
O cenário da inteligência artificial foi fundamentalmente transformado com o lançamento do Llama 4 pela Meta—não apenas através de melhorias incrementais, mas por meio de avanços arquitetônicos que redefinem as relações de custo-desempenho em toda a indústria. Esses novos modelos representam a convergência de três inovações críticas: multimodalidade nativa através de técnicas de fusão precoce, arquiteturas de mistura esparsa de especialistas (MoE) que melhoram radicalmente a eficiência dos parâmetros, e expansões da janela de contexto que se estendem a impressionantes 10 milhões de tokens.
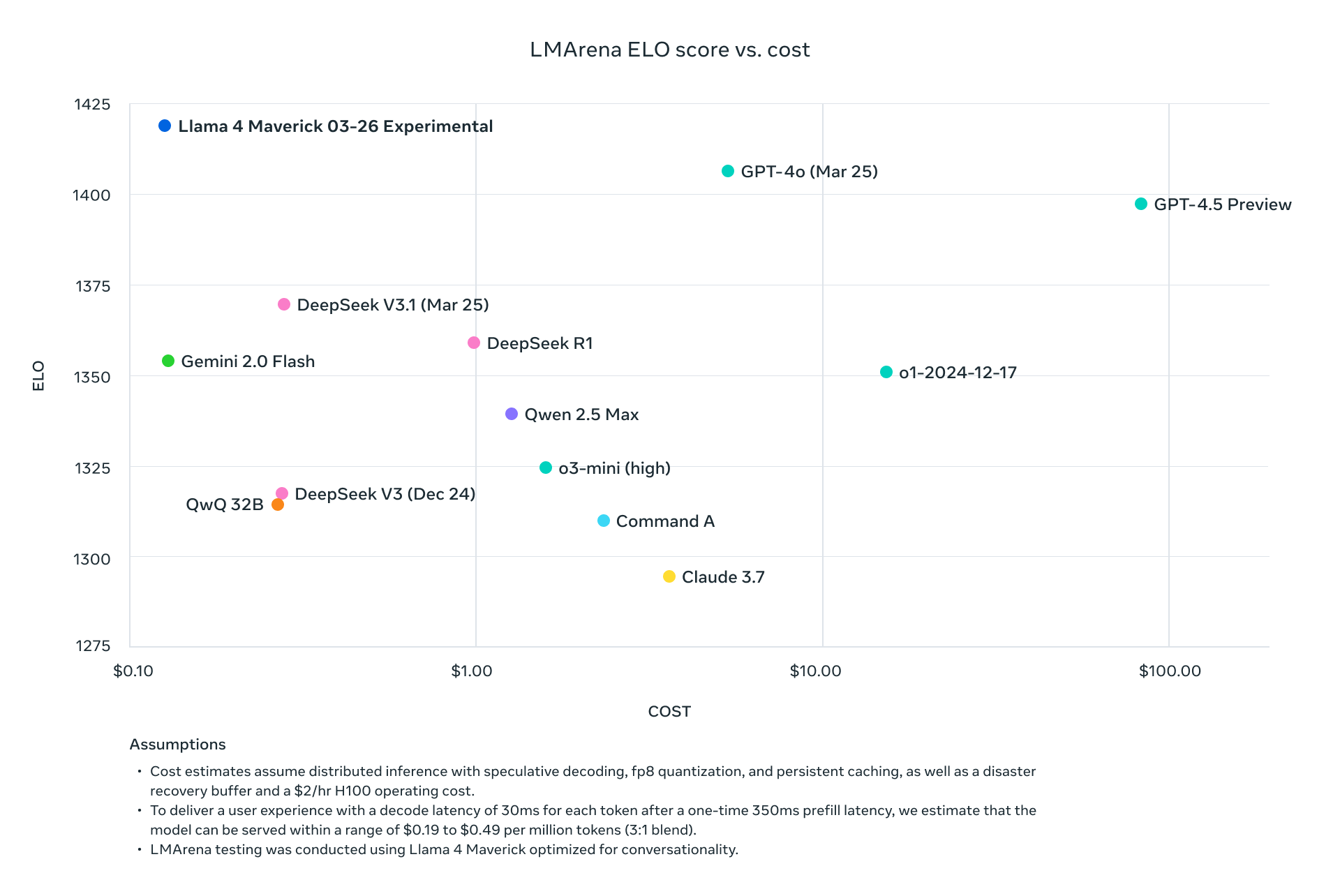
O Llama 4 Scout e o Maverick não apenas competem com os atuais líderes da indústria—eles superam sistematicamente esses concorrentes em benchmarks padrão enquanto reduzem drasticamente os requisitos computacionais. Com o Maverick alcançando resultados melhores que o GPT-4o a aproximadamente um-nono do custo por token, e o Scout se ajustando em uma única GPU H100 enquanto mantém desempenho superior a modelos que requerem múltiplas GPUs, a Meta alterou fundamentalmente a economia da implementação de IA avançada.
Esta análise técnica disseca as inovações arquitetônicas que alimentam esses modelos, apresenta dados abrangentes de benchmarks em tarefas de raciocínio, codificação, multilíngue e multimodal, e examina as estruturas de preços da API entre os principais provedores. Para tomadores de decisão técnica avaliando opções de infraestrutura de IA, fornecemos comparações detalhadas de desempenho/custo e estratégias de implementação para maximizar a eficiência desses modelos inovadores em ambientes de produção.
Você pode baixar o Meta Llama 4 de Código Aberto e Peso Aberto no Hugging Face, a partir de hoje:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

Como Llama 4 Alcançou a Janela de Contexto de 10M?
Implementação de Mistura de Especialistas (MoE)
Todos os modelos Llama 4 empregam uma arquitetura MoE sofisticada que muda fundamentalmente a equação de eficiência:
| Modelo | Parâmetros Ativos | Contagem de Especialistas | Total de Parâmetros | Método de Ativação de Parâmetros |
|---|---|---|---|---|
| Llama 4 Scout | 17B | 16 | 109B | Roteamento específico de tokens |
| Llama 4 Maverick | 17B | 128 | 400B | Especialista roteado compartilhado + único por token |
| Llama 4 Behemoth | 288B | 16 | ~2T | Roteamento específico de tokens |
O design MoE no Llama 4 Maverick é particularmente sofisticado, utilizando camadas densas e camadas MoE alternadas. Cada token ativa o especialista compartilhado mais um dos 128 especialistas roteados, significando que apenas aproximadamente 17B de 400B de parâmetros totais estão ativos para processar qualquer token dado.
Arquitetura Multimodal
Arquitetura Multimodal do Llama 4:
├── Tokens de Texto
│ └── Caminho de processamento de texto nativo
├── Codificador de Visão (MetaCLIP Aprimorado)
│ ├── Processamento de imagem
│ └── Converte imagens em sequências de tokens
└── Camada de Fusão Precoce
└── Unifica tokens de texto e visão na espinha dorsal do modelo
Essa abordagem de fusão precoce permite pré-treinamento em mais de 30 trilhões de tokens de dados mistos de texto, imagem e vídeo, resultando em capacidades multimodais significativamente mais coerentes do que abordagens retroativas.
Arquitetura iRoPE para Janelas de Contexto Estendidas
A janela de contexto de 10M tokens do Llama 4 Scout aproveita a inovadora arquitetura iRoPE:
# Pseudocódigo para a arquitetura iRoPE
def iRoPE_layer(tokens, layer_index):
if layer_index % 2 == 0:
# Camadas pares: Atenção intercalada sem embeddings posicionais
return attention_no_positional(tokens)
else:
# Camadas ímpares: RoPE (Embeddings de Posição Rotativa)
return attention_with_rope(tokens)
def inference_scaling(tokens, temperature_factor):
# A escalabilidade de temperatura durante a inferência melhora a generalização de comprimento
return scale_attention_scores(tokens, temperature_factor)
Essa arquitetura permite que o Scout processe documentos de comprimento sem precedentes enquanto mantém coerência ao longo do texto, com um fator de escalabilidade aproximadamente 80 vezes maior do que as janelas de contexto dos modelos anteriores do Llama.
Análise Abrangente de Benchmark
Métricas de Desempenho de Benchmark Padrão
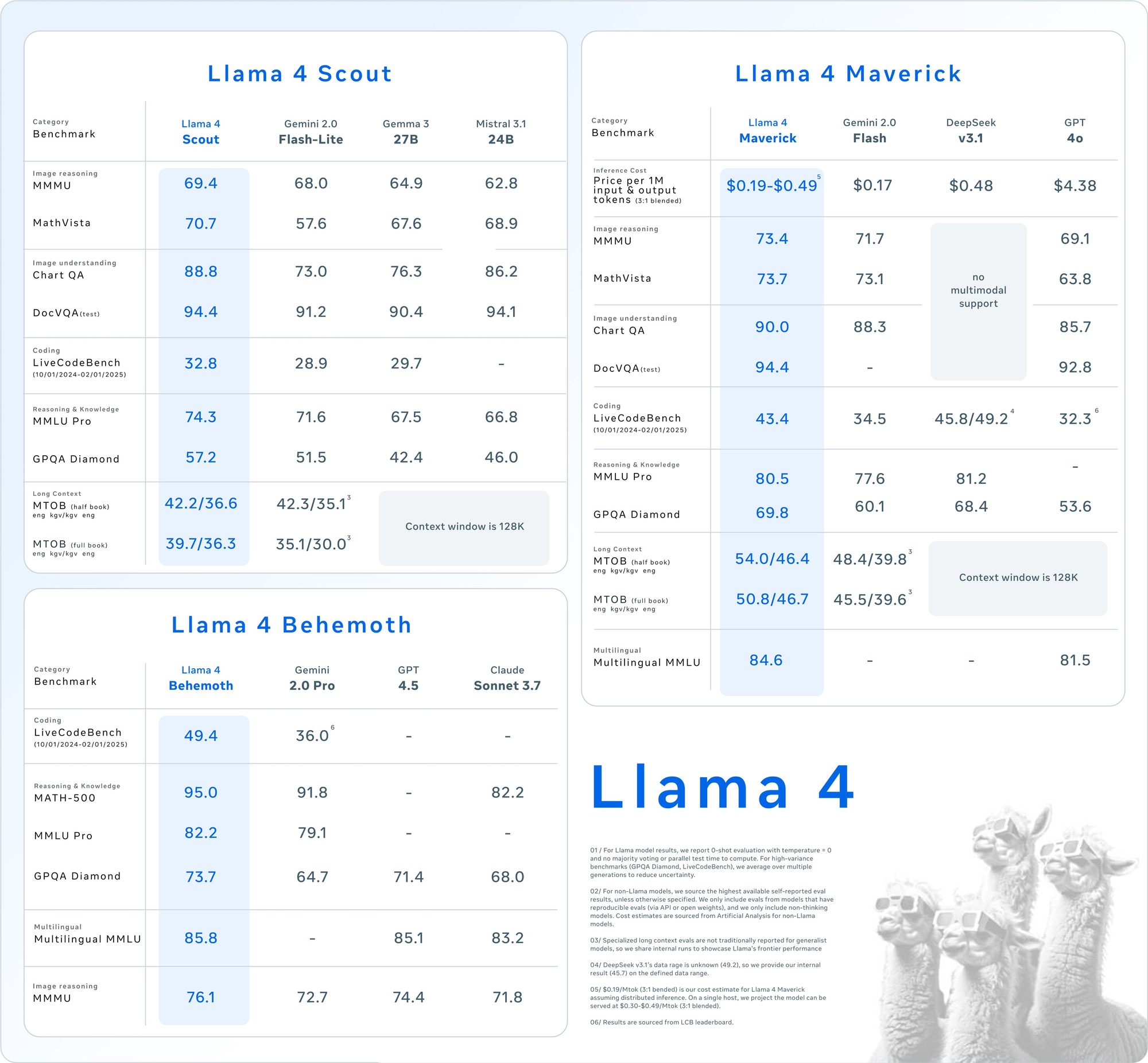
Resultados detalhados de benchmark entre os principais conjuntos de avaliação revelam a posição competitiva dos modelos Llama 4:
| Categoria | Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| Raciocínio de Imagens | MMMU | 73.4 | 69.1 | 71.7 | Sem suporte multimodal |
| MathVista | 73.7 | 63.8 | 73.1 | Sem suporte multimodal | |
| Compreensão de Imagens | ChartQA | 90.0 | 85.7 | 88.3 | Sem suporte multimodal |
| DocVQA (teste) | 94.4 | 92.8 | - | Sem suporte multimodal | |
| Codificação | LiveCodeBench | 43.4 | 32.3 | 34.5 | 45.8/49.2 |
| Raciocínio & Conhecimento | MMLU Pro | 80.5 | - | 77.6 | 81.2 |
| GPQA Diamond | 69.8 | 53.6 | 60.1 | 68.4 | |
| Multilíngue | Multilingual MMLU | 84.6 | 81.5 | - | - |
| Longo Contexto | MTOB (meio livro) eng→kgv/kgv→eng | 54.0/46.4 | Contexto limitado a 128K | 48.4/39.8 | Contexto limitado a 128K |
| MTOB (livro completo) eng→kgv/kgv→eng | 50.8/46.7 | Contexto limitado a 128K | 45.5/39.6 | Contexto limitado a 128K |
Análise Técnica de Desempenho por Categoria
Capacidades de Processamento Multimodal
O Llama 4 demonstra desempenho superior em tarefas multimodais, com o Maverick marcando 73.4% no MMMU em comparação com 69.1% do GPT-4o e 71.7% do Gemini 2.0 Flash. A diferença de desempenho se amplia ainda mais no MathVista, onde o Maverick marca 73.7% contra 63.8% do GPT-4o.
Essa vantagem decorre da arquitetura multimodal nativa que permite:
- Mecanismos de atenção conjunta entre tokens de texto e imagem
- Integração de modalidades por meio de fusão precoce durante o pré-treinamento
- Codificador de visão MetaCLIP aprimorado especificamente ajustado para integração com LLMs
Análise de Geração de Código
Desempenho do LiveCodeBench (01/10/2024-01/02/2025):
├── Llama 4 Maverick: 43.4%
├── Llama 4 Scout: 38.1%
├── GPT-4o: 32.3%
├── Gemini 2.0 Flash: 34.5%
└── DeepSeek v3.1: 45.8%/49.2%
O DeepSeek v3.1 supera marginalmente o Llama 4 Maverick