A equipe Qwen da Alibaba Cloud lançou duas adições poderosas à sua linha de modelos de linguagem grandes (LLM): Qwen3-4B-Instruct-2507 e Qwen3-4B-Thinking-2507. Esses modelos trazem avanços significativos em raciocínio, seguimento de instruções e compreensão de contexto longo, com suporte nativo para um comprimento de contexto de 256K tokens. Projetados para desenvolvedores, pesquisadores e entusiastas de IA, esses modelos oferecem capacidades robustas para tarefas que vão desde codificação até resolução de problemas complexos. Além disso, ferramentas como o Apidog, uma plataforma gratuita de gerenciamento de API, podem otimizar o teste e a integração desses modelos em suas aplicações.
Compreendendo os Modelos Qwen3-4B
A série Qwen3 representa a mais recente evolução na família de modelos de linguagem grandes da Alibaba Cloud, sucedendo a série Qwen2.5. Especificamente, Qwen3-4B-Instruct-2507 e Qwen3-4B-Thinking-2507 são adaptados para casos de uso distintos: o primeiro se destaca em diálogo de propósito geral e seguimento de instruções, enquanto o último é otimizado para tarefas de raciocínio complexas. Ambos os modelos suportam um comprimento de contexto nativo de 262.144 tokens, permitindo-lhes processar grandes conjuntos de dados, documentos longos ou conversas multi-turno com facilidade. Além disso, sua compatibilidade com frameworks como Hugging Face Transformers e ferramentas de implantação como o Apidog os torna acessíveis para aplicações locais e baseadas em nuvem.
Qwen3-4B-Instruct-2507: Otimizado para Eficiência
O Qwen3-4B-Instruct-2507 opera em modo não-pensante, focando em respostas eficientes e de alta qualidade para tarefas de propósito geral. Este modelo foi ajustado para aprimorar o seguimento de instruções, raciocínio lógico, compreensão de texto e capacidades multilíngues. Notavelmente, ele não gera blocos <think></think>, tornando-o ideal para cenários onde respostas rápidas e diretas são preferidas em vez de raciocínio passo a passo.
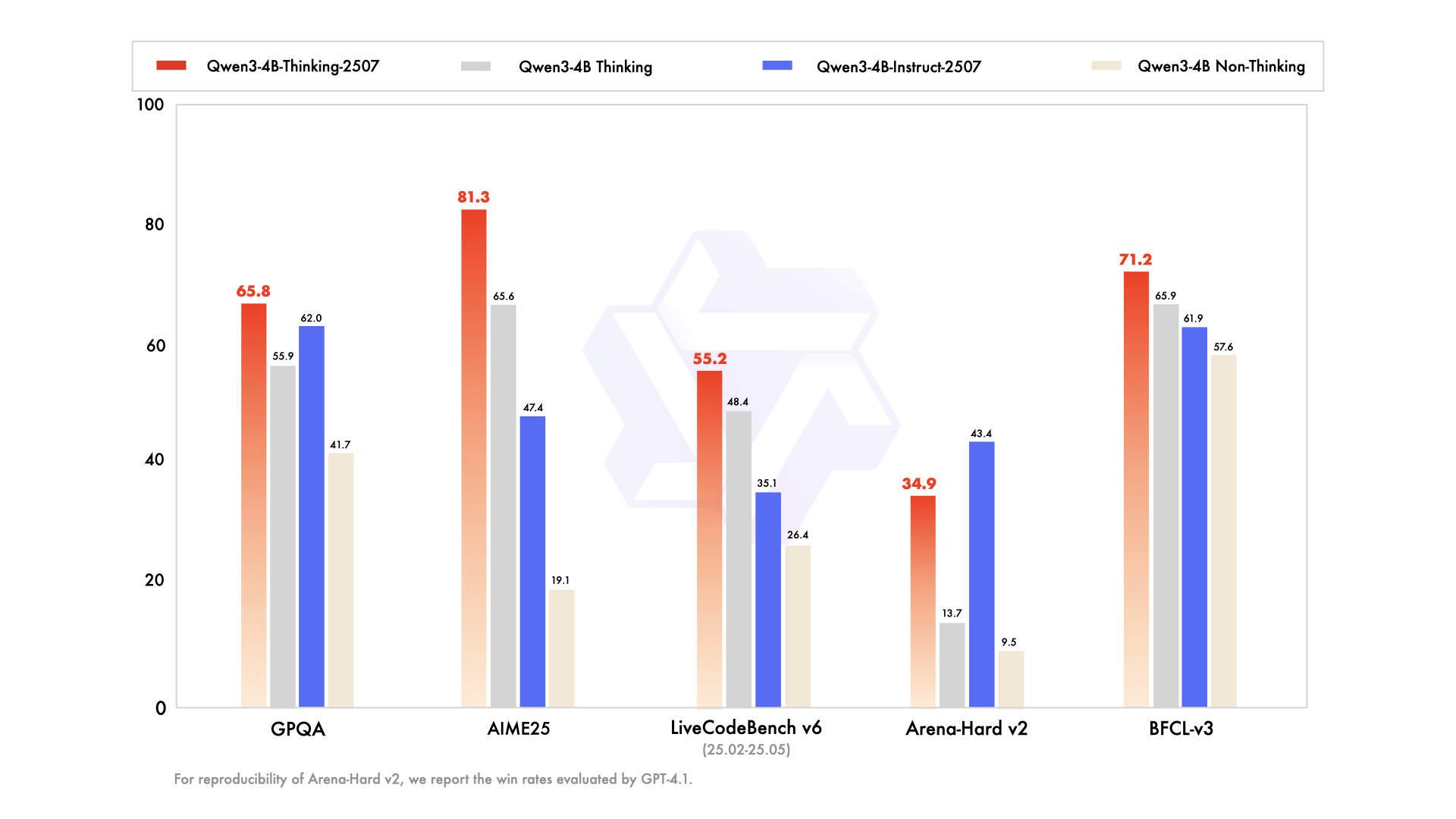
Principais aprimoramentos incluem:
- Capacidades Gerais Aprimoradas: O modelo demonstra desempenho superior em matemática, ciência, codificação e uso de ferramentas, tornando-o versátil para aplicações técnicas.
- Suporte Multilíngue: Abrange mais de 100 idiomas e dialetos, garantindo um desempenho robusto em aplicações globais.
- Compreensão de Contexto Longo: Com um comprimento de contexto de 256K tokens, ele lida com entradas estendidas, como documentos legais ou bases de código extensas, sem truncamento.
- Alinhamento com as Preferências do Usuário: O modelo oferece respostas mais naturais e envolventes, destacando-se na escrita criativa e em diálogos multi-turno.
Para desenvolvedores que integram este modelo em APIs, o Apidog oferece uma interface amigável para testar e gerenciar endpoints de API, garantindo uma implantação perfeita. Essa eficiência torna o Qwen3-4B-Instruct-2507 uma escolha ideal para aplicações que exigem respostas rápidas e precisas.
Qwen3-4B-Thinking-2507: Construído para Raciocínio Profundo
Em contraste, o Qwen3-4B-Thinking-2507 é projetado para tarefas que exigem raciocínio intensivo, como resolução de problemas lógicos, matemática e benchmarks acadêmicos. Este modelo opera exclusivamente no modo de pensamento, incorporando automaticamente processos de cadeia de pensamento (CoT) para decompor problemas complexos. Sua saída pode incluir uma tag de fechamento </think> sem uma tag de abertura <think>, pois o modelo de chat padrão incorpora o comportamento de pensamento.
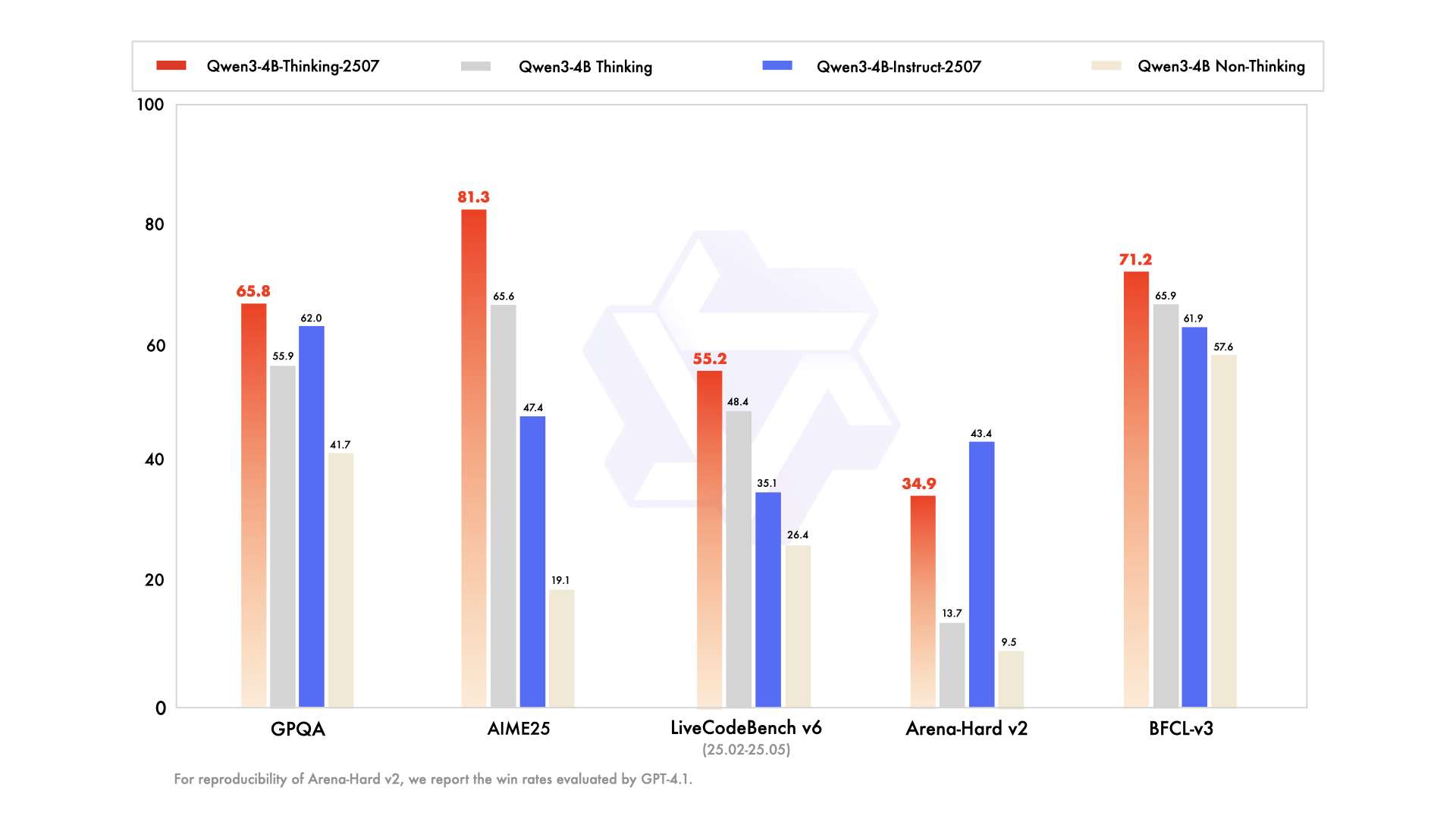
Principais aprimoramentos incluem:
- Capacidades Avançadas de Raciocínio: O modelo alcança resultados de ponta entre os modelos de pensamento de código aberto, particularmente em campos STEM e codificação.
- Profundidade de Pensamento Aumentada: Ele se destaca em tarefas que exigem raciocínio em nível de especialista humano, com um comprimento de pensamento estendido para análise completa.
- Comprimento de Contexto de 256K: Assim como sua contraparte Instruct, ele suporta janelas de contexto massivas, ideais para processar grandes conjuntos de dados ou consultas complexas.
- Integração de Ferramentas: O modelo aproveita ferramentas como Qwen-Agent para fluxos de trabalho de agente simplificados, aprimorando sua utilidade em sistemas automatizados.
Para desenvolvedores que trabalham com aplicações que exigem raciocínio intensivo, o Apidog pode facilitar o teste de API, garantindo que as saídas do modelo estejam alinhadas com os resultados esperados. Este modelo é particularmente adequado para ambientes de pesquisa e cenários complexos de resolução de problemas.
Especificações Técnicas e Arquitetura
Ambos os modelos Qwen3-4B fazem parte da família Qwen3, que inclui arquiteturas densas e de mistura de especialistas (MoE). A designação 4B refere-se aos seus 4 bilhões de parâmetros, estabelecendo um equilíbrio entre eficiência computacional e desempenho. Consequentemente, esses modelos são acessíveis em hardware de nível de consumidor, ao contrário de modelos maiores como o Qwen3-235B-A22B, que exigem recursos substanciais.
Destaques da Arquitetura
- Design de Modelo Denso: Ao contrário dos modelos MoE, os modelos Qwen3-4B usam uma arquitetura densa, garantindo desempenho consistente em todas as tarefas sem a necessidade de ativação seletiva de parâmetros.
- YaRN para Extensão de Contexto: Os modelos aproveitam o YaRN para estender seu comprimento de contexto de 32.768 para 262.144 tokens, permitindo o processamento de contexto longo sem degradação significativa de desempenho.
- Pipeline de Treinamento: A equipe Qwen empregou um processo de treinamento de quatro estágios, incluindo início a frio de cadeia de pensamento longa, aprendizado por reforço baseado em raciocínio, fusão de modo de pensamento e aprendizado por reforço geral. Essa abordagem aprimora as capacidades de raciocínio e diálogo.
- Suporte à Quantização: Ambos os modelos suportam quantização FP8, reduzindo os requisitos de memória enquanto mantêm a precisão. Por exemplo, o Qwen3-4B-Thinking-2507-FP8 está disponível para ambientes com recursos limitados.
Requisitos de Hardware
Para executar esses modelos eficientemente, considere o seguinte:
- Memória da GPU: Um mínimo de 8GB de VRAM é recomendado para modelos quantizados em FP8, enquanto modelos bfloat16 podem exigir 16GB ou mais.
- RAM: Para desempenho ideal, 16GB de memória unificada (VRAM + RAM) é suficiente para a maioria das tarefas.
- Frameworks de Inferência: Ambos os modelos são compatíveis com Hugging Face Transformers (versão ≥4.51.0), vLLM (≥0.8.5) e SGLang (≥0.4.6.post1). Ferramentas locais como Ollama e LMStudio também suportam Qwen3.
Para desenvolvedores que implantam esses modelos, o Apidog simplifica o processo, fornecendo ferramentas para monitorar e testar o desempenho da API, garantindo uma integração eficiente com os frameworks de inferência.
Integração com Hugging Face e ModelScope
Os modelos Qwen3-4B estão disponíveis tanto no Hugging Face quanto no ModelScope, oferecendo flexibilidade para desenvolvedores. Abaixo, fornecemos um trecho de código para demonstrar como usar o Qwen3-4B-Instruct-2507 com Hugging Face Transformers.

from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Write a Python function to calculate Fibonacci numbers."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=16384)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()content = tokenizer.decode(output_ids, skip_special_tokens=True)print("Generated Code:\n", content)Para o Qwen3-4B-Thinking-2507, é necessária análise adicional para lidar com o conteúdo de pensamento:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Solve the equation 2x^2 + 3x - 5 = 0."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:index = len(output_ids) - output_ids[::-1].index(151668) # tokenexcept ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("Thinking Process:\n", thinking_content)print("Solution:\n", content)Esses trechos demonstram a facilidade de integrar modelos Qwen em fluxos de trabalho Python. Para implantações baseadas em API, o Apidog pode ajudar a testar esses endpoints, garantindo um desempenho confiável.
Otimização de Desempenho e Melhores Práticas
Para maximizar o desempenho dos modelos Qwen3-4B, considere as seguintes recomendações:
- Parâmetros de Amostragem: Para o Qwen3-4B-Instruct-2507, use
temperature=0.7,top_p=0.8,top_k=20emin_p=0. Para o Qwen3-4B-Thinking-2507, usetemperature=0.6,top_p=0.95,top_k=20emin_p=0. Evite a decodificação gulosa para evitar a degradação do desempenho. - Gerenciamento do Comprimento do Contexto: Se encontrar problemas de falta de memória, reduza o comprimento do contexto para 32.768 tokens. No entanto, para tarefas de raciocínio, mantenha um comprimento de contexto acima de 131.072 tokens.
- Penalidade de Presença: Defina
presence_penaltyentre 0 e 2 para reduzir repetições, mas evite valores altos para evitar a mistura de idiomas. - Frameworks de Inferência: Use vLLM ou SGLang para inferência de alto rendimento e aproveite o Apidog para monitorar o desempenho da API.
Comparando Qwen3-4B-Instruct-2507 e Qwen3-4B-Thinking-2507
Embora ambos os modelos compartilhem a mesma arquitetura de 4 bilhões de parâmetros, suas filosofias de design diferem:
- Qwen3-4B-Instruct-2507: Prioriza velocidade e eficiência, tornando-o adequado para chatbots, suporte ao cliente e aplicações de propósito geral.
- Qwen3-4B-Thinking-2507: Foca em raciocínio profundo, ideal para pesquisa acadêmica, resolução de problemas complexos e tarefas que exigem processos de cadeia de pensamento.
Os desenvolvedores podem alternar entre os modos usando os prompts /think e /no_think, permitindo flexibilidade com base nos requisitos da tarefa. O Apidog pode auxiliar no teste dessas alternâncias de modo em aplicações orientadas por API.
Suporte da Comunidade e Ecossistema
Os modelos Qwen3-4B se beneficiam de um ecossistema robusto, com suporte do Hugging Face, ModelScope e ferramentas como Ollama, LMStudio e llama.cpp. A natureza de código aberto desses modelos, licenciados sob Apache 2.0, incentiva contribuições da comunidade e ajuste fino. Por exemplo, o Unsloth fornece ferramentas para ajuste fino 2x mais rápido com 70% menos VRAM, tornando esses modelos acessíveis a um público mais amplo.
Conclusão
Os modelos Qwen3-4B-Instruct-2507 e Qwen3-4B-Thinking-2507 marcam um salto significativo na série Qwen da Alibaba Cloud, oferecendo capacidades inigualáveis em seguimento de instruções, raciocínio e processamento de contexto longo. Com um comprimento de contexto de 256K tokens, suporte multilíngue e compatibilidade com ferramentas como o Apidog, esses modelos capacitam os desenvolvedores a construir aplicações inteligentes e escaláveis. Seja para gerar código, resolver equações ou criar chatbots multilíngues, esses modelos entregam um desempenho excepcional. Comece a explorar seu potencial hoje mesmo e use o Apidog para otimizar suas integrações de API para uma experiência de desenvolvimento perfeita.