
O mundo dos grandes modelos de linguagem (LLMs) avança a uma velocidade vertiginosa, mas os desafios em eficiência e adaptabilidade em tempo real persistem. Em 10 de setembro de 2025, a Moonshot AI — a força inovadora por trás da série Kimi — lançou o checkpoint-engine, um middleware de código aberto que redefine as atualizações de peso em motores de inferência de LLMs. Adaptado para aprendizado por reforço (RL), esta ferramenta leve pode atualizar um gigante de 1 trilhão de parâmetros como o Kimi-K2 em milhares de GPUs em meros 20 segundos, reduzindo o tempo de inatividade e aumentando a escalabilidade.
Este artigo explora a mecânica do checkpoint-engine, desde sua arquitetura até seus benchmarks, enquanto destaca suas implicações para RL e seu encaixe no ecossistema mais amplo. Ao tornar esta joia de código aberto, a Moonshot AI capacita a comunidade a expandir ainda mais os limites dos LLMs. Vamos desvendar esta inovação camada por camada.
Compreendendo o Checkpoint-Engine: Conceitos Centrais e Arquitetura
O que é o Checkpoint-Engine?
Em sua essência, o checkpoint-engine é um middleware que facilita atualizações de peso contínuas e no local para LLMs durante a inferência. Isso é crucial em RL, onde os modelos evoluem através de feedback iterativo sem retreinamentos completos. Métodos tradicionais sobrecarregam os sistemas com recargas demoradas; o checkpoint-engine contraria isso com uma abordagem simplificada e de baixa sobrecarga.
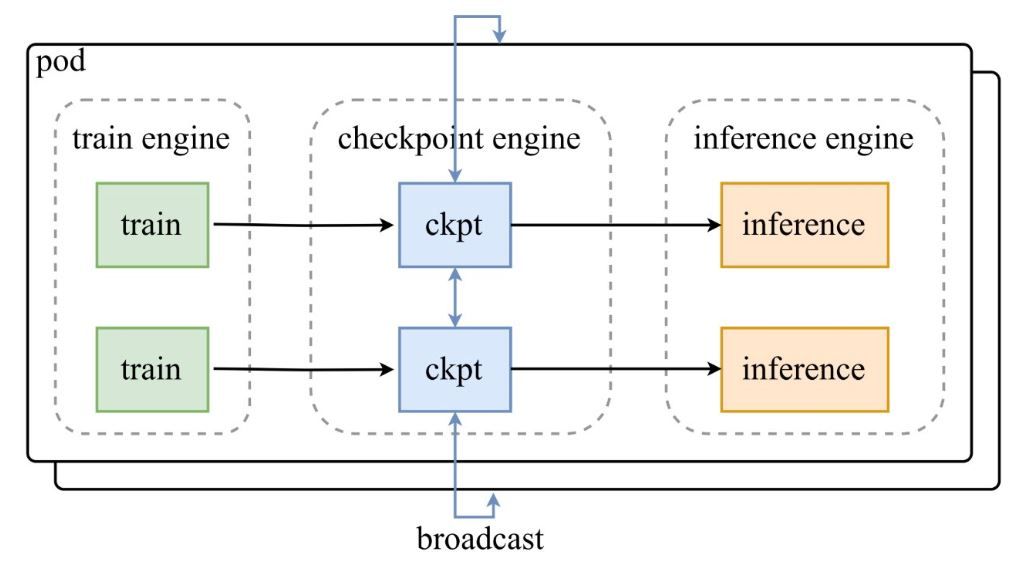
Como mostrado no diagrama de arquitetura do tweet de anúncio da Moonshot AI, um conjunto de motores de treinamento alimenta os checkpoints para o checkpoint-engine central, que então transmite as atualizações para os motores de inferência. O repositório do GitHub aprofunda-se no código, destacando a classe ParameterServer como o orquestrador de atualizações.
Componentes Arquitetônicos
- Motor de Treinamento (Train Engine): Produz novos pesos a partir do treinamento contínuo de RL, capturando refinamentos de política em ambientes dinâmicos.
- Checkpoint Engine: O núcleo do middleware, colocalizado com a inferência para latência mínima. Ele lida com a coleta de metadados e executa atualizações via modos Broadcast ou P2P.
- Motor de Inferência (Inference Engine): Integra atualizações em tempo real, mantendo a continuidade do serviço em clusters de GPU distribuídos.
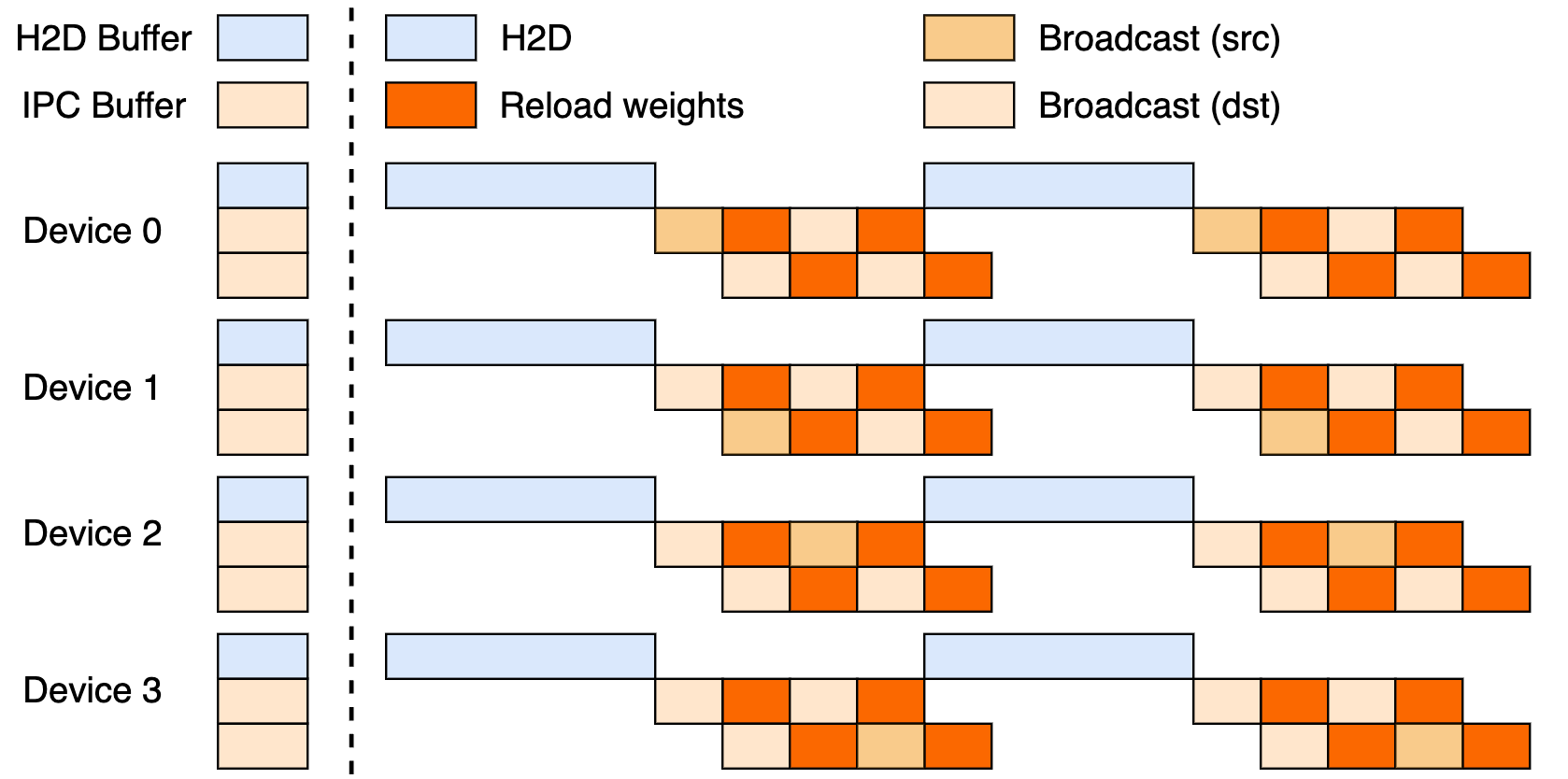
Esta configuração aproveita um pipeline de três estágios: transferências Host-to-Device (H2D), transmissões entre workers usando CUDA IPC e recargas direcionadas. Ao sobrepor esses estágios, ele maximiza a utilização da GPU e reduz gargalos de transferência.
Atualizações Broadcast vs. P2P
O Broadcast se destaca em atualizações síncronas e em todo o cluster — seu modo padrão para velocidade máxima, agrupando dados para um fluxo ideal. O P2P, por sua vez, sobressai em cenários elásticos, como escalar durante picos, usando RDMA via mooncake-transfer-engine para evitar interrupções. Essa dualidade torna o checkpoint-engine versátil para implantações estáveis e fluidas.
Benchmarks de Desempenho: Quão Rápido é Rápido o Suficiente?
Atualizando um Modelo de Um Trilhões de Parâmetros em 20 Segundos
O feito principal do checkpoint-engine? Atualizar os parâmetros de 1T do Kimi-K2 em milhares de GPUs em ~20 segundos. Isso decorre de um pipeline inteligente: o planejamento de metadados define tamanhos de bucket eficientes, os sockets ZeroMQ coordenam as transferências e os estágios H2D/broadcast sobrepostos ocultam latências.
Contraste isso com técnicas legadas, que podem deixar os sistemas ociosos por minutos em meio a grandes embaralhamentos de dados. O ethos in-place do checkpoint-engine mantém a inferência funcionando, ideal para a necessidade de adaptações rápidas do RL.
Análise de Benchmark
A tabela de benchmark revela resultados estelares em modelos e configurações, testados com vLLM v0.10.2rc1:
| Modelo | Info. do Dispositivo | Coletar Metadados | Atualização (Broadcast) | Atualização (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
Reproduza-os via examples/update.py do repositório. As execuções em FP8 exigem patches do vLLM, enfatizando a eficiência em escala.
Implicações para o Aprendizado por Reforço
O RL prospera em iterações rápidas; os ciclos de menos de 20 segundos do checkpoint-engine permitem loops de aprendizado contínuos, superando métodos em lote. Isso desbloqueia aplicativos responsivos — de agentes adaptativos a chatbots em evolução — onde cada segundo conta no ajuste de políticas.
Implementação Técnica: Mergulhando na Base de Código
Acessibilidade de Código Aberto
A disponibilização no GitHub da Moonshot AI democratiza ferramentas de RL de elite. O ParameterServer ancora as atualizações, oferecendo Broadcast (compartilhamento rápido via CUDA IPC) e P2P (RDMA para novos usuários). Exemplos como update.py e testes (test_update.py) facilitam a integração.
A compatibilidade começa com o vLLM (via extensões de worker), com ganchos para SGLang sendo considerados em seguida. O pipeline parcial de três estágios sugere um potencial inexplorado.
Técnicas de Otimização
- Sobreposições em Pipeline: Comunicação e cópias são executadas concorrentemente, reduzindo o tempo efetivo.
- Otimização de Buckets: Dimensionamento baseado em metadados ajusta-se a sharding e redes.
- Controle ZeroMQ: Sinalização de baixa latência para motores de inferência.
Estas abordam obstáculos de trilhões de parâmetros, desde conflitos de PCIe até compressões de memória (recorrendo ao serial, se necessário).
Limitações Atuais
O funil de rank-0 do P2P pode engasgar em escala, e o pipeline completo aguarda polimento. O foco no vLLM limita a abrangência, mas patches preenchem lacunas de FP8 para modelos como DeepSeek-V3.1. Fique de olho no repositório para evoluções.
Integração com Frameworks Existentes: vLLM e Além
Colaboração com vLLM
O checkpoint-engine se integra nativamente com o PagedAttention do vLLM para uma inferência RL suave. Essa dupla atinge sincronizações de 20 segundos em modelos de 1T, como sugerido nas atualizações do vLLM — um aceno à colaboração aberta que amplifica o throughput.
Extensões Potenciais para Claude e Apidog
Estender para o Claude da Anthropic poderia infundir dinamismo de RL em seus chats focados em segurança, permitindo ajustes finos em tempo real. O Apidog se encaixa perfeitamente para simulação de endpoints durante ajustes ZeroMQ — baixe o Apidog gratuitamente para prototipar essas pontes sem esforço.
Impacto no Ecossistema Mais Amplo
Conectar-se ao Ollama ou LM Studio poderia localizar o poder de trilhões de parâmetros, nivelando o campo para desenvolvedores independentes. Esse efeito cascata fomenta um cenário de IA mais inclusivo.
Perspectivas Futuras: O Que o Futuro Reserva para o Checkpoint-Engine?
Melhorias de Escalabilidade e Desempenho
A implementação completa do pipeline poderia reduzir ainda mais segundos, enquanto a descentralização P2P elimina gargalos para uma verdadeira elasticidade. Ajustes de RDMA prometem proeza nativa da nuvem.
Contribuições da Comunidade
O código aberto convida a correções e ports — pense em fusões SGLang ou modos agnósticos a PCIe. Respostas iniciais no tweet vibram com entusiasmo, impulsionando o momento.
Aplicações na Indústria
Da tradução em tempo real ao RL para carros autônomos, o checkpoint-engine se adapta a domínios com alta taxa de mudança. Sua velocidade mantém os modelos atualizados, superando rivais em agilidade.
Uma Nova Era para a Inferência de LLMs?
O checkpoint-engine anuncia futuros ágeis para LLMs, abordando problemas de peso com um toque de código aberto. Essa atualização de 1T em 20 segundos, apoiada por uma arquitetura inteligente e benchmarks, consolida seu trono no RL — apesar das limitações.
Combine-o com o Apidog para fluxos de desenvolvimento ou com o Claude para inteligência híbrida, e a inovação dispara. Acompanhe o GitHub, pegue o Apidog gratuitamente e junte-se à revolução que está remodelando a inferência hoje!