
Os desenvolvedores buscam constantemente ferramentas que simplifiquem a integração com serviços avançados, como conversão de texto em fala (TTS) e processamento de áudio. O servidor ElevenLabs MCP se destaca como uma solução robusta, permitindo uma interação perfeita entre modelos de IA e a poderosa API da ElevenLabs. Projetado com o Protocolo de Controle de Modelo (MCP), este servidor capacita os desenvolvedores a aproveitar recursos de áudio de ponta—como gerar fala realista ou clonar vozes—diretamente em suas aplicações. Seja você construindo agentes de voz, automatizando tarefas de áudio ou aprimorando experiências do usuário, o servidor ElevenLabs MCP oferece uma plataforma escalável e eficiente.
Introdução ao Servidor ElevenLabs MCP
O servidor ElevenLabs MCP é uma implementação de servidor open-source que conecta modelos de IA à API da ElevenLabs através do Protocolo de Controle de Modelo (MCP). Desenvolvido pela Anthropic, o MCP facilita a comunicação segura entre sistemas de IA e serviços externos. Aqui, o servidor ElevenLabs MCP atua como uma ponte, permitindo que modelos como Claude ou Cursor aproveitem os avançados recursos de TTS, clonagem de vozes e processamento de áudio da ElevenLabs.

Por que usar o servidor ElevenLabs MCP? Primeiro, ele simplifica a geração de áudio. Os desenvolvedores podem criar fala natural a partir de prompts de texto. Em segundo lugar, suporta a clonagem de vozes, permitindo saídas de áudio personalizadas. Em terceiro lugar, oferece transcrição e manipulação avançada de áudio, tornando-o ideal para diversas aplicações—pense em call centers automatizados, ferramentas de podcast ou jogos interativos. Ao integrar este servidor, você desbloqueia um conjunto de ferramentas de áudio sem a complexidade do gerenciamento de API.
A seguir, vamos percorrer o processo de configuração para colocar o servidor em funcionamento no seu sistema.
Configurando o Servidor ElevenLabs MCP
Antes de mergulhar no uso do servidor ElevenLabs MCP, você deve configurá-lo corretamente. Felizmente, o processo é direto, desde que você atenda aos pré-requisitos e siga estas etapas.
Pré-requisitos
Certifique-se de ter o seguinte:
- Python 3.8+: O servidor depende do Python, então instale uma versão compatível.
- Chave da API da ElevenLabs: Inscreva-se em ElevenLabs para obter sua chave para autenticação da API.
- uv (Opcional): Este gerenciador de pacotes Python simplifica a instalação de dependências. Instale-o com:
curl -LsSf https://astral.sh/uv/install.sh | sh
Etapas de Instalação
Clone o Repositório
Comece baixando o código-fonte do GitHub. Abra seu terminal e execute:
git clone https://github.com/elevenlabs/elevenlabs-mcp.git
cd elevenlabs-mcp
Instale Dependências
Com uv, instale os pacotes necessários sem esforço:
uv sync
Alternativamente, use pip:
pip install -r requirements.txt
Defina a Chave da API
O servidor precisa da sua chave da API da ElevenLabs. Você pode configurá-la de duas maneiras:
- Variável de Ambiente: Adicione-a ao seu shell:
export ELEVENLABS_API_KEY="sua-chave-aqui"
- Linha de Comando: Passe-a ao iniciar o servidor (mostrado abaixo).
Inicie o Servidor
Execute o servidor com uv:
uv run elevenlabs_mcp --api-key=sua-chave-aqui
Se você definir a variável de ambiente, pule a flag --api-key:
uv run elevenlabs_mcp
Uma vez iniciado, o servidor escuta na porta 8000 por padrão. Agora você está pronto para configurá-lo ainda mais ou conectar um modelo de IA.
Configurando o Servidor ElevenLabs MCP
Após a instalação, configure o servidor ElevenLabs MCP para atender às suas necessidades. O servidor oferece flexibilidade através de opções de linha de comando, variáveis de ambiente ou um arquivo de configuração.
Opções Chave de Configuração
Personalize o servidor com estes parâmetros:
--api-key: Sua chave da API da ElevenLabs (ou useELEVENLABS_API_KEY).--port: Defina a porta de escuta (padrão: 8000).--host: Defina o endereço do host (padrão: 127.0.0.1).--log-level: Ajuste a verbosidade dos logs (por exemplo, DEBUG, INFO).
Para ver todas as opções, execute:
uv run elevenlabs_mcp --help
Usando um Arquivo de Configuração
Para configurações complexas, use um arquivo JSON. Crie config.json:
{
"api_key": "sua-chave-aqui",
"port": 8000,
"host": "127.0.0.1",
"log_level": "INFO"
}
Então inicie o servidor:
uv run elevenlabs_mcp --config=config.json
Este método brilha ao gerenciar múltiplos ambientes. Com a configuração concluída, vamos explorar a integração.
Integrando o Servidor ElevenLabs MCP com Modelos de IA
O servidor ElevenLabs MCP se destaca quando emparelhado com modelos de IA. Ao conectar ferramentas como Claude ou Cursor, você habilita tarefas de áudio guiadas por linguagem natural.
Integração com Claude Desktop
Siga estas etapas para conectar o Claude Desktop:
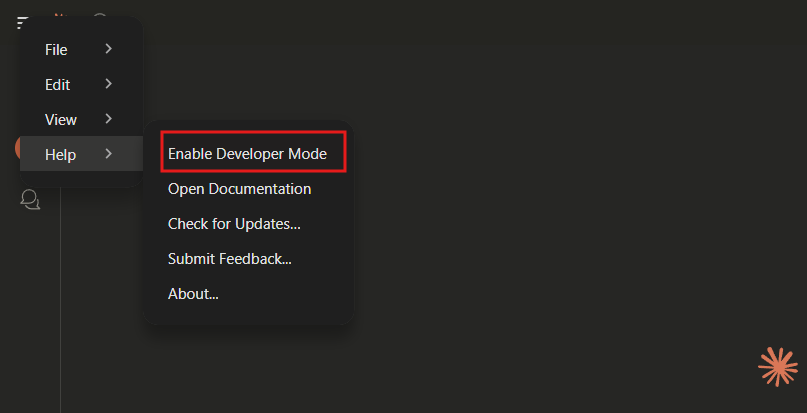
Ativar o Modo Desenvolvedor
- Abra o Claude Desktop.
- Navegue até o menu de hambúrguer > Ajuda > Ativar Modo Desenvolvedor.
Configure as Configurações do MCP
- Vá em Claude > Configurações > Desenvolvedor > Editar Config.
- Atualize
claude_desktop_config.json:
{
"mcpServers": {
"ElevenLabs": {
"command": "uvx",
"args": ["elevenlabs-mcp"],
"env": {
"ELEVENLABS_API_KEY": "sua-chave-aqui"
}
}
}
}
Reinicie o Claude
Feche e reabra o Claude Desktop. Agora, faça solicitações como “Gerar fala: ‘Mensagem de teste’ com a ElevenLabs.”
Outros Clientes MCP
Para clientes personalizados, configure-os para acessar a URL do servidor (por exemplo, http://127.0.0.1:8000). Garanta a autenticação adequada, se necessário. Essa flexibilidade torna o servidor adaptável a vários fluxos de trabalho.
Usando o Servidor ElevenLabs MCP para Conversão de Texto em Fala
Um recurso principal do servidor ElevenLabs MCP é sua capacidade de conversão de texto em fala. Aqui está como usá-lo de forma eficaz.
Gerando Fala Básica
Com um modelo de IA conectado, envie um prompt:
- Prompt: “Gerar fala: ‘Olá, bem-vindo!’ usando a voz ‘Brian’.”
- Resultado: O servidor processa isso e retorna áudio.
O servidor MCP lida com a chamada de API em segundo plano, entregando a saída de forma transparente.
Personalizando a Fala
Adapte a saída com estas opções:
- Voz: Selecione da biblioteca da ElevenLabs ou de uma voz clonada.
- Modelo: Escolha um modelo TTS para qualidade ou velocidade.
- Estabilidade/Similaridade: Ajuste as vozes clonadas.
Exemplo de prompt:
- “Gerar fala: ‘Atualização de serviço.’ usando a voz ‘Emma’ com alta estabilidade.”
Essa personalização garante que seu áudio se encaixe no tom do seu projeto.
Recursos Avançados do Servidor ElevenLabs MCP
Além do TTS, o servidor ElevenLabs MCP oferece funcionalidades avançadas. Vamos explorar recursos chave.
Clonagem de Voz
Clone uma voz para aplicações únicas:
- Reúna Amostras: Colete áudio claro da voz alvo.
- Envie Requisição: “Clone uma voz com [sample1.wav, sample2.wav].”
- Use-a: Referencie o ID da voz clonada em prompts de TTS.
Isso é perfeito para branding ou criação de personagens.
Transcrição de Áudio
Transcreva áudio sem esforço:
- Prompt: “Transcreva [meeting.mp3].”
- Saída: O servidor retorna o texto.
Use isso para notas, legendas ou análise de conteúdo.
Tarefas de Longa Duração
Tarefas como design de voz podem levar tempo. O servidor as lida de forma assíncrona. Verifique o progresso com:
- “Qual o status da minha tarefa de clonagem de voz?”
Solucionando Problemas do Servidor ElevenLabs MCP
Problemas podem surgir. Veja como corrigir os comuns:
- Time-outs: Atualize seu cliente MCP; verifique os logs para o status da tarefa.
- Erros de Chave da API: Verifique sua chave no ambiente ou na configuração.
- Conflitos de Porta: Use
--portpara mudar (por exemplo,--port=8080).
Consulte o repositório do GitHub para mais ajuda.
Conclusão: Dominando o Servidor ElevenLabs MCP
O servidor ElevenLabs MCP capacita desenvolvedores a integrar recursos avançados de áudio em aplicações impulsionadas por IA. Desde a configuração até a personalização avançada, este guia proporciona o conhecimento necessário para aproveitar todo o seu potencial. Experimente diferentes configurações, conecte seus modelos de IA preferidos e explore suas capacidades ainda mais. Para fluxos de trabalho de API mais suaves, baixe Apidog gratuitamente—é uma mudança de jogo para testar e gerenciar requisições.