
Hoje é mais um ótimo dia para a comunidade de IA de código aberto, que, em particular, prospera nesses momentos, desconstruindo, testando e construindo ansiosamente sobre o novo estado da arte. Em julho de 2025, a equipe Qwen da Alibaba desencadeou um desses eventos com o lançamento de sua série Qwen3, uma nova e poderosa família de modelos pronta para redefinir os parâmetros de desempenho. No centro deste lançamento está uma variante fascinante e altamente especializada: Qwen3-235B-A22B-Thinking-2507.
Este modelo não é apenas mais uma atualização incremental; ele representa um passo deliberado e estratégico em direção à criação de sistemas de IA com profundas capacidades de raciocínio. Seu nome por si só é uma declaração de intenções, sinalizando um foco em lógica, planejamento e resolução de problemas em várias etapas. Este artigo oferece um mergulho profundo na arquitetura, propósito e impacto potencial do Qwen3-Thinking, examinando seu lugar dentro do ecossistema Qwen3 mais amplo e o que ele significa para o futuro do desenvolvimento de IA.
Quer uma plataforma integrada e completa para sua Equipe de Desenvolvedores trabalhar com máxima produtividade?
Apidog atende a todas as suas demandas e substitui o Postman por um preço muito mais acessível!
A Família Qwen3: Um Ataque Multifacetado ao Estado da Arte
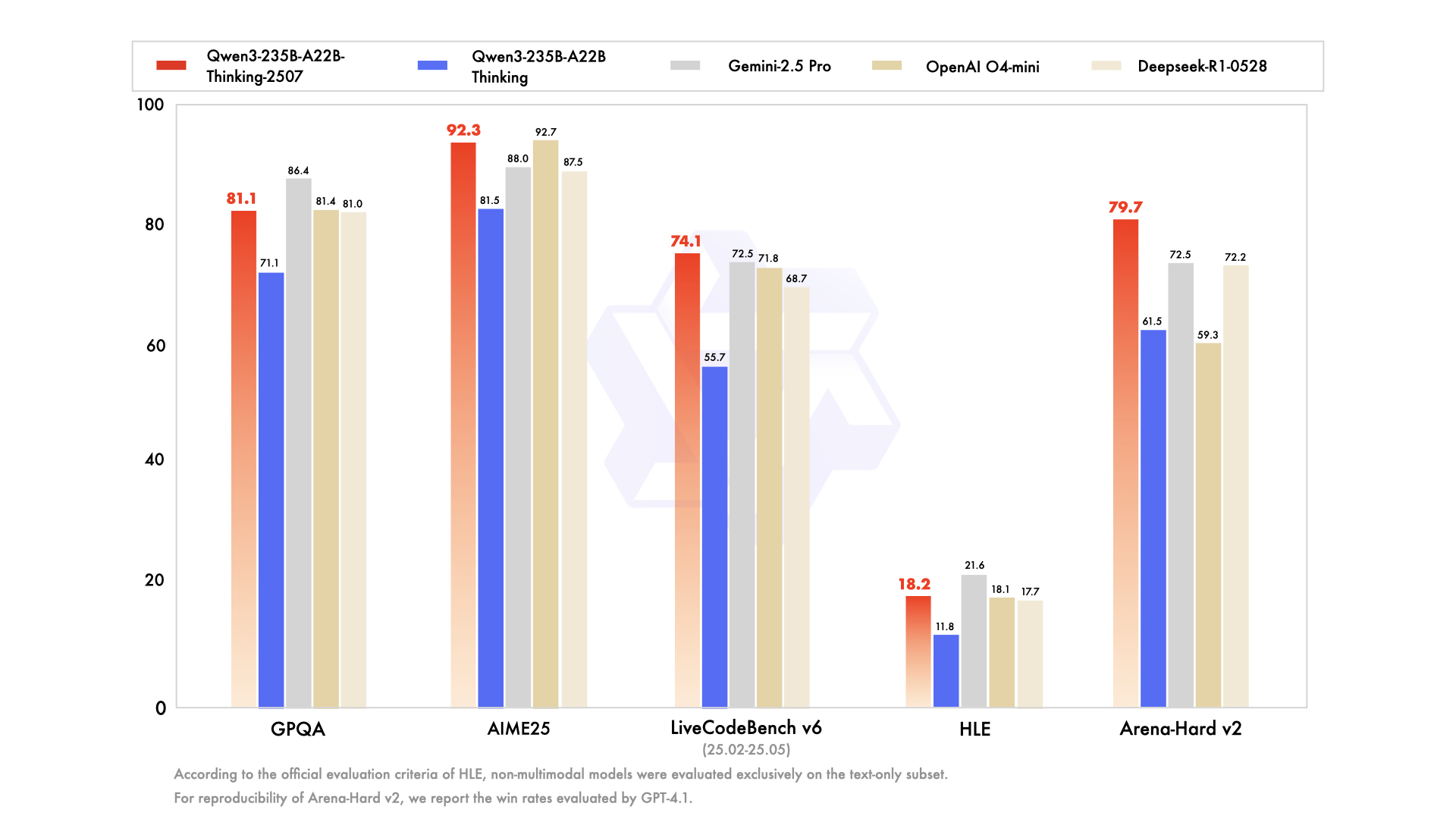
Para entender o modelo Thinking, é preciso primeiro apreciar o contexto de seu nascimento. Ele não chegou isoladamente, mas como parte de uma família de modelos Qwen3 abrangente e estrategicamente diversa. A série Qwen já cultivou um enorme número de seguidores, com um histórico de downloads na casa das centenas de milhões e promovendo uma comunidade vibrante que criou mais de 100.000 modelos derivados em plataformas como o Hugging Face.
A série Qwen3 inclui várias variantes-chave, cada uma adaptada para diferentes domínios:
- Qwen3-Instruct: Um modelo de propósito geral para seguir instruções, projetado para uma ampla gama de aplicações conversacionais e orientadas a tarefas. A variante
Qwen3-235B-A22B-Instruct-2507, por exemplo, é notada por seu alinhamento aprimorado com as preferências do usuário em tarefas abertas e ampla cobertura de conhecimento. - Qwen3-Coder: Uma série de modelos explicitamente projetados para codificação agêntica. O mais poderoso deles, um modelo massivo de 480 bilhões de parâmetros, estabelece um novo padrão para geração de código de código aberto e automação de desenvolvimento de software. Ele até vem com uma ferramenta de linha de comando, Qwen Code, para melhor aproveitar suas habilidades agênticas.
- Qwen3-Thinking: O foco da nossa análise, especializado em tarefas cognitivas complexas que vão além do simples seguimento de instruções ou geração de código.
Essa abordagem familiar demonstra uma estratégia sofisticada: em vez de um único modelo monolítico tentando ser um 'faz-tudo', a Alibaba está fornecendo um conjunto de ferramentas especializadas, permitindo que os desenvolvedores escolham a base certa para suas necessidades específicas.
Vamos Falar Sobre a Parte "Thinking" de Qwen3-235B-A22B-Thinking-2507
O nome do modelo, Qwen3-235B-A22B-Thinking-2507, é denso em informações que revelam sua arquitetura subjacente e filosofia de design. Vamos desconstruí-lo pedaço por pedaço.
Qwen3: Isso significa que o modelo pertence à terceira geração da série Qwen, construindo sobre o conhecimento e os avanços de seus predecessores.235B-A22B(Mistura de Especialistas - MoE): Este é o detalhe arquitetônico mais crucial. O modelo não é uma rede densa de 235 bilhões de parâmetros, onde cada parâmetro é usado para cada cálculo. Em vez disso, ele emprega uma arquitetura de **Mistura de Especialistas (MoE)**.Thinking: Este sufixo denota a especialização do modelo, ajustado com dados que recompensam a dedução lógica e a análise passo a passo.2507: Esta é uma tag de versionamento, provavelmente significando julho de 2025, indicando a data de lançamento ou conclusão do treinamento do modelo.
A arquitetura MoE é a chave para a combinação de poder e eficiência deste modelo. Ela pode ser pensada como uma grande equipe de "especialistas" especializados — redes neurais menores — gerenciada por uma "rede de gating" ou "roteador". Para qualquer token de entrada, o roteador seleciona dinamicamente um pequeno subconjunto dos especialistas mais relevantes para processar a informação.
No caso de Qwen3-235B-A22B, as especificações são:
- Parâmetros Totais (
235B): Isso representa o vasto repositório de conhecimento distribuído por todos os especialistas disponíveis. O modelo contém um total de **128 especialistas distintos**. - Parâmetros Ativos (
A22B): Para qualquer passagem de inferência única, a rede de gating seleciona **8 especialistas** para ativar. O tamanho combinado desses especialistas ativos é de aproximadamente 22 bilhões de parâmetros.
Os benefícios dessa abordagem são imensos. Ela permite que o modelo possua o vasto conhecimento, nuances e capacidades de um modelo de 235B parâmetros, enquanto tem um custo computacional e velocidade de inferência mais próximos de um modelo denso muito menor de 22B parâmetros. Isso torna a implantação e execução de um modelo tão grande mais viável sem sacrificar sua profundidade de conhecimento.
Especificações Técnicas e Perfil de Desempenho
Além da arquitetura de alto nível, as especificações detalhadas do modelo pintam um quadro mais claro de suas capacidades.
- Arquitetura do Modelo: Mistura de Especialistas (MoE)
- Parâmetros Totais: ~235 Bilhões
- Parâmetros Ativos: ~22 Bilhões por token
- Número de Especialistas: 128
- Especialistas Ativados por Token: 8
- Comprimento do Contexto: O modelo suporta uma **janela de contexto de 128.000 tokens**. Esta é uma melhoria massiva que permite processar e raciocinar sobre documentos extremamente longos, bases de código inteiras ou históricos de conversas extensos sem perder o controle de informações cruciais desde o início da entrada.
- Tokenizador: Ele utiliza um tokenizador personalizado de Byte Pair Encoding (BPE) com um vocabulário de mais de 150.000 tokens. Este grande tamanho de vocabulário é indicativo de seu forte treinamento multilíngue, permitindo codificar eficientemente texto de uma ampla gama de idiomas, incluindo inglês, chinês, alemão, espanhol e muitos outros, bem como linguagens de programação.
- Dados de Treinamento: Embora a composição exata do corpus de treinamento seja proprietária, um modelo
Thinkingé certamente treinado em uma mistura especializada de dados projetados para fomentar o raciocínio. Este conjunto de dados iria muito além do texto web padrão e provavelmente incluiria: - Artigos Acadêmicos e Científicos: Grandes volumes de texto de fontes como arXiv, PubMed e outros repositórios de pesquisa para absorver raciocínio científico e matemático complexo.
- Conjuntos de Dados Lógicos e Matemáticos: Conjuntos de dados como GSM8K (Grade School Math) e o conjunto de dados MATH, que contêm problemas de texto que exigem soluções passo a passo.
- Problemas de Programação e Código: Conjuntos de dados como HumanEval e MBPP, que testam o raciocínio lógico através da geração de código.
- Textos Filosóficos e Jurídicos: Documentos que exigem a compreensão de argumentos lógicos densos, abstratos e altamente estruturados.
- Dados de Cadeia de Pensamento (CoT): Exemplos gerados sinteticamente ou curados por humanos onde o modelo é explicitamente mostrado como "pensar passo a passo" para chegar a uma resposta.
Essa mistura de dados curados é o que separa o modelo Thinking de seu irmão Instruct. Ele não é apenas treinado para ser útil; ele é treinado para ser rigoroso.
O Poder do "Thinking": Um Foco na Cognição Complexa
A promessa do modelo Qwen3-Thinking reside em sua capacidade de abordar problemas que historicamente têm sido grandes desafios para grandes modelos de linguagem. São tarefas onde a simples correspondência de padrões ou recuperação de informações é insuficiente. A especialização "Thinking" sugere proficiência em áreas como:
- Raciocínio Multi-Etapas: Resolver problemas que exigem a decomposição de uma consulta em uma sequência de etapas lógicas. Por exemplo, calcular as implicações financeiras de uma decisão de negócios com base em múltiplas variáveis de mercado ou planejar a trajetória de um projétil dadas um conjunto de restrições físicas.
- Dedução Lógica: Analisar um conjunto de premissas e tirar uma conclusão válida. Isso pode envolver resolver um quebra-cabeça de grade lógica, identificar falácias lógicas em um texto ou determinar as consequências de um conjunto de regras em um contexto legal ou contratual.
- Planejamento Estratégico: Elaborar uma sequência de ações para atingir um objetivo. Isso tem aplicações em jogos complexos (como xadrez ou Go), simulações de estratégia de negócios, otimização da cadeia de suprimentos e gerenciamento automatizado de projetos.
- Inferência Causal: Tentativa de identificar relações de causa e efeito dentro de um sistema complexo descrito em texto, um pilar do raciocínio científico e analítico com o qual os modelos frequentemente lutam.
- Raciocínio Abstrato: Compreender e manipular conceitos abstratos e analogias. Isso é essencial para a resolução criativa de problemas e a verdadeira inteligência em nível humano, indo além dos fatos concretos para as relações entre eles.
O modelo é projetado para se destacar em benchmarks que medem especificamente essas habilidades cognitivas avançadas, como MMLU (Massive Multitask Language Understanding) para conhecimento geral e resolução de problemas, e os já mencionados GSM8K e MATH para raciocínio matemático.
Acessibilidade, Quantização e Engajamento da Comunidade
O poder de um modelo só é significativo se puder ser acessado e utilizado. Mantendo seu compromisso de código aberto, a Alibaba disponibilizou amplamente a família Qwen3, incluindo a variante Thinking, em plataformas como Hugging Face e ModelScope.
Reconhecendo os significativos recursos computacionais necessários para executar um modelo dessa escala, versões quantizadas também estão disponíveis. O modelo **Qwen3-235B-A22B-Thinking-2507-FP8** é um excelente exemplo. FP8 (ponto flutuante de 8 bits) é uma técnica de quantização de ponta que reduz drasticamente a pegada de memória do modelo e aumenta a velocidade de inferência.
Vamos detalhar o impacto:
- Um modelo de 235B parâmetros em precisão padrão de 16 bits (BF16/FP16) exigiria mais de **470 GB de VRAM**, uma quantidade proibitiva para todos, exceto os maiores clusters de servidores de nível empresarial.
- A **versão quantizada FP8**, no entanto, reduz esse requisito para menos de **250 GB**. Embora ainda substancial, isso coloca o modelo no campo das possibilidades para instituições de pesquisa, startups e até mesmo indivíduos com estações de trabalho multi-GPU equipadas com hardware de consumo ou prosumer de ponta.
Isso torna o raciocínio avançado acessível a um público muito mais amplo. Para usuários corporativos que preferem serviços gerenciados, os modelos também estão sendo integrados às plataformas de nuvem da Alibaba. O acesso à API via Model Studio e a integração no assistente de IA carro-chefe da Alibaba, Quark, garantem que a tecnologia possa ser aproveitada em qualquer escala.
Conclusão: Uma Nova Ferramenta para uma Nova Classe de Problemas
O lançamento do Qwen3-235B-A22B-Thinking-2507 é mais do que apenas outro ponto no gráfico sempre crescente do desempenho de modelos de IA. É uma declaração sobre a direção futura do desenvolvimento da IA: uma mudança de modelos monolíticos de propósito geral para um ecossistema diverso de ferramentas poderosas e especializadas. Ao empregar uma arquitetura eficiente de Mistura de Especialistas, a Alibaba entregou um modelo com o vasto conhecimento de uma rede de 235 bilhões de parâmetros e a relativa facilidade computacional de um modelo de 22 bilhões de parâmetros.
Ao ajustar explicitamente este modelo para "Thinking", a equipe Qwen oferece ao mundo uma ferramenta dedicada a resolver os mais difíceis desafios analíticos e de raciocínio. Ele tem o potencial de acelerar a descoberta científica, ajudando pesquisadores a analisar dados complexos, capacitar empresas a tomar melhores decisões estratégicas e servir como uma camada fundamental para uma nova geração de aplicações inteligentes que podem planejar, deduzir e raciocinar com sofisticação sem precedentes. À medida que a comunidade de código aberto começa a explorar suas profundezas, o Qwen3-Thinking está pronto para se tornar um bloco de construção crítico na busca contínua por uma IA mais capaz e verdadeiramente inteligente.
Quer uma plataforma integrada e completa para sua Equipe de Desenvolvedores trabalhar com máxima produtividade?
Apidog atende a todas as suas demandas e substitui o Postman por um preço muito mais acessível!