
O processamento de áudio ganhou rapidamente importância na inteligência artificial, impulsionando aplicativos como assistentes virtuais, ferramentas de transcrição e interfaces controladas por voz. A OpenAI, pioneira em inovação em IA, recentemente revelou seus modelos de áudio de próxima geração, estabelecendo um novo padrão para as capacidades de conversão de fala em texto e de texto em fala. Esses modelos, nomeadamente gpt-4o-transcribe, gpt-4o-mini-transcribe e gpt-4o-mini-tts, oferecem desempenho excepcional, permitindo que os desenvolvedores criem soluções baseadas em voz mais precisas e responsivas. Neste post do blog, vamos explorar como você pode acessar esses modelos através da API da OpenAI, oferecendo um roteiro técnico detalhado para ajudá-lo a começar.
Vamos prosseguir explorando o que esses novos modelos oferecem.
Quais São os Novos Modelos de Áudio da OpenAI?
Os últimos modelos de áudio da OpenAI enfrentam desafios do mundo real no processamento de áudio, como ambientes barulhentos e padrões de fala diversos. Para usar efetivamente a API, primeiro você precisa entender as capacidades de cada modelo.

Aqui está uma análise.
gpt-4o-transcribe: Conversão de Fala em Texto com Precisão
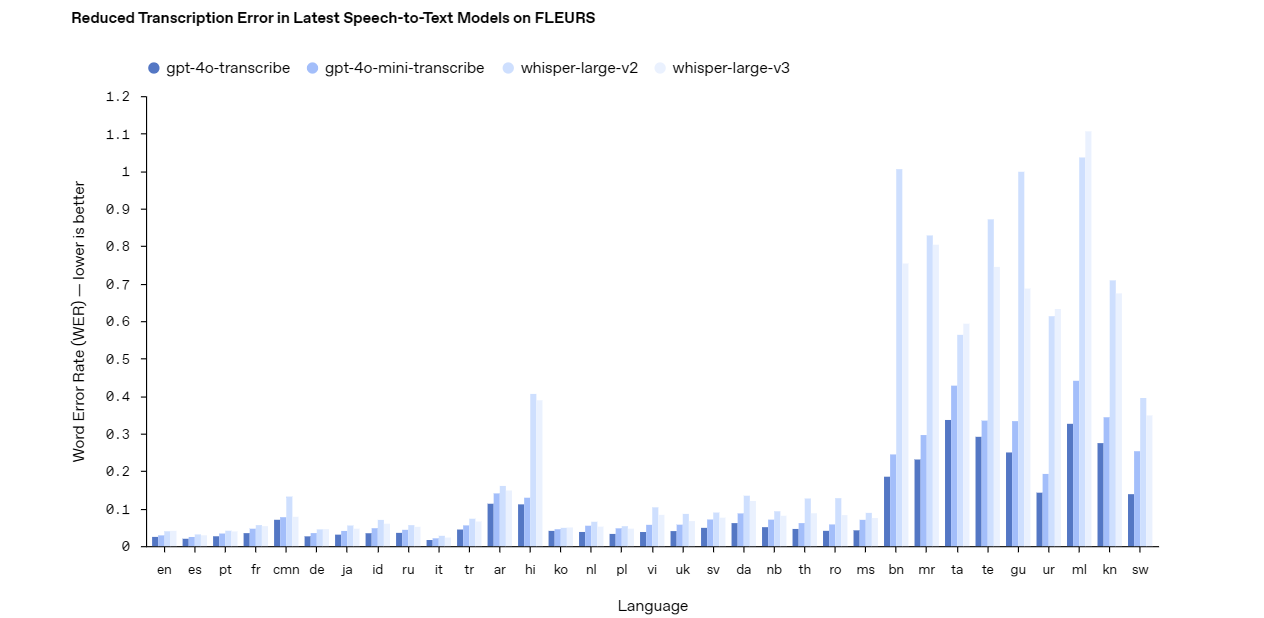
O modelo gpt-4o-transcribe se destaca como uma solução robusta de conversão de fala em texto. Ele oferece alta precisão, mesmo em condições difíceis, como ruído de fundo ou fala rápida. Os desenvolvedores podem contar com este modelo para aplicativos que exigem transcrições precisas, como legendagem ao vivo, sistemas de comando de voz ou ferramentas de análise de áudio. Seu design avançado o torna uma escolha de topo para projetos complexos e de alto risco.
gpt-4o-mini-transcribe: Transcrição Leve
Em contraste, o modelo gpt-4o-mini-transcribe oferece uma alternativa mais leve e eficiente. Embora sacrifique um pouco de precisão em comparação com gpt-4o-transcribe, ele consome menos recursos, tornando-o ideal para tarefas mais simples. Use este modelo para aplicativos como gravações de voz casuais ou reconhecimento básico de comandos, onde a velocidade e a eficiência superam a necessidade de precisão perfeita.

gpt-4o-mini-tts: Texto para Fala Personalizável
Mudando para texto para fala, o modelo gpt-4o-mini-tts brilha com sua saída com som natural. Ao contrário dos sistemas tradicionais de texto para fala, este modelo permite a personalização de tom, estilo e emoção por meio de instruções. Essa flexibilidade se adapta a projetos como agentes de voz personalizados, narração de audiolivros ou bots de atendimento ao cliente que precisam de uma experiência de voz adaptada.
Com esses modelos em mente, vamos passar para entender a estrutura de preços antes de acessá-los através da API.
Preços para a API dos Modelos de Áudio da OpenAI
Antes de integrar os modelos de áudio da OpenAI em seus projetos, é crucial entender os custos associados. A OpenAI oferece um modelo de preços baseado em uso para suas APIs de áudio, que varia dependendo do modelo específico e do volume de uso. Abaixo, delineamos os principais detalhes de preços para gpt-4o-transcribe, gpt-4o-mini-transcribe e gpt-4o-mini-tts.
Modelos de Fala para Texto: gpt-4o-transcribe e gpt-4o-mini-transcribe
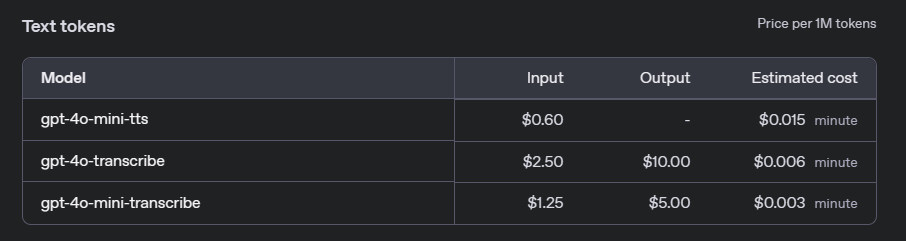
Para serviços de fala para texto, a OpenAI cobra com base na duração do áudio processado. As taxas diferem entre o modelo completo gpt-4o-transcribe e o leve gpt-4o-mini-transcribe:
- gpt-4o-transcribe: $0.006 por minuto de áudio.
- gpt-4o-mini-transcribe: $0.003 por minuto de áudio.
Essas taxas fazem do gpt-4o-mini-transcribe uma opção econômica para aplicativos onde extrema precisão não é crítica, enquanto gpt-4o-transcribe é mais adequado para tarefas de alta precisão.
Modelo Texto para Fala: gpt-4o-mini-tts
Para texto para fala, os preços são baseados no número de caracteres no texto de entrada:
- gpt-4o-mini-tts: $0.015 por caractere.
Esse modelo de precificação permite flexibilidade, especialmente para aplicativos que geram comprimentos variados de saída de áudio, como respostas interativas por voz ou geração de audiolivros.
Camada Gratuita e Limites de Uso
A OpenAI oferece uma camada gratuita para desenvolvedores experimentarem os modelos de áudio antes de se comprometerem com o uso pago. Novos usuários recebem $5 em créditos gratuitos, que podem ser aplicados a quaisquer serviços de API, incluindo os modelos de áudio. Além disso, o uso está sujeito a limites de taxa para garantir acesso justo. Por exemplo, a API de fala para texto tem um limite de 100 solicitações por minuto, enquanto a API de texto para fala permite até 50 solicitações por minuto.
Compreender esses custos ajudará você a orçar efetivamente enquanto integra os modelos de áudio em seus aplicativos. Agora, vamos passar para o acesso a esses modelos via API.
Como Acessar a API dos Modelos de Áudio da OpenAI: Passo a Passo
Acessar a API da OpenAI requer uma abordagem estruturada. Siga estas etapas para integrar os modelos de áudio em seus projetos.
Etapa 1: Garanta uma Chave de API
Primeiro, obtenha uma chave API da OpenAI. Visite a plataforma da OpenAI, crie uma conta se ainda não tiver e gere uma chave no painel do desenvolvedor. Armazene essa chave com segurança—é sua porta de entrada para a API e deve permanecer confidencial.

Etapa 2: Instale a Biblioteca OpenAI Python
Em seguida, instale a biblioteca OpenAI Python para simplificar as interações com a API. Abra seu terminal e execute este comando:
pip install openai
Essa biblioteca fornece uma interface limpa para enviar solicitações, economizando-o de chamadas de HTTP manuais.
Etapa 3: Autentique Sua Chave de API
Antes de enviar solicitações, autentique seu script com a chave API. Adicione este código ao seu arquivo Python:
import openai
openai.api_key = 'sua-chave-api-aqui'
Substitua 'sua-chave-api-aqui' pela sua chave real. Esta etapa garante que suas solicitações sejam autorizadas.
Etapa 4: Envie Solicitações para os Modelos de Áudio
Agora, vamos fazer solicitações para os modelos de áudio. Cada modelo usa endpoints e parâmetros específicos. Abaixo estão exemplos para conversão de fala em texto e texto em fala.
Fala para Texto com gpt-4o-transcribe
Para transcrever áudio usando gpt-4o-transcribe, envie um arquivo de áudio para a API. Aqui está um exemplo de script:
with open('audio_file.wav', 'rb') as audio_file:
response = openai.Audio.transcribe(
model="gpt-4o-transcribe",
file=audio_file
)
print(response['text'])
Esse código abre um arquivo de áudio (por exemplo, audio_file.wav) e imprime o texto transcrito. Certifique-se de que seu arquivo esteja em um formato compatível, como WAV ou MP3.
Texto para Fala com gpt-4o-mini-tts
Para texto para fala com gpt-4o-mini-tts, forneça texto e instruções opcionais de voz. Tente este exemplo:
response = openai.Audio.synthesize(
model="gpt-4o-mini-tts",
text="Bem-vindo ao nosso serviço! Como posso ajudá-lo?",
voice_instructions="Use um tom caloroso e profissional."
)
with open('output_audio.wav', 'wb') as audio_file:
audio_file.write(response['audio'])
Isso gera um arquivo de áudio (output_audio.wav) com uma voz personalizada. Experimente com voice_instructions para ajustar a saída.
Com essas etapas concluídas, você está pronto para integrar os modelos em aplicativos do mundo real.
Aplicações Práticas dos Modelos de Áudio da OpenAI
Os modelos de áudio da OpenAI desbloqueiam inúmeras possibilidades. Aqui estão alguns exemplos para inspirar.
Assistentes de Voz
Construa um assistente de voz que ouça e responda de forma natural. Combine gpt-4o-transcribe para reconhecimento de comandos e gpt-4o-mini-tts para respostas faladas, criando uma experiência do usuário excepcional.
Serviços de Transcrição
Desenvolva uma ferramenta de transcrição para reuniões ou palestras. Use gpt-4o-transcribe para converter áudio em texto com alta precisão e, em seguida, ofereça transcrições para download aos usuários.
Soluções de Acessibilidade
Aumente a acessibilidade convertendo texto em fala para usuários com deficiência visual. A personalização do modelo gpt-4o-mini-tts garante uma experiência de leitura envolvente e semelhante à humana.
Automação do Atendimento ao Cliente
Crie um agente de suporte movido por IA. Combine gpt-4o-transcribe para entender perguntas com gpt-4o-mini-tts para responder em uma voz de marca, melhorando a satisfação do cliente.
Esses exemplos destacam a versatilidade da API. Agora, vamos discutir as melhores práticas para otimizar sua implementação.
Melhores Práticas para Usar a API dos Modelos de Áudio da OpenAI
Para maximizar o desempenho, siga estas diretrizes.
Otimize a Qualidade do Áudio
Use sempre entradas de áudio de alta qualidade. Reduza o ruído de fundo e escolha um microfone claro para melhorar a precisão da transcrição com gpt-4o-transcribe ou gpt-4o-mini-transcribe.
Selecione o Modelo Correto
Combine o modelo com suas necessidades. Para precisão crítica, escolha gpt-4o-transcribe. Para tarefas leves, gpt-4o-mini-transcribe é suficiente. Avalie as restrições de recursos antes de decidir.
Aproveite a Personalização
Com gpt-4o-mini-tts, experimente com instruções de voz. Ajuste a saída para seu aplicativo—seja um cumprimento alegre ou uma narração tranquila.
Teste Exaustivamente
Teste sua integração com amostras de áudio diversas. Verifique se gpt-4o-transcribe lida com sotaques e ruídos, e assegure que gpt-4o-mini-tts ofereça qualidade de voz consistente.
Por que Usar o Apidog para Teste de API?
Falando em ferramentas, o Apidog merece uma atenção especial. Esta plataforma simplifica o desenvolvimento de API, oferecendo recursos como simulação de solicitações, validação de respostas e monitoramento de desempenho. Ao trabalhar com a API da OpenAI, o Apidog permite que você teste endpoints como gpt-4o-transcribe sem escrever código extenso. Sua interface intuitiva economiza tempo, permitindo que você se concentre em construir em vez de depurar.

Conclusão
Os novos modelos de áudio da OpenAI—gpt-4o-transcribe, gpt-4o-mini-transcribe e gpt-4o-mini-tts—marcam um avanço na tecnologia de processamento de áudio. Este guia mostrou como acessá-los via API, desde a obtenção de uma chave até a codificação de exemplos práticos. Seja para aumentar a acessibilidade ou automatizar o suporte, esses modelos oferecem soluções poderosas.
Para tornar sua jornada mais suave, use Apidog. Baixe o Apidog gratuitamente e simplifique seus testes de API, garantindo que suas integrações funcionem perfeitamente. Comece a experimentar com os modelos de áudio da OpenAI hoje e desbloqueie todo o seu potencial.
