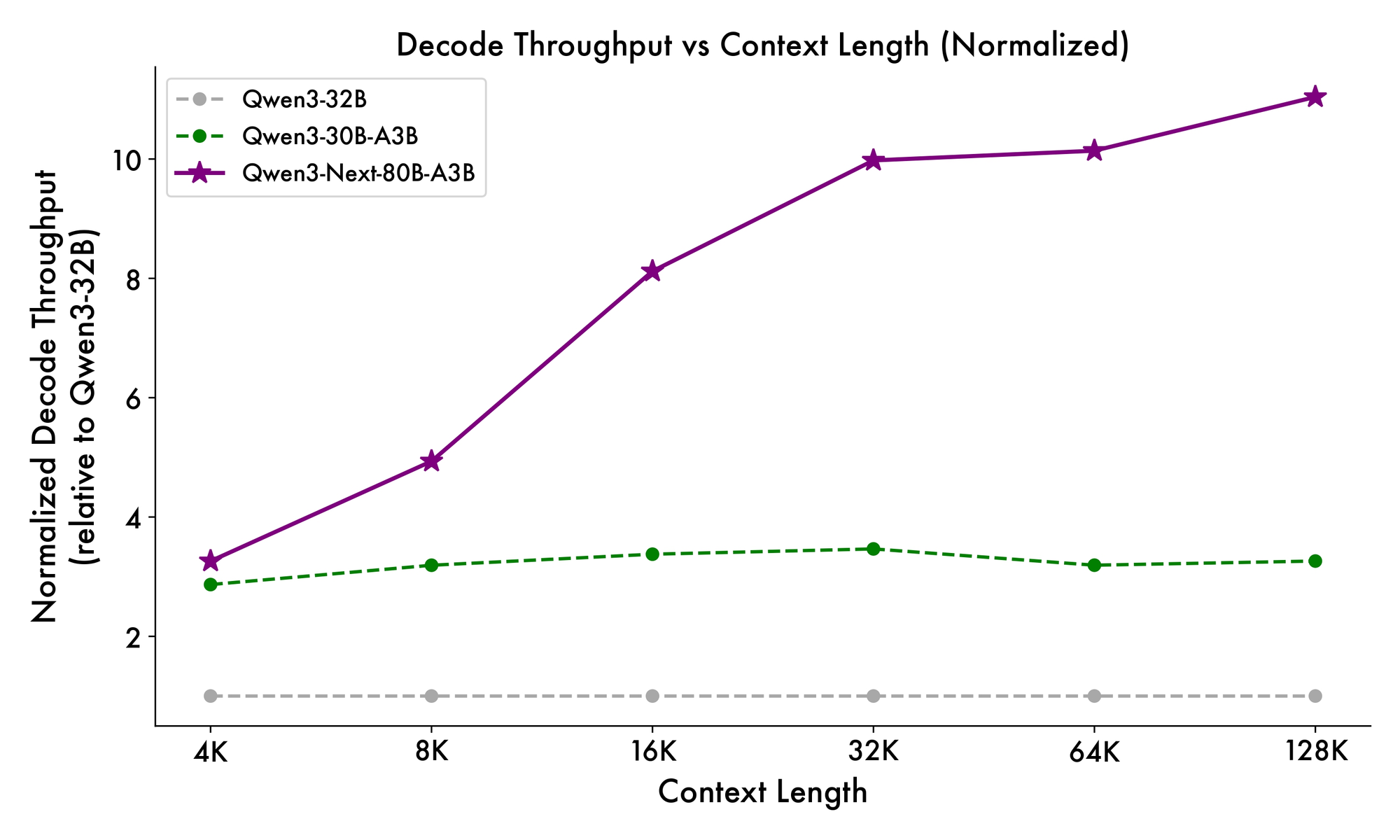
Além disso, a estrutura geral incorpora um especialista compartilhado no MoE para lidar com padrões comuns entre tokens, reduzindo a redundância. Embeddings de corda parcial nas projeções preservam a invariância rotacional para contextos estendidos. Conforme evidenciado em benchmarks, essa configuração produz um throughput quase 7 vezes maior em comprimentos de contexto de 4K em comparação com o Qwen3-32B. Além de 32K tokens, as velocidades excedem 10 vezes, tornando-o adequado para análise de documentos ou tarefas de geração de código.
Os desenvolvedores se beneficiam dessa modularidade ao fazer o fine-tuning. Você pode trocar especialistas ou ajustar os limiares de roteamento para especializar o modelo para domínios como finanças ou saúde. Em essência, a arquitetura não apenas otimiza a computação, mas também promove a adaptabilidade. Com essas informações, agora você se volta para como esses elementos se traduzem em ganhos de desempenho mensuráveis.
Benchmarking do Qwen3-Next-80B-A3B: Métricas de Desempenho Importantes
Avaliações empíricas posicionam o Qwen3-Next-80B-A3B como líder em IA orientada à eficiência. Em benchmarks padrão como MMLU e HumanEval, o modelo base supera o Qwen3-32B, apesar de usar um décimo dos parâmetros ativos. Especificamente, ele atinge 78,5% no MMLU para conhecimento geral, superando concorrentes em 2-3 pontos em subconjuntos de raciocínio.
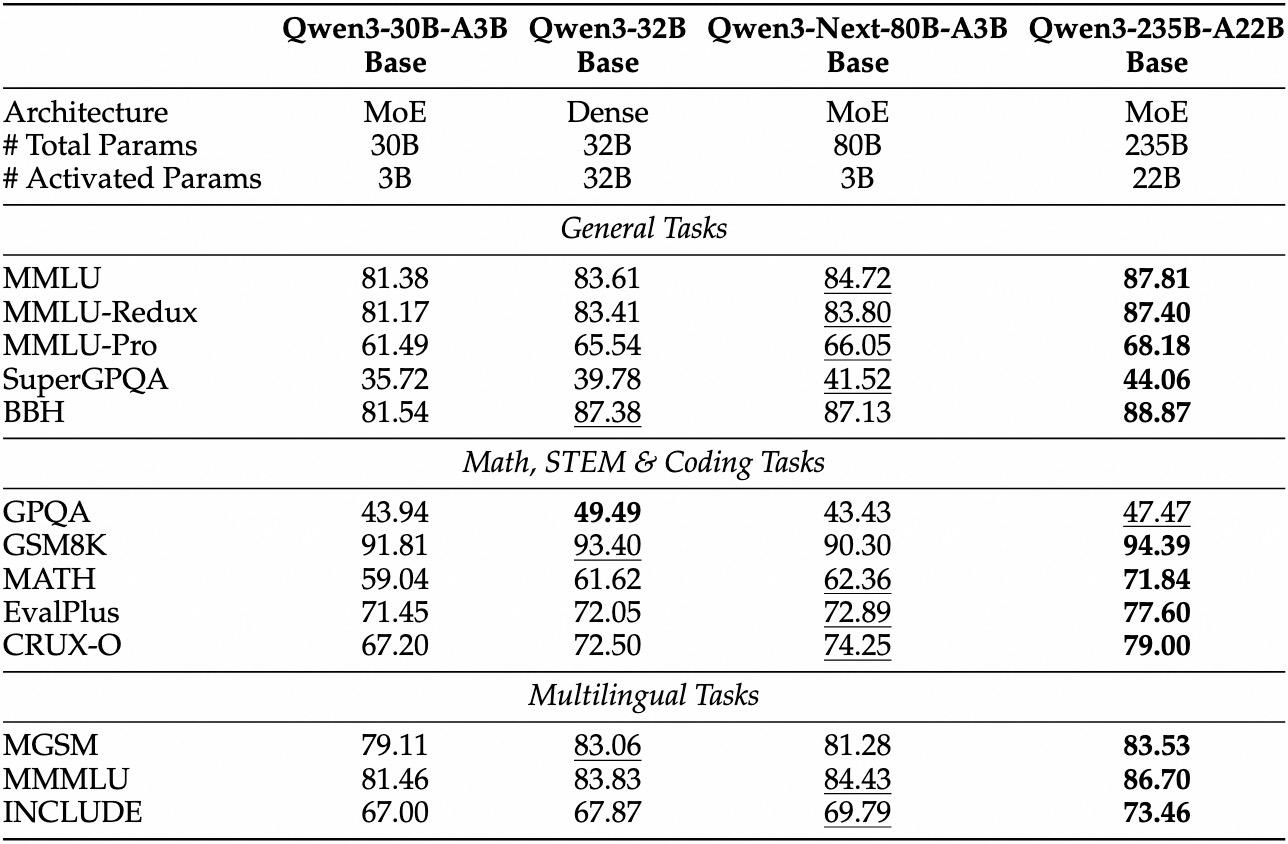
Para a variante de instrução, as tarefas conversacionais revelam pontos fortes na execução de instruções. Ela atinge 85% no MT-Bench, demonstrando diálogos multi-turn coerentes. Enquanto isso, o modelo de pensamento se destaca em cenários de cadeia de pensamento, alcançando 92% no GSM8K para problemas de matemática — superando o Qwen3-30B-A3B-Thinking em 4%.
A velocidade de inferência é um pilar de seu apelo. Em contexto de 4K, o throughput de decodificação atinge 4x o do Qwen3-32B, escalando para 10x em comprimentos maiores. As etapas de pré-preenchimento, críticas para o processamento de prompts, mostram melhorias de 7x, graças ao MoE esparso. O consumo de energia cai correspondentemente, com custos de treinamento em 10% dos modelos mais densos.
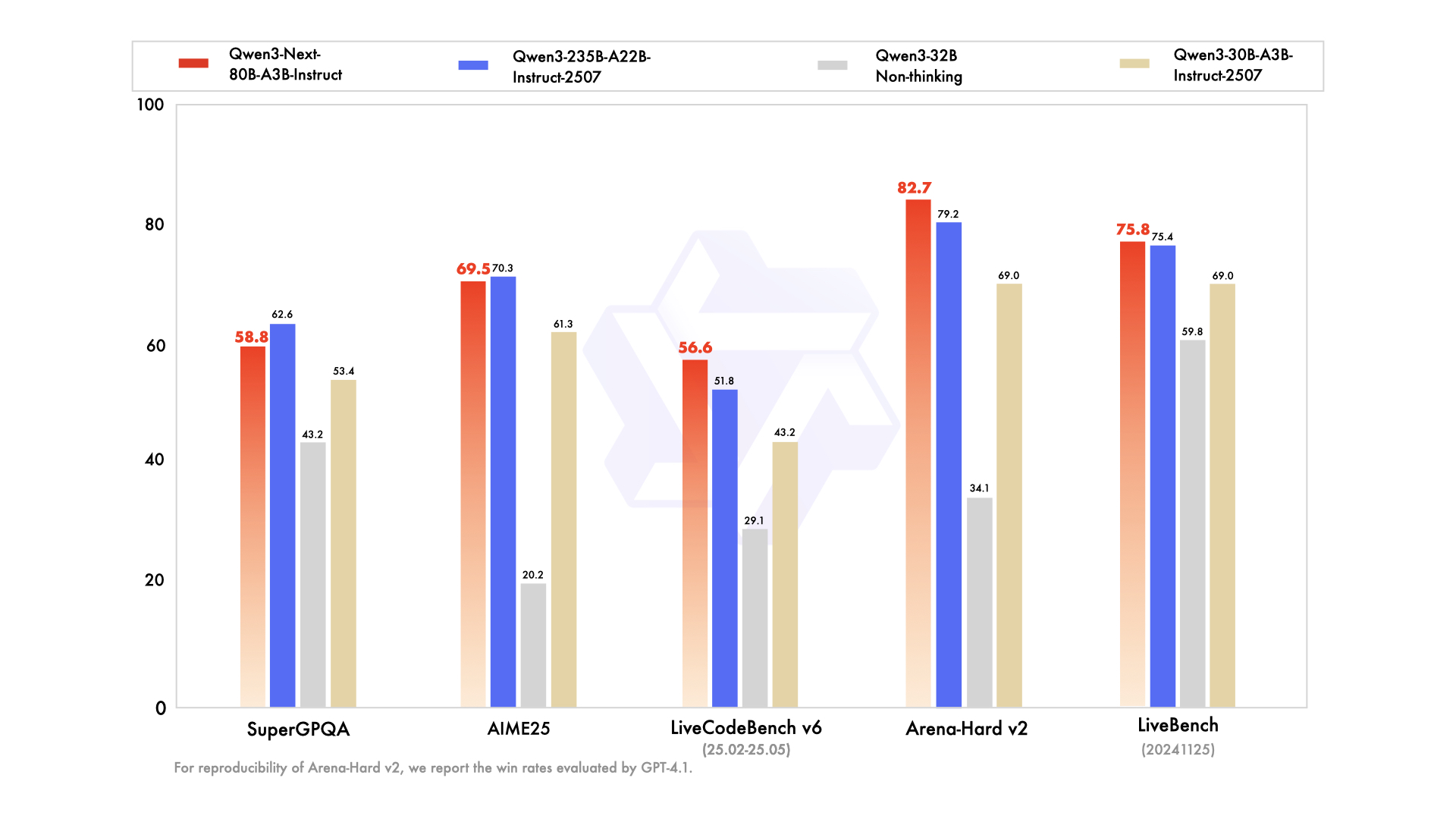
Comparações com rivais destacam sua vantagem. Contra o Llama 3.1-70B, o Qwen3-Next-80B-A3B-Thinking lidera no RULER (recuperação de contexto longo) em 15%, recuperando detalhes de 128K tokens com precisão. Em relação ao DeepSeek-V2, ele oferece melhor suporte multilíngue sem sacrificar a velocidade.

| Benchmark | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Instrução) | 81.9% | 83.5% |
Esta tabela destaca um desempenho consistentemente superior. Como resultado, as organizações o adotam para produção, equilibrando qualidade e custo. Transicionando da teoria para a prática, agora você se equipa com ferramentas de acesso à API.
Configurando o Acesso à API do Qwen3-Next-80B-A3B: Pré-requisitos e Autenticação
A Alibaba fornece a API Qwen através do DashScope, sua plataforma em nuvem, garantindo uma integração perfeita. Primeiro, crie uma conta Alibaba Cloud e navegue até o console do Model Studio. Selecione Qwen3-Next-80B-A3B na lista de modelos — disponível nos modos base, instrução e pensamento.
Obtenha sua chave de API no painel em "API Keys". Essa chave autentica as solicitações, com limites de taxa baseados no seu nível (o nível gratuito oferece 1M de tokens/mês). Para chamadas compatíveis com OpenAI, defina a URL base para https://dashscope.aliyuncs.com/compatible-mode/v1. Os endpoints nativos do DashScope usam https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation.
Instale o SDK Python via pip: pip install dashscope. Esta biblioteca lida com serialização, retentativas e análise de erros. Alternativamente, use clientes HTTP como requests para implementações personalizadas.
As melhores práticas de segurança ditam o armazenamento de chaves em variáveis de ambiente: export DASHSCOPE_API_KEY='sua_chave_aqui'. Consequentemente, seu código permanece portátil entre os ambientes. Com a configuração concluída, você prossegue para a criação de sua primeira chamada de API.
Guia Prático: Usando a API do Qwen3-Next-80B-A3B com Python e DashScope
O DashScope simplifica as interações com o Qwen3-Next-80B-A3B. Comece com uma solicitação de geração básica usando a variante de instrução para respostas semelhantes a bate-papos.
Aqui está um script inicial:
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
Este código envia um prompt e recupera até 200 tokens. O modelo responde com uma explicação concisa, destacando os ganhos de eficiência. Para o modo de pensamento, mude para 'qwen3-next-80b-a3b-thinking' e adicione instruções de raciocínio: "Pense passo a passo antes de responder."
Parâmetros avançados aumentam o controle. Defina top_p=0.9 para amostragem de núcleo, ou repetition_penalty=1.1 para evitar loops. Para contextos longos, especifique max_context_length=131072 para aproveitar a capacidade de 128K do modelo.
Lidar com streaming para aplicativos em tempo real:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
Isso produz saída token a token, ideal para integrações de interface de usuário. O tratamento de erros inclui a verificação de response.code para problemas de cota (por exemplo, 10402 para saldo insuficiente).
Além disso, a chamada de função estende a utilidade. Defina ferramentas no esquema JSON:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
O modelo analisa a intenção e retorna uma chamada de ferramenta, que você executa externamente. Esse padrão impulsiona fluxos de trabalho de agente. Com esses exemplos, você constrói pipelines robustos. Em seguida, incorpore o Apidog para testar e refinar essas chamadas sem codificar a cada vez.
Aprimorando seu Fluxo de Trabalho: Integre o Apidog para Testes da API Qwen3-Next-80B-A3B
O Apidog transforma o desenvolvimento de API em um processo simplificado, particularmente para endpoints de IA como o Qwen3-Next-80B-A3B. Esta plataforma combina design, mocking, teste e documentação em uma única interface, impulsionada por IA para automação inteligente.
Comece importando o esquema DashScope para o Apidog. Crie um novo projeto, adicione o endpoint POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation e cole sua chave de API como um cabeçalho: X-DashScope-API-Key: sua_chave.
Projete as requisições visualmente: Defina o parâmetro do modelo para 'qwen3-next-80b-a3b-instruct', insira um prompt no corpo como JSON {"input": {"messages": [{"role": "user", "content": "Seu prompt aqui"}]}}. A IA do Apidog sugere casos de teste, gerando variações como prompts de casos extremos ou amostras de alta temperatura.
Execute coleções de testes sequencialmente. Por exemplo, compare a latência em diferentes temperaturas:
- Teste 1: Temperatura 0.1, comprimento do prompt 100 tokens.
- Teste 2: Temperatura 1.0, contexto 10K tokens.
A ferramenta rastreia métricas — tempo de resposta, uso de token, taxas de erro — e visualiza tendências em painéis. Simule respostas para desenvolvimento offline: o Apidog simula saídas do Qwen com base em dados históricos, acelerando a construção de front-ends.
A documentação é gerada automaticamente a partir de suas coleções. Exporte especificações OpenAPI com exemplos, incluindo detalhes específicos do Qwen3-Next-80B-A3B, como notas de roteamento MoE. Recursos de colaboração permitem que as equipes compartilhem ambientes, garantindo testes consistentes.
Em um cenário, um desenvolvedor testa prompts multilíngues. A IA do Apidog detecta inconsistências, sugerindo correções como a adição de dicas de idioma. Como resultado, o tempo de integração cai em 40%, de acordo com relatórios de usuários. Para testes específicos de IA, aproveite sua geração inteligente de dados: insira um esquema e ele cria prompts realistas que imitam o tráfego de produção.
Além disso, o Apidog suporta hooks de CI/CD, executando testes de API em pipelines. Conecte-se ao GitHub Actions para validação automatizada pós-implantação. Essa abordagem de ciclo fechado minimiza bugs em aplicativos alimentados por Qwen.
Estratégias Avançadas: Otimizando Chamadas de API do Qwen3-Next-80B-A3B para Produção
A otimização eleva o uso básico à confiabilidade de nível empresarial. Primeiro, agrupe as requisições sempre que possível — o DashScope suporta até 10 prompts por chamada, reduzindo a sobrecarga para tarefas paralelas como fazendas de sumarização.
Monitore a economia de tokens: O modelo cobra por parâmetro ativo, então prompts concisos geram economia. Use o result_format='message' da API para saídas estruturadas, analisando JSON diretamente para evitar pós-processamento.
Para alta disponibilidade, implemente retentativas com backoff exponencial:
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
Isso lida com erros transitórios, como limites de taxa 429. Escale horizontalmente distribuindo chamadas entre regiões — o DashScope oferece endpoints em Singapura e nos EUA.
As considerações de segurança incluem a sanitização de entrada para evitar a injeção de prompt. Valide as entradas do usuário em relação a listas de permissões antes de encaminhá-las para a API. Além disso, registre as respostas anonimamente para auditoria, em conformidade com o GDPR.
Em casos extremos, como contextos ultra-longos, divida as entradas em blocos e encadeie as previsões. A variante de pensamento ajuda aqui: Prompt com "Passo 1: Analisar seção A; Passo 2: Sintetizar com B." Isso mantém a coerência em mais de 100K+ tokens.
Os desenvolvedores também exploram o fine-tuning através da plataforma da Alibaba, embora os usuários da API se limitem à engenharia de prompts. Consequentemente, essas táticas garantem implantações escaláveis e seguras.
Conclusão: Por que o Qwen3-Next-80B-A3B Merece Sua Atenção
O Qwen3-Next-80B-A3B redefine a IA eficiente com seu MoE esparso, gates híbridos e benchmarks superiores. Os desenvolvedores aproveitam sua API via DashScope para prototipagem rápida, aprimorada por ferramentas como o Apidog para rigor nos testes.
Agora você tem o projeto: desde as nuances arquitetônicas até as otimizações de produção. Implemente essas informações para construir sistemas mais rápidos e inteligentes. Experimente hoje — o futuro da inteligência escalável o aguarda.