
Executar modelos de linguagem grandes (LLMs) localmente costumava ser o domínio de usuários hardcore de CLI e entusiastas de sistemas. Mas isso está mudando rapidamente. O Ollama, conhecido por sua interface de linha de comando simples para executar LLMs de código aberto em máquinas locais, acaba de lançar aplicativos de desktop nativos para macOS e Windows.
E eles não são apenas wrappers básicos. Esses aplicativos trazem recursos poderosos que tornam a conversação com modelos, a análise de documentos, a escrita de documentação e até mesmo o trabalho com imagens drasticamente mais fáceis para os desenvolvedores.
Neste artigo, exploraremos como a nova experiência de desktop melhora o fluxo de trabalho do desenvolvedor, quais recursos se destacam e onde essas ferramentas realmente brilham na vida de codificação diária.
Por que os LLMs Locais Ainda Importam
Embora ferramentas baseadas em nuvem como ChatGPT, Claude e Gemini dominem as manchetes, há um movimento crescente em direção ao desenvolvimento de IA local-first. Os desenvolvedores querem ferramentas que sejam:
- Privado - Seu código e documentos permanecem em sua máquina.
- Customizável - Você escolhe os modelos, limites de memória e hardware.
- Amigável para uso offline - Sem dependência de APIs externas ou tempo de atividade.
- Rápido - Sem latência de rede ou gargalos de servidor.
O Ollama se encaixa diretamente nessa tendência, permitindo que você execute modelos como LLaMA, Mistral, Gemma, Codellama, Mixtral e outros nativamente em sua máquina - agora com uma experiência muito mais fluida.
Passo 1: Baixe o Ollama para Desktop
Vá para ollama.com e baixe a versão mais recente para o seu sistema:
- macOS (Apple Silicon ou Intel)
- Windows 10/11 (x64)
Instale-o como um aplicativo de desktop comum. Nenhuma configuração de linha de comando é necessária para começar.
Passo 2: Inicie e Escolha um Modelo
Uma vez instalado, abra o aplicativo de desktop Ollama. A interface é limpa e se parece com uma janela de chat simples.
Você será solicitado a escolher um modelo para baixar e executar. Algumas opções incluem:
llama3– assistente de propósito geralcodellama– ótimo para geração e refatoração de códigomistral– rápido, pequeno e precisogemma– modelo de código aberto, apoiado pelo Google
Escolha um e o aplicativo fará o download e o carregará automaticamente.
Uma Integração Mais Suave para Desenvolvedores - Uma Maneira Mais Fácil de Conversar com Modelos
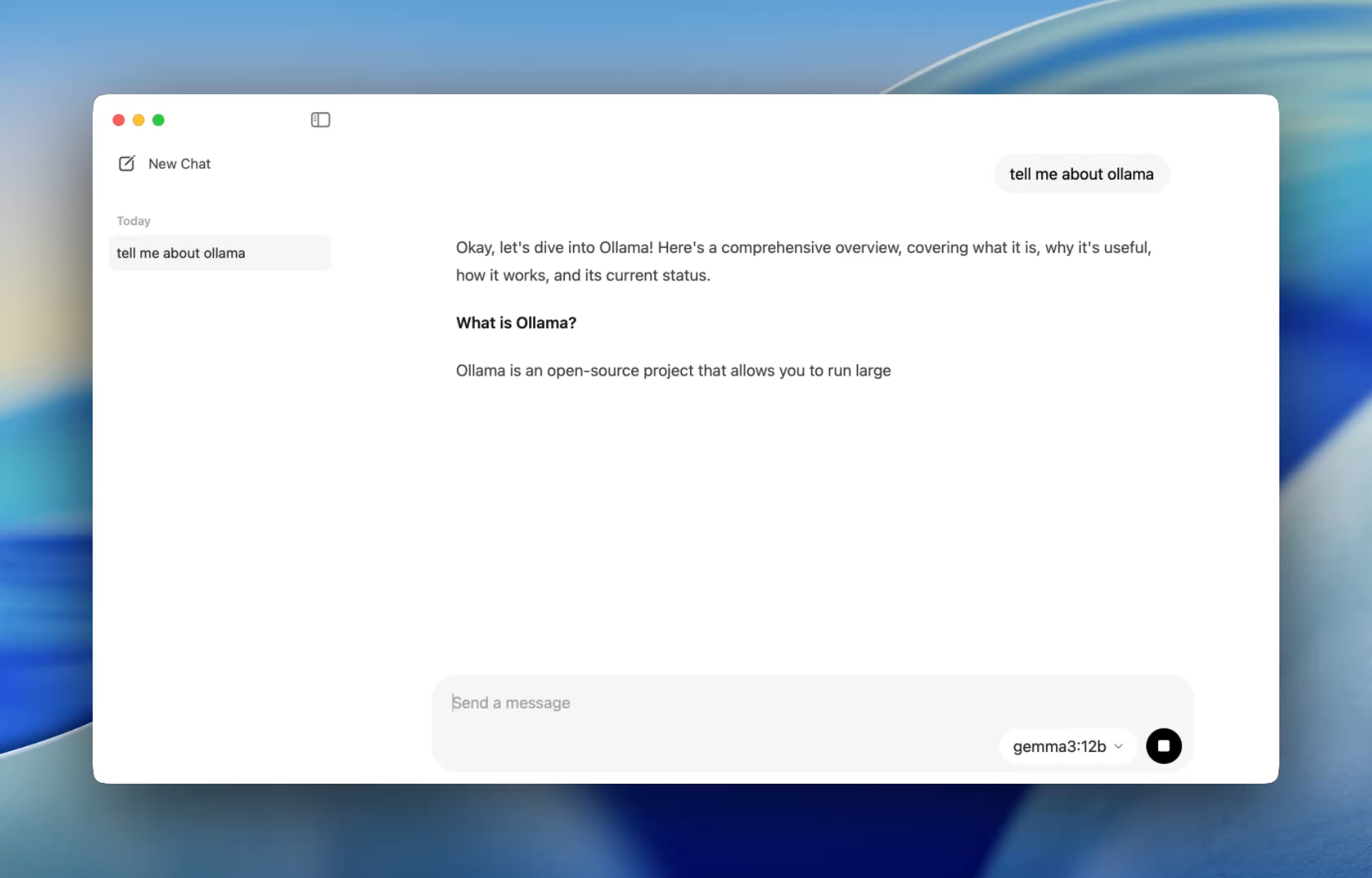
Anteriormente, usar o Ollama significava iniciar um terminal e emitir comandos ollama run para iniciar uma sessão de modelo. Agora, o aplicativo de desktop abre como qualquer aplicativo nativo, oferecendo uma interface de chat simples e limpa.
Agora você pode conversar com modelos da mesma forma que faria no ChatGPT — mas totalmente offline. Isso é perfeito para:
- Assistência para revisão de código
- Geração de testes
- Dicas de refatoração
- Aprendendo novas APIs ou linguagens
O aplicativo oferece acesso imediato a modelos locais como codellama ou mistral sem nenhuma configuração além de uma simples instalação.
E para desenvolvedores que amam personalização, a CLI ainda funciona nos bastidores, permitindo que você alterne o comprimento do contexto, prompts do sistema e versões do modelo via terminal, se necessário.
Arrastar. Soltar. Fazer Perguntas.
Conversar com Arquivos
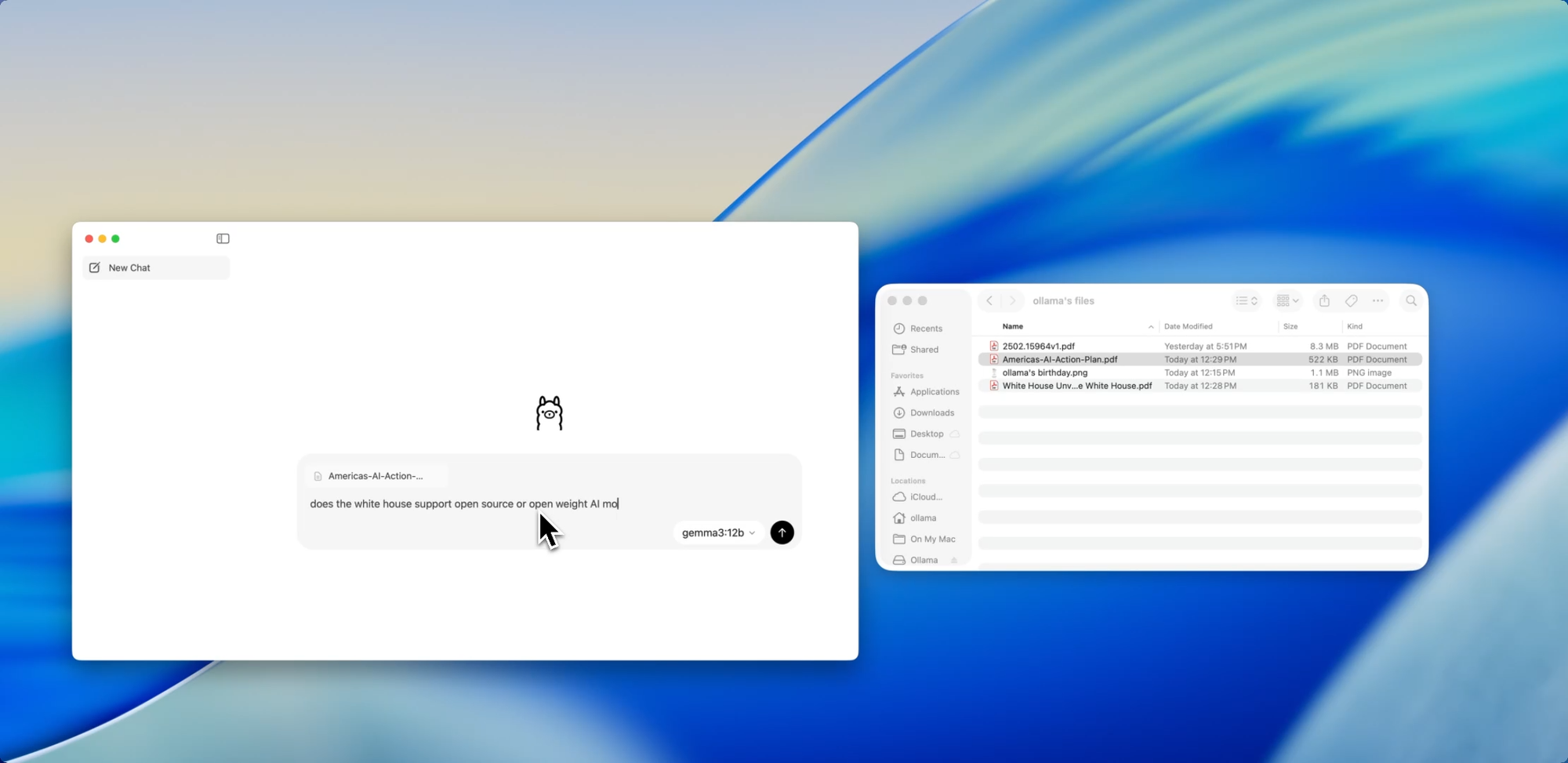
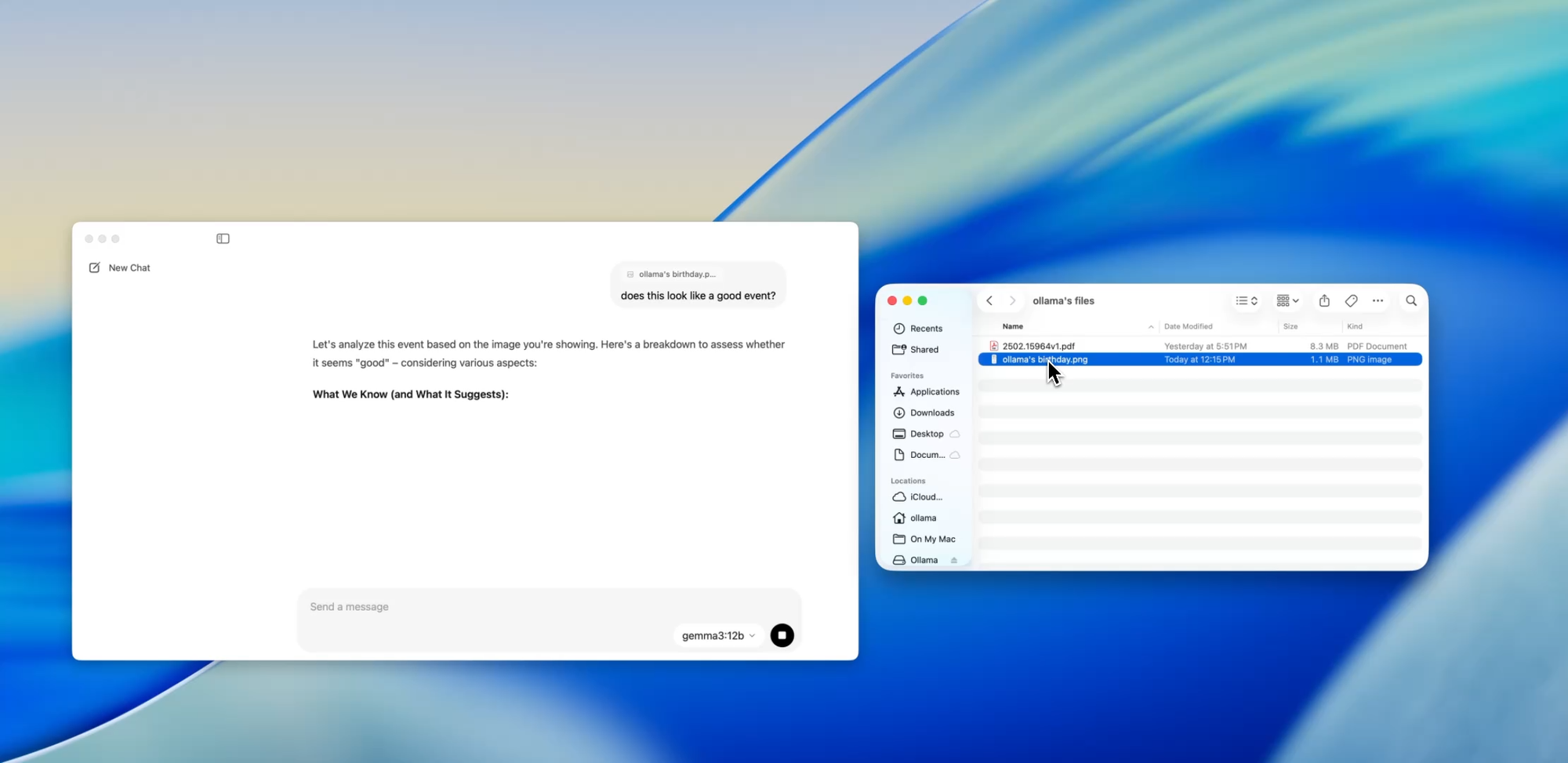
Um dos recursos mais amigáveis para desenvolvedores no novo aplicativo é a ingestão de arquivos. Basta arrastar um arquivo para a janela de chat — seja um .pdf, .md ou .txt — e o modelo lerá seu conteúdo.
Precisa entender um documento de design de 60 páginas? Quer extrair TODOs de um README bagunçado? Ou resumir o briefing de produto de um cliente? Arraste-o e faça perguntas em linguagem natural como:
- “Quais são os principais recursos discutidos neste documento?”
- “Resuma isso em um parágrafo.”
- “Existem seções ausentes ou inconsistências?”
Este recurso pode reduzir drasticamente o tempo gasto na leitura de documentação, revisão de especificações ou integração em novos projetos.
Vá Além do Texto
Suporte Multimodal
Modelos selecionados dentro do Ollama (como os baseados em Llava) agora suportam entrada de imagem. Isso significa que você pode fazer upload de uma imagem, e o modelo a interpretará e responderá a ela.
Alguns casos de uso incluem:
- Leitura de diagramas ou gráficos a partir de uma captura de tela
- Descrição de mockups de UI
- Revisão de notas manuscritas digitalizadas
- Análise de infográficos simples
Embora isso ainda esteja em estágio inicial em comparação com ferramentas como o GPT-4 Vision, ter suporte multimodal integrado a um aplicativo local-first é um grande passo para desenvolvedores que constroem sistemas de múltiplas entradas ou testam interfaces de IA.
Documentos Privados e Locais — ao Seu Comando
Escrita de Documentação
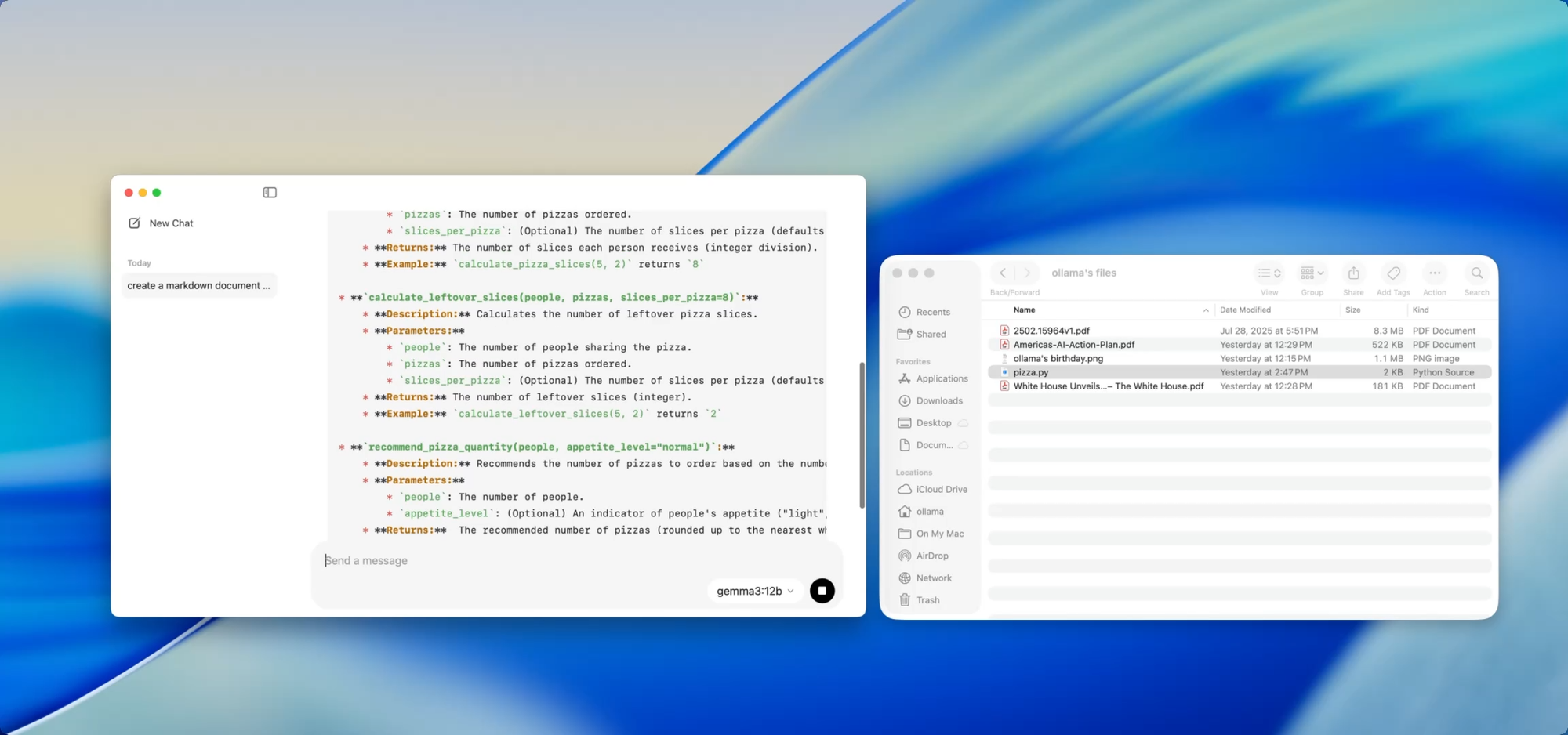
Se você está mantendo uma base de código crescente, conhece a dor da defasagem da documentação. Com o Ollama, você pode usar modelos locais para ajudar a gerar ou atualizar a documentação sem nunca enviar código sensível para a nuvem.
Basta arrastar um arquivo — digamos utils.py — para o aplicativo e perguntar:
- “Escreva docstrings para estas funções.”
- “Crie uma visão geral em Markdown do que este arquivo faz.”
- “Quais dependências este módulo usa?”
Isso se torna ainda mais poderoso quando combinado com ferramentas como [Deepdocs] que automatizam fluxos de trabalho de documentação usando IA. Você pode pré-carregar os arquivos README ou de esquema do seu projeto, então fazer perguntas de acompanhamento ou gerar logs de alterações, notas de migração ou guias de atualização — tudo localmente.
Ajuste de Desempenho Interno
Com este novo lançamento, o Ollama também melhorou o desempenho em todos os aspectos:
- A aceleração de GPU é melhor otimizada para Apple Silicon e placas Nvidia/AMD modernas.
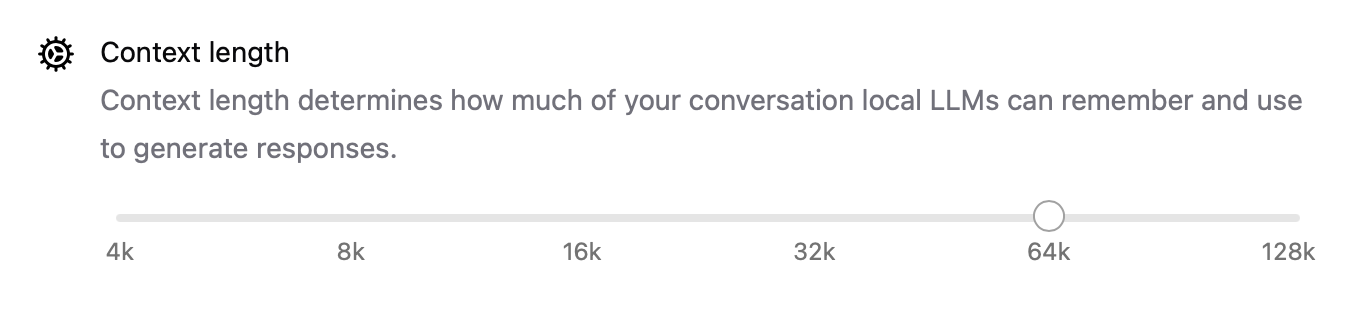
- O comprimento do contexto agora é configurável com configurações como
num_ctx=8192, para que você possa lidar com entradas mais longas. - O modo de rede permite que o Ollama funcione como um servidor de API local que você pode chamar de outros aplicativos ou dispositivos em sua LAN.
- Agora você pode alterar o local de armazenamento para modelos baixados — perfeito se você estiver trabalhando a partir de um drive externo ou quiser isolar modelos por projeto.
Essas atualizações tornam o aplicativo flexível para tudo, desde agentes locais a ferramentas de desenvolvimento e assistentes de pesquisa pessoais.
CLI e GUI: O Melhor dos Dois Mundos
A melhor parte? O novo aplicativo de desktop não substitui o terminal — ele o complementa.
Você ainda pode:
ollama pull codellama
ollama run codellama
Ou expor o servidor de modelo:
ollama serve --host 0.0.0.0
Então, se você está construindo uma interface de IA personalizada, agente ou plugin que depende de um LLM local, agora você pode construir sobre a API do Ollama e usar a GUI para interação direta ou testes.
Teste a API do Ollama Localmente com Apidog
Quer integrar o Ollama em seu aplicativo de IA ou testar seus endpoints de API locais? Você pode iniciar a API REST do Ollama usando:
bash ollama serve
Então, use o Apidog para testar, depurar e documentar seus endpoints de LLM locais.

Por que usar Apidog com Ollama:
- Interface visual para enviar requisições POST para o seu servidor local
http://localhost:11434 - Suporta geração de requisições assistida por IA e validação de respostas
- Perfeito para aplicativos de IA auto-hospedados, frameworks de agentes ou ferramentas internas
- Funciona perfeitamente com fluxos de trabalho de LLM locais e servidores de modelo personalizados
Casos de Uso para Desenvolvedores Que Realmente Funcionam
Aqui é onde o novo aplicativo Ollama se destaca em fluxos de trabalho reais de desenvolvedores:
| Caso de Uso | Como o Ollama Ajuda |
|---|---|
| Assistente de Revisão de Código | Execute codellama localmente para feedback de refatoração |
| Atualizações de Documentação | Peça aos modelos para reescrever, resumir ou corrigir arquivos de documentação |
| Chatbot de Desenvolvimento Local | Incorpore em seu aplicativo como um assistente ciente do contexto |
| Ferramenta de Pesquisa Offline | Carregue PDFs ou whitepapers e faça perguntas-chave |
| Ambiente de Testes Pessoal de LLM | Experimente engenharia de prompts e fine-tuning |
Para equipes preocupadas com a privacidade dos dados ou alucinações do modelo, os fluxos de trabalho de LLM local-first oferecem uma alternativa cada vez mais atraente.
Considerações Finais
A versão desktop do Ollama faz com que os LLMs locais pareçam menos um experimento científico improvisado e mais uma ferramenta de desenvolvedor polida.
Com suporte para interação com arquivos, entradas multimodais, escrita de documentos e desempenho nativo, é uma opção séria para desenvolvedores que se preocupam com velocidade, flexibilidade e controle.
Sem chaves de API na nuvem. Sem rastreamento em segundo plano. Sem cobrança por token. Apenas inferência rápida e local com a escolha de qualquer modelo aberto que atenda às suas necessidades.
Se você tem curiosidade em executar LLMs em sua máquina, ou se já usa o Ollama e deseja uma experiência mais fluida, agora é a hora de tentar novamente.