Os modelos Llama 4 da Meta, nomeadamente Llama 4 Maverick e Llama 4 Scout, representam um avanço significativo na tecnologia de IA multimodal. Lançados em 5 de abril de 2025, esses modelos aproveitam uma arquitetura de Mistura de Especialistas (MoE), permitindo um processamento eficiente de texto e imagens com relações de desempenho para custo notáveis. Os desenvolvedores podem aproveitar essas capacidades através de APIs fornecidas por várias plataformas, tornando a integração em aplicações sem costura e poderosa.
Entendendo Llama 4 Maverick e Llama 4 Scout
Antes de mergulhar no uso da API, compreenda as especificações principais desses modelos. Llama 4 introduz multimodalidade nativa, significando que processa texto e imagens juntos desde o início. Além disso, seu design MoE ativa apenas um subconjunto de parâmetros por tarefa, aumentando a eficiência.
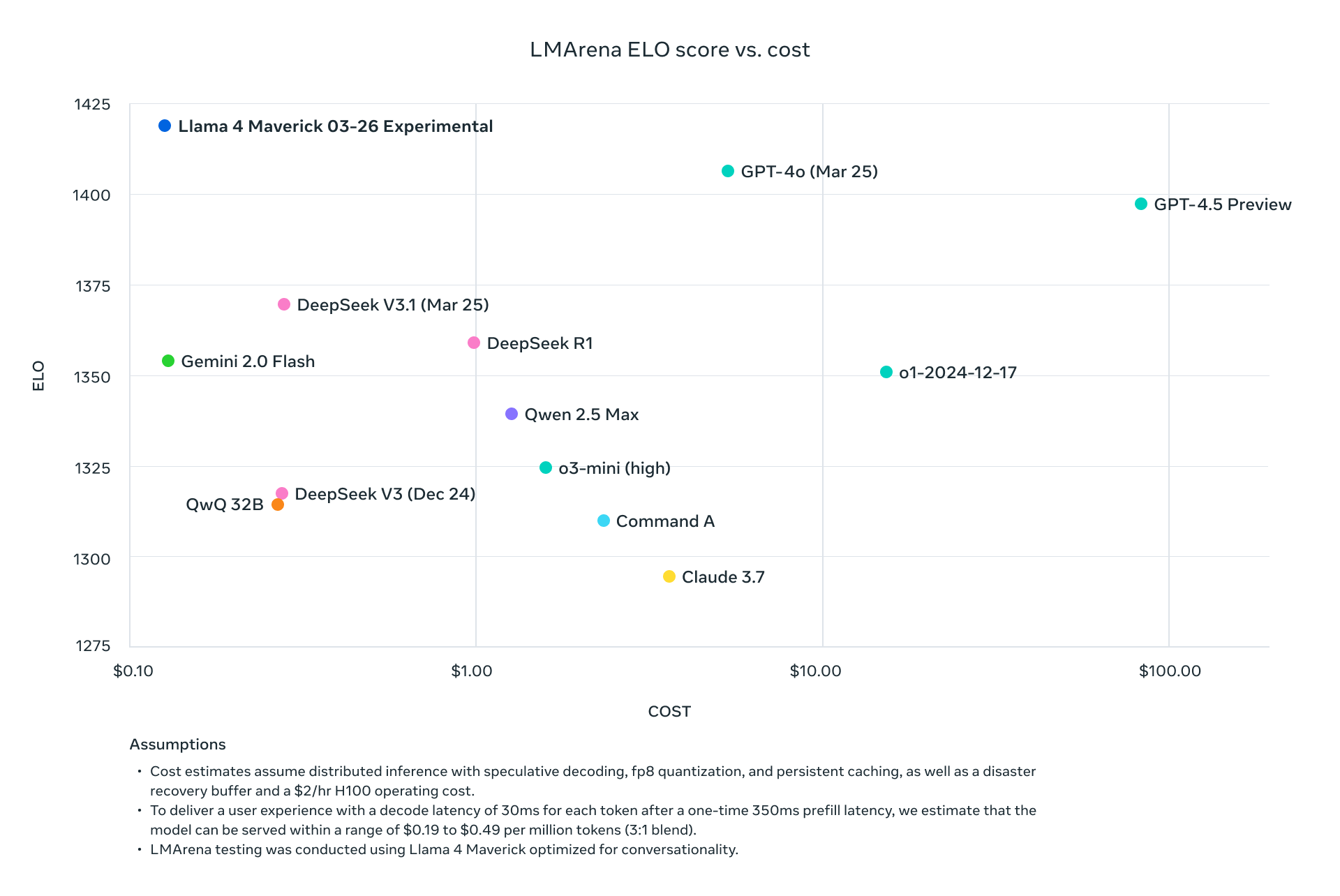
Llama 4 Scout: O Cavalo de Trabalho Multimodal Eficiente
- Parâmetros: 17 bilhões ativos, 109 bilhões totais, 16 especialistas.
- Janela de Contexto: Até 10 milhões de tokens.
- Recursos Principais: Destaca-se em tarefas de longo contexto, como sumarização de múltiplos documentos e raciocínio sobre grandes bases de código. Cabe em uma única GPU NVIDIA H100 com quantização INT4.
- Caso de Uso: Ideal para desenvolvedores que precisam de processamento multimodal rápido e eficiente em recursos.
Llama 4 Maverick: A Potência Versátil
- Parâmetros: 17 bilhões ativos, 400 bilhões totais, 128 especialistas.
- Janela de Contexto: Até 1 milhão de tokens.
- Recursos Principais: Oferece entendimento de texto e imagem de alta qualidade, suportando 12 idiomas (por exemplo, inglês, espanhol, hindi). Está otimizado para chat e escrita criativa.
- Caso de Uso: Adequado para assistentes de nível empresarial e aplicações multilíngues.
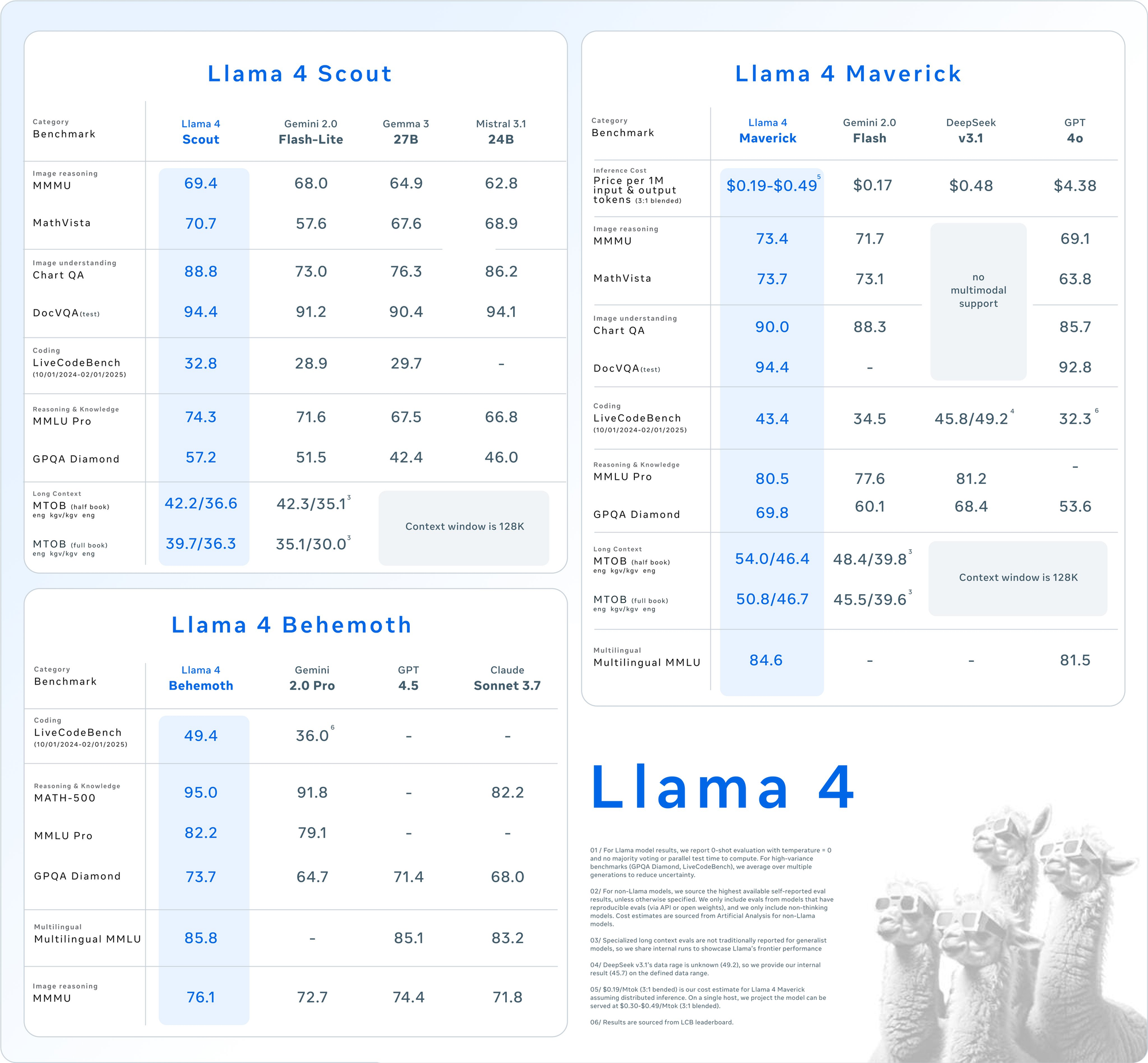
Ambos os modelos superam seus predecessores, como Llama 3, e competem com gigantes da indústria, como GPT-4o, tornando-os escolhas atraentes para projetos impulsionados por API.
Por que Usar a API Llama 4?
Integrar o Llama 4 via API elimina a necessidade de hospedar esses modelos massivos localmente, o que frequentemente requer hardware significativo (por exemplo, NVIDIA H100 DGX para Maverick). Em vez disso, plataformas como Groq, Together AI e OpenRouter oferecem APIs gerenciadas, oferecendo:
- Escalabilidade: Lidar com cargas variadas sem sobrecarga de infraestrutura.
- Eficiência de Custo: Pague por token, com tarifas a partir de $0,11/M para tokens de entrada (Scout no Groq).
- Facilidade de Uso: Acesse recursos multimodais com simples requisições HTTP.
Em seguida, vamos configurar seu ambiente para chamar essas APIs.
Configurando Seu Ambiente para Chamadas de API Llama 4
Para interagir com Llama 4 Maverick e Llama 4 Scout via API, prepare seu ambiente de desenvolvimento. Siga estes passos:
Passo 1: Escolha um Provedor de API
Várias plataformas hospedam APIs Llama 4. Aqui estão opções populares:
- Groq: Oferece inferência de baixo custo (Scout: $0.11/M de entrada, Maverick: $0.50/M de entrada).
- Together AI: Fornece endpoints dedicados com dimensionamento personalizado.
- OpenRouter: Camada gratuita disponível, ideal para testes.
- Cloudflare Workers AI: Implementação sem servidor com suporte ao Scout.
Para este guia, usaremos Groq e Together AI como exemplos devido à sua documentação robusta e desempenho.
Passo 2: Obtenha Chaves de API
- Groq: Cadastre-se em groq.com, navegue até o Console do Desenvolvedor e gere uma chave de API.
- Together AI: Registre-se em together.ai, depois acesse sua chave de API no painel.
Armazene essas chaves de forma segura (por exemplo, em variáveis de ambiente) para evitar a codificação rígida.
Passo 3: Instale Dependências
Use Python para simplicidade. Instale as bibliotecas necessárias:
pip install requests
Para testes, Apidog complementa essa configuração permitindo que você depure visualmente endpoints de API.
Fazendo Sua Primeira Chamada de API Llama 4
Com seu ambiente pronto, envie uma requisição para a API Llama 4. Vamos começar com um exemplo básico de geração de texto.
Exemplo 1: Geração de Texto com Llama 4 Scout (Groq)
import requests
import os
# Defina a chave da API
API_KEY = os.getenv("GROQ_API_KEY")
URL = "https://api.groq.com/v1/chat/completions"
# Defina o payload
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": "Escreva um poema curto sobre IA."}
],
"max_tokens": 150,
"temperature": 0.7
}
# Defina os cabeçalhos
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Envie a requisição
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Saída: Um poema conciso gerado pelo Scout, aproveitando sua arquitetura MoE eficiente.
Exemplo 2: Entrada Multimodal com Llama 4 Maverick (Together AI)
Maverick brilha em tarefas multimodais. Aqui está como descrever uma imagem:
import requests
import os
# Defina a chave da API
API_KEY = os.getenv("TOGETHER_API_KEY")
URL = "https://api.together.ai/v1/chat/completions"
# Defina o payload com imagem e texto
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/sample.jpg"}
},
{
"type": "text",
"text": "Descreva esta imagem."
}
]
}
],
"max_tokens": 200
}
# Defina os cabeçalhos
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Envie a requisição
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Saída: Uma descrição detalhada da imagem, mostrando o alinhamento imagem-texto do Maverick.
Otimização de Requisições de API para Desempenho
Para maximizar a eficiência, ajuste suas chamadas de API Llama 4. Considere essas técnicas:
Ajuste o Comprimento do Contexto
- Scout: Use sua janela de 10M de tokens para documentos longos. Defina
max_model_len(se suportado) para lidar com grandes entradas. - Maverick: Limite a 1M de tokens para aplicativos de chat para equilibrar velocidade e qualidade.
Ajuste Fino dos Parâmetros
- Temperatura: Diminua (por exemplo, 0,5) para respostas factuais, aumente (por exemplo, 1.0) para criatividade.
- Max Tokens: Limite o comprimento da saída para evitar cálculos desnecessários.
Processamento em Lote
Envie vários prompts em uma única requisição (se a API suportar) para reduzir a latência. Verifique a documentação do provedor para endpoints em lote.
Casos de Uso Avançados com a API Llama 4
Agora, explore integrações avançadas para desbloquear todo o potencial do Llama 4.
Caso de Uso 1: Chatbot Multilíngue
Maverick suporta 12 idiomas. Construa um bot de suporte ao cliente:
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Saída: Uma resposta em espanhol, aproveitando a fluência multilíngue do Maverick.
Caso de Uso 2: Sumarização de Documentos com Scout
A janela de 10M de tokens do Scout se destaca em resumir textos longos:
long_text = "..." # Insira um documento longo aqui
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": f"Resuma isto: {long_text}"}
],
"max_tokens": 300
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Saída: Um resumo conciso, processado de forma eficiente pelo Scout.
Depuração e Testes com Apidog
Testar APIs pode ser complicado, especialmente com entradas multimodais. Aqui é onde Apidog brilha:
- Interface Visual: Construa e envie requisições sem codificação.
- Rastreamento de Erros: Identifique problemas como limites de taxa ou payloads malformados.
- Respostas Simuladas: Simule saídas do Llama 4 para desenvolvimento frontend.
Para testar os exemplos acima no Apidog:
- Abra o Apidog e crie uma nova requisição.
- Defina a URL (por exemplo,
https://api.groq.com/v1/chat/completions).

- Adicione cabeçalhos (
Authorization,Content-Type).
- Cole o payload JSON.

- Envie e revise a resposta.

Esse fluxo de trabalho garante que sua integração com a API Llama 4 funcione sem problemas.
Comparando Provedores de API para Llama 4
Escolher o provedor certo impacta custo e desempenho. Aqui está uma análise:
| Provedor | Suporte ao Modelo | Preço (Entrada/Saída por M) | Limite de Contexto | Notas |
|---|---|---|---|---|
| Groq | Scout, Maverick | $0.11/$0.34 (Scout), $0.50/$0.77 (Maverick) | 128K (extensível) | Custo mais baixo, alta velocidade |
| Together AI | Scout, Maverick | Personalizado (endpoints dedicados) | 1M (Maverick) | Escalável, focado em empresas |
| OpenRouter | Ambos | Camada gratuita disponível | 128K | Ótimo para testes |
| Cloudflare | Scout | Baseado em uso | 131K | Simplicidade sem servidor |
Selecione com base na escala e no orçamento do seu projeto. Para prototipagem, comece com a camada gratuita do OpenRouter, e depois aumente com Groq ou Together AI.
Melhores Práticas para Integração da API Llama 4
Para garantir uma integração robusta, siga essas diretrizes:
- Limitação de Taxa: Respeite os limites do provedor (por exemplo, 100 requisições/minuto no Groq). Implemente um retrocesso exponencial para novas tentativas.
- Tratamento de Erros: Capture erros HTTP (por exemplo, 429 Muitas Requisições) e os registre.
- Segurança: Criptografe chaves de API e use endpoints HTTPS.
- Monitoramento: Acompanhe o uso de tokens para gerenciar custos, especialmente com as taxas mais altas do Maverick.
Solução de Problemas Comuns de API
Encontrou problemas? Resolva-os rapidamente:
- 401 Não Autorizado: Verifique sua chave de API.
- 429 Limite de Taxa Excedido: Reduza a frequência de solicitações ou faça upgrade em seu plano.
- Erros de Payload: Verifique se o formato JSON corresponde às especificações do provedor (por exemplo, array de
messages).
Apidog ajuda a diagnosticar esses problemas visualmente, economizando tempo.
Conclusão
Integrar Llama 4 Maverick e Llama 4 Scout via API capacita os desenvolvedores a construir aplicações de ponta com mínima sobrecarga. Quer você precise da eficiência de longo contexto do Scout ou da destreza multilíngue do Maverick, esses modelos oferecem desempenho de alto nível por meio de endpoints acessíveis. Ao seguir este guia, você pode configurar, otimizar e solucionar suas chamadas de API de forma eficaz.
Pronto para mergulhar mais fundo? Experimente provedores como Groq e Together AI, e aproveite Apidog para refinar seu fluxo de trabalho. O futuro da IA multimodal está aqui—comece a construir hoje!