
O campo da inteligência artificial continua a evoluir rapidamente, trazendo modelos inovadores que redefinem os limites computacionais. Entre esses avanços, o MiniMax-M1 surge como um desenvolvimento revolucionário, marcando seu lugar como o primeiro modelo de raciocínio de atenção híbrida em larga escala e de peso aberto do mundo. Desenvolvido pela MiniMax, este modelo promete transformar a maneira como abordamos tarefas de raciocínio complexas, oferecendo uma impressionante janela de contexto de 1 milhão de tokens de entrada e 80.000 tokens de saída.
Compreendendo a Arquitetura Central do MiniMax-M1
O MiniMax-M1 se destaca por sua arquitetura híbrida única de Mixture-of-Experts (MoE), combinada com um mecanismo de atenção extremamente rápido. Este design se baseia na fundação estabelecida por seu predecessor, MiniMax-Text-01, que possui impressionantes 456 bilhões de parâmetros, com 45,9 bilhões ativados por token. A abordagem MoE permite que o modelo ative apenas um subconjunto de seus parâmetros com base na entrada, otimizando a eficiência computacional e permitindo escalabilidade. Enquanto isso, o mecanismo de atenção híbrida aprimora a capacidade do modelo de processar dados de longo contexto, tornando-o ideal para tarefas que exigem compreensão profunda sobre sequências estendidas.

A integração desses componentes resulta em um modelo que equilibra performance e uso de recursos de forma eficaz. Ao engajar seletivamente especialistas dentro da estrutura MoE, o MiniMax-M1 reduz a sobrecarga computacional tipicamente associada a modelos de larga escala. Além disso, o mecanismo de atenção lightning acelera o processamento dos pesos de atenção, garantindo que o modelo mantenha alto rendimento mesmo com sua extensa janela de contexto.
Eficiência de Treinamento: O Papel do Aprendizado por Reforço
Um dos aspectos mais notáveis do MiniMax-M1 é seu processo de treinamento, que aproveita o aprendizado por reforço (RL) em larga escala com uma eficiência sem precedentes. O modelo foi treinado a um custo de apenas $534.700, um valor que destaca o inovador framework de escalonamento de RL desenvolvido pela MiniMax. Este framework introduz o CISPO (Clipped Importance Sampling with Policy Optimization), um algoritmo inovador que limita os pesos de amostragem de importância em vez das atualizações de token. Esta abordagem supera as variantes tradicionais de RL, proporcionando um processo de treinamento mais estável e eficiente.

Além disso, o design de atenção híbrida desempenha um papel crucial no aumento da eficiência do RL. Ao abordar desafios únicos associados à escalabilidade do RL dentro de uma arquitetura híbrida, o MiniMax-M1 atinge um nível de performance que rivaliza com modelos de peso fechado, apesar de sua natureza de código aberto. Esta metodologia de treinamento não só reduz custos, mas também estabelece um novo parâmetro para o desenvolvimento de modelos de IA de alto desempenho com recursos limitados.
Métricas de Performance: Benchmarking do MiniMax-M1
Para avaliar as capacidades do MiniMax-M1, os desenvolvedores realizaram extensos benchmarks em uma variedade de tarefas, incluindo matemática de nível competitivo, codificação, engenharia de software, uso de ferramentas agentivas e compreensão de longo contexto. Os resultados destacam a superioridade do modelo sobre outros modelos de peso aberto, como DeepSeek-R1 e Qwen3-235B-A22B.
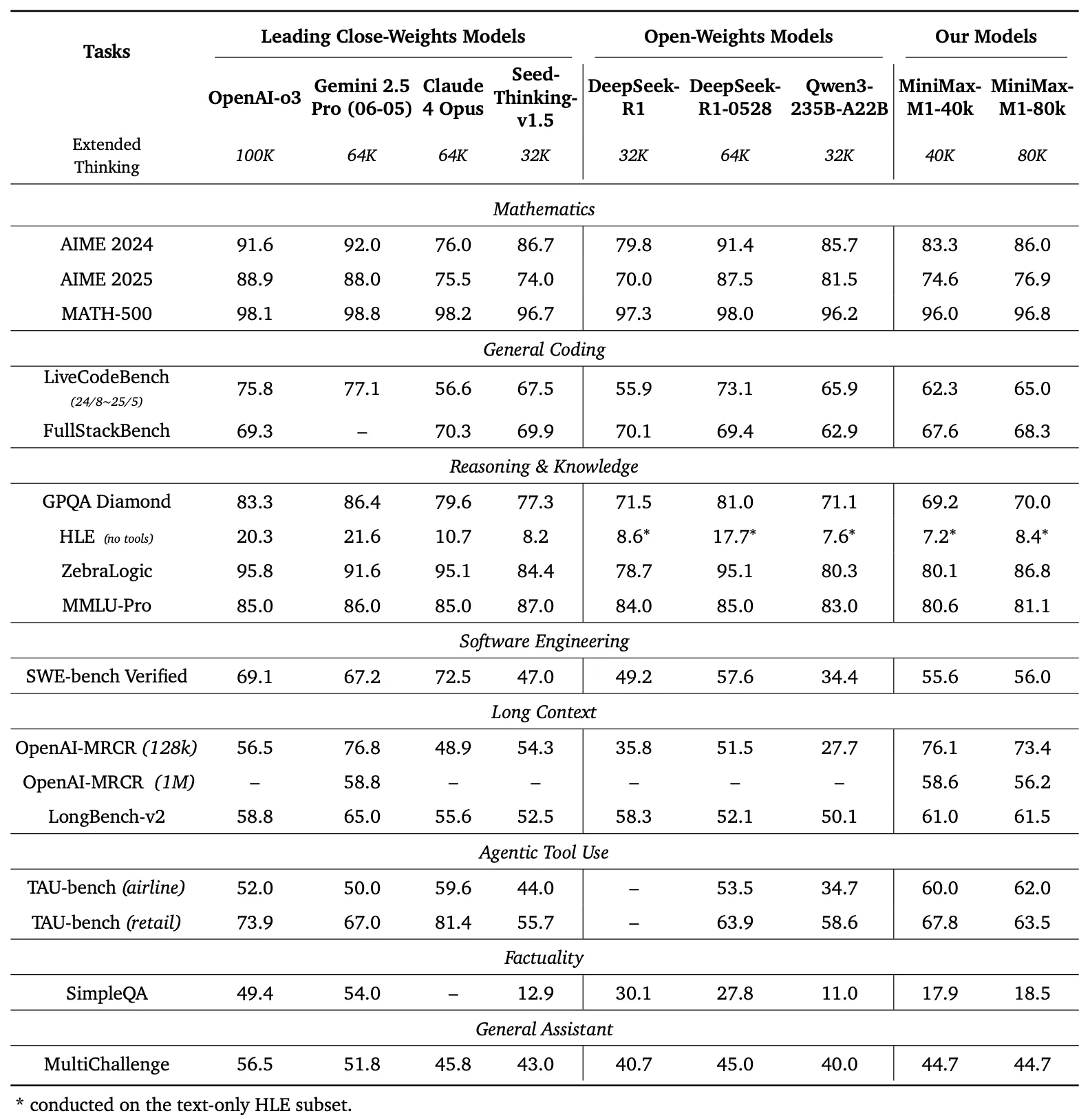
Comparação de Benchmark
O painel esquerdo da Figura 1 compara a performance do MiniMax-M1 com modelos comerciais e de peso aberto líderes em vários benchmarks

- AIME 2024: O MiniMax-M1 alcança uma precisão de 86,0%, superando OpenAI o3 (88,0%) e Claude 4 Opus (80,0%), demonstrando sua proficiência em raciocínio matemático.
- LiveCodeBench: Com uma pontuação de 65,0%, o MiniMax-M1 supera DeepSeek-R1-0528 (56,0%) e iguala a performance de Seed-Thinking v1.5 (65,0%), indicando fortes capacidades de codificação.
- SW-E Bench Verified: O modelo pontua 62,8%, superando Qwen3-235B-A22B (60,0%) em tarefas de engenharia de software.
- TAU-bench: O MiniMax-M1 registra 73,4% de precisão, excedendo Gemini 2.5 Pro (70,0%) no uso de ferramentas agentivas.
- MRCR (4-needle): Com 74,4% de precisão, ele lidera sobre outros modelos em tarefas de compreensão de longo contexto.
Esses resultados destacam a versatilidade do MiniMax-M1 e sua capacidade de competir com modelos proprietários, tornando-o um ativo valioso para as comunidades de código aberto.

O MiniMax-M1 demonstra um aumento linear em FLOPs (Floating Point Operations) à medida que o comprimento da geração se estende de 32k para 128k tokens. Essa escalabilidade garante que o modelo mantenha a eficiência e o desempenho mesmo com saídas estendidas, um fator crítico para aplicações que exigem respostas detalhadas e longas.
Raciocínio de Longo Contexto: Uma Nova Fronteira
A característica mais distintiva do MiniMax-M1 é sua janela de contexto ultra-longa, suportando até 1 milhão de tokens de entrada e 80.000 tokens de saída. Essa capacidade permite que o modelo processe vastas quantidades de dados — equivalente a um romance inteiro ou uma série de livros — em uma única passagem, excedendo em muito o limite de 128.000 tokens de modelos como o GPT-4 da OpenAI. O modelo oferece dois modos de inferência — orçamentos de pensamento de 40k e 80k — atendendo a diversas necessidades de cenário e permitindo uma implantação flexível.

Esta janela de contexto estendida aprimora a performance do modelo em tarefas de longo contexto, como resumir documentos extensos, conduzir conversas de várias rodadas ou analisar conjuntos de dados complexos. Ao reter informações contextuais ao longo de milhões de tokens, o MiniMax-M1 fornece uma base robusta para aplicações em pesquisa, análise jurídica e geração de conteúdo, onde manter a coerência em sequências longas é primordial.
Uso de Ferramentas Agentivas e Aplicações Práticas
Além de sua impressionante janela de contexto, o MiniMax-M1 se destaca no uso de ferramentas agentivas, um domínio onde modelos de IA interagem com ferramentas externas para resolver problemas. A capacidade do modelo de integrar-se com plataformas como o MiniMax Chat e gerar aplicações web funcionais — como testes de velocidade de digitação e geradores de labirintos — demonstra sua utilidade prática. Essas aplicações, construídas com configuração mínima e sem plugins, exibem a capacidade do modelo de produzir código pronto para produção.

Por exemplo, o modelo pode gerar um aplicativo web limpo e funcional para rastrear palavras por minuto (WPM) em tempo real ou criar um gerador de labirintos visualmente atraente com visualização do algoritmo A*. Tais capacidades posicionam o MiniMax-M1 como uma ferramenta poderosa para desenvolvedores que buscam automatizar fluxos de trabalho de desenvolvimento de software ou criar experiências de usuário interativas.
Acessibilidade de Código Aberto e Impacto na Comunidade
O lançamento do MiniMax-M1 sob a licença Apache 2.0 marca um marco significativo para a comunidade de código aberto. Disponível no GitHub e no Hugging Face, o modelo convida desenvolvedores, pesquisadores e empresas a explorá-lo, modificá-lo e implantá-lo sem restrições proprietárias. Essa abertura fomenta a inovação, permitindo a criação de soluções personalizadas adaptadas a necessidades específicas.
A acessibilidade do modelo também democratiza o acesso à tecnologia avançada de IA, permitindo que organizações menores e desenvolvedores independentes compitam com entidades maiores. Ao fornecer documentação detalhada e um relatório técnico, a MiniMax garante que os usuários possam replicar e estender as capacidades do modelo, acelerando ainda mais os avanços no ecossistema de IA.
Implementação Técnica: Implantação e Otimização
A implantação do MiniMax-M1 requer consideração cuidadosa dos recursos computacionais e técnicas de otimização. O relatório técnico recomenda o uso de vLLM (Virtual Large Language Model) para implantação em produção, o que otimiza a velocidade de inferência e o uso de memória. Esta ferramenta aproveita a arquitetura híbrida do modelo para distribuir a carga computacional de forma eficiente, garantindo uma operação suave mesmo com entradas em larga escala.
Desenvolvedores podem ajustar finamente o MiniMax-M1 para tarefas específicas ajustando o orçamento de pensamento (40k ou 80k) com base em seus requisitos. Além disso, o eficiente framework de treinamento RL do modelo permite personalização adicional através de aprendizado por reforço, possibilitando a adaptação a aplicações de nicho, como tradução em tempo real ou suporte automatizado ao cliente.
Conclusão: Abraçando a Revolução MiniMax-M1
O MiniMax-M1 representa um salto significativo no domínio dos modelos de raciocínio de atenção híbrida em larga escala e de peso aberto. Sua impressionante janela de contexto, processo de treinamento eficiente e performance superior em benchmarks o posicionam como um líder no cenário da IA. Ao oferecer esta tecnologia como um recurso de código aberto, a MiniMax capacita desenvolvedores e pesquisadores a explorar novas possibilidades, desde engenharia de software avançada até análise de longo contexto.
À medida que a comunidade de IA continua a crescer, o MiniMax-M1 serve como um testemunho do poder da inovação e colaboração. Para aqueles prontos para explorar seu potencial, baixar o Apidog gratuitamente oferece um ponto de entrada prático para experimentar este modelo transformador. A jornada com o MiniMax-M1 está apenas começando, e seu impacto, sem dúvida, moldará o futuro da inteligência artificial.
