
Desenvolvedores buscam constantemente maneiras eficientes de integrar modelos avançados de IA em suas aplicações, e o Qwen Next surge como uma opção atraente. Este modelo, parte da série Qwen da Alibaba, oferece uma arquitetura esparsa de Mistura de Especialistas (MoE) que ativa apenas uma fração de seus parâmetros durante a inferência. Como resultado, você obtém tempos de processamento mais rápidos e custos mais baixos sem sacrificar o desempenho.
Compreendendo a Arquitetura Central do Qwen Next e Por Que Ela é Importante para Usuários de API
Qwen Next possui uma arquitetura híbrida que combina mecanismos de gating com normalização avançada, otimizando-o para tarefas orientadas por API. Sua camada MoE roteia entradas para 10 de 512 especialistas especializados por token, mais um especialista compartilhado, ativando apenas 3 bilhões de parâmetros. Essa esparsidade reduz as demandas de recursos, permitindo inferência mais rápida para usuários da API Qwen.

Além disso, o modelo emprega atenção de produto escalar com Embeddings de Posição Rotacional (RoPE) parciais, preservando o contexto em sequências de até 128K tokens. Camadas RMSNorm com centro zero estabilizam gradientes, garantindo saídas confiáveis durante chamadas de API de alto volume. O caminho DeltaNet, com um fator de expansão de 3x, usa normalização L2, camadas convolucionais e ativações SiLU para suportar decodificação especulativa, gerando múltiplos tokens simultaneamente.
Para desenvolvedores, isso significa que a Integração Next em aplicações como ferramentas de análise de documentos é eficiente e escalável. A modularidade da arquitetura permite o ajuste fino para domínios como finanças, tornando-a adaptável via API Qwen. Em seguida, examinaremos como esses recursos se traduzem em desempenho mensurável.
Avaliando Benchmarks de Desempenho para Qwen Next em Aplicações Orientadas por API
Desenvolvedores que integram o Qwen Next em fluxos de trabalho orientados por API priorizam modelos que equilibram alto desempenho com eficiência computacional. O Qwen3-Next-80B-A3B, com sua arquitetura esparsa de Mistura de Especialistas (MoE) ativando apenas 3 bilhões de parâmetros durante a inferência, se destaca neste domínio. Esta seção avalia os principais benchmarks, destacando como o Qwen Next supera contrapartes mais densas como o Qwen3-32B, ao mesmo tempo em que oferece velocidades de inferência superiores — cruciais para respostas de API em tempo real. Ao examinar métricas em conhecimento geral, codificação, raciocínio e tarefas de contexto longo, você obtém insights sobre sua adequação para aplicações escaláveis.
Eficiência de Pré-Treinamento e Desempenho do Modelo Base
O pré-treinamento do Qwen Next demonstra notável eficiência. Treinado em um subconjunto de 15 trilhões de tokens do corpus de 36 trilhões de tokens do Qwen3, o modelo Qwen3-Next-80B-A3B-Base consome menos de 80% das horas de GPU exigidas pelo Qwen3-30B-A3B e apenas 9,3% do custo computacional do Qwen3-32B. Apesar disso, ele ativa apenas um décimo dos parâmetros não-embedding usados pelo Qwen3-32B-Base, mas o supera na maioria dos benchmarks padrão e supera significativamente o Qwen3-30B-A3B.
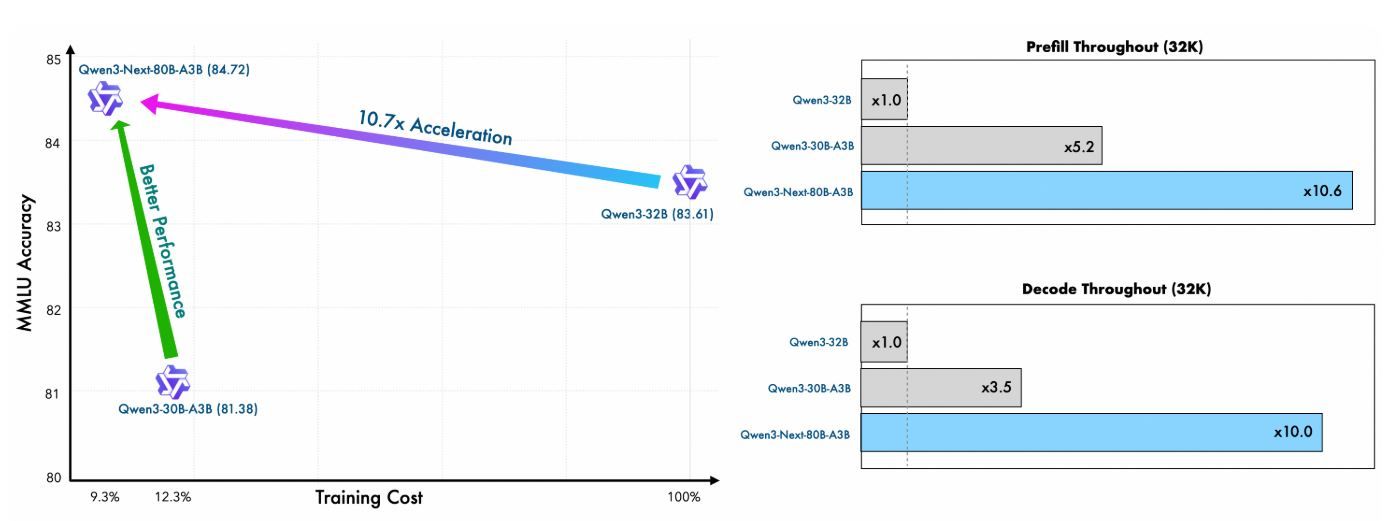
Essa eficiência decorre da arquitetura híbrida — combinando Gated DeltaNet (75% das camadas) com Gated Attention (25%) — que otimiza tanto a estabilidade do treinamento quanto o throughput da inferência. Para usuários de API, isso se traduz em custos de implantação mais baixos e prototipagem mais rápida, pois o modelo alcança melhor perplexidade e redução de perdas com menos recursos.
Métrica | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Qwen3-30B-A3B-Base |
|---|---|---|---|
Horas de GPU de Treinamento (% de Qwen3-32B) | 9.3% | 100% | ~125% |
Razão de Parâmetros Ativos | 10% | 100% | 10% |
Superação de Benchmark | Supera na maioria | Linha de Base | Significativamente melhor |
Esses números destacam o valor do Qwen Next em ambientes de API com recursos limitados, onde o treinamento de variantes personalizadas via ajuste fino permanece viável.
Velocidade de Inferência: Estágios de Pré-preenchimento e Decodificação para Latência de API
A velocidade de inferência impacta diretamente os tempos de resposta da API, especialmente em cenários de alto throughput, como serviços de chat ou geração de conteúdo. O Qwen Next se destaca aqui, aproveitando seu MoE ultra-esparso (512 especialistas, roteando 10 + 1 compartilhado) e Multi-Token Prediction (MTP) para decodificação especulativa.
No estágio de pré-preenchimento (processamento de prompt), o Qwen Next alcança um throughput quase 7x maior do que o Qwen3-32B em comprimentos de contexto de 4K. Além de 32K tokens, essa vantagem excede 10x, tornando-o ideal para APIs de análise de documentos longos.
Para o estágio de decodificação (geração de tokens), o throughput atinge quase 4x em contextos de 4K e mais de 10x em comprimentos maiores. O mecanismo MTP, otimizado para consistência multi-passos, aumenta as taxas de aceitação na decodificação especulativa, acelerando ainda mais a inferência no mundo real.
Comprimento do Contexto | Throughput de Pré-preenchimento (vs. Qwen3-32B) | Throughput de Decodificação (vs. Qwen3-32B) |
|---|---|---|
4K Tokens | 7x Mais Rápido | 4x Mais Rápido |
>32K Tokens | >10x Mais Rápido | >10x Mais Rápido |
Desenvolvedores de API se beneficiam imensamente: latência reduzida permite respostas em sub-segundos em produção, enquanto a eficiência energética (ao ativar apenas 3,7% dos parâmetros) reduz os custos da nuvem. Frameworks como vLLM e SGLang amplificam esses ganhos, suportando até 256K contextos com paralelismo de tensor.
Fazendo Sua Primeira Chamada de API com Qwen Next: Uma Implementação Passo a Passo
Para aproveitar as capacidades do Qwen Next, siga estes passos claros e acionáveis para configurar e executar chamadas da API Qwen através da plataforma DashScope da Alibaba. Este guia garante que você possa integrar o modelo de forma eficiente, seja para consultas simples ou cenários complexos de Integração Next.
Passo 1: Crie uma Conta Alibaba Cloud e Acesse o Model Studio
Comece registrando-se para uma conta Alibaba Cloud em alibabacloud.com. Após verificar sua conta, navegue até o console do Model Studio dentro da plataforma DashScope. Selecione Qwen3-Next-80B-A3B na lista de modelos, escolhendo a variante base, instruct ou thinking com base no seu caso de uso — por exemplo, instruct para tarefas conversacionais ou thinking para raciocínio complexo.
Passo 2: Gere e Proteja Sua Chave de API
No painel do DashScope, localize a seção “API Keys” e gere uma nova chave. Esta chave autentica suas solicitações da API Qwen. Observe os limites de taxa: o nível gratuito oferece 1 milhão de tokens mensais, suficiente para testes iniciais. Armazene a chave com segurança em uma variável de ambiente para evitar exposição:
bash
export DASHSCOPE_API_KEY='sua_chave_aqui'Essa prática mantém seu código portátil e seguro.
Passo 3: Instale o SDK Python do DashScope
Instale o SDK do DashScope para simplificar as interações da API Qwen. Execute o seguinte comando em seu terminal:
bash
pip install dashscopeO SDK lida com serialização, retentativas e análise de erros, otimizando seu processo de integração. Alternativamente, use clientes HTTP como requests para configurações personalizadas, mas o SDK é recomendado para maior facilidade.
Passo 4: Configure o Endpoint da API
Para clientes compatíveis com OpenAI, defina a URL base para:
text
https://dashscope.aliyuncs.com/compatible-mode/v1Para chamadas nativas do DashScope, use:
text
https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generationInclua sua chave de API no cabeçalho da solicitação como X-DashScope-API-Key. Essa configuração garante o roteamento adequado para o Qwen Next.
Passo 5: Faça Sua Primeira Chamada de API
Crie uma solicitação de geração básica usando a variante instruct. Abaixo está um script Python para consultar o Qwen Next:
python
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'sua_chave_api'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explique os benefícios das arquiteturas MoE em LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Erro: {response.message}")Este script envia um prompt, limita a saída a 200 tokens e controla a criatividade com temperature=0.7. Um código de status 200 indica sucesso; caso contrário, lide com erros como limites de cota (código 10402).
Passo 6: Implemente Streaming para Respostas em Tempo Real
Para aplicações que exigem feedback imediato, use streaming:
python
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Gere uma função Python para análise de sentimento.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Erro: {response.message}")
breakIsso entrega a saída token por token, perfeito para interfaces de chat ao vivo na Integração Next.
Passo 7: Adicione Chamada de Função para Fluxos de Trabalho Agentes
Estenda a funcionalidade com integração de ferramentas. Defina um esquema JSON para uma ferramenta, como recuperação de clima:
python
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obter o clima atual",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Qual é o clima em Pequim?',
tools=tools,
tool_choice='auto'
)A API Qwen analisa o prompt, acionando a chamada da ferramenta. Execute a função externamente e alimente os resultados de volta.
Passo 8: Teste e Valide com Apidog
Use o Apidog para testar suas chamadas de API. Importe o esquema DashScope para um novo projeto Apidog, adicione o endpoint e inclua sua chave de API no cabeçalho. Crie um corpo JSON com seu prompt e, em seguida, execute casos de teste para verificar as respostas. O Apidog gera métricas como latência e sugere casos de borda, aumentando a confiabilidade.
Passo 9: Monitore e Depure Respostas
Verifique os códigos de resposta para erros (por exemplo, 429 para limites de taxa). Registre as saídas anonimizadas para auditoria. Use os painéis do Apidog para rastrear o uso de tokens e os tempos de resposta, garantindo que suas chamadas da API Qwen permaneçam dentro das cotas.
Esses passos fornecem uma base robusta para integrar o Qwen Next. Em seguida, otimize seus testes com o Apidog.
Aproveitando a Chamada de Função na API Qwen Next para Fluxos de Trabalho Agentes
A chamada de função estende a utilidade do Qwen Next além da geração de texto. Defina ferramentas em esquema JSON, especificando nomes, descrições e parâmetros. Para consultas meteorológicas, descreva uma função get_weather com um parâmetro city.
Em sua chamada de API, inclua o array de ferramentas e defina tool_choice como 'auto'. O modelo analisa o prompt, identificando intenções e retornando chamadas de ferramentas. Execute a função externamente, alimentando os resultados de volta para as respostas finais.
Esse padrão cria sistemas agentes, onde o Qwen Next orquestra múltiplas ferramentas. Por exemplo, combine dados meteorológicos com análise de sentimento para recomendações personalizadas. A API Qwen lida com a análise de forma eficiente, reduzindo a necessidade de código personalizado.
Otimize validando estritamente os esquemas. Garanta que os parâmetros correspondam aos tipos esperados para evitar erros de tempo de execução. Ao integrar, teste essas chamadas minuciosamente — ferramentas como o Apidog se mostram inestimáveis aqui, simulando respostas sem chamadas de API ao vivo.
Integrando o Apidog para Testes e Documentação Eficientes da API Qwen
Este guia fornece um fluxo de trabalho abrangente para integrar o Apidog com a API Qwen (Qwen Next/3.0 da Alibaba Cloud) para testes eficientes, documentação e gerenciamento do ciclo de vida da API.
Fase 1: Configuração Inicial e da Conta
Passo 1: Configuração da Conta
1.1 Crie as Contas Necessárias
1. Conta Alibaba Cloud
2. Visite: https://www.alibabacloud.com
3. Registre-se e complete a verificação
4. Habilite o serviço "Model Studio"
5. Conta Apidog
6. Visite: https://apidog.com
7. Cadastre-se com e-mail/Google/GitHub
1.2 Obtenha as Credenciais da API Qwen
1. Navegue até: Console Alibaba Cloud → Model Studio → API Keys
2. Crie uma nova chave: qwen-testing-key
3. Salve sua chave: sk-[sua-chave-real-aqui]

1.3 Crie um Projeto Apidog
- Faça login no Apidog → Clique em "New Project"
2. Configure o Projeto :
1. Nome do Projeto: Qwen API Integration
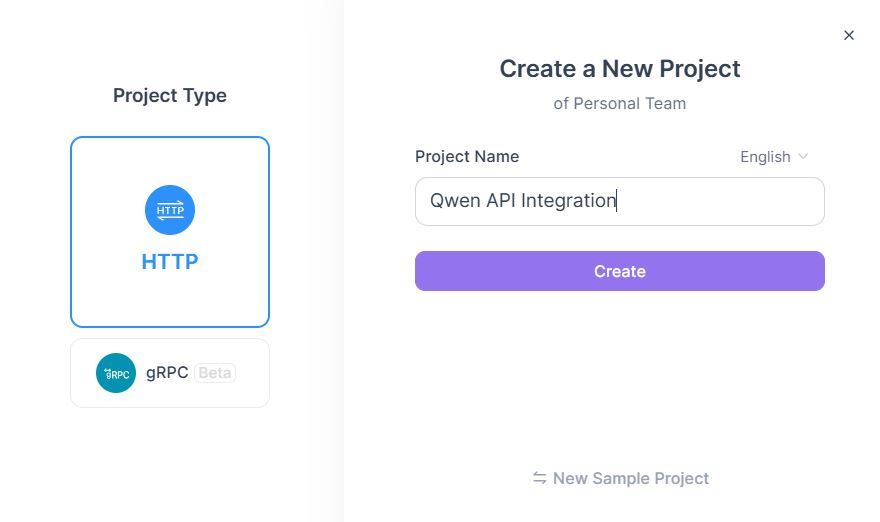
2. Descrição: Qwen Next API testing & documentation
Fase 2: Importação e Configuração da API
Passo 2: Importar Especificações da API Qwen
Método A: Criação Manual de API
- Adicionar Nova API → "Create API Manually"
- Configurar Endpoint de Chat Qwen :

3. Definir Configuração de Solicitação :
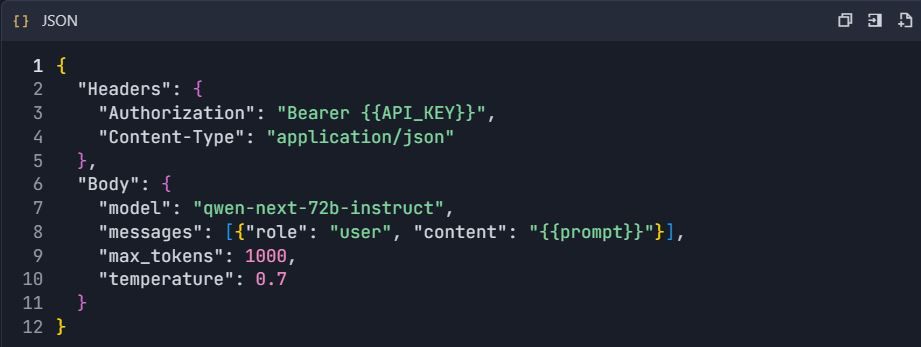
Método B: Importação OpenAPI
- Baixe a especificação OpenAPI do Qwen (se disponível)
- Vá para Projeto → "Import" → "OpenAPI/Swagger"
- Faça upload do arquivo de especificação → "Import"
Fase 3: Configuração de Ambiente e Autenticação
Passo 3: Configurar Ambientes
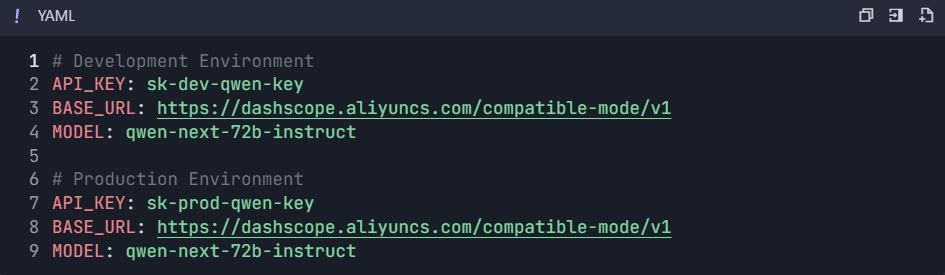
3.1 Criar Variáveis de Ambiente
- Vá para Configurações do Projeto → "Environments"
- Crie ambientes :
Fase 4: Suíte de Testes Abrangente
Passo 4: Criar Cenários de Teste
4.1 Teste Básico de Geração de Texto
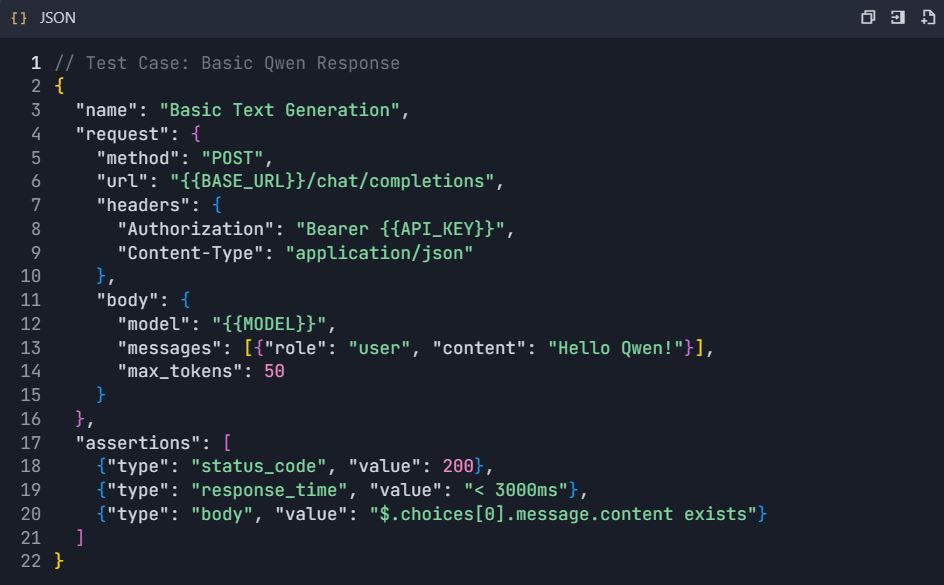
4.2 Cenários de Teste Avançados
Suíte de Testes: Testes Abrangentes da API Qwen
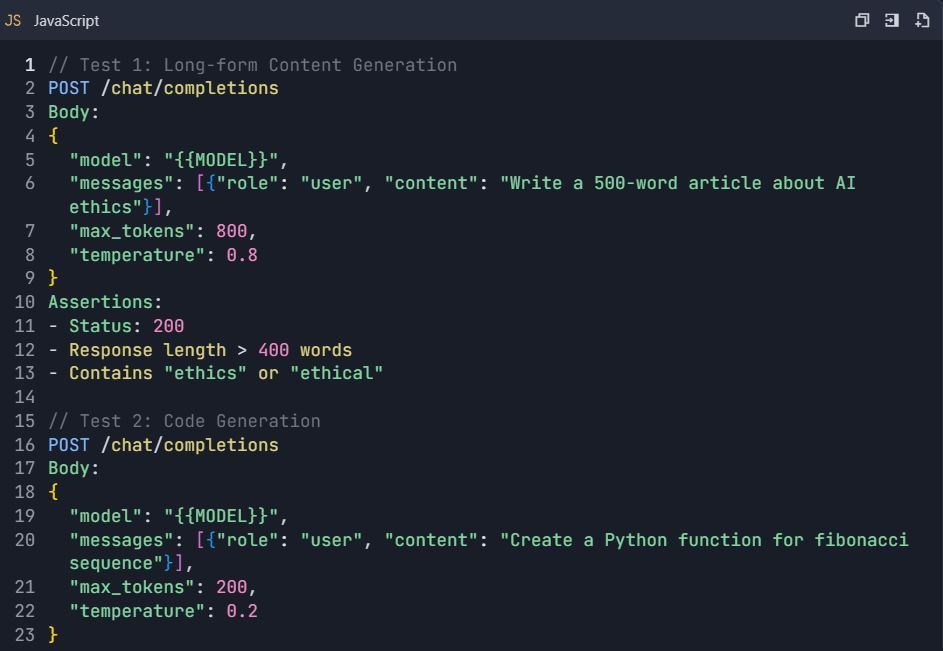
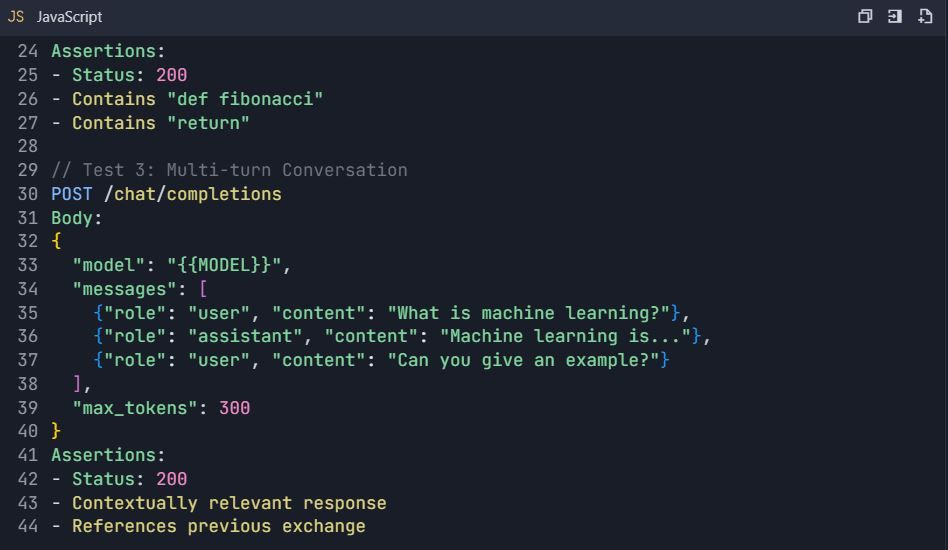
4.3 Testes de Tratamento de Erros
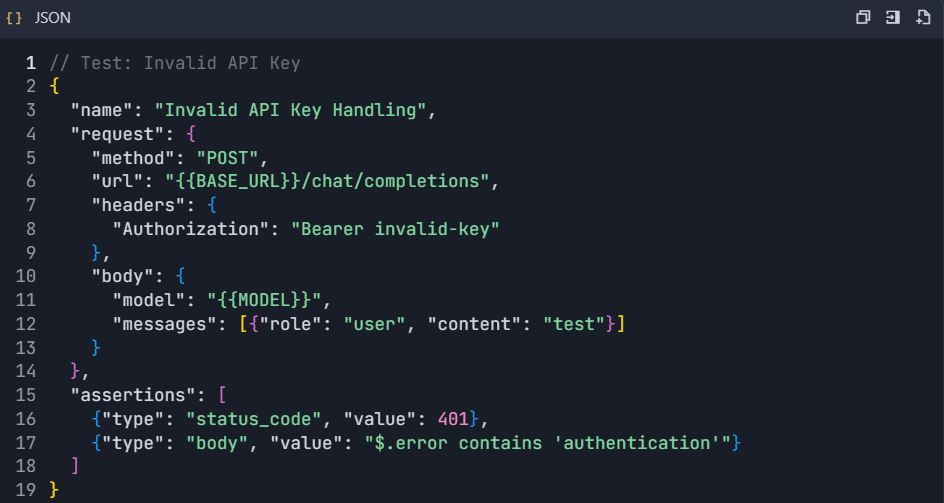
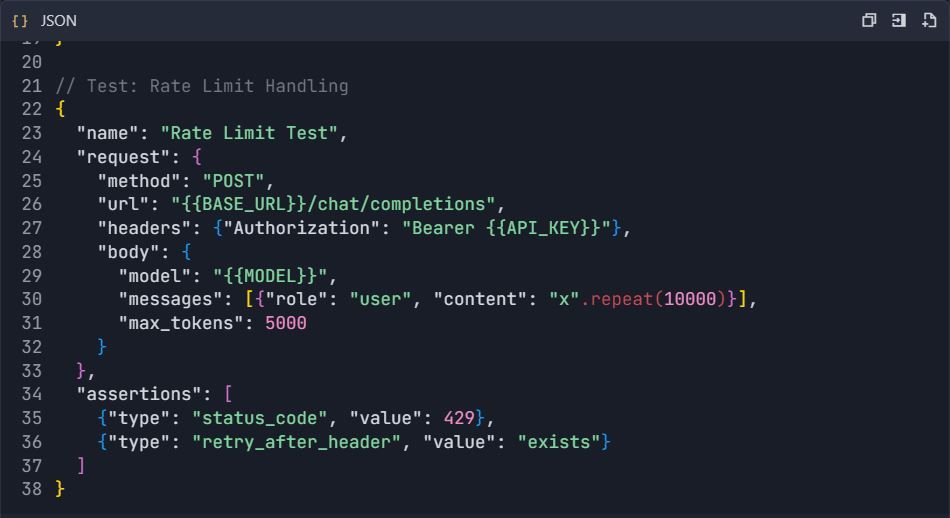
Fase 5: Geração de Documentação
Passo 5: Geração Automática de Documentação da API 5.1 Criar Estrutura de Documentação
- Vá para Projeto → "Documentation"
- Crie seções :
https://dashscope.aliyuncs.com/compatible-mode/v1

Autorização: Bearer sk-[sua-chave-api]

5.2 Explorador Interativo de API
- Configure exemplos interativos:
Fase 6: Recursos Avançados e Automação
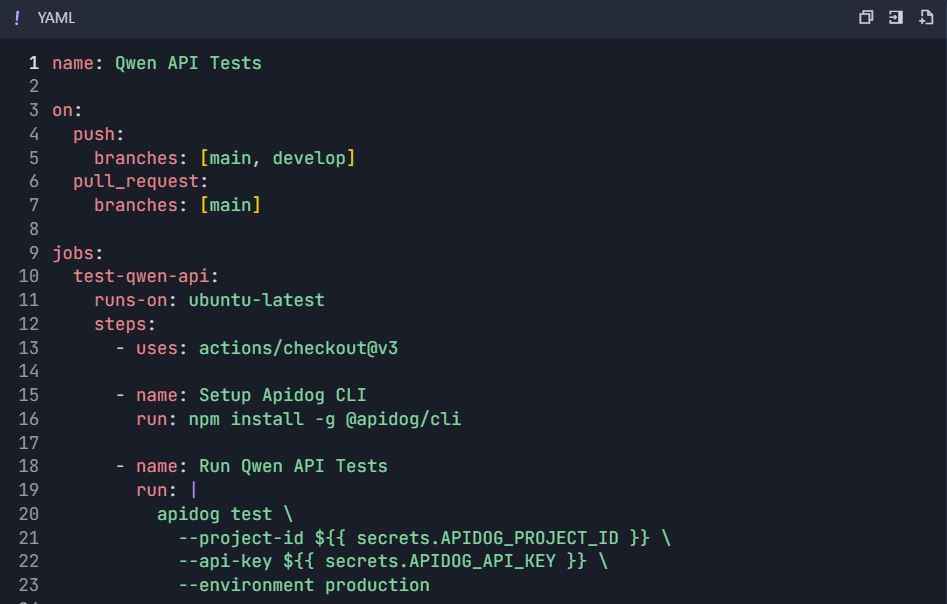
Passo 6: Fluxos de Trabalho de Teste Automatizados 6.1 Integração CI/CD
Fluxo de Trabalho do GitHub Actions ( .github/workflows/qwen-tests.yml ):
6.2 Teste de Desempenho
- Crie suíte de teste de desempenho:

2. Monitore métricas:
- Tempo de resposta (p50, p95, p99)
- Throughput (solicitações/segundo)
- Taxa de erro
- Eficiência de uso de tokens
6.3 Configuração de Servidor Mock
- Habilite o servidor mock:

2. Configure respostas mock:
Fase 7: Monitoramento e Análise
Passo 7: Painel de Análise de Uso
7.1 Métricas Chave para Rastrear
- Estatísticas de Uso da API :
- Contagem de solicitações por endpoint
- Consumo de tokens
- Tendências de tempo de resposta
- Análise da taxa de erros
2. Monitoramento de Custos :
- Uso diário de tokens
- Custo estimado por solicitação
- Alertas de orçamento
7.2 Configuração de Painel Personalizado
Fase 8: Colaboração em Equipe e Controle de Versão
Passo 8: Configuração do Fluxo de Trabalho da Equipe
8.1 Configuração de Funções da Equipe

8.2 Integração de Controle de Versão
- Conecte-se ao repositório Git:

2. Estratégia de Branching :

Exemplo de Fluxo de Trabalho de Teste Completo
Cenário de Teste de Ponta a Ponta
📋 Comandos de Teste:
Este guia de integração abrangente fornece tudo o que é necessário para testar e documentar eficientemente a API Qwen usando o Apidog. A configuração permite testes automatizados, monitoramento de desempenho, colaboração em equipe e integração contínua para um desenvolvimento robusto de API.
Técnicas Avançadas de Otimização para a API Qwen Next em Ambientes de Produção
O processamento em lote maximiza a eficiência em cenários de alto volume. O DashScope permite até 10 prompts por chamada, consolidando solicitações para minimizar a sobrecarga de latência. Isso é adequado para aplicações como sumarização em massa.
Monitore de perto o uso de tokens, pois as cobranças estão vinculadas aos parâmetros ativos. Crie prompts concisos para economizar custos e use result_format='message' para saídas analisáveis, pulando processamentos extras.
Implemente retentativas com backoff exponencial para lidar com transientes. Uma função que encapsula a chamada tenta várias vezes, esperando progressivamente mais tempo entre as tentativas. Isso garante a confiabilidade sob carga.
Para escalabilidade, distribua entre regiões como Cingapura ou EUA. Higienize as entradas para frustrar injeções de prompt, validando contra listas de permissão. Registre respostas anonimizadas para conformidade.
Em casos de contexto longo, divida os dados em blocos e encadeie chamadas. A variante thinking suporta prompts estruturados para coerência em tokens estendidos. Essas estratégias garantem implantações robustas.
Explorando a Integração Next: Incorporando o Qwen Next em Aplicações Web
A Integração Next refere-se à incorporação do Qwen Next em frameworks Next.js, aproveitando a renderização do lado do servidor para recursos de IA. Configure rotas de API no Next.js para proxy de chamadas Qwen, ocultando chaves dos clientes.
Em seu manipulador de API, use o SDK do DashScope para processar solicitações, retornando respostas transmitidas, se necessário. Essa configuração permite conteúdo dinâmico, como páginas personalizadas geradas em tempo real.
Lide com a autenticação no lado do servidor, usando gerenciamento de sessão. Para atualizações em tempo real, integre WebSockets com saídas de streaming. Teste-os com o Apidog, simulando solicitações de clientes.
A otimização de desempenho envolve o cache de consultas frequentes. Use o Redis para armazenar respostas, reduzindo as chamadas de API. Essa combinação impulsiona aplicativos interativos de forma eficiente.
Capacidades Multilíngues e de Contexto Longo na API Qwen Next
O Qwen Next suporta 119 idiomas, tornando-o versátil para aplicativos globais. Especifique os idiomas nos prompts para traduções ou gerações precisas. A API lida com as mudanças de forma contínua, mantendo o contexto.
Para contextos longos, estenda até 128K tokens definindo max_context_length. Isso se destaca na análise de grandes documentos. O prompt de cadeia de pensamento aprimora o raciocínio em volumes.
O benchmarking mostra uma recuperação superior, ideal para mecanismos de busca. Integre com bancos de dados para alimentar contextos dinamicamente.
Melhores Práticas de Segurança para Implantações da API Qwen
Proteja as chaves com cofres como o AWS Secrets Manager. Monitore o uso para anomalias, configurando alertas para picos. Cumpra as regulamentações anonimizando os dados.
A limitação de taxa no lado do cliente evita abusos. Criptografe as transmissões com HTTPS.
Monitoramento e Escalonamento do Uso da API Qwen Next
Os painéis do DashScope rastreiam métricas como o consumo de tokens. Defina orçamentos para evitar excessos. Escale atualizando os níveis para limites mais altos.
A infraestrutura de autoescalonamento responde ao tráfego. Ferramentas como Kubernetes gerenciam contêineres que hospedam a Integração Next.
Estudos de Caso: Aplicações Reais do Qwen Next via API
No e-commerce, o Qwen Next impulsiona mecanismos de recomendação, analisando históricos de usuários para sugestões. Chamadas de API geram descrições dinamicamente.
Aplicativos de saúde usam a variante thinking para auxílios de diagnóstico, processando relatórios com alta precisão.
Plataformas de conteúdo empregam modelos instruct para escrita automatizada, escalando a produção.
Perspectivas Futuras e Atualizações para o Qwen Next
A Alibaba continua a desenvolver a série, com potencial para mais especialistas ou roteamento mais refinado. Mantenha-se atualizado através dos canais oficiais, como a conta QwenAI_Plus no X.
Aprimoramentos da API podem incluir melhor suporte a ferramentas.
Aproveitando o Qwen Next para Soluções Inovadoras
O Qwen Next via API oferece eficiência incomparável. Da configuração às otimizações, você agora possui as ferramentas para implementar de forma eficaz. Experimente integrações, aproveitando o Apidog para fluxos de trabalho suaves.