
Qwen-Image, um modelo de fundação de imagem MMDiT de 20B de ponta da equipe Qwen da Alibaba Cloud, redefine as possibilidades da criação visual impulsionada por IA. Lançado em 4 de agosto de 2025, este modelo oferece capacidades incomparáveis na geração de imagens de alta qualidade, renderização de texto multilíngue complexo e realização de edições precisas de imagem. Quer você esteja criando visuais de marketing dinâmicos ou analisando dados de imagem complexos, o Qwen-Image capacita os desenvolvedores com ferramentas robustas para dar vida às ideias.
O Que É Qwen-Image? Uma Visão Geral Técnica
Qwen-Image, parte da série Qwen da Alibaba Cloud, é um modelo de transformador de difusão multimodal (MMDiT) com 20 bilhões de parâmetros, projetado tanto para geração quanto para edição de imagens. Diferente dos modelos tradicionais que se concentram apenas na geração de visuais, o Qwen-Image integra renderização avançada de texto e compreensão de imagem, tornando-o uma ferramenta versátil para tarefas criativas e analíticas. O modelo, de código aberto sob a licença Apache 2.0, é acessível via plataformas como GitHub, Hugging Face e ModelScope, permitindo que os desenvolvedores o integrem em diversos fluxos de trabalho.

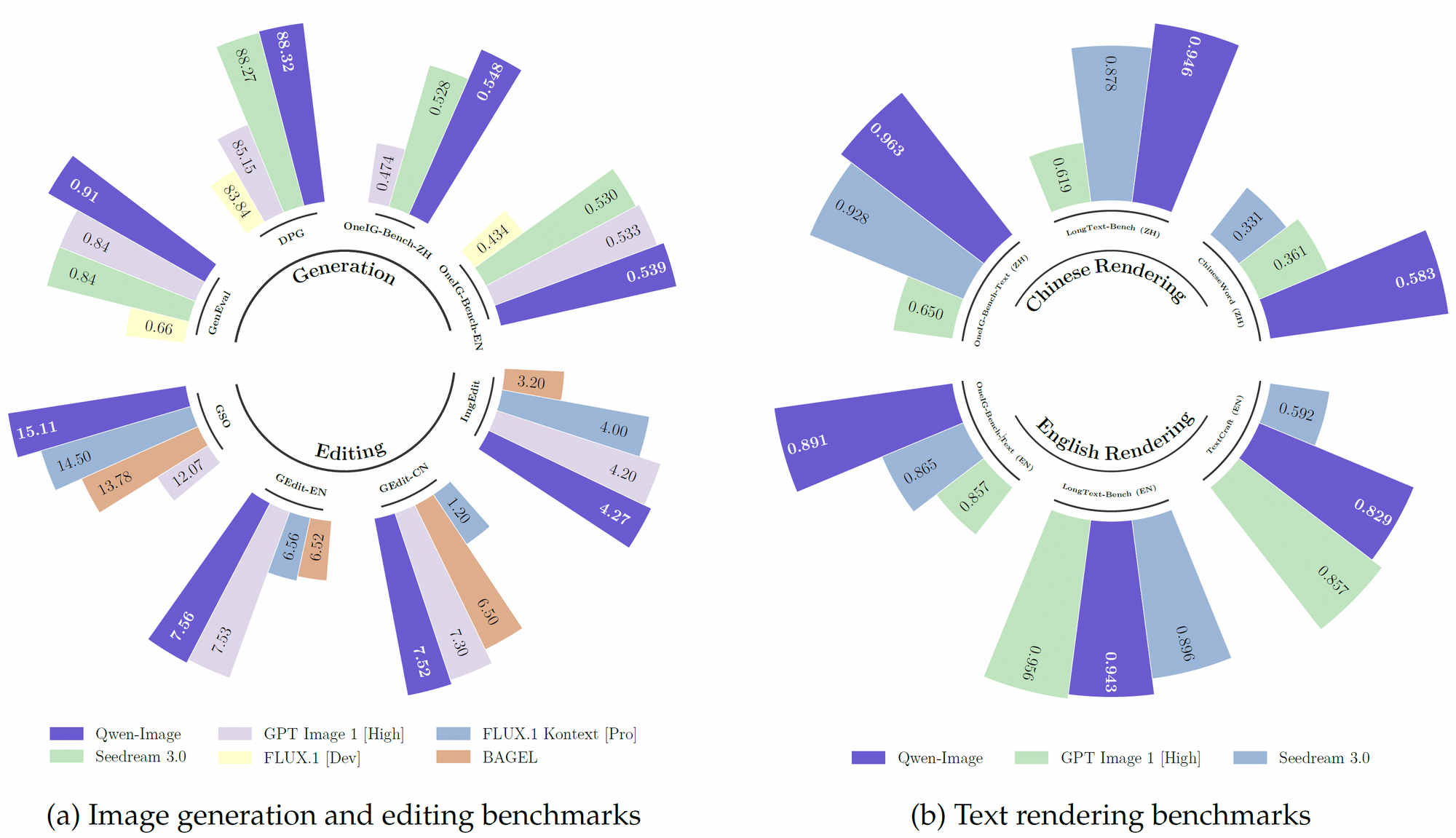
Além disso, o Qwen-Image utiliza um robusto conjunto de dados de pré-treinamento, incorporando mais de 30 trilhões de tokens em 119 idiomas, com foco em chinês e inglês. Este extenso conjunto de dados, combinado com técnicas de aprendizado por reforço, permite que o modelo lide com tarefas complexas como renderização de texto multilíngue e manipulação precisa de objetos. Consequentemente, ele supera muitos modelos existentes em benchmarks como GenEval, DPG e LongText-Bench.
Principais Recursos do Qwen-Image
Renderização Superior de Texto para Visuais Multilíngues
O Qwen-Image se destaca na renderização de texto complexo dentro de imagens, um recurso que o diferencia dos concorrentes. Ele suporta tanto idiomas alfabéticos (por exemplo, inglês) quanto escritas logográficas (por exemplo, chinês), garantindo integração de texto de alta fidelidade. Por exemplo, o modelo pode gerar um pôster de filme com layouts de texto precisos, como um título como "Imagination Unleashed" e legendas em várias linhas, mantendo a coerência tipográfica. Essa capacidade deriva de seu treinamento em diversos conjuntos de dados, incluindo LongText-Bench e ChineseWord, onde alcança desempenho de ponta.
Além disso, o Qwen-Image lida com layouts de várias linhas e semântica em nível de parágrafo com notável precisão. Em um cenário de teste, ele renderizou com precisão um poema manuscrito em papel amarelado dentro de uma imagem, apesar de o texto ocupar menos de um décimo do espaço visual. Essa precisão o torna ideal para aplicações como sinalização digital, design de pôsteres e visualização de documentos.
Capacidades Avançadas de Edição de Imagem
Além da renderização de texto, o Qwen-Image oferece recursos sofisticados de edição de imagem. Ele suporta operações como transferência de estilo, inserção de objetos, aprimoramento de detalhes e manipulação de pose humana. Por exemplo, os usuários podem instruir o modelo a "adicionar um céu ensolarado a esta imagem" ou "mudar esta pintura para um estilo Van Gogh", e o Qwen-Image entrega resultados coerentes. Seu paradigma aprimorado de treinamento multi-tarefa garante que as edições preservem o significado semântico e o realismo visual.
Além disso, a capacidade do modelo de editar texto dentro de imagens é particularmente notável. Os desenvolvedores podem modificar texto em placas ou pôsteres sem perturbar o contexto visual circundante, um recurso valioso para publicidade e criação de conteúdo. Essas capacidades são suportadas pela profunda compreensão visual do Qwen-Image, que lhe permite interpretar e manipular elementos de imagem com precisão.
Compreensão Visual Abrangente
O Qwen-Image não apenas cria ou edita — ele entende. O modelo suporta um conjunto de tarefas de compreensão de imagem, incluindo detecção de objetos, segmentação semântica, estimativa de profundidade, detecção de bordas (Canny), síntese de novas visualizações e super-resolução. Essas tarefas são impulsionadas por sua capacidade de processar entradas de alta resolução e extrair detalhes finos. Por exemplo, o Qwen-Image pode gerar caixas delimitadoras para objetos descritos em linguagem natural, como "detectar o cão Husky na cena do metrô", tornando-o uma ferramenta poderosa para análise visual.
Além disso, seu suporte a múltiplos idiomas aumenta sua usabilidade em aplicações globais. Ao integrar-se com ferramentas como o Qwen-Plus Prompt Enhancement Tool, os desenvolvedores podem otimizar prompts para um melhor desempenho multilíngue, garantindo resultados precisos em diversos contextos linguísticos.
Excelência de Desempenho em Diversos Benchmarks
O Qwen-Image supera consistentemente os concorrentes em múltiplos benchmarks públicos, incluindo GenEval, DPG, OneIG-Bench, GEdit, ImgEdit e GSO. Seu desempenho superior na renderização de texto, particularmente para chinês, é evidente em benchmarks como o TextCraft, onde ele supera os modelos de ponta existentes. Além disso, suas capacidades gerais de geração de imagem suportam uma ampla gama de estilos artísticos, de cenas fotorrealistas a estéticas de anime, tornando-o uma escolha versátil para profissionais criativos.
Arquitetura Técnica do Qwen-Image
Transformador de Difusão Multimodal (MMDiT)
Em sua essência, o Qwen-Image emprega uma arquitetura de Transformador de Difusão Multimodal (MMDiT), que combina os pontos fortes dos modelos de difusão e dos transformadores. Essa abordagem híbrida permite que o modelo processe entradas visuais e textuais de forma eficiente. O processo de difusão refina iterativamente entradas ruidosas em imagens coerentes, enquanto o componente transformador lida com relações complexas entre texto e elementos visuais.
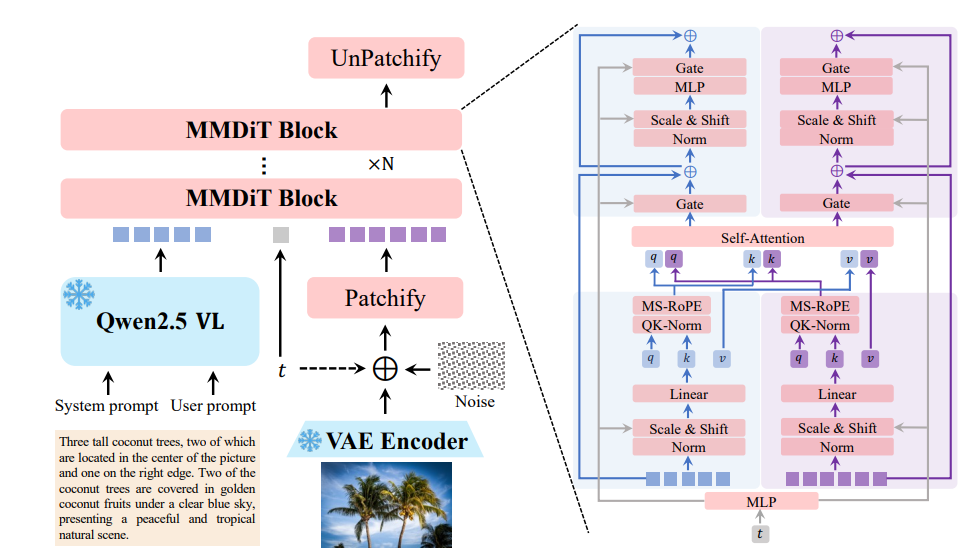
Os 20 bilhões de parâmetros do modelo são otimizados para eficiência, permitindo que ele seja executado em hardware de consumo com apenas 4GB de VRAM ao usar técnicas como quantização FP8 e descarregamento camada por camada. Essa acessibilidade torna o Qwen-Image adequado tanto para desenvolvedores empresariais quanto individuais.
Pré-treinamento e Ajuste Fino
O conjunto de dados de pré-treinamento do Qwen-Image é a pedra angular de seu desempenho. Abrangendo mais de 30 trilhões de tokens, o conjunto de dados inclui dados da web, documentos semelhantes a PDF e dados sintéticos gerados por modelos como Qwen2.5-VL e Qwen2.5-Coder. O processo de pré-treinamento ocorre em três estágios:

- Estágio 1 (S1): O modelo é pré-treinado em 30 trilhões de tokens com um comprimento de contexto de 4K tokens, estabelecendo habilidades fundamentais de linguagem e visuais.
- Estágio 2: O aprendizado por reforço aprimora as capacidades de raciocínio e específicas da tarefa do modelo.
- Estágio 3: O ajuste fino com conjuntos de dados curados melhora o alinhamento com as preferências do usuário e tarefas específicas como renderização de texto e edição de imagem.
Essa abordagem de múltiplos estágios garante que o Qwen-Image seja robusto e adaptável, capaz de lidar com diversas tarefas com alta precisão.
Integração com Ferramentas de Desenvolvimento
O Qwen-Image se integra perfeitamente com frameworks de desenvolvimento populares como Diffusers e DiffSynth-Studio. Por exemplo, os desenvolvedores podem usar o seguinte código Python para gerar imagens com o Qwen-Image:
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "A coffee shop entrance with a chalkboard sign reading 'Qwen Coffee 😊 $2 per cup.'"
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
Este trecho de código demonstra como os desenvolvedores podem aproveitar as capacidades do Qwen-Image para gerar visuais de alta qualidade com configuração mínima. Ferramentas como o Apidog simplificam ainda mais a integração de API, permitindo prototipagem e implantação rápidas.
Aplicações Práticas do Qwen-Image
Geração de Conteúdo Criativo
A capacidade do Qwen-Image de gerar cenas fotorrealistas, pinturas impressionistas e visuais no estilo anime o torna uma ferramenta poderosa para artistas e designers. Por exemplo, um designer gráfico pode criar um pôster de filme com layouts de texto dinâmicos e imagens vibrantes, como demonstrado em um caso de teste onde o Qwen-Image produziu um pôster para "Imagination Unleashed" com um computador futurista emitindo criaturas caprichosas.

Publicidade e Marketing
Em publicidade, as capacidades de renderização e edição de texto do Qwen-Image permitem a criação de campanhas visualmente atraentes. Profissionais de marketing podem gerar pôsteres com posicionamento preciso de texto ou editar visuais existentes para atualizar mensagens promocionais, garantindo consistência da marca e coerência visual.

Análise Visual e Automação
Para indústrias como e-commerce e sistemas autônomos, as tarefas de compreensão de imagem do Qwen-Image — como detecção de objetos e segmentação semântica — oferecem valor significativo. Plataformas de varejo podem usar o modelo para marcar automaticamente produtos em imagens, enquanto veículos autônomos podem aproveitar sua estimativa de profundidade para navegação.
Ferramentas Educacionais
A capacidade do Qwen-Image de gerar visuais educacionais, como diagramas com anotações de texto precisas, suporta plataformas de e-learning. Por exemplo, ele pode criar uma ilustração detalhada de um conceito científico com componentes rotulados, aumentando o engajamento e a compreensão dos alunos.

Comparando Qwen-Image com Concorrentes
Quando comparado a modelos como DALL-E 3 e Stable Diffusion, o Qwen-Image se destaca por sua renderização de texto multilíngue e capacidades avançadas de edição. Enquanto o DALL-E 3 se sobressai na geração criativa de imagens, ele tem dificuldades com layouts de texto complexos, particularmente para escritas logográficas. O Stable Diffusion, embora versátil, carece da profunda compreensão visual oferecida pelo conjunto de tarefas de entendimento do Qwen-Image.
Além disso, a natureza de código aberto do Qwen-Image e sua compatibilidade com hardware de baixa memória lhe dão uma vantagem para desenvolvedores com recursos limitados. Seu desempenho em benchmarks como TextCraft e GEdit solidifica ainda mais sua posição como um modelo líder em IA multimodal.
Desafios e Limitações
Apesar de seus pontos fortes, o Qwen-Image enfrenta desafios. A dependência do modelo em grandes conjuntos de dados levanta preocupações sobre privacidade de dados e fornecimento ético, embora a Alibaba Cloud siga diretrizes rigorosas. Além disso, embora o modelo suporte mais de 100 idiomas, seu desempenho pode variar para dialetos menos representados, exigindo ajuste fino adicional.
Além disso, as demandas computacionais do modelo de 20 bilhões de parâmetros podem ser significativas sem técnicas de otimização como a quantização FP8. Os desenvolvedores devem equilibrar desempenho e restrições de recursos ao implantar o Qwen-Image em ambientes de produção.
Perspectivas Futuras para o Qwen-Image
Olhando para o futuro, o Qwen-Image está pronto para evoluir ainda mais. A equipe Qwen planeja lançar uma versão do modelo específica para edição, aprimorando suas capacidades para aplicações de nível profissional. A integração com frameworks emergentes como vLLM e o suporte contínuo para LoRA e fluxos de trabalho de ajuste fino expandirão sua acessibilidade.
Além disso, avanços no aprendizado por reforço, como visto em modelos como o Qwen3, sugerem que o Qwen-Image poderia incorporar capacidades de raciocínio mais profundas, permitindo tarefas de raciocínio visual mais complexas. À medida que a comunidade de IA continua a contribuir para o seu desenvolvimento, o Qwen-Image tem o potencial de redefinir a criação e a compreensão visual.
Começando com o Qwen-Image
Para começar a usar o Qwen-Image, os desenvolvedores podem acessar os pesos do modelo no GitHub ou no Hugging Face. O blog oficial em qwenlm.github.io fornece instruções detalhadas de configuração e casos de uso. Para uma experiência prática, visite o Qwen Chat e selecione "Geração de Imagem" para testar as capacidades do modelo.
Para integração de API, ferramentas como o Apidog simplificam o processo, oferecendo uma interface amigável para testar e implantar os recursos do Qwen-Image. Baixe o Apidog gratuitamente para otimizar seu fluxo de trabalho de desenvolvimento.
Conclusão: Por Que o Qwen-Image Importa
O Qwen-Image representa um avanço significativo na IA multimodal, combinando renderização avançada de texto, edição precisa de imagem e compreensão visual robusta. Sua disponibilidade de código aberto, extenso pré-treinamento e compatibilidade com ferramentas de desenvolvimento o tornam uma escolha versátil para criadores, desenvolvedores e pesquisadores. Ao abordar desafios como suporte multilíngue e eficiência de recursos, o Qwen-Image estabelece um novo padrão para a criação visual impulsionada por IA.
À medida que a IA continua a evoluir, modelos como o Qwen-Image desempenharão um papel fundamental na ponte entre linguagem e imagens, abrindo novas possibilidades para aplicações criativas e analíticas. Quer você esteja construindo uma campanha de marketing, analisando dados visuais ou criando conteúdo educacional, o Qwen-Image oferece as ferramentas para dar vida à sua visão.