
A equipe Qwen da Alibaba lançou o Qwen3-Coder-Flash, sua mais recente variante de modelo de codificação que promete "geração de código ultrarrápida e precisa" com algumas especificações técnicas impressionantes. No entanto, a verdadeira pergunta que os desenvolvedores estão fazendo é se este novo modelo pode realmente lidar com desafios de codificação de nível empresarial ou se é apenas mais uma melhoria incremental.
O Que Torna o Qwen3-Coder-Flash Diferente
Para entender o Qwen3-Coder-Flash, é preciso examinar sua arquitetura e posicionamento dentro do ecossistema de modelos em expansão da Alibaba. Este modelo possui um total de 30,5 bilhões de parâmetros, com 3,3 bilhões ativos a qualquer momento, utilizando uma arquitetura Mixture-of-Experts que permite que ele funcione eficientemente em sistemas Mac de 64 GB ou até mesmo em sistemas de 32 GB quando quantizado.
A convenção de nomenclatura revela um posicionamento estratégico. Enquanto a família Qwen3-Coder mais ampla inclui variantes massivas como o modelo de 480 bilhões de parâmetros, o Qwen3-Coder-Flash visa especificamente desenvolvedores que precisam de geração de código rápida e eficiente sem exigir enormes recursos computacionais. Essa abordagem torna a codificação avançada de IA acessível a desenvolvedores individuais e equipes menores.
Além disso, a designação "Flash" enfatiza a otimização de velocidade. O modelo é projetado como um "modelo não pensante que é especialmente treinado para tarefas de codificação", o que significa que ele se concentra na geração rápida de código, em vez de processos de raciocínio complexos que poderiam atrasar os fluxos de trabalho de desenvolvimento.
Análise Aprofundada da Arquitetura Técnica
A arquitetura Mixture-of-Experts (MoE) representa um avanço técnico significativo na forma como os modelos de codificação operam. Ao contrário dos modelos densos tradicionais que ativam todos os parâmetros para cada computação, o Qwen3-Coder-Flash ativa seletivamente apenas as redes de especialistas mais relevantes para tarefas de codificação específicas. Essa ativação seletiva reduz drasticamente a sobrecarga computacional, mantendo altos níveis de desempenho.
Além disso, o modelo incorpora várias inovações arquitetônicas que o distinguem dos concorrentes. A distribuição de parâmetros permite que redes de especialistas especializadas lidem com diferentes linguagens de programação e paradigmas de codificação de forma mais eficaz. A geração de código Python pode ativar diferentes combinações de especialistas em comparação com tarefas de desenvolvimento em JavaScript ou C++.
A metodologia de treinamento também enfatiza cenários práticos de codificação. O modelo utilizou o Qwen2.5-Coder para limpar e reescrever dados ruidosos, melhorando significativamente o desempenho geral por meio de técnicas avançadas de geração de dados sintéticos. Essa abordagem garante que o modelo compreenda os padrões de codificação do mundo real, em vez de apenas exemplos de programação acadêmicos.
Recursos de Comprimento de Contexto Transformam Fluxos de Trabalho de Desenvolvimento
Uma das vantagens mais significativas do Qwen3-Coder-Flash reside em seus recursos de manipulação de contexto. O modelo oferece suporte nativo a contexto de 256K com recursos de extensão de até 1M de tokens usando a tecnologia YaRN (Yet another RoPE extensioN). Essa janela de contexto estendida muda fundamentalmente a forma como os desenvolvedores podem interagir com assistentes de codificação de IA.
Modelos de codificação tradicionais frequentemente têm dificuldade com grandes bases de código porque não conseguem manter contexto suficiente sobre a estrutura do projeto, dependências e padrões arquitetônicos. No entanto, o contexto estendido do Qwen3-Coder-Flash permite que ele compreenda repositórios inteiros, hierarquias de herança complexas e dependências de vários arquivos simultaneamente.
Além disso, o contexto estendido se mostra particularmente valioso para fluxos de trabalho de desenvolvimento de API. Quando integrado a ferramentas como o Apidog, os desenvolvedores podem fornecer documentação de API abrangente, múltiplas especificações de endpoint e esquemas de dados complexos dentro de uma única janela de contexto. Essa capacidade permite uma geração de código mais precisa que lida adequadamente com os requisitos de integração de API e mantém a consistência entre diferentes endpoints.
As implicações práticas vão além da simples conclusão de código. Os desenvolvedores agora podem fornecer especificações de projeto completas, diagramas arquitetônicos e documentos de requisitos como contexto, permitindo que o modelo gere código que se alinha aos objetivos mais amplos do projeto, em vez de funcionalidades isoladas.
Integração de Plataforma e Ecossistema de Desenvolvedores
O Qwen3-Coder-Flash foi otimizado para plataformas como Qwen Code, Cline, Roo Code e Kilo Code, indicando o foco estratégico da Alibaba no desenvolvimento de ecossistemas, em vez de implantação de modelos autônomos. Essa abordagem centrada na plataforma reconhece que os fluxos de trabalho de desenvolvimento modernos exigem cadeias de ferramentas integradas, em vez de capacidades de IA isoladas.
A estratégia de integração se estende à chamada de funções e fluxos de trabalho de agentes. O modelo apresenta um formato de chamada de função especialmente projetado que suporta codificação agêntica em várias plataformas. Essa padronização permite que os desenvolvedores criem fluxos de trabalho de automação mais sofisticados que podem interagir com várias ferramentas e serviços de desenvolvimento.
Além disso, a compatibilidade do modelo com ambientes de desenvolvimento populares reduz o atrito na adoção. Os desenvolvedores podem integrar o Qwen3-Coder-Flash em fluxos de trabalho existentes sem mudanças significativas na infraestrutura ou aprendizado de novos paradigmas de interface. Essa abordagem de integração perfeita contrasta com modelos que exigem ambientes especializados ou processos de configuração extensos.
Os recursos de fluxo de trabalho de agente também permitem uma automação de desenvolvimento mais sofisticada. As equipes podem criar agentes de IA que lidam com tarefas de codificação de rotina, processos de revisão de código e geração de documentação, mantendo a consistência com os padrões do projeto e os padrões arquitetônicos.
Benchmarks de Desempenho e Testes no Mundo Real
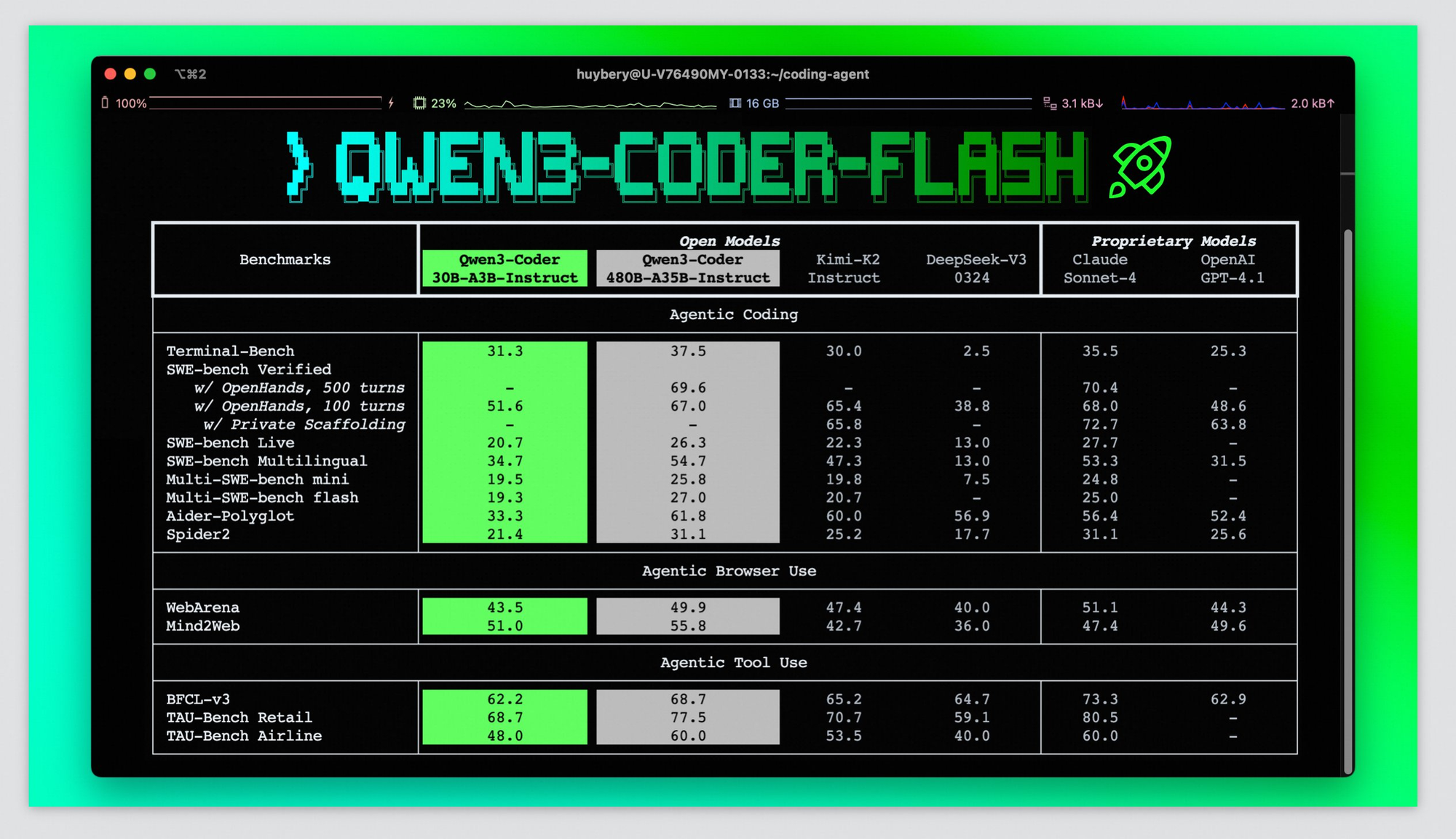
A avaliação do desempenho do Qwen3-Coder-Flash exige o exame de benchmarks sintéticos e cenários de desenvolvimento do mundo real. A família Qwen3-Coder mais ampla alcança desempenho de codificação de ponta, rivalizando com Claude Sonnet-4, GPT-4.1 e Kimi K2, com 61,8% de desempenho nos benchmarks Aider Polygot. Embora benchmarks específicos para a variante Flash ainda não estejam disponíveis, suas semelhanças arquitetônicas sugerem níveis de desempenho comparáveis.
No entanto, o desempenho em benchmarks conta apenas parte da história. O desenvolvimento no mundo real envolve cenários complexos que os benchmarks padrão não capturam: depurar código legado, integrar-se com APIs mal documentadas, lidar com casos extremos em sistemas de produção e manter a qualidade do código em grandes equipes.
O feedback inicial dos desenvolvedores sugere que o Qwen3-Coder-Flash se destaca em cenários de prototipagem rápida, onde a velocidade importa mais do que a otimização perfeita. O modelo gera código funcional rapidamente, permitindo que os desenvolvedores iterem rapidamente durante as fases de exploração. No entanto, a implantação em produção frequentemente exige revisão e otimização adicionais que o modelo não pode fornecer automaticamente.
O desempenho do modelo também varia significativamente entre diferentes linguagens de programação e frameworks. Embora demonstre fortes capacidades com linguagens populares como Python e JavaScript, o desempenho com linguagens especializadas ou frameworks emergentes pode ser menos consistente.
Integração com Ferramentas de Desenvolvimento de API
A sinergia entre o Qwen3-Coder-Flash e plataformas de desenvolvimento de API como o Apidog cria poderosos fluxos de trabalho de desenvolvimento que otimizam todo o ciclo de vida da API. Quando os desenvolvedores usam os recursos abrangentes de design e teste de API do Apidog juntamente com os recursos de geração de código do Qwen3-Coder-Flash, eles podem prototipar, implementar e testar endpoints de API rapidamente com eficiência sem precedentes.
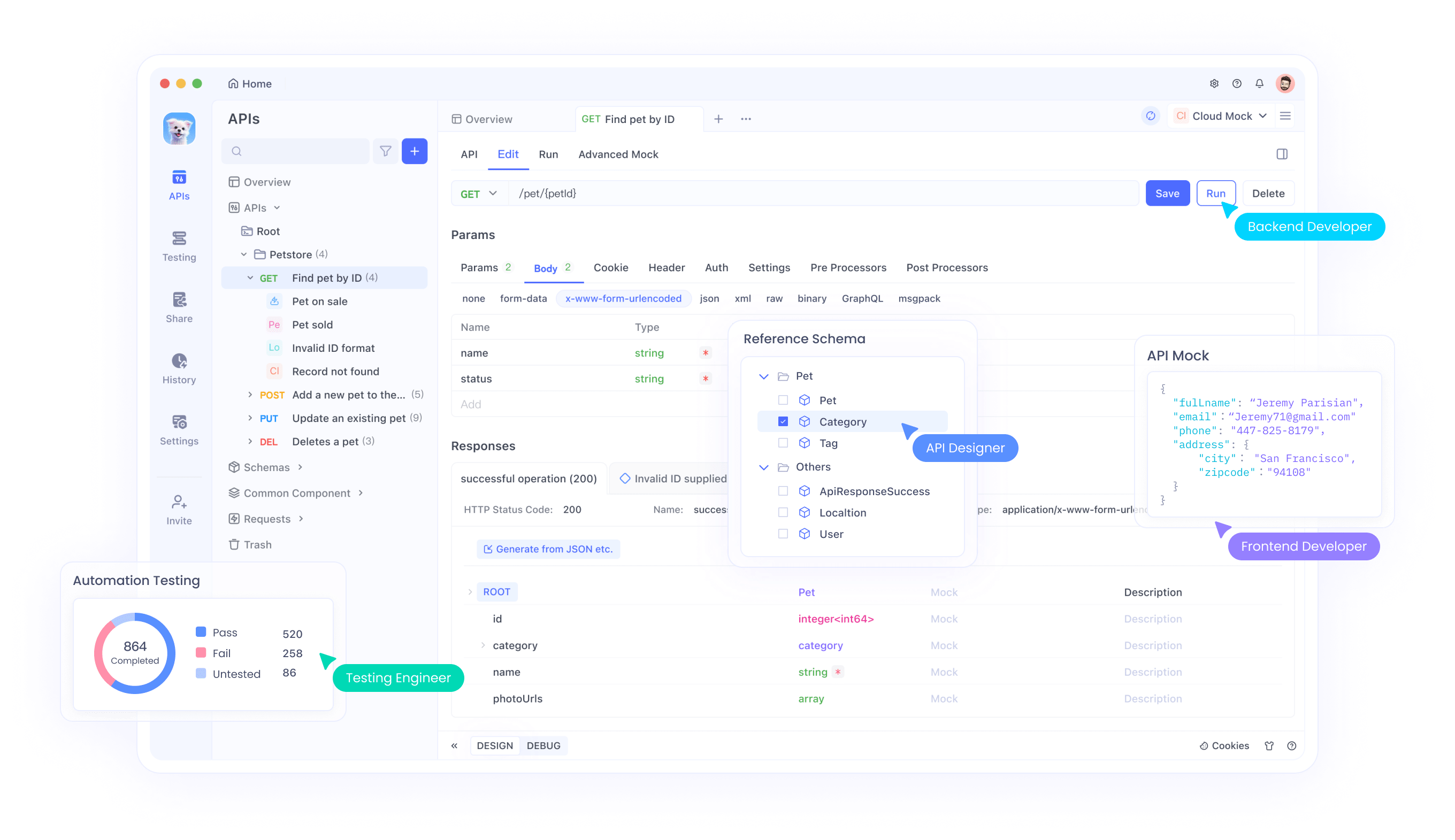
Especificamente, o designer visual de API do Apidog pode gerar especificações abrangentes que o Qwen3-Coder-Flash pode então converter em implementações de código funcionais. A janela de contexto estendida do modelo permite que ele compreenda esquemas de API complexos, requisitos de autenticação e regras de validação de dados simultaneamente, produzindo código que lida adequadamente com todos os requisitos especificados.
Além disso, a integração permite fluxos de trabalho de teste automatizados onde o Qwen3-Coder-Flash gera casos de teste com base em especificações de API, enquanto o Apidog executa esses testes e fornece feedback detalhado sobre a correção da implementação. Esse processo de desenvolvimento em ciclo fechado reduz significativamente o tempo entre o design da API e a implementação funcional.
O potencial colaborativo se estende a cenários de desenvolvimento em equipe, onde múltiplos desenvolvedores trabalham em diferentes componentes de API. O Qwen3-Coder-Flash pode manter a consistência entre diferentes implementações de endpoint, compreendendo a arquitetura mais ampla da API através do gerenciamento centralizado de especificações do Apidog.
Limitações e Considerações
Apesar de suas capacidades impressionantes, o Qwen3-Coder-Flash enfrenta várias limitações que os desenvolvedores devem considerar. O foco do modelo na velocidade às vezes ocorre em detrimento da otimização de código e das melhores práticas. O código gerado pode ser funcionalmente correto, mas carecer das otimizações de eficiência que desenvolvedores experientes implementariam.
Considerações de segurança também exigem atenção cuidadosa. Embora o modelo gere código sintaticamente correto, ele nem sempre pode implementar medidas de segurança adequadas, como validação de entrada, prevenção de injeção de SQL ou tratamento adequado de autenticação. Os desenvolvedores ainda devem realizar revisões de segurança e implementar salvaguardas apropriadas.
Além disso, as limitações dos dados de treinamento do modelo significam que ele pode ter dificuldades com frameworks de ponta, recursos de linguagem recém-lançados ou conhecimento de domínio altamente especializado. Desenvolvedores que trabalham com tecnologias emergentes devem esperar fornecer contexto e orientação adicionais para obter resultados ótimos.
Os requisitos de custo e infraestrutura também apresentam desafios práticos. Embora mais eficiente que modelos maiores, o Qwen3-Coder-Flash ainda exige recursos computacionais significativos para um desempenho ideal. As organizações devem equilibrar os benefícios de produtividade com os custos e a complexidade da infraestrutura.
Estratégias de Implementação para Equipes de Desenvolvimento
A implementação bem-sucedida do Qwen3-Coder-Flash exige um planejamento estratégico que considere tanto os requisitos técnicos quanto a dinâmica da equipe. As organizações devem começar com projetos-piloto que aproveitem os pontos fortes do modelo, minimizando a exposição às suas limitações.
A implementação inicial deve focar em casos de uso onde a geração rápida de código oferece valor claro: criação de endpoints de API, geração de casos de teste, automação de documentação e desenvolvimento de protótipos. Esses cenários permitem que as equipes ganhem experiência com o modelo, ao mesmo tempo em que entregam melhorias tangíveis de produtividade.
Treinamento e gestão de mudanças também exigem atenção cuidadosa. As equipes de desenvolvimento precisam de orientação sobre engenharia de prompt eficaz, compreensão das limitações do modelo e integração de código gerado por IA em processos de garantia de qualidade existentes. Sem o treinamento adequado, as equipes podem subutilizar as capacidades do modelo ou depender excessivamente de sua saída sem validação apropriada.
A integração com ferramentas de desenvolvimento existentes deve ser gradual e medida. Em vez de substituir fluxos de trabalho estabelecidos por completo, as organizações devem identificar pontos problemáticos específicos onde o Qwen3-Coder-Flash pode fornecer melhorias imediatas, mantendo a estabilidade geral do fluxo de trabalho.
Conclusão
O Qwen3-Coder-Flash representa um avanço significativo na assistência de codificação de IA acessível, oferecendo capacidades de nível empresarial em um pacote mais eficiente e econômico. Seus recursos de contexto estendido, arquitetura MoE e integrações de plataforma criam oportunidades poderosas para equipes de desenvolvimento que buscam acelerar seus fluxos de trabalho de codificação.
No entanto, o sucesso com o Qwen3-Coder-Flash exige expectativas realistas e implementação estratégica. O modelo se destaca na geração rápida de código e prototipagem, mas não pode substituir a expertise humana em design de arquitetura, implementação de segurança e otimização de código. Organizações que compreendem esses limites e implementam processos apropriados obterão ganhos significativos de produtividade.