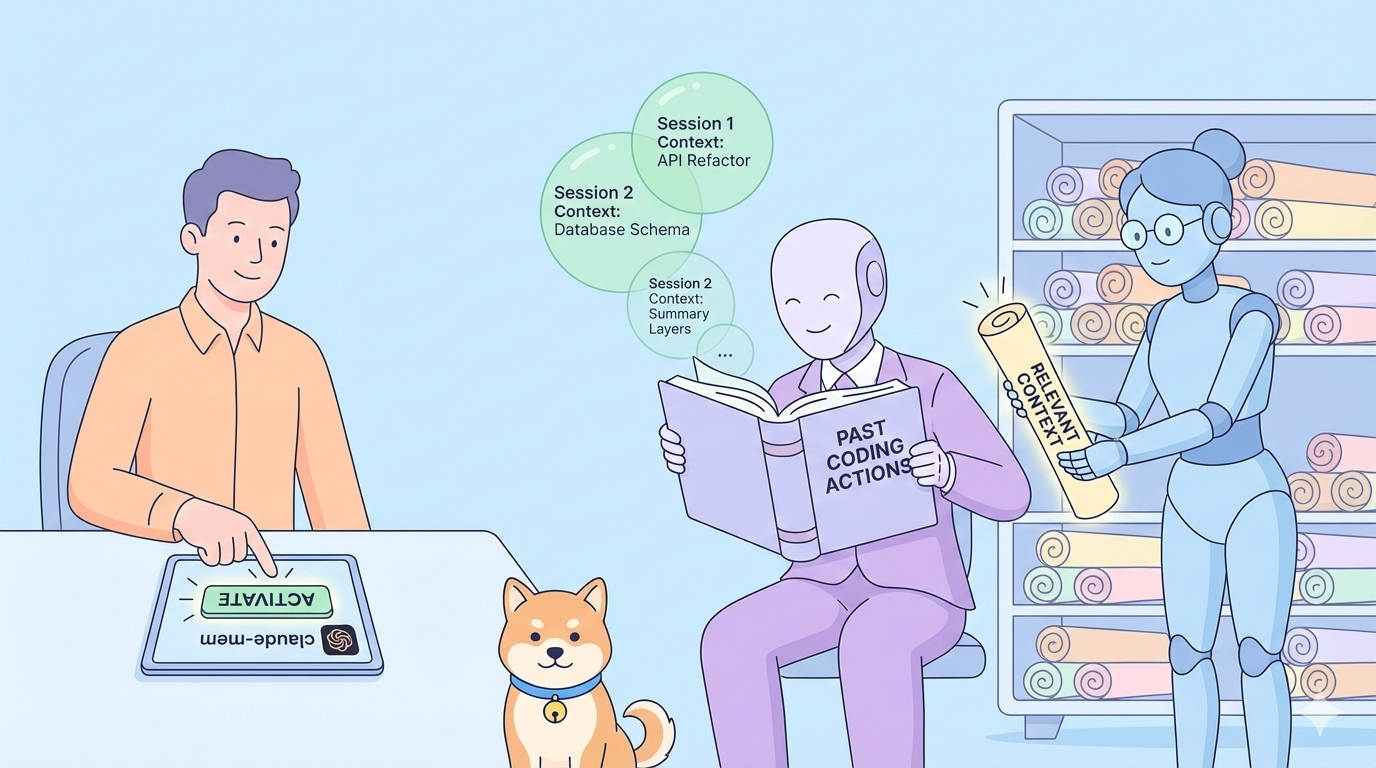
E se o seu assistente de IA se lembrasse de cada decisão arquitetural, correção de bug e sessão de refatoração ao longo de semanas de desenvolvimento? O Claude-mem elimina o atrito da perda de contexto ao capturar automaticamente observações de uso de ferramentas, compactá-las em resumos semânticos e injetar histórico relevante em cada nova sessão do Claude Code.
O Problema: Amnésia de Contexto no Desenvolvimento Assistido por IA
Cada sessão do Claude Code começa como uma tela em branco. Quando você fecha o seu terminal ou se desconecta de uma sessão, Claude esquece tudo; a estrutura do seu projeto, decisões recentes de refatoração, descobertas de depuração e padrões arquitetônicos. Isso o força a explicar repetidamente seu código, gastando tokens em contexto redundante e quebrando a continuidade do fluxo de trabalho.
Atualmente, os desenvolvedores contornam isso mantendo manualmente arquivos CLAUDE.md, anotando em documentos separados ou reexplicando o contexto do projeto no início de cada sessão. Essas abordagens são frágeis, demoradas e nunca capturam a riqueza completa do seu histórico de desenvolvimento. O Claude-mem resolve isso observando automaticamente cada invocação de ferramenta, compactando a saída em memórias semânticas pesquisáveis e recuperando inteligentemente o contexto relevante quando você precisa.
Quer uma plataforma integrada e completa para sua Equipe de Desenvolvedores trabalhar em conjunto com produtividade máxima?
Apidog atende a todas as suas demandas e substitui o Postman por um preço muito mais acessível!
Compreendendo a Arquitetura do Claude-mem
O Claude-mem opera como um sistema persistente de compressão de memória que se conecta ao ciclo de vida do Claude Code. Ele captura as saídas das ferramentas – tipicamente de 1.000 a 10.000 tokens – e as compacta em observações semânticas de aproximadamente 500 tokens usando o SDK do Agente de Claude. Essas observações são categorizadas por tipo (decisão, correção de bug, recurso, refatoração, descoberta, mudança) e marcadas com conceitos relevantes e referências de arquivos, sendo então armazenadas em um banco de dados SQLite local com recursos de pesquisa de texto completo.
O sistema usa cinco ganchos de ciclo de vida para capturar o contexto:
- SessionStart: Injeta contexto de sessões anteriores quando você inicia
- UserPromptSubmit: Captura suas consultas para reconhecimento de padrões
- PostToolUse: Observa cada execução de ferramenta e sua saída
- Stop: Gera resumos de sessão quando Claude termina de responder
- SessionEnd: Finaliza o armazenamento da sessão e a limpeza
Essa arquitetura permite a divulgação progressiva – um sistema de recuperação de memória em camadas que equilibra a cobertura com a eficiência de tokens. Em vez de despejar todo o seu histórico no contexto, o Claude-mem recupera observações em camadas, economizando aproximadamente 2.250 tokens por sessão em comparação com o gerenciamento manual de contexto.
Instalação e Requisitos do Sistema
O Claude-mem requer Node.js 18.0.0 ou superior, o Claude Code mais recente com suporte a plugins, e Bun como o ambiente de execução JavaScript e gerenciador de processos (auto-instalado se ausente). SQLite 3 é empacotado para armazenamento persistente. O plugin funciona em várias plataformas: Windows, macOS e Linux.
Instalação Rápida
Instale o Claude-mem diretamente do marketplace de plugins com dois comandos:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
Reinicie o Claude Code após a instalação. O plugin baixa automaticamente binários pré-construídos, instala dependências incluindo Bun e SQLite, configura ganchos para gerenciamento do ciclo de vida da sessão e inicia automaticamente o serviço de worker na sua primeira sessão.
Instalação Avançada a partir do Código-Fonte
Para desenvolvimento ou teste, clone e compile a partir do código-fonte no github:
git clone https://github.com/thedotmack/claude-mem.git
cd claude-mem
npm install
npm run build
npm run worker:start
Essa abordagem é útil se você precisar modificar o plugin ou executar recursos beta como o Modo Infinito.

Verificação Pós-Instalação
Após a instalação, verifique se tudo está funcionando:
- Verifique a instalação do plugin:
cat plugin/hooks/hooks.json
- Verifique se o serviço de worker está em execução:
curl http://localhost:37777/api/health
- Visualize os logs recentes do worker:
npm run worker:logs
Teste a recuperação de contexto iniciando uma nova sessão do Claude Code. Você deverá ver o contexto de sessões anteriores carregado automaticamente no prompt inicial.
Armazenamento de Dados e Configuração
O Claude-mem armazena todos os dados localmente em ~/.claude-mem/:
- Banco de Dados:
~/.claude-mem/claude-mem.db(SQLite com pesquisa FTS5) - Arquivo PID:
~/.claude-mem/.worker.pid - Arquivo de Porta:
~/.claude-mem/.worker.port - Logs:
~/.claude-mem/logs/worker-YYYY-MM-DD.log - Configurações:
~/.claude-mem/settings.json
Substitua o diretório de dados padrão com uma variável de ambiente:
export CLAUDE_MEM_DATA_DIR=/caminho/personalizado
Opções de Configuração
As configurações são gerenciadas em ~/.claude-mem/settings.json (criado automaticamente na primeira execução). As configurações principais incluem:
CLAUDE_MEM_CONTEXT_OBSERVATIONS: Número de observações injetadas no início da sessão (padrão: 50)CLAUDE_MEM_FOLDER_INDEX_ENABLED: Ativa/desativa arquivos CLAUDE.md gerados automaticamente em pastas- Seleção de modelo para compressão impulsionada por IA
- Configurações de porta e host do worker
- Configuração do nível de log
Como o Claude-mem Captura e Processa o Contexto
Quando você usa o Claude Code com o claude-mem ativado, o sistema captura automaticamente cada invocação de ferramenta. Seja Claude lendo um arquivo, executando um comando bash, pesquisando com padrões glob ou editando código, o claude-mem observa a entrada e a saída.
O serviço de worker processa essas observações e extrai:
- Título: Breve descrição do que aconteceu
- Subtítulo: Contexto adicional
- Narrativa: Explicação detalhada da atividade
- Fatos: Principais aprendizados em tópicos
- Conceitos: Tags e categorias relevantes para pesquisa
- Tipo: Classificação (decisão, correção de bug, recurso, refatoração, descoberta, mudança)
- Arquivos: Quais arquivos foram lidos ou modificados
Essa compressão acontece automaticamente sem intervenção manual. A saída bruta da ferramenta pode ser de 5.000 tokens, mas a observação semântica armazenada no banco de dados é de aproximadamente 500 tokens — preservando o significado enquanto elimina o ruído.
Resumos de Sessão
Quando Claude termina de responder (acionando o gancho Stop), o claude-mem gera automaticamente um resumo da sessão contendo:
- Solicitação: O que você pediu
- Investigado: O que Claude explorou para responder
- Aprendido: Descobertas e insights chave
- Concluído: O que foi realizado
- Próximos Passos: Ações de acompanhamento recomendadas
Esses resumos são injetados em sessões futuras junto com observações individuais, fornecendo detalhes granulares e contexto narrativo de alto nível.
Usando Ferramentas de Busca MCP para Consultar Sua Memória
O Claude-mem expõe quatro ferramentas MCP que seguem um padrão de fluxo de trabalho de 3 camadas eficiente em termos de tokens. Este design recupera o contexto progressivamente, minimizando o uso de tokens e maximizando a relevância.
O Fluxo de Trabalho de 3 Camadas
search: Obtém um índice compacto com IDs (~50-100 tokens por resultado)timeline: Obtém contexto cronológico em torno de resultados interessantesget_observations: Busca detalhes completos APENAS para IDs filtrados (~500-1.000 tokens por resultado)
Essa abordagem alcança aproximadamente 10x de economia de tokens ao filtrar antes de buscar todos os detalhes.
Ferramentas MCP Disponíveis
search: Pesquisa o índice de memória com consultas de texto completo. Filtra por tipo, data ou projeto.timeline: Obtém contexto cronológico em torno de uma observação ou consulta específica. Útil para entender o que levou a uma decisão ou correção de bug em particular.get_observations: Busca detalhes completos da observação por IDs. Sempre agrupe múltiplos IDs em uma única chamada para minimizar a sobrecarga.__IMPORTANT: Documentação do fluxo de trabalho que está sempre visível para Claude, explicando como usar o sistema de memória de forma eficaz.
Padrões de Uso de Exemplo
Encontrar uma correção de bug específica:
// Passo 1: Procurar pelo bug
search(query="bug de autenticação", type="bugfix", limit=10)
// Passo 2: Revisar o índice, identificar IDs relevantes (por exemplo, #123, #456)
// Passo 3: Buscar detalhes completos para observações relevantes
get_observations(ids=[123, 456])
Explorar decisões arquitetônicas recentes:
search(query="esquema do banco de dados", type="decision", limit=5)
Encontrar tudo relacionado a um arquivo específico:
search(query="worker-service.ts", limit=20)
Consultas em Linguagem Natural
Você pode perguntar a Claude naturalmente sobre o histórico do seu projeto:
- "O que decidimos sobre tratamento de erros?"
- "Como implementamos a autenticação?"
- "Quais bugs corrigimos na camada de API?"
- "Mostre-me as alterações no esquema do banco de dados"
Claude invoca automaticamente as ferramentas MCP apropriadas para recuperar o contexto relevante, apresentando os resultados com citações URI claude-mem:// que fazem referência a observações específicas.
Arquivos de Contexto de Pasta e Geração Automática de CLAUDE.md
O Claude-mem gera automaticamente arquivos CLAUDE.md em pastas de projeto, criando linhas do tempo de atividade que complementam o banco de dados de memória global.
Como o Contexto de Pasta Funciona
Quando você trabalha com arquivos em uma pasta, o claude-mem:
- Identifica caminhos de pasta únicos a partir de arquivos tocados
- Consulta observações recentes relevantes para cada pasta
- Gera uma linha do tempo de atividade formatada
- Escreve-a para CLAUDE.md nessa pasta (dentro das tags
<claude-mem-context>)
O CLAUDE.md de cada pasta contém uma seção de Atividade Recente mostrando IDs de observação, carimbos de data/hora, indicadores de tipo (correções de bugs, recursos, descobertas), títulos breves e estimativas de contagem de tokens.
Preservação de Conteúdo do Usuário
O conteúdo gerado automaticamente é encapsulado em tags <claude-mem-context>. Qualquer conteúdo que você escreva fora dessas tags é preservado quando o arquivo é regenerado. Isso permite que você:
- Adicione sua própria documentação acima ou abaixo da seção gerada
- Escreva instruções específicas da pasta para Claude
- Inclua notas arquitetônicas ou convenções
Exemplo de estrutura CLAUDE.md:
# Módulo de Autenticação
Esta pasta contém todo o código relacionado à autenticação.
Siga os padrões estabelecidos para novos provedores de autenticação.
<claude-mem-context>
# Atividade Recente
| ID | Hora | Tipo | Título | Tokens |
|----|------|------|-------|--------|
| #1234 | 16:30 | 🔵 | Autenticação de usuário implementada | ~250 |
| #1235 | 16:45 | 🔴 | Corrigido bug de redirecionamento de login | ~180 |
</claude-mem-context>
## Notas Manuais
- Os provedores OAuth vão em /providers/
- O gerenciamento de sessão usa Redis
Controles de Privacidade e Segurança
O Claude-mem oferece controles de privacidade granulares para evitar que dados sensíveis entrem no sistema de memória.
Tags de Conteúdo Privado
Empacote o conteúdo sensível em tags <private> para excluí-lo do armazenamento:
<private>
API_KEY=sk-live-abc123xyz789
DATABASE_PASSWORD=supersecret456
</private>
O processamento de borda garante que o conteúdo privado nunca chegue ao banco de dados. Isso é crucial para chaves de API, credenciais e lógica proprietária.
Sistema de Privacidade de Dupla Tag
O Claude-mem usa uma abordagem de dupla tag:
<private>: Privacidade controlada pelo usuário para conteúdo sensível<claude-mem-context>: Tags de nível de sistema evitam o armazenamento de observações recursivas
Interface do Usuário do Visualizador Web e Monitoramento em Tempo Real
O Claude-mem executa um visualizador web em http://localhost:37777 para visualização em tempo real do fluxo de memória. A interface mostra:
- Fluxo de observação ao vivo com indicadores de emoji para importância
- Linha do tempo da sessão com marcadores cronológicos
- Interface de pesquisa para consultar memórias
- Painel de configurações para ajustes de configuração
- Troca de versão entre canais estável e beta
Esta UI é opcional para uso básico, mas inestimável para entender o que o claude-mem captura e como ele organiza seu histórico de desenvolvimento.
Recursos Beta: Modo Infinito
O canal beta oferece o Modo Infinito, uma arquitetura de memória biomimética para sessões estendidas. Em vez de atingir limites de contexto após 50 usos de ferramentas, o Modo Infinito promete aproximadamente 1.000 usos — um aumento de 20 vezes. Ele alcança isso comprimindo as saídas das ferramentas em tempo real, reduzindo os tokens em cerca de 95% e alterando a escala de O(N²) quadrática para O(N) linear.
Compromisso: A geração de observações adiciona 60-90 segundos por invocação de ferramenta. Para sessões de codificação profundas e ponderadas que duram dias ou semanas, essa latência pode ser aceitável. Para uso rápido de ferramentas, pode ser proibitivo.
Ative os recursos beta na UI do visualizador web em http://localhost:37777 → Configurações → Canal de Versão.
Solução de Problemas Comuns
Serviço de Worker Não Iniciando
Se o worker falhar ao iniciar na porta 37777:
- Verifique se a porta já está ocupada:
lsof -i :37777
- Configure uma porta alternativa:
export CLAUDE_MEM_WORKER_PORT=8080
- Inicie manualmente o worker:
bun plugin/scripts/worker-service.cjs
Memória Não Sendo Salva
Se Claude não se lembrar de sessões anteriores:
- Verifique se o worker está em execução:
npm run worker:status
- Verifique se o arquivo do banco de dados existe:
ls -la ~/.claude-mem/claude-mem.db
- Revise os logs do worker em busca de erros:
npm run worker:logs
Problemas de Injeção de Contexto
Se muito ou pouco contexto aparecer no início da sessão:
Ajuste o limite de observação:
export CLAUDE_MEM_CONTEXT_OBSERVATIONS=10 # Reduzir
export CLAUDE_MEM_CONTEXT_OBSERVATIONS=100 # Aumentar
Arquivos CLAUDE.md Vazios
Se o claude-mem criar arquivos CLAUDE.md vazios em seu projeto, este é um problema conhecido na v9.0.5. As soluções alternativas atuais incluem excluir manualmente os diretórios criados, adicionar padrões ao .gitignore ou aguardar a correção em uma versão subsequente.
Integração com Claude Desktop
O Claude-mem funciona com o Claude Desktop através da configuração do servidor MCP. Adicione o servidor mcp-search à sua configuração do Claude Desktop, aponte para o script do servidor MCP na instalação do claude-mem e reinicie o Claude Desktop.
Uma vez configurado, pergunte naturalmente sobre trabalhos passados:
- "O que fizemos na última sessão?"
- "Já corrigimos este bug antes?"
- "Como implementamos a autenticação?"
Use o visualizador web em localhost:37777 para verificar se as memórias estão sendo capturadas e verifique os logs do Claude Desktop se a conexão falhar.
Comandos Manuais de Gerenciamento do Worker
No diretório claude-mem, você pode gerenciar o serviço de worker:
npm run worker:start # Iniciar o serviço de worker
npm run worker:stop # Parar o serviço de worker
npm run worker:restart # Reiniciar o serviço de worker
npm run worker:logs # Visualizar logs do worker
npm run worker:status # Verificar o status do worker
Conclusão
O Claude-mem transforma o Claude Code de um assistente sem estado em um parceiro de desenvolvimento persistente que acumula conhecimento sobre sua base de código ao longo do tempo. Ao capturar automaticamente o uso de ferramentas, comprimir observações em memórias pesquisáveis e recuperar inteligentemente o contexto relevante, ele elimina a construção repetitiva de contexto que retarda o desenvolvimento assistido por IA.
A arquitetura de divulgação progressiva do sistema – recuperação em camadas com ferramentas MCP, arquivos CLAUDE.md baseados em pastas e controles de privacidade – oferece aproximadamente 10x mais eficiência de tokens em comparação com o gerenciamento manual de contexto, mantendo a localidade e a segurança completas dos dados.
Ao construir APIs ou trabalhar com serviços externos em seu fluxo de trabalho aprimorado com Claude-mem, otimize seus testes com Apidog. Ele oferece testes visuais de API, geração automática de documentação e depuração colaborativa que complementa sua configuração de memória persistente.