
No rápido cenário em evolução dos grandes modelos de linguagem, o Llama Nemotron Ultra 253B da NVIDIA se destaca como uma potência para empresas que buscam capacidades avançadas de raciocínio. Este guia abrangente examina os impressionantes benchmarks do modelo, compara-o a outros modelos de código aberto líderes e fornece etapas claras para implementar sua API em suas aplicações.
Benchmark do llama-3.1-nemotron-ultra-253b
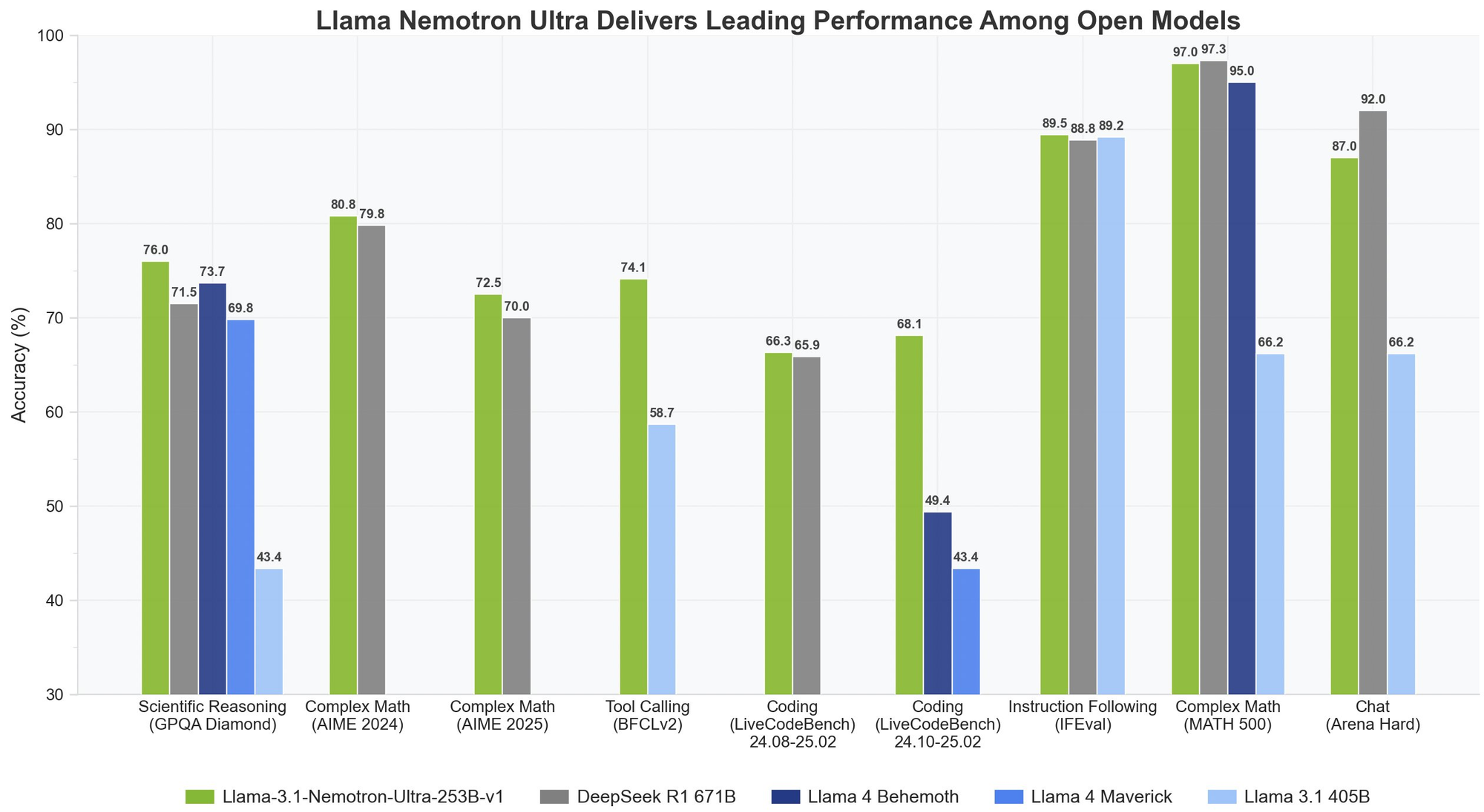
O Llama Nemotron Ultra 253B apresenta resultados excepcionais em benchmarks críticos de raciocínio e agentes, com sua capacidade única de "Raciocínio LIGADO/DESLIGADO" mostrando diferenças de desempenho dramáticas:
Raciocínio Matemático
O Llama Nemotron Ultra 253B realmente brilha em tarefas de raciocínio matemático:
- MATH500
- Raciocínio DESLIGADO: 80,4% pass@1
- Raciocínio LIGADO: 97,0% pass@1
Com 97% de precisão com o Raciocínio LIGADO, o Llama Nemotron Ultra 253B quase aperfeiçoa este desafiador benchmark matemático.
- AIME25 (Exame de Matemática Convite Americana)
- Raciocínio DESLIGADO: 16,7% pass@1
- Raciocínio LIGADO: 72,50% pass@1
Essa notável melhoria de 56 pontos demonstra como as capacidades de raciocínio do Llama Nemotron Ultra 253B transformam seu desempenho em problemas complexos de matemática.
Raciocínio Científico
- GPQA (Questões e Respostas de Física de Nível de Graduação)
- Raciocínio DESLIGADO: 56,6% pass@1
- Raciocínio LIGADO: 76,01% pass@1
A melhoria significativa demonstra como o Llama Nemotron Ultra 253B pode enfrentar problemas de física de nível de graduação por meio de uma análise metódica quando o raciocínio é ativado.
Programação e Uso de Ferramentas
- LiveCodeBench (20240801-20250201)
- Raciocínio DESLIGADO: 29,03% pass@1
- Raciocínio LIGADO: 66,31% pass@1
O Llama Nemotron Ultra 253B mais do que duplica seu desempenho em codificação com o raciocínio ativado.
- BFCL V2 Ao Vivo (Chamada de Função)
- Raciocínio DESLIGADO: 73,62 pontuação
- Raciocínio LIGADO: 74,10 pontuação
Esse benchmark demonstra as fortes capacidades de uso de ferramentas do modelo em ambos os modos, críticos para a construção de agentes de IA eficazes.
Seguindo Instruções
- IFEval (Avaliação de Seguir Instruções)
- Raciocínio DESLIGADO: 88,85% de precisão estrita
- Raciocínio LIGADO: 89,45% de precisão estrita
Ambos os modos apresentam um desempenho excelente, mostrando que o Llama Nemotron Ultra 253B mantém fortes habilidades de seguir instruções, independentemente do modo de raciocínio.
Llama Nemotron Ultra 253B vs. DeepSeek-R1
O DeepSeek-R1 tem sido o padrão ouro para modelos de raciocínio de código aberto, mas o Llama Nemotron Ultra 253B iguala ou supera seu desempenho em benchmarks críticos de raciocínio:
- No GPQA, o Llama Nemotron Ultra 253B alcança 76,01% de precisão, competindo com o desempenho de elite do DeepSeek-R1
- O Llama Nemotron Ultra 253B oferece modos de raciocínio duplo, ao contrário da abordagem fixa de raciocínio do DeepSeek-R1
- O Llama Nemotron Ultra 253B fornece capacidades superiores de chamada de função, tornando-o mais versátil para aplicações agentes
Llama Nemotron Ultra 253B vs. Llama 4
Quando comparado aos próximos modelos Behemoth e Maverick do Llama 4:
- O Llama Nemotron Ultra 253B demonstra desempenho superior em benchmarks de raciocínio científico e matemático complexo
- O interruptor de raciocínio explícito no Llama Nemotron Ultra 253B oferece mais flexibilidade do que os modelos padrão do Llama 4
- O Llama Nemotron Ultra 253B é especificamente otimizado para hardware NVIDIA, proporcionando melhor eficiência de inferência
Vamos Testar Llama Nemotron Ultra 253B via API
Implementar o Llama Nemotron Ultra 253B em suas aplicações requer seguir etapas específicas para garantir desempenho ideal:
Etapa 1: Obtenha Acesso à API
Para acessar o Llama Nemotron Ultra 253B:
- Visite o portal de API da NVIDIA em https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1
- Registre-se para obter uma chave de API, se ainda não tiver uma
- Se estiver rodando no ambiente NGC da NVIDIA, a configuração da chave de API pode ser simplificada
Etapa 2: Configure Seu Ambiente de Desenvolvimento
Antes de fazer chamadas de API:
- Instale o pacote Python da OpenAI usando
pip install openai - Importe a biblioteca necessária:
from openai import OpenAI - Configure seu ambiente para armazenar a chave de API com segurança
Etapa 3: Configure o Cliente da API
Inicialize o cliente OpenAI com os endpoints da NVIDIA:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "SUA_CHAVE_API_AQUI"
)

- Diferente do Postman, o Apidog oferece uma experiência mais integrada com documentação de API embutida, testes automatizados e servidores simulados especificamente otimizados para endpoints de modelos de IA.
- A interface intuitiva do Apidog torna mais fácil configurar os complexos conjuntos de parâmetros necessários para o teste de API, e suas funcionalidades de visualização de respostas são particularmente úteis para analisar as saídas de streaming do modelo.
- Embora o Postman continue sendo uma ferramenta popular de teste de API de propósito geral, as funcionalidades focadas em IA do Apidog e o fluxo de trabalho simplificado podem acelerar significativamente seu processo de desenvolvimento.

Etapa 4: Determine o Modo de Raciocínio Apropriado
O Llama Nemotron Ultra 253B oferece dois modos de operação distintos:
- Raciocínio LIGADO: Melhor para problemas complexos que exigem pensamento passo a passo (matemática, física, codificação)
- Raciocínio DESLIGADO: Ideal para seguir instruções diretas e bate-papo geral
Etapa 5: Crie Seus Prompts de Sistema e Usuário
Para o modo Raciocínio LIGADO:
- Defina o prompt do sistema para
"pensamento detalhado ligado" - Coloque todas as instruções na mensagem do usuário
- Considere usar templates específicos para tarefas avaliadas (como problemas de matemática)
Para o modo Raciocínio DESLIGADO:
- Remova o prompt do sistema de raciocínio
- Use instruções concisas e claras na mensagem do usuário
Etapa 6: Configure os Parâmetros de Geração
Para resultados ótimos:
- Raciocínio LIGADO: Defina temperature=0.6 e top_p=0.95 conforme recomendado pela NVIDIA
- Raciocínio DESLIGADO: Use decodificação gananciosa com temperature=0
- Defina
max_tokensapropriado com base no comprimento esperado da resposta - Considere habilitar streaming para respostas em tempo real
Etapa 7: Faça o Pedido à API e Trate as Respostas
Crie seu pedido de conclusão com todos os parâmetros configurados:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "pensamento detalhado ligado"},
{"role": "user", "content": "Seu prompt aqui"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
Etapa 8: Processe e Exiba a Resposta
Se estiver usando streaming:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Para respostas não-streaming, acesse simplesmente completion.choices[0].message.content.
Conclusão
O Llama Nemotron Ultra 253B representa um avanço significativo nos modelos de raciocínio de código aberto, oferecendo desempenho de ponta em uma ampla gama de benchmarks. Seus únicos modos de raciocínio duplo, combinados com excepcionais capacidades de chamada de função e uma enorme janela de contexto, fazem dele uma escolha ideal para aplicações de IA empresariais que requerem capacidades avançadas de raciocínio.
Com o guia de implementação da API passo a passo descrito neste artigo, os desenvolvedores podem aproveitar todo o potencial do Llama Nemotron Ultra 253B para construir sistemas de IA sofisticados que enfrentam problemas complexos com raciocínio semelhante ao humano. Seja construindo agentes de IA, aprimorando sistemas RAG ou desenvolvendo aplicações especializadas, o Llama Nemotron Ultra 253B fornece uma base poderosa para capacidades de IA de próxima geração em um pacote de código aberto amigável ao comércio.