
Introdução
À medida que os volumes de dados continuam a crescer, uma abordagem comum no treinamento de modelos de aprendizado de máquina é o treinamento por lotes. Esse método envolve dividir um conjunto de dados em subconjuntos menores ou "lotes", que são alimentados ao modelo um de cada vez.
Neste post, vamos explorar três técnicas diferentes para dividir conjuntos de dados em lotes:
- Criar um grande tensor
- Carregar dados parciais com HDF5
- Usar geradores do Python
Para ilustrar, vamos assumir que o modelo é um detector baseado em som, mas os métodos discutidos são amplamente aplicáveis. Embora este exemplo seja específico, os passos principais — dividir, pré-processar e iterar sobre os dados — são universalmente relevantes. Essas técnicas podem ser usadas com várias fontes de dados, como arquivos de imagem, tabelas de uma consulta SQL ou uma resposta HTTP. O foco aqui é no próprio processo.
Vamos avaliar cada método considerando os seguintes fatores:
- Qualidade do código
- Uso de memória
- Eficiência de tempo
Antes de começarmos, se você está fazendo Testes de API e precisa de uma substituição para o Postman (que está ficando mais caro e oferecendo menos recursos), o APIDog é a sua escolha ideal!

Apidog é uma plataforma colaborativa projetada para a gestão e testes de APIs, semelhante ao Postman, mas com recursos adicionais que tornam o manuseio de datas mais fácil. Veja como isso pode ajudar:
O que é um Lote no Contexto de Conjuntos de Dados
Um lote é geralmente um par entrada-saída (X[i], y[i]), representando um subconjunto dos dados. Para nosso detector baseado em som, o modelo recebe uma sequência de áudio processada como entrada e gera a probabilidade de um determinado evento ocorrer. Neste caso, um lote consiste em:
- X[t] - uma matriz representando a faixa de áudio processada amostrada ao longo de uma janela de tempo
- y[t] - um rótulo binário indicando a ocorrência do evento.
Aqui, t refere-se à janela de tempo (figura 1).
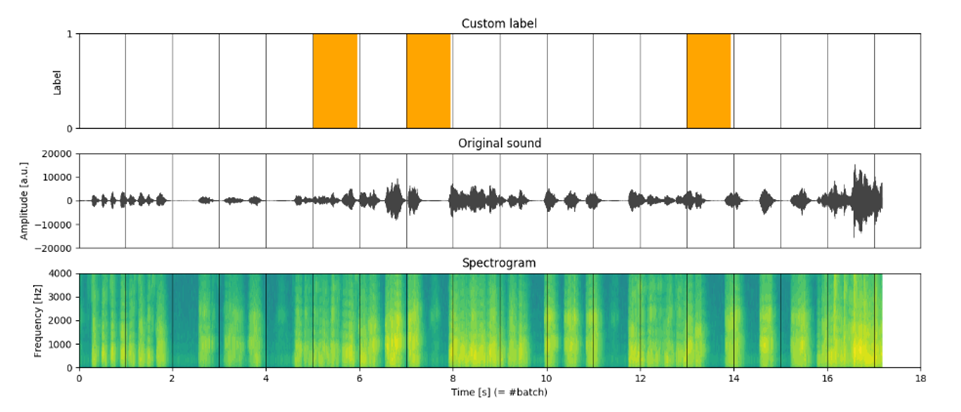
Comparando Diferentes Abordagens para Dividir Conjuntos de Dados
Abordagem #1 - Usando um Grande Tensor
O modelo recebe a entrada na forma de um tensor 2D. Para acomodar o processamento por lotes, podemos aumentar a ordem do tensor, usando a terceira dimensão para representar o tamanho do lote. Os passos neste processo são os seguintes:
- Carregar os dados de entrada (X).
- Carregar os rótulos correspondentes (y).
- Dividir X e y em lotes menores.
- Extrair características para cada lote (por exemplo, o espectrograma).
- Combinar os lotes processados de X[t] e y[t].
No entanto, por que essa abordagem pode não ser ideal? Vamos explorar um exemplo de implementação para entender melhor.
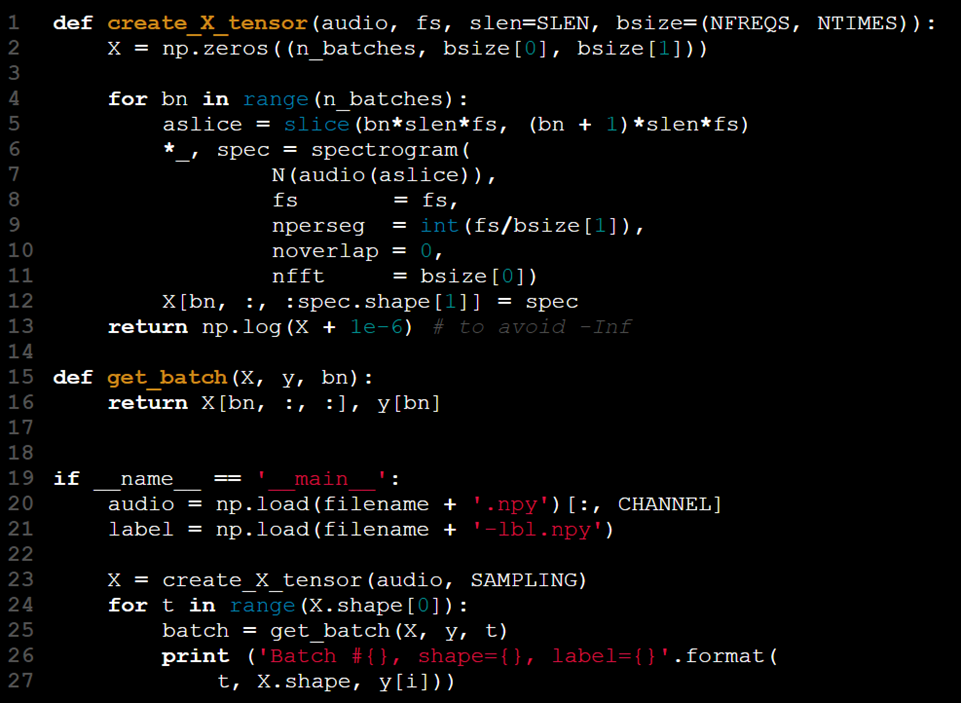
Essa abordagem pode ser resumida como "carregar tudo de uma vez e lidar com as consequências depois."
Prós e Contras da Abordagem do "Grande Tensor"
Embora tratar X como um conjunto de dados autossuficiente possa parecer vantajoso, há várias desvantagens neste método:
1.Limitações de memória: Carregar todo o conjunto de dados na RAM pode causar problemas, especialmente se a memória disponível não for suficiente para armazenar todos os dados.
2.Rigidez da dimensão do lote: A primeira dimensão de X é usada para representar o tamanho do lote, mas isso é apenas uma convenção. Se alguém decidir mudar essa ordem (por exemplo, usar a última dimensão para os lotes), o código precisa de ajustes.
3.Rastreamento de lotes: Embora X.shape[0] forneça o número exato de lotes, você ainda precisa de uma variável auxiliar (por exemplo, t) para rastrear o lote atual, o que adiciona complexidade ao código.
4.Função redundante: Esse design requer uma função get_batch, que serve apenas para fatiar e combinar X e y para o lote, tornando o código desnecessariamente convoluto.
Abordagem #2 - Carregando Lotes Usando HDF5
Uma maneira de resolver o problema de carregar todos os dados na RAM é carregar apenas porções dos dados conforme necessário. Se os dados estiverem armazenados em um arquivo, faz sentido carregar e trabalhar com pequenas seções em vez do conjunto de dados inteiro.
No caso de arquivos CSV, usar os argumentos skiprows e nrows na função read_csv do Pandas permite que você carregue partes específicas do arquivo.
Mas este método realmente capta todos os cenários? Vamos supor que queremos lidar com dados muito grandes e muito complexos, ou seja, arquivos de áudio, pode não ser adequado lidar com eles usando skiprows ou nrow utilizando a função read_csv do Pandas. É por isso que aqui está outra maneira: Formato de Dados Hierárquicos (HDF5).
Esse formato suporta o armazenamento de múltiplos arrays e fornece uma maneira conveniente de acessá-los e manipulá-los, semelhante aos arrays do NumPy.
Por exemplo, você pode trabalhar com conjuntos de dados nomeados 'áudio' e 'rótulo' armazenados em um arquivo HDF5. A biblioteca Python h5py é uma ferramenta útil para gerenciar esse formato.
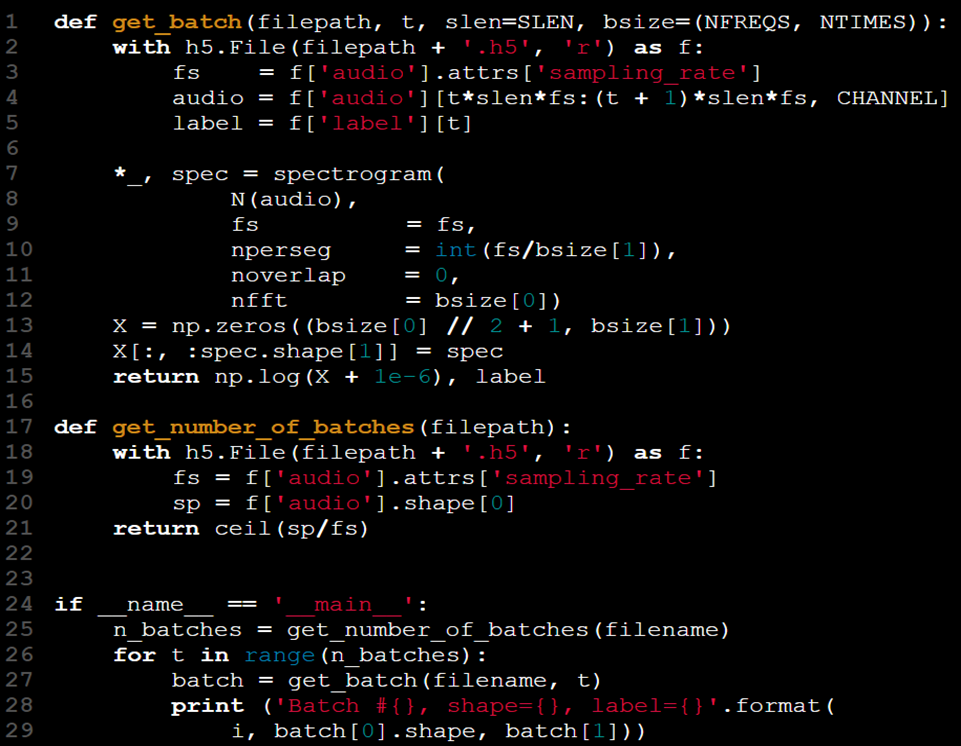
Agora que nossos dados estão mais gerenciáveis, também melhoramos sua qualidade geral:
- A função anterior get_batch foi substituída por uma versão mais prática que calcula e recupera os dados de forma eficiente.
- Não há mais necessidade de modificar artificialmente o tensor X.
- Ao mudar get_batch(X, y, t) para get_batch(filename, t), abstraímos o acesso aos dados e eliminamos a necessidade de manter X e y no espaço de nomes.
- O conjunto de dados agora está consolidado em um único arquivo, tornando desnecessário buscar dados e rótulos em arquivos separados.
- A taxa de amostragem (fs) está incluída como parte do arquivo do conjunto de dados através de atributos HDF5, eliminando a necessidade de passá-la como um argumento separado.
Apesar dessas melhorias, permanecem dois desafios:
- A nova função get_batch não rastreia seu estado, então ainda dependemos do uso de um loop para controlar t. Não há uma maneira embutida para a função saber o quão grande o loop deve ser, exigindo que verifiquemos o tamanho dos dados com antecedência. Isso torna necessária a criação de uma segunda função: get_number_of_batches.
- Embora essa configuração seja melhor, ainda carece da elegância de uma função get_batch totalmente preservadora de estado, que poderia simplificar ainda mais o processo.
Abordagem #3 – Usando Geradores
O que são Geradores?
Geradores são funções que retornam objetos iteradores. Em vez de computar todos os resultados de uma vez, esses iteradores fornecem dados uma peça de cada vez, esperando a próxima solicitação para prosseguir. Isso os torna uma escolha ideal para lidar com grandes conjuntos de dados de forma eficiente.
Vamos identificar o padrão recorrente:
Precisamos apenas acessar, processar e entregar porções de dados sequencialmente, em vez de carregar tudo de uma vez. O Python oferece uma solução para isso na forma de geradores.
Os geradores podem ser implementados de três maneiras:
Usando uma expressão geradora, semelhante a uma compreensão de lista, mas com parênteses em vez de colchetes (por exemplo, (i for i in iterable)).
Criando uma função geradora usando o yield em vez de return.
Definindo uma classe com métodos iter personalizados (ou getitem) e next.
Neste cenário, a palavra-chave yield é uma solução natural para nossas necessidades, permitindo que processemos e retornemos dados em pedaços gerenciáveis.
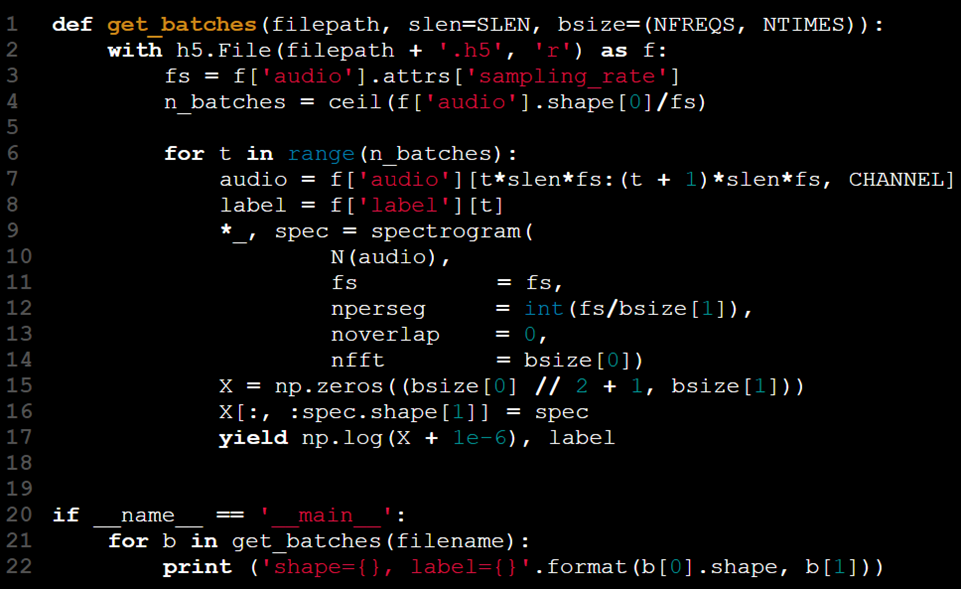
O loop agora está contido dentro da função. Usando a declaração yield, o par (X[t], y[t]) é retornado apenas quando get_batches foi chamado t - 1 vezes. Isso remove a necessidade de o código de treinamento do modelo gerenciar o estado do loop. A função mantém seu estado entre chamadas, permitindo que o usuário simplesmente itere pelos lotes sem precisar de um índice de lote manual.
Iteradores geradores podem ser comparados a contêineres que esvaziam gradualmente à medida que os dados são processados. Como os lotes são recuperados a cada iteração, o processo continua até que todos os dados sejam consumidos, eliminando a necessidade de indexação explícita ou condições de parada.
Desempenho: Tempo e Memória
Começamos focando na qualidade do código, pois isso se alinha de perto com a forma como nossa solução se desenvolveu. No entanto, também é igualmente importante considerar as limitações de recursos, particularmente ao lidar com grandes conjuntos de dados.
A figura 2 mostra o tempo necessário para entregar lotes usando os três métodos que discutimos. Como observado, o tempo para processar e transferir dados permanece quase o mesmo em todos os métodos. Se carregamos todos os dados de uma vez e depois os dividimos em lotes, ou os processamos de forma incremental desde o início, o tempo total para obter o resultado é quase idêntico. Isso pode ser parcialmente devido ao uso de SSDs, que oferecem acesso mais rápido aos dados. No entanto, a abordagem escolhida parece ter efeito mínimo no desempenho geral de tempo.
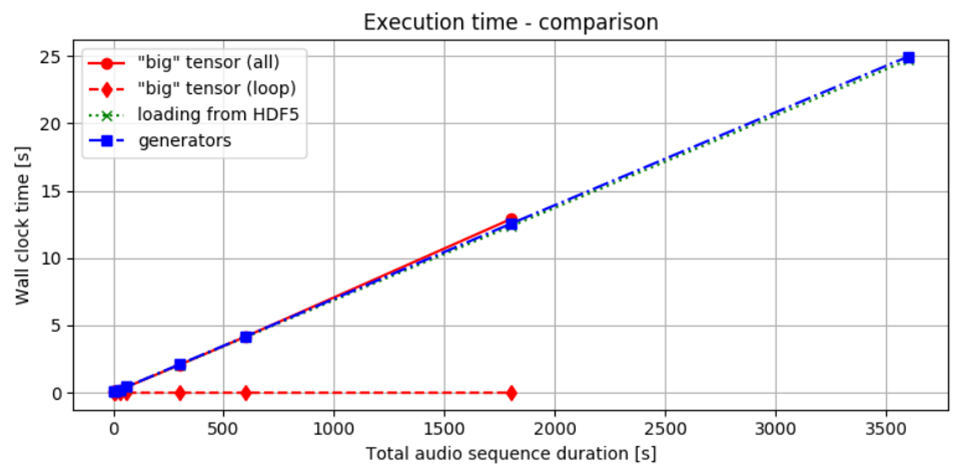
Figura 2. Comparação de Desempenho de Tempo: A linha sólida vermelha indica o tempo necessário tanto para carregar dados na memória quanto para realizar cálculos. A linha pontilhada vermelha representa o tempo gasto apenas no loop que processa os cortes, assumindo que os dados já foram pré-computados.
A linha pontilhada verde mostra o tempo de carregamento de lotes de um arquivo HDF5, enquanto a linha azul pontilhada ilustra o desempenho usando um gerador. Comparando as linhas vermelhas, é evidente que acessar os dados uma vez que eles estão carregados na RAM gera um custo adicional mínimo. Quando os dados estão locais, as diferenças entre os vários métodos são relativamente pequenas.
Figura 3. Comparação do Uso de Memória: A primeira abordagem demonstra o maior consumo de memória, levando a um Erro de Memória ao lidar com uma amostra de áudio de 1 hora. Em contraste, o método de carregamento em blocos controla a alocação de memória com base no tamanho do lote, garantindo que o uso de RAM permaneça dentro de limites seguros.
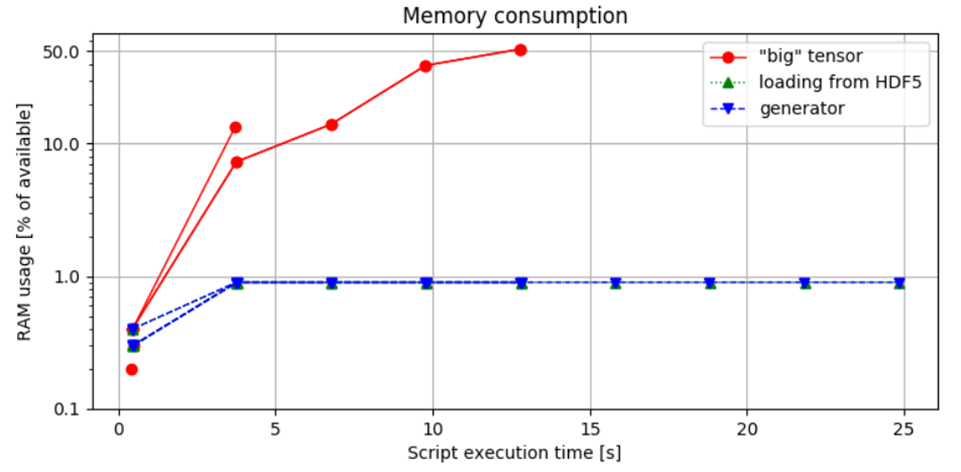
Figura 3. Comparação do Consumo de Memória: Esta figura ilustra a porcentagem da RAM disponível utilizada pelo script Python, medida executando o script com o comando:
python idea.py & top -b -n 10 > capture.log;cat capture.log | egrep python > analysis.log, e subsequentemente analisada.
Observações e Insights:
A comparação entre os segundos e terceiros métodos não mostra diferença significativa no uso de memória, indicando que a escolha de implementar um iterador gerador não impacta a pegada de memória. Essa constatação sublinha um ponto importante: embora geradores sejam frequentemente recomendados por sua eficiência em gerenciar tempo e memória, eles não reduzem inherentemente o consumo de recursos.
O fator-chave é a eficiência do acesso aos dados e a capacidade de manusear os dados em porções gerenciáveis.
Utilizar arquivos HDF5 é vantajoso, pois permite acesso rápido aos dados e flexibilidade para evitar carregar todos os dados de uma vez. Enquanto isso, incorporar um gerador aumenta a legibilidade e qualidade do código.
Combinar o uso de HDF5 para carregamento parcial de dados com iteradores geradores parece ser a abordagem mais eficaz, conforme demonstrado pelo terceiro método. Essa combinação otimiza tanto a gestão de memória quanto a clareza do código.
Como Dividir Conjuntos de Dados em Python (Exemplos)
Lembre-se de que em Python, você pode dividir um conjunto de dados em lotes usando uma variedade de métodos, dependendo do tipo de dado e do framework que você está usando. Abaixo estão várias abordagens comuns:
- Apenas Python: Use um loop simples ou um gerador para dividir listas ou arrays.
- NumPy: Use numpy.array_split para dividir arrays.
- PyTorch: Use DataLoader para eficiente agrupamento em redes neurais.
- TensorFlow: Use tf.data.Dataset para eficiente agrupamento e pipelines de dados.
- Pandas: Use compreensões de lista ou loops para dividir DataFrames.
1. Usando uma Função Simples em Python
Se você tem um conjunto de dados na forma de uma lista ou array do NumPy, você pode usar uma função personalizada para dividir os dados em lotes.
def split_into_batches(data, batch_size):
"""Dividir dados em lotes de um tamanho especificado."""
for i in range(0, len(data), batch_size):
yield data[i:i + batch_size]
# Exemplo de uso
dataset = [i for i in range(100)] # Exemplo de conjunto de dados
batch_size = 10
batches = list(split_into_batches(dataset, batch_size))
# Imprimir lotes
for batch in batches:
print(batch)2. Usando numpy.array_split
Se seu conjunto de dados estiver na forma de um array do NumPy, você pode usar a função numpy.array_split() para dividir o conjunto de dados em lotes.
import numpy as np
# Exemplo de conjunto de dados
dataset = np.arange(100)
# Dividir em lotes
batch_size = 10
batches = np.array_split(dataset, len(dataset) // batch_size)
# Imprimir lotes
for batch in batches:
print(batch)3. Usando torch.utils.data.DataLoader (PyTorch)
Se você está trabalhando com PyTorch, pode facilmente agrupar seu conjunto de dados usando DataLoader, que pode embaralhar e agrupar seus dados.
import torch
from torch.utils.data import DataLoader, TensorDataset
# Exemplo de conjunto de dados
data = torch.arange(100)
labels = torch.arange(100) # Suponha que você tenha rótulos também
# Criar um TensorDataset
dataset = TensorDataset(data, labels)
# Dividir em lotes usando DataLoader
batch_size = 10
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# Imprimir lotes
for batch_data, batch_labels in dataloader:
print(batch_data, batch_labels)Exemplo: Uma lista simples para alcançar o indexador
import math
import torch
import torch.nn as nn
X = torch.rand(1000,10, 4)
batch_size = 64
num_batches = math.ceil(X.size()[0]/batch_size)
X_list = [X[batch_size*y:batch_size*(y+1),:,:] for y in range(num_batches)]
print(X_list[0].size())4. Usando tensorflow.data.Dataset (TensorFlow)
Para TensorFlow, a API tf.data.Dataset oferece uma maneira de alto desempenho para agrupar conjuntos de dados.
import tensorflow as tf
# Exemplo de conjunto de dados
dataset = tf.data.Dataset.range(100)
# Dividir em lotes
batch_size = 10
batched_dataset = dataset.batch(batch_size)
# Imprimir lotes
for batch in batched_dataset:
print(batch.numpy())5. Usando pandas para DataFrames
Se seu conjunto de dados é um DataFrame do pandas, você pode dividi-lo em lotes segmentando-o.
import pandas as pd
# Exemplo de conjunto de dados
data = pd.DataFrame({'A': range(100), 'B': range(100)})
# Dividir em lotes
batch_size = 10
batches = [data[i:i+batch_size] for i in range(0, data.shape[0], batch_size)]
# Imprimir lotes
for batch in batches:
print(batch)Considerações Finais
Neste post, exploramos três métodos para dividir e processar dados em lotes, comparando seu desempenho e qualidade geral de código. Observamos que, embora os geradores por si só não melhorem necessariamente a eficiência, eles contribuem para uma solução mais elegante e legível. Em última análise, a eficácia de cada abordagem é influenciada por restrições de tempo e memória.
Qual abordagem você considera mais atraente?
Escolha o método que melhor se adapta ao formato dos seus dados e às suas necessidades de processamento.
Boa sorte!
Perguntas Frequentes Sobre Divisão de Conjuntos de Dados em Python
Como dividir um conjunto de dados em lotes em Python?
Para dividir um conjunto de dados em lotes em Python, você pode usar bibliotecas como NumPy ou PyTorch. Aqui está um exemplo simples usando NumPy:
import numpy as np
def create_batches(data, batch_size):
return np.array_split(data, np.ceil(len(data) / batch_size))
# Exemplo de uso
data = np.arange(10) # Conjunto de dados de exemplo
batches = create_batches(data, 3)
print(batches)
Essa função divide o conjunto de dados em lotes do tamanho especificado.
Como devo dividir meu conjunto de dados?
Ao dividir um conjunto de dados, considere as seguintes estratégias:
- Divisão Aleatória: Embaralhe o conjunto de dados e divida-o em conjuntos de treinamento, validação e teste.
- Divisão Estratificada: Assegure-se de que cada subconjunto mantenha a mesma distribuição de classes-alvo que o conjunto de dados original.
- Divisão Baseada em Tempo: Para dados de séries temporais, divida com base no tempo para manter a sequência.
A prática comum é usar uma combinação desses métodos para garantir uma amostra representativa em cada subconjunto.
Como dividir um conjunto de dados 80 20?
Para dividir um conjunto de dados em 80% para treinamento e 20% para teste, você pode usar a função train_test_split do módulo sklearn.model_selection:
from sklearn.model_selection import train_test_split
data = ... # Seu conjunto de dados
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
Esse código irá dividir aleatoriamente o conjunto de dados, alocando 80% para train_data e 20% para test_data.
Como escolho um tamanho de lote para um grande conjunto de dados?
A escolha de um tamanho de lote para um grande conjunto de dados envolve várias considerações:
- Restrições de Memória: Assegure-se de que o tamanho do lote se encaixa nos limites de memória da sua GPU ou CPU.
- Estabilidade do Treinamento: Tamanhos de lote menores podem levar a um treinamento mais estável, mas podem aumentar o tempo de treinamento.
- Dinamismo de Aprendizado: Tamanhos de lote maiores podem acelerar o treinamento, mas podem levar a uma pior generalização.
Uma abordagem comum é começar com um tamanho de lote de 32 ou 64 e ajustar com base no desempenho e na disponibilidade de recursos. A experimentação é fundamental para encontrar o tamanho de lote ideal para seu cenário específico.
Antes de concluirmos, se você está fazendo Testes de API e precisa de uma substituição para o Postman (que está ficando mais caro e oferecendo menos recursos), o APIDog é a sua escolha ideal!
Apidog é uma plataforma colaborativa projetada para a gestão e testes de APIs, semelhante ao Postman, mas com recursos adicionais que tornam o manuseio de datas mais fácil. Veja como isso pode ajudar: