
Engenheiros da Mistral AI projetaram o Magistral Small 1.2 como um modelo de 24 bilhões de parâmetros que prioriza a eficiência de raciocínio. Esta versão se baseia diretamente no Mistral Small 1.1. Os engenheiros aplicaram ajuste fino supervisionado (supervised fine-tuning) usando rastros do Magistral Medium, seguido por estágios de aprendizado por reforço (reinforcement learning). Consequentemente, o modelo se destaca em lógica multi-etapa sem demandas computacionais excessivas.
Compreendendo a Evolução da Família de Modelos Magistral
Fundação da Arquitetura e Especificações Técnicas
O Magistral Small 1.2 se baseia na robusta fundação do Magistral 1.1, incorporando capacidades avançadas de raciocínio através de ajuste fino supervisionado (SFT) a partir de rastros do Magistral Medium, combinado com otimização por aprendizado por reforço (RL). Construído sobre o Magistral 1.1, com capacidades de raciocínio adicionadas, passando por SFT a partir de rastros do Magistral Medium e RL por cima, é um modelo de raciocínio pequeno e eficiente com 24 bilhões de parâmetros.

Além disso, o design arquitetônico permite cenários de implantação eficientes. O Magistral Small pode ser implantado localmente, cabendo em uma única RTX 4090 ou em um MacBook com 32GB de RAM uma vez quantizado. Essa acessibilidade torna o modelo adequado tanto para ambientes empresariais quanto para desenvolvedores individuais.
Principais Aprimoramentos Técnicos na Versão 1.2
A transição da versão 1.1 para a 1.2 introduz diversas melhorias críticas que impactam significativamente o desempenho e a usabilidade do modelo. Mais notavelmente, essas atualizações abordam limitações fundamentais enquanto expandem os limites de capacidade.
Avanço na Integração Multimodal
Agora equipados com um codificador de visão, esses modelos lidam com texto e imagens de forma contínua. Essa integração representa uma mudança de paradigma, de raciocínio puramente baseado em texto para uma compreensão multimodal abrangente. A arquitetura do codificador de visão permite que os modelos processem informações visuais, mantendo suas capacidades de raciocínio textual.
Resultados de Otimização de Desempenho
Melhorias de 15% em benchmarks de matemática e codificação, como AIME 24/25 e LiveCodeBench v5/v6. Esses ganhos de desempenho se traduzem diretamente em aplicações práticas, beneficiando particularmente desenvolvedores que trabalham com computação matemática, desenvolvimento de algoritmos e cenários complexos de resolução de problemas.
Análise Abrangente de Recursos
Capacidades Avançadas de Raciocínio
A arquitetura de raciocínio incorpora tokens de pensamento especializados que estruturam o processo de raciocínio interno do modelo. A implementação utiliza os tokens [THINK] e [/THINK] para encapsular o conteúdo do raciocínio, criando transparência no processo de tomada de decisão do modelo e evitando confusão durante o processamento de prompts.
Além disso, o sistema de raciocínio opera através de cadeias estendidas de inferência lógica antes de gerar as respostas finais. Essa abordagem permite que o modelo lide com problemas complexos que exigem análise multi-etapa, derivações matemáticas e deduções lógicas.
Infraestrutura de Suporte Multilíngue
Os modelos demonstram suporte abrangente a idiomas em diversas famílias linguísticas. Os idiomas suportados abrangem regiões europeias, asiáticas, do Oriente Médio e do Sul da Ásia, incluindo inglês, francês, alemão, grego, hindi, indonésio, italiano, japonês, coreano, malaio, nepalês, polonês, português, romeno, russo, sérvio, espanhol, turco, ucraniano, vietnamita, árabe, bengali, chinês e farsi.
Além disso, essa extensa capacidade multilíngue garante acessibilidade global e permite que os desenvolvedores criem aplicações que atendam a mercados internacionais sem a necessidade de implementações de modelo separadas para diferentes idiomas.
Arquitetura de Processamento de Visão
A integração do codificador de visão permite análise e raciocínio sofisticados de imagens. O modelo processa conteúdo visual e o combina com informações textuais para gerar respostas abrangentes. Essa capacidade se estende além do simples reconhecimento de imagem para incluir compreensão contextual, raciocínio espacial e resolução de problemas visuais.
Benchmarks de Desempenho e Análise Comparativa
Desempenho em Raciocínio Matemático
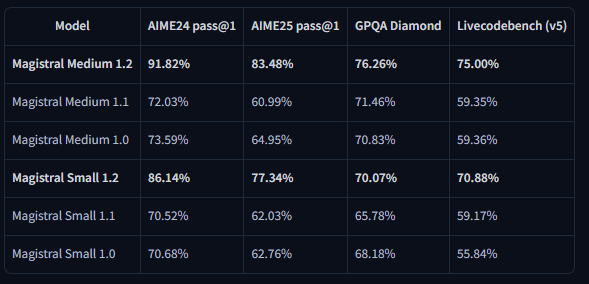
Os resultados dos benchmarks demonstram melhorias substanciais nas principais métricas de avaliação. O Magistral Small 1.2 atinge 86,14% no AIME24 pass@1 e 77,34% no AIME25 pass@1, representando avanços significativos em relação aos 70,52% e 62,03% da versão 1.1, respectivamente.
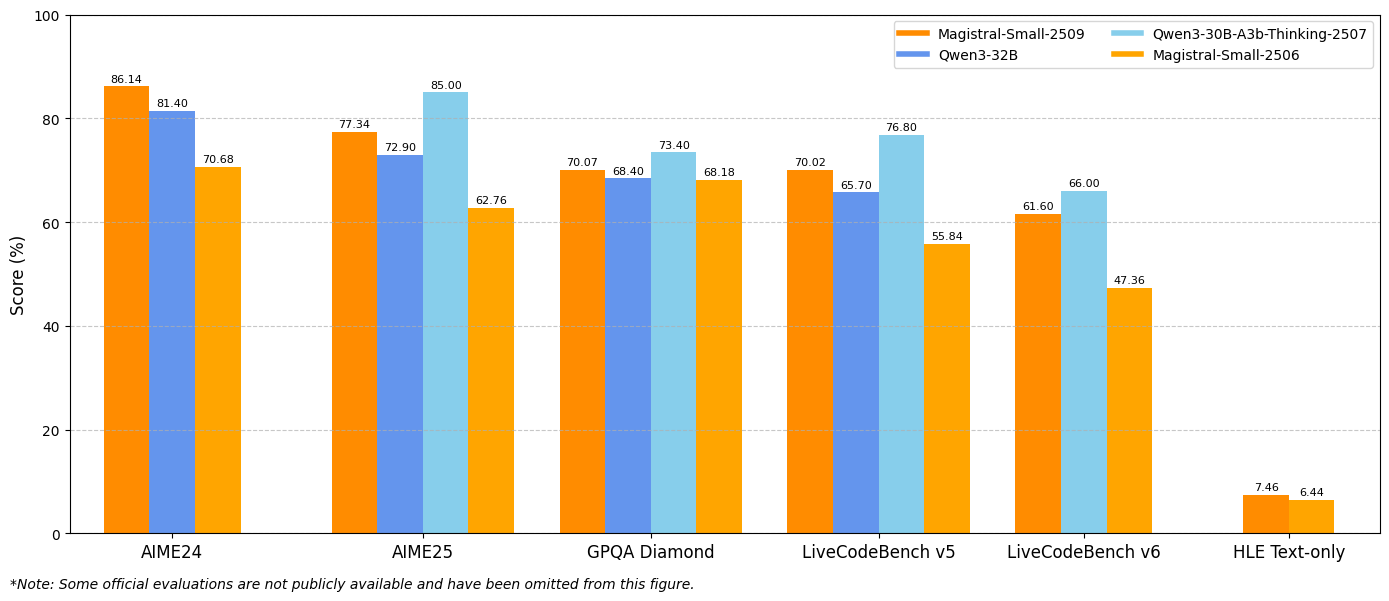
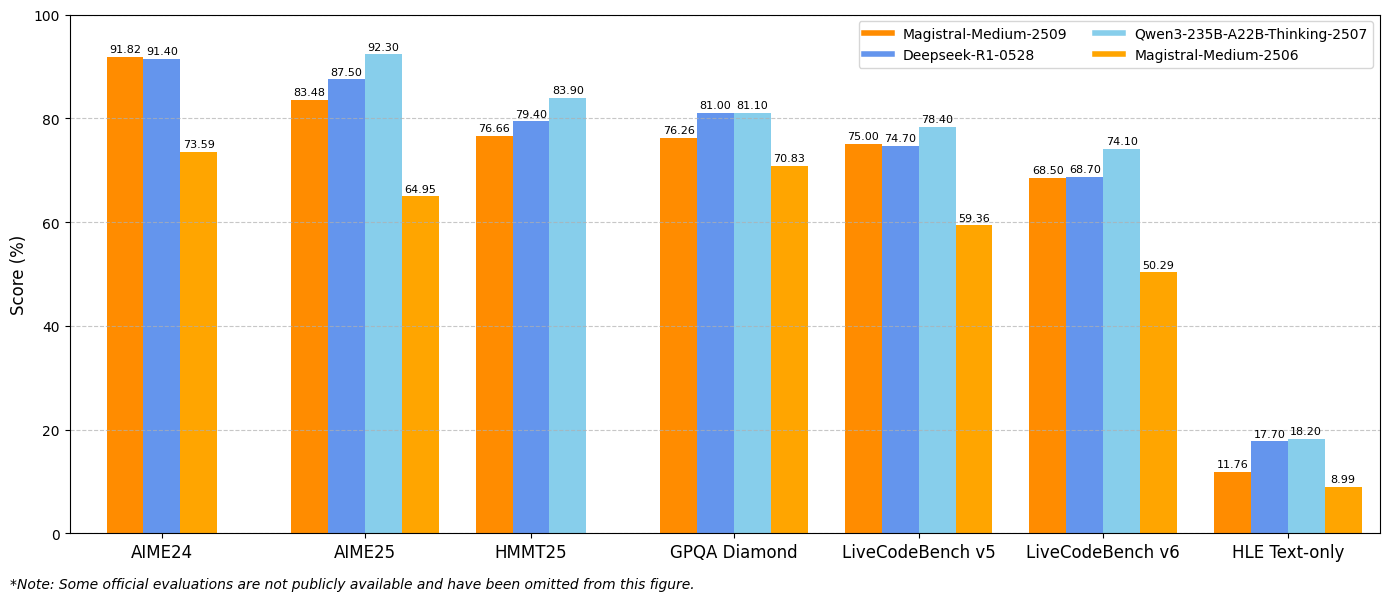
Da mesma forma, o Magistral Medium 1.2 oferece desempenho excepcional com 91,82% no AIME24 pass@1 e 83,48% no AIME25 pass@1, superando os 72,03% e 60,99% da versão 1.1. Essas melhorias indicam capacidades aprimoradas de raciocínio matemático que beneficiam diretamente a computação científica, aplicações de engenharia e ambientes de pesquisa.
Métricas de Desempenho em Codificação
As avaliações do LiveCodeBench revelam melhorias substanciais na capacidade de codificação. O Magistral Small 1.2 atinge 70,88% no LiveCodeBench v5, enquanto o Magistral Medium 1.2 alcança 75,00%. Essas pontuações representam avanços significativos em tarefas de geração de código, depuração e implementação de algoritmos.
Além disso, os modelos demonstram uma compreensão aprimorada de conceitos de programação, padrões de arquitetura de software e metodologias de depuração. Esse desempenho de codificação aprimorado beneficia equipes de desenvolvimento de software, frameworks de teste automatizados e ambientes de programação educacionais.
Resultados do GPQA Diamond
Os resultados do benchmark General Purpose Question Answering (GPQA) Diamond demonstram as amplas capacidades de aplicação de conhecimento dos modelos. O Magistral Small 1.2 atinge 70,07%, enquanto o Magistral Medium 1.2 alcança 76,26%. Essas pontuações refletem a capacidade dos modelos de lidar com diversos tipos de perguntas que exigem conhecimento e raciocínio interdisciplinares.
Estratégias de Implementação e Integração
Configuração do Ambiente de Desenvolvimento
A implementação do Magistral Small 1.2 e do Magistral Medium 1.2 requer configurações técnicas específicas para otimizar o desempenho. Os parâmetros de amostragem recomendados incluem top_p: 0.95, temperature: 0.7 e max_tokens: 131072. Essas configurações equilibram criatividade com consistência, ao mesmo tempo que suportam sequências de raciocínio estendidas.
Além disso, os modelos suportam vários frameworks de implantação, incluindo vLLM, Transformers, llama.cpp e formatos de quantização especializados. Essa flexibilidade permite a integração em diferentes ambientes de computação e casos de uso.
Integração de API com Apidog
Apidog oferece ferramentas abrangentes para testar e integrar APIs Magistral em suas aplicações. A plataforma suporta cenários avançados de teste de API, incluindo manipulação de entrada multimodal, análise de rastros de raciocínio e monitoramento de desempenho. Através da interface do Apidog, os desenvolvedores podem testar eficientemente combinações de imagem-texto, validar saídas de raciocínio e otimizar parâmetros de chamadas de API.
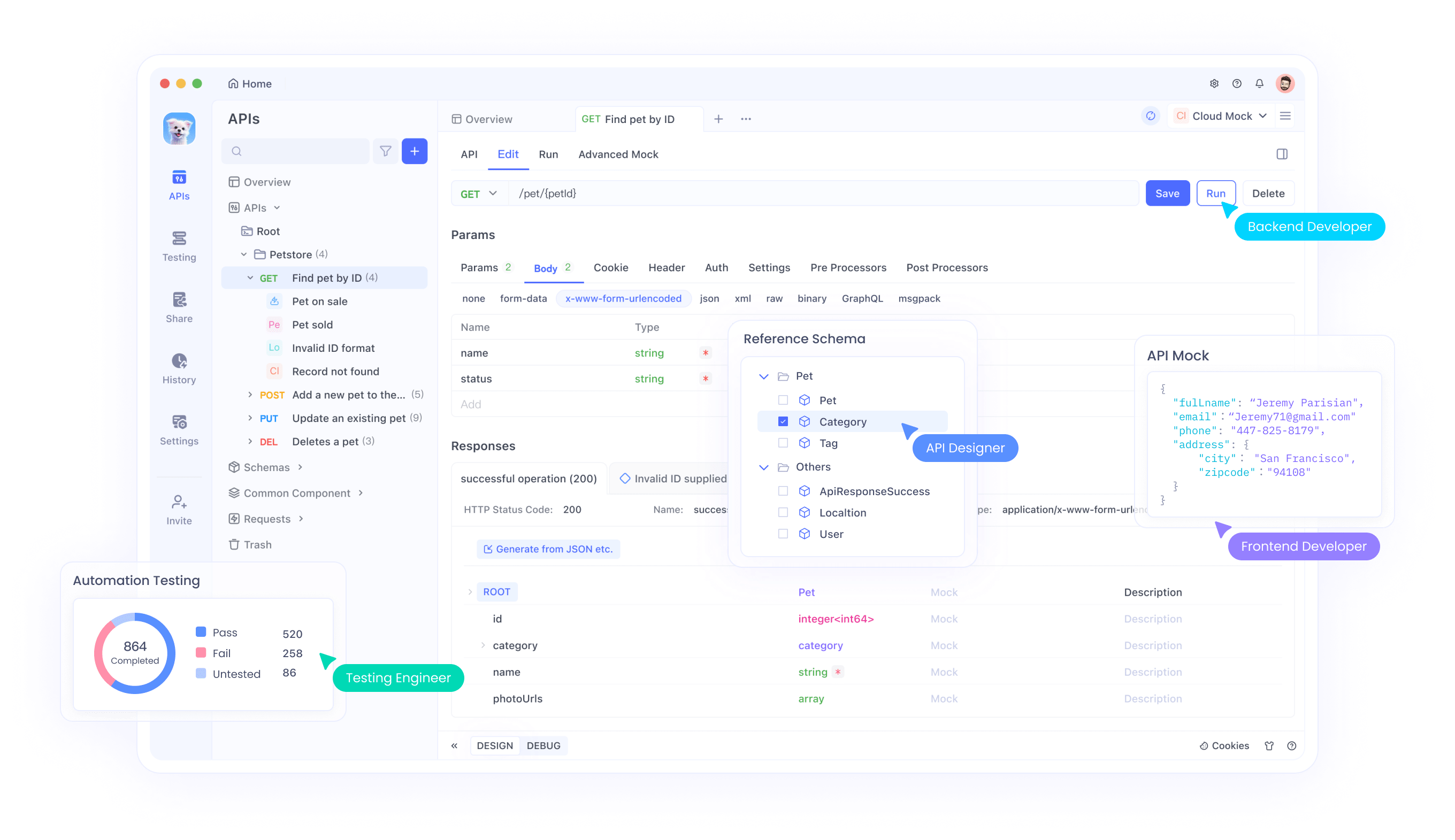
Além disso, os recursos de colaboração do Apidog permitem que as equipes compartilhem configurações de teste de API, documentem padrões de integração e mantenham padrões de teste consistentes em todos os ciclos de desenvolvimento. Essa abordagem colaborativa acelera os prazos de desenvolvimento, garantindo implementações de API robustas.
Otimização de Prompts de Sistema
Os modelos exigem prompts de sistema cuidadosamente elaborados para alcançar o desempenho ideal. A estrutura de prompt de sistema recomendada inclui instruções de raciocínio, diretrizes de formatação e especificações de idioma. O prompt deve solicitar explicitamente processos de pensamento usando os tokens especializados, mantendo uma formatação de resposta consistente.
Além disso, a personalização de prompts de sistema permite otimizações específicas da aplicação. Os desenvolvedores podem modificar os prompts para enfatizar padrões de raciocínio específicos, ajustar formatos de saída ou incorporar requisitos de conhecimento específicos do domínio.
Análise Detalhada da Implementação Técnica
Requisitos de Memória e Computacionais
O Magistral Small 1.2 opera eficientemente em ambientes de hardware restritos, mantendo alto desempenho. A arquitetura de 24 bilhões de parâmetros permite a implantação em hardware de consumo quando devidamente quantizado, tornando as capacidades avançadas de raciocínio acessíveis a desenvolvedores individuais e pequenas equipes.
Além disso, as melhorias na eficiência computacional na versão 1.2 reduzem a latência de inferência, mantendo a qualidade do raciocínio. Essa otimização permite aplicações em tempo real e sistemas interativos que exigem geração imediata de respostas.
Janela de Contexto e Capacidades de Processamento
Os modelos suportam uma janela de contexto de 128.000 tokens, permitindo o processamento de documentos extensos, conversas complexas e tarefas analíticas em larga escala. Embora o desempenho possa degradar além de 40.000 tokens, os modelos mantêm funcionalidade razoável em toda a faixa de contexto.
Além disso, a capacidade de contexto estendido permite análise abrangente de documentos, tarefas de raciocínio de formato longo e conversas multi-turno com consciência de contexto mantida. Essa capacidade suporta aplicações empresariais que exigem processamento extensivo de informações.
Técnicas de Quantização e Otimização
Os modelos suportam vários formatos de quantização através de implementações GGUF, permitindo a implantação em diferentes configurações de hardware. Essas otimizações reduzem os requisitos de memória, preservando as capacidades de raciocínio, tornando os modelos acessíveis em ambientes com recursos limitados.
Além disso, técnicas de otimização especializadas mantêm a velocidade de inferência, ao mesmo tempo que suportam as operações complexas de raciocínio. Essas melhorias técnicas garantem a viabilidade de implantação prática em diversos ambientes de computação.
Teste e Validação com Apidog
Estratégias Abrangentes de Teste de API
O Apidog fornece ferramentas essenciais para validar integrações de modelos Magistral através de frameworks de teste abrangentes. A plataforma suporta teste de entrada multimodal, validação de rastros de raciocínio e benchmarking de desempenho. As equipes podem criar suítes de teste que verificam tanto a correção funcional quanto as características de desempenho.
As capacidades de teste automatizado do Apidog permitem fluxos de trabalho de integração contínua que garantem a consistência do desempenho do modelo em todos os ciclos de desenvolvimento. Essa automação reduz a sobrecarga de testes manuais, mantendo os padrões de garantia de qualidade.
Monitoramento e Otimização de Desempenho
Através das capacidades de monitoramento do Apidog, as equipes de desenvolvimento podem rastrear métricas de desempenho da API, identificar oportunidades de otimização e manter a confiabilidade do serviço. A plataforma fornece análises detalhadas sobre tempos de resposta, qualidade do raciocínio e padrões de utilização de recursos.
Além disso, os dados de monitoramento permitem estratégias de otimização proativas que melhoram o desempenho da aplicação e a experiência do usuário. Essa abordagem orientada a dados garante a utilização ideal do modelo em ambientes de produção.
Conclusão
O Magistral Small 1.2 e o Magistral Medium 1.2 representam avanços significativos na tecnologia de raciocínio de IA multimodal. A combinação de desempenho matemático aprimorado, capacidades de visão e transparência de raciocínio melhorada cria ferramentas poderosas para diversas aplicações, desde pesquisa científica até desenvolvimento de software.
As melhorias de acessibilidade através de opções de implantação local e suporte abrangente a API democratizam o acesso a capacidades avançadas de raciocínio. As organizações podem agora integrar raciocínio de IA sofisticado em seus fluxos de trabalho sem exigir investimentos extensivos em infraestrutura.
Seja você desenvolvendo aplicações educacionais, conduzindo pesquisa científica ou construindo sistemas de software complexos, o Magistral Small 1.2 e o Magistral Medium 1.2 fornecem as capacidades de raciocínio necessárias para aplicações de IA de próxima geração. Combinados com ferramentas robustas de teste e integração como o Apidog, esses modelos permitem fluxos de trabalho de desenvolvimento abrangentes que aceleram a inovação, mantendo os padrões de qualidade.