
Desenvolvedores buscam maneiras eficientes de integrar modelos de linguagem avançados em suas aplicações. O INTELLECT-3 surge como uma opção atraente devido à sua base de código aberto e forte desempenho em tarefas de raciocínio. Este modelo, desenvolvido pela Prime Intellect, destaca-se por sua arquitetura Mixture-of-Experts (MoE) de 106 bilhões de parâmetros, que permite alta eficiência no manuseio de computações complexas.
Compreendendo o INTELLECT-3: A Potência de Código Aberto
A Prime Intellect lança o INTELLECT-3 como um modelo totalmente de código aberto, o que capacita pesquisadores e desenvolvedores a personalizar e estender suas capacidades sem barreiras proprietárias. Essa transparência fomenta a inovação em áreas como aprendizado por reforço (RL) e sistemas de IA agênticos. Você acessa o pacote completo, incluindo pesos do modelo, frameworks de treinamento, conjuntos de dados, ambientes de RL e ferramentas de avaliação, diretamente dos repositórios da Prime Intellect.

Em sua essência, o INTELLECT-3 emprega uma arquitetura MoE de 106 bilhões de parâmetros, construída sobre o modelo base GLM-4.5-Air. Designs MoE direcionam entradas para sub-redes "especialistas" especializadas, o que otimiza o uso computacional e acelera a inferência. Por exemplo, durante o processamento, o modelo ativa apenas um subconjunto de parâmetros relevantes para a consulta, reduzindo a latência e mantendo a precisão. Essa configuração se mostra particularmente eficaz para tarefas que exigem expertise seletiva, como derivações matemáticas ou geração de código.
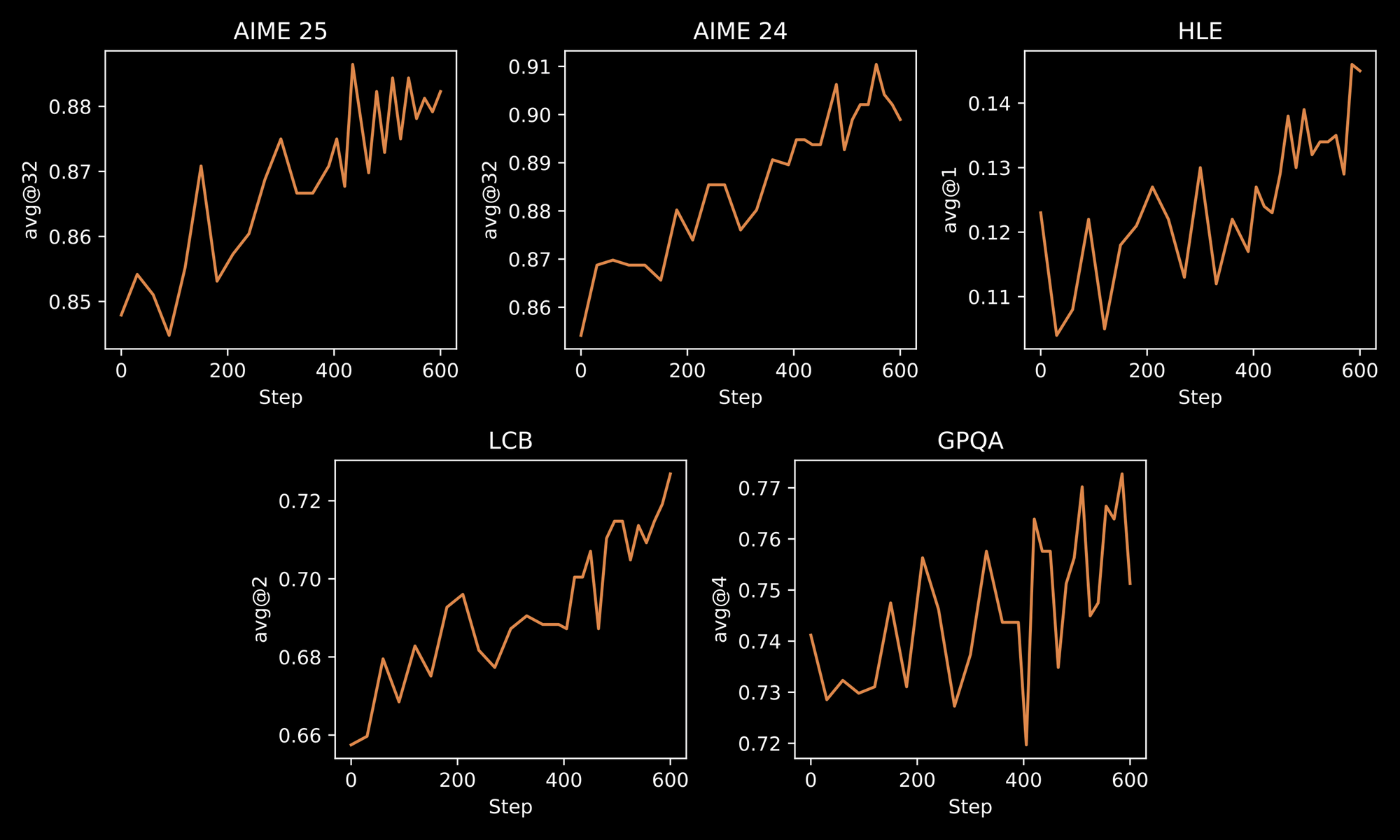
O processo de treinamento ressalta a robustez do INTELLECT-3. Engenheiros aplicam uma metodologia de duas etapas: um Super Fine-Tuning Supervisionado (SFT) inicial em conjuntos de dados selecionados, seguido por RL em larga escala usando o framework personalizado prime-rl. O prime-rl opera como um sistema de RL assíncrono fora da política, que lida com vastas simulações paralelas de forma eficiente. Você se beneficia disso através de comportamentos de modelo aprimorados em ambientes dinâmicos, como resolução iterativa de problemas ou planejamento multi-etapas.
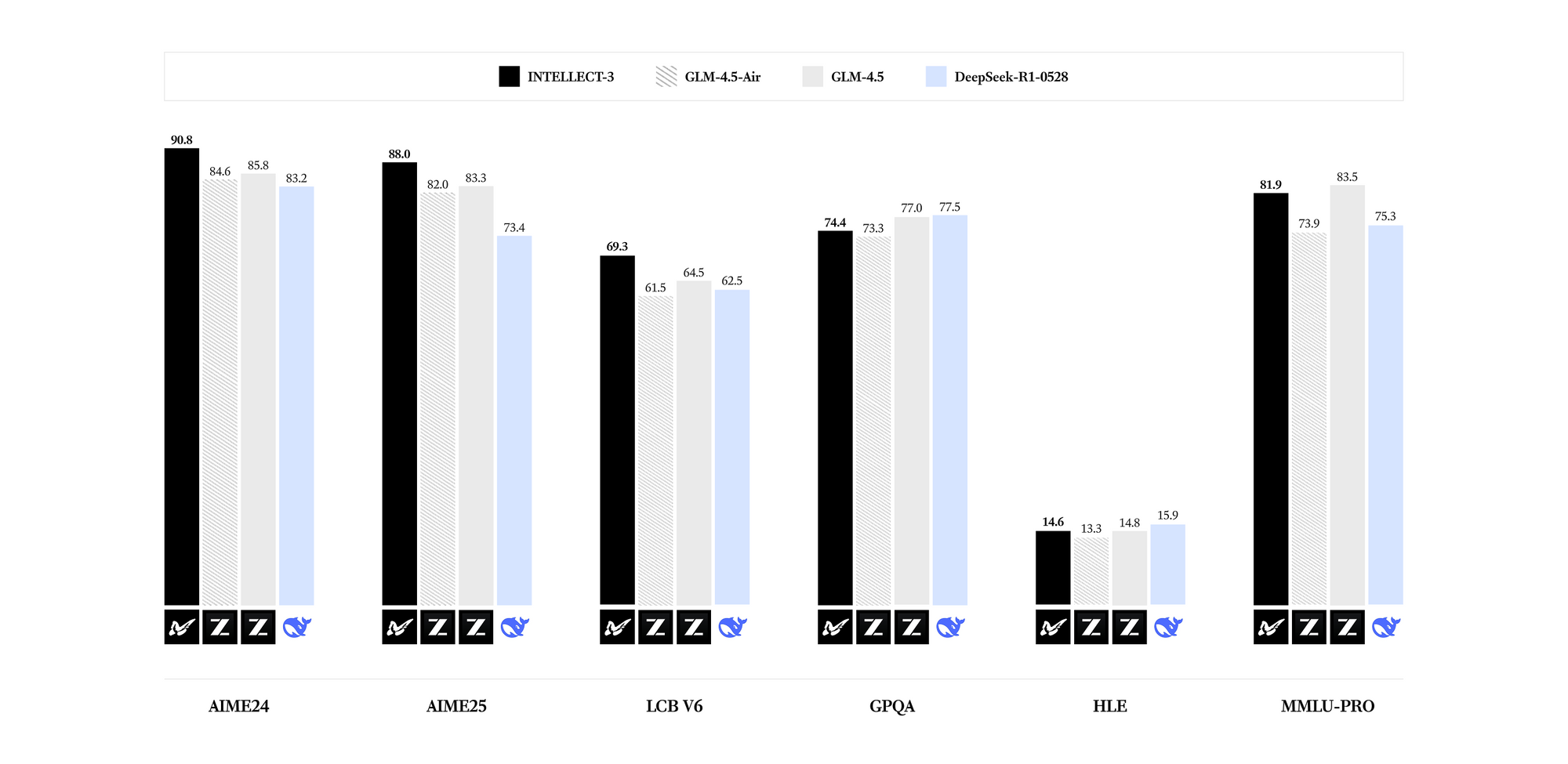
O INTELLECT-3 se destaca em domínios especializados. Benchmarks revelam resultados de ponta para sua contagem de parâmetros em matemática (por exemplo, pontuações GSM8K excedendo 95%), codificação (taxas de aprovação HumanEval acima de 85%), ciência (precisão GPQA acima de 60%) e raciocínio (pontuações MMLU próximas de 80%). Comparado a modelos mais densos como Llama 3.1 70B, o INTELLECT-3 alcança eficiência superior – inferência até 2x mais rápida em hardware equivalente – devido aos seus padrões de ativação esparsos. Consequentemente, você o implanta em ambientes com recursos limitados sem sacrificar a qualidade da saída.
A infraestrutura de suporte aprimora seu apelo de código aberto. O Hub de Verificadores e Ambientes fornece mais de 500 ambientes de RL, desde quebra-cabeças simples até provadores de teoremas avançados.
Os Prime Sandboxes oferecem execução de código segura e de alta vazão, que isola as ações do agente durante o treinamento ou a inferência. Desenvolvedores utilizam essas ferramentas para otimizar o INTELLECT-3 para aplicações personalizadas, como agentes autônomos em pipelines de desenvolvimento de software.
Na prática, você baixa os pesos do modelo via Hugging Face ou GitHub da Prime Intellect. A instalação requer dependências padrão como PyTorch e a biblioteca Transformers. Um script básico para carregar o modelo se parece com isto:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
Este código inicializa o modelo em hardware habilitado para GPU. No entanto, para uso em escala de produção, você faz a transição para APIs hospedadas, já que a hospedagem própria exige computação significativa (por exemplo, múltiplas GPUs A100). Assim, o acesso de código aberto estabelece as bases, mas a integração de API dimensiona suas implantações de forma eficaz.
Em transição da experimentação local, você agora explora como acessar o INTELLECT-3 através de serviços gerenciados. Essa mudança garante confiabilidade e lida com as complexidades da inferência distribuída.
Acessando a API do INTELLECT-3: Configuração e Autenticação
Opção 1 – Endpoint Nativo Prime Intellect (Recomendado para desempenho máximo e menor latência)
Você inicia o acesso à API obtendo credenciais da plataforma da Prime Intellect. Visite o painel da Prime Intellect em app.primeintellect.ai e crie uma conta, se necessário.
Uma vez logado, navegue até a seção de chaves de API e gere uma nova chave com as permissões de Inferência ativadas. Esta chave autentica todas as requisições subsequentes, garantindo acesso seguro ao INTELLECT-3.
Em seguida, configure seu ambiente. Defina a chave da API como uma variável de ambiente para integração perfeita:
export PRIME_API_KEY="your-api-key-here"
Para fluxos de trabalho baseados em equipe, inclua o cabeçalho X-Prime-Team-ID nas requisições. Este identificador direciona o uso para o pool de faturamento correto, evitando cobranças entre contas. Você recupera o ID da equipe no painel, em configurações da conta.
A API adota uma interface compatível com OpenAI, o que simplifica a adoção se você já usa bibliotecas como openai-python. Especifique a URL base como https://api.pinference.ai/api/v1. Este endpoint atua como proxy para provedores de inferência otimizados, incluindo Parasail e Nebius, que hospedam instâncias do INTELLECT-3. Como resultado, você obtém respostas de baixa latência sem gerenciar clusters subjacentes.
Para verificar o acesso, consulte o endpoint de modelos. Isso lista os modelos disponíveis, confirmando a presença do INTELLECT-3 (tipicamente sob um identificador como prime-intellect/intellect-3). Use a ferramenta CLI para verificações rápidas:
prime inference models
Alternativamente, envie uma requisição GET via curl:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
A resposta retorna um array JSON de objetos de modelo, cada um detalhando parâmetros como id, max_tokens e context_window. O INTELLECT-3 suporta um contexto de 128K tokens, que acomoda cadeias de raciocínio longas.
A autenticação se estende à limitação de taxa e cotas. A Prime Intellect impõe limites por minuto e diários com base no seu plano, visíveis no painel. Você monitora o uso através da aba Faturamento, que registra os tokens processados e as chamadas de API realizadas. Se os limites atrapalharem seu fluxo de trabalho, faça um upgrade sem interrupções pela plataforma.
Além disso, integre-se com o Apidog para testes aprimorados. Importe o esquema OpenAI para o Apidog e, em seguida, simule requisições para os endpoints do INTELLECT-3. Essa prática identifica problemas precocemente, como payloads JSON malformados. O nível gratuito do Apidog é suficiente para configurações iniciais, fazendo a ponte entre o desenvolvimento local e as APIs de produção.
Com a autenticação em vigor, você prossegue para a elaboração de requisições. A seção a seguir descreve formatos precisos para obter respostas ideais do INTELLECT-3.
Opção 2 – OpenRouter (Acesso instantâneo e créditos unificados)
Além da auto-hospedagem ou do uso da plataforma de inferência nativa da Prime Intellect, o INTELLECT-3 também está oficialmente disponível no OpenRouter. Isso lhe oferece um gateway alternativo com faturamento unificado, roteamento de fallback automático e acesso instantâneo — sem necessidade de uma conta separada da Prime Intellect se você já usa o OpenRouter.
- URL Base: https://openrouter.ai/api/v1
- Nome do modelo: prime-intellect/intellect-3
- Autenticação: Sua chave de API OpenRouter (OPENROUTER_API_KEY)
- Roteamento automático do provedor (atualmente servido por clusters da Prime Intellect)
- Pagamento conforme o uso com créditos OpenRouter; custo por token ligeiramente mais alto devido à taxa da plataforma
Ambos os endpoints suportam esquemas idênticos de requisição/resposta, streaming, chamada de ferramentas e modo JSON.
Realizando Requisições à API do INTELLECT-3: Formatos e Exemplos
Você inicia interações através do endpoint /chat/completions, que lida com prompts conversacionais e orientados a tarefas. Construa requisições como objetos JSON com campos para model, messages, temperature e max_tokens. O array messages mimetiza históricos de chat, usando papéis como "system", "user" e "assistant".
Considere um exemplo básico para geração de código. Você envia:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
Este código gera uma implementação recursiva de Fibonacci com memoização, aproveitando a capacidade de codificação do INTELLECT-3. O parâmetro temperature controla a criatividade — valores mais baixos (por exemplo, 0.2) favorecem saídas determinísticas para consultas factuais, enquanto valores mais altos (até 1.0) incentivam caminhos de raciocínio diversos.
Para raciocínio matemático, você estrutura prompts para encadear pensamentos. O treinamento de RL do INTELLECT-3 se destaca aqui, pois simula a verificação passo a passo. Exemplo:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
O modelo responde com uma prova rigorosa, citando axiomas e teoremas. Você analisa a saída via response.choices[0].message.content, que chega como uma string. Para dados estruturados, ative o modo JSON adicionando "response_format": {"type": "json_object"} à requisição, garantindo respostas analisáveis.
O uso avançado envolve a chamada de ferramentas, onde o INTELLECT-3 integra funções externas. Defina ferramentas na requisição:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
Se o modelo invocar a ferramenta, ele retorna argumentos em response.choices[0].message.tool_calls. Você executa a função externamente e alimenta os resultados de volta em uma mensagem de acompanhamento. Este padrão constrói fluxos de trabalho agênticos, capitalizando nos comportamentos do INTELLECT-3 treinados no ambiente.
O tratamento de erros é uma parte crítica. Problemas comuns incluem 401 (chave inválida), 429 (limite de taxa) e 400 (requisição malformada). Implemente tentativas com espera exponencial:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
As respostas incluem metadados como usage (prompt_tokens, completion_tokens, total_tokens), que você registra para otimização. O INTELLECT-3 processa até 4096 tokens por conclusão, equilibrando profundidade e velocidade.
Respostas em streaming aprimoram aplicações em tempo real. Adicione stream=True à chamada de criação; o cliente gera chunks como Server-Sent Events. Analise-os iterativamente:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Esta técnica é adequada para chatbots ou assistentes de código ao vivo, onde os usuários esperam feedback incremental.
Tendo dominado a criação de requisições, você avalia o desempenho. O próximo segmento apresenta ferramentas de benchmark personalizadas para o INTELLECT-3.
Otimizando e Avaliando o Uso da API do INTELLECT-3
Você otimiza as chamadas de API ajustando parâmetros empiricamente. Comece com o agrupamento de múltiplas mensagens em uma única requisição para ganhos de throughput — até 10x de eficiência em suites de avaliação. O CLI da Prime Intellect suporta isso:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
Este comando executa 100 amostras GSM8K, agregando métricas de precisão e latência. Você analisa os resultados para ajustar top_p ou frequency_penalty, que atenuam a repetição em gerações longas.
A avaliação se estende a ambientes personalizados do Verifiers Hub. Carregue um ambiente de RL e consulte o INTELLECT-3 como a política:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
Recompensas quantificam melhorias, guiando o ajuste fino se você hospedar localmente. Para usuários apenas de API, registre interações em um banco de dados vetorial e calcule métricas de downstream como a taxa de sucesso da tarefa.
Considerações de segurança também são importantes. Limpe as entradas do usuário para prevenir injeção de prompt e use prompts de sistema para impor limites. O histórico de RL do INTELLECT-3 reduz alucinações, mas você deve validar as saídas contra verificadores para aplicações de alto risco.
O escalonamento envolve monitoramento via painel. Configure alertas para limites de token e integre-se com ferramentas de observabilidade como o Prometheus, que a Prime Intellect expõe para clusters. Assim, você mantém a confiabilidade à medida que o uso cresce.
Agora que você lida com a otimização, considere os custos. A transparência nos preços garante uma integração sustentável.
Preços da API do INTELLECT-3: Modelo Transparente Baseado em Token
A Prime Intellect estrutura os preços com base no consumo de tokens, cobrando separadamente por entrada e saída. Você paga por 1.000 tokens, com taxas variando por modelo e provedor. Para o INTELLECT-3, espere valores competitivos — cerca de US$ 0,50 por milhão de tokens de entrada e US$ 1,50 por milhão de saída — embora os valores exatos apareçam na resposta do endpoint de modelos.
| Provedor | Entrada (US$ /1M tokens) | Saída ( US$ /1M tokens) | Notas |
|---|---|---|---|
| Prime Intellect Direto | ~US$0.45–US$0.60 | ~US$1.30–US$1.80 | Menor custo, descontos por volume |
| OpenRouter | ~US$0.60–US$0.80 | ~US$1.80–US$2.40 | Inclui taxa de plataforma OpenRouter |
As taxas exatas flutuam; verifique sempre os valores mais recentes no seu painel ou através do endpoint de modelos.
Qual Você Deve Escolher?
- Escolha Prime Intellect direto se você busca velocidade máxima, menor custo ou planeja uso de alto volume.
- Escolha OpenRouter se você prefere uma única chave de API para mais de 50 modelos, precisa de onboarding instantâneo ou deseja roteamento de fallback integrado.
Ambas as opções entregam o mesmo desempenho do INTELLECT-3. Escolha a que melhor se adapta ao seu fluxo de trabalho — muitas equipes até usam ambas simultaneamente para redundância.
O restante deste guia (formatos de requisição, streaming, chamada de ferramentas, otimização, etc.) se aplica igualmente, seja você chamando a Prime Intellect diretamente ou via OpenRouter.
Continue com os detalhes completos da implementação técnica abaixo e comece a construir com o INTELLECT-3 hoje — através do gateway que melhor funcionar para você.
Integrações Avançadas com a API do INTELLECT-3
Você estende o INTELLECT-3 para ecossistemas como LangChain ou LlamaIndex para orquestração. No LangChain:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
Isso conecta a API a pipelines de geração aumentada por recuperação (RAG), aprimorando a precisão com conhecimento externo.
Para microsserviços, implante via wrappers FastAPI que atuam como proxy para o INTELLECT-3:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
Exponha este endpoint de forma segura, com limitação de taxa usando Redis. Tais configurações alimentam ferramentas SaaS, desde geradores de conteúdo até assistentes de pesquisa.
Casos extremos exigem atenção. Lide com transbordamentos de token truncando as entradas dinamicamente e faça fallback para modelos menores se o INTELLECT-3 estiver em fila. Fóruns da comunidade no site da Prime Intellect oferecem tópicos de solução de problemas.
Conclusão: Implante a API do INTELLECT-3 com Confiança
Você agora possui um conjunto de ferramentas abrangente para o uso da API do INTELLECT-3. Desde suas raízes de código aberto até o tratamento preciso de requisições e a gestão de custos, este guia o capacita para implantações no mundo real. Experimente o Apidog para refinar seus fluxos de trabalho e monitore a documentação em evolução para atualizações.
Implemente essas técnicas incrementalmente — comece com chats simples, depois dimensione para agentes. A eficiência e a abertura do INTELLECT-3 o posicionam como uma escolha ideal para projetos de IA técnicos. Comece a codificar hoje e testemunhe o impacto em suas aplicações.