
Já teve vontade de executar um poderoso modelo de linguagem na sua máquina local? Apresentando QwQ-32B, o LLM mais recente e poderoso da Alibaba disponível. Seja você um desenvolvedor, pesquisador ou apenas um curioso em tecnologia, executar o QwQ-32B localmente pode abrir um mundo de possibilidades—desde a construção de aplicações de IA personalizadas até a experimentação com tarefas avançadas de processamento de linguagem natural.
Neste guia, vamos guiá-lo por todo o processo, passo a passo. Usaremos ferramentas como Ollama e LM Studio para facilitar a configuração o máximo possível.
Como você deseja usar APIs com Ollama e uma Ferramenta de Teste de API, não se esqueça de conferir Apidog. É uma ferramenta fantástica para agilizar seus fluxos de trabalho de API, e a melhor parte? Você pode baixá-la gratuitamente!
Pronto para mergulhar? Vamos começar!
1. Entendendo o QwQ-32B?
Antes de entrarmos nos detalhes técnicos, vamos dedicar um momento para entender o que é QwQ-32B. O QwQ-32B é um modelo de linguagem de última geração com 32 bilhões de parâmetros, projetado para lidar com tarefas complexas de linguagem natural, como geração de texto, tradução e resumo. É uma ferramenta versátil para desenvolvedores e pesquisadores que buscam expandir os limites da IA.
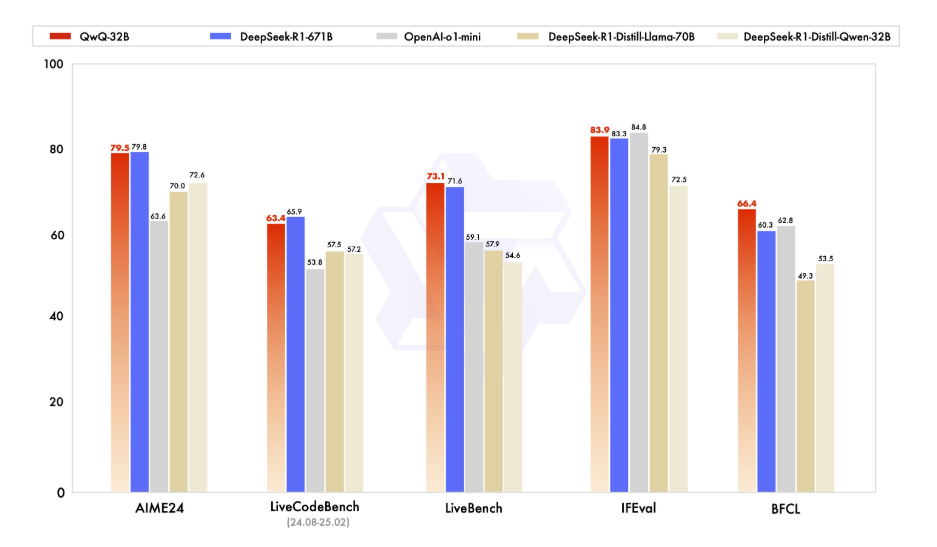
Executar o QwQ-32B localmente oferece controle total sobre o modelo, permitindo que você o personalize para casos de uso específicos sem depender de serviços baseados em nuvem. Privacidade, Personalização, Custo-efetividade e Acesso Offline são algumas das muitas vantagens que você pode aproveitar ao executar esse modelo localmente.
2. Requisitos
Sua máquina local precisará atender aos seguintes requisitos antes que você possa executar o QwQ-32B localmente:
- Hardware: Uma máquina potente com pelo menos 16GB de RAM e uma GPU de alto desempenho com no mínimo 24GB de VRAM (por exemplo, NVIDIA RTX 3090 ou melhor) para desempenho ideal.
- Software: Python 3.8 ou posterior, Git e um gerenciador de pacotes como pip ou conda.
- Ferramentas: Ollama e LMStudio (vamos cobrir isso em detalhes mais adiante).
3. Executar o QwQ-32B localmente usando Ollama
Ollama é uma estrutura leve que simplifica o processo de execução de grandes modelos de linguagem localmente. Veja como instalá-lo:
Passo 1: Baixar e Instalar o Ollama:
- Para Windows e macOS, baixe o arquivo executável do site oficial do Ollama e execute-o para instalar. Em seguida, siga as simples instruções de instalação fornecidas na configuração de instalação.
- Para usuários do Linux, você pode usar o seguinte comando:
curl -fsSL https://ollama.ai/install.sh | sh
- Verificar Instalação: Após a instalação, se você quiser verificar se instalou o Ollama corretamente, abra um terminal e execute:
ollama --version
- Se a instalação for bem-sucedida, você verá o número da versão.
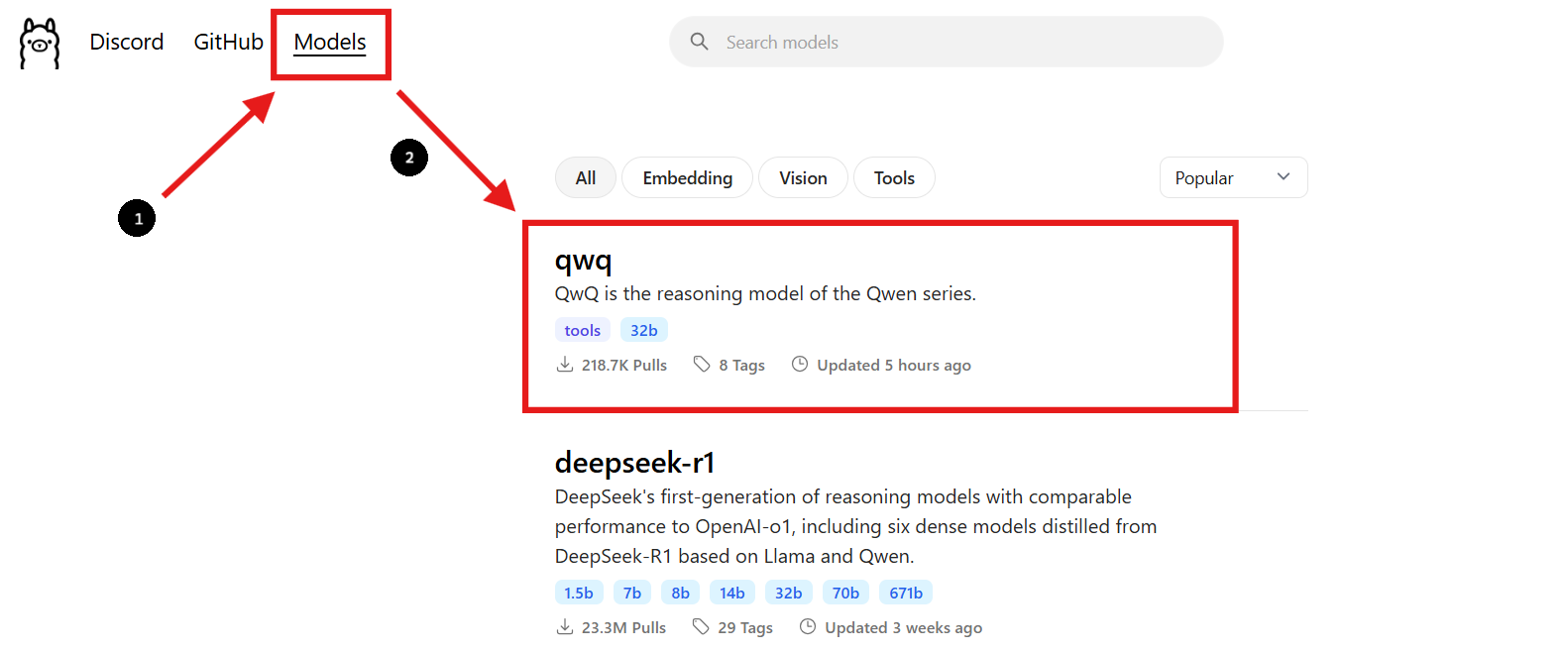
Passo 2: Encontrar o Modelo QwQ-32B
- Volte para o site do Ollama e navegue até a seção "Modelos".
- Use a barra de pesquisa para encontrar "QwQ-32B".
- Quando você encontrar o modelo QwQ-32B, verá o comando de instalação fornecido na página.
Passo 3: Baixar o Modelo QwQ-32B
- Abra uma nova janela de terminal para baixar o modelo e execute o seguinte comando:
ollama pull qwq:32b- Após o download ser concluído, você pode verificar se o modelo está instalado executando o seguinte comando:
ollama list
- O comando listará todos os modelos que você baixou usando o Ollama, confirmando que o QwQ-32B está disponível.
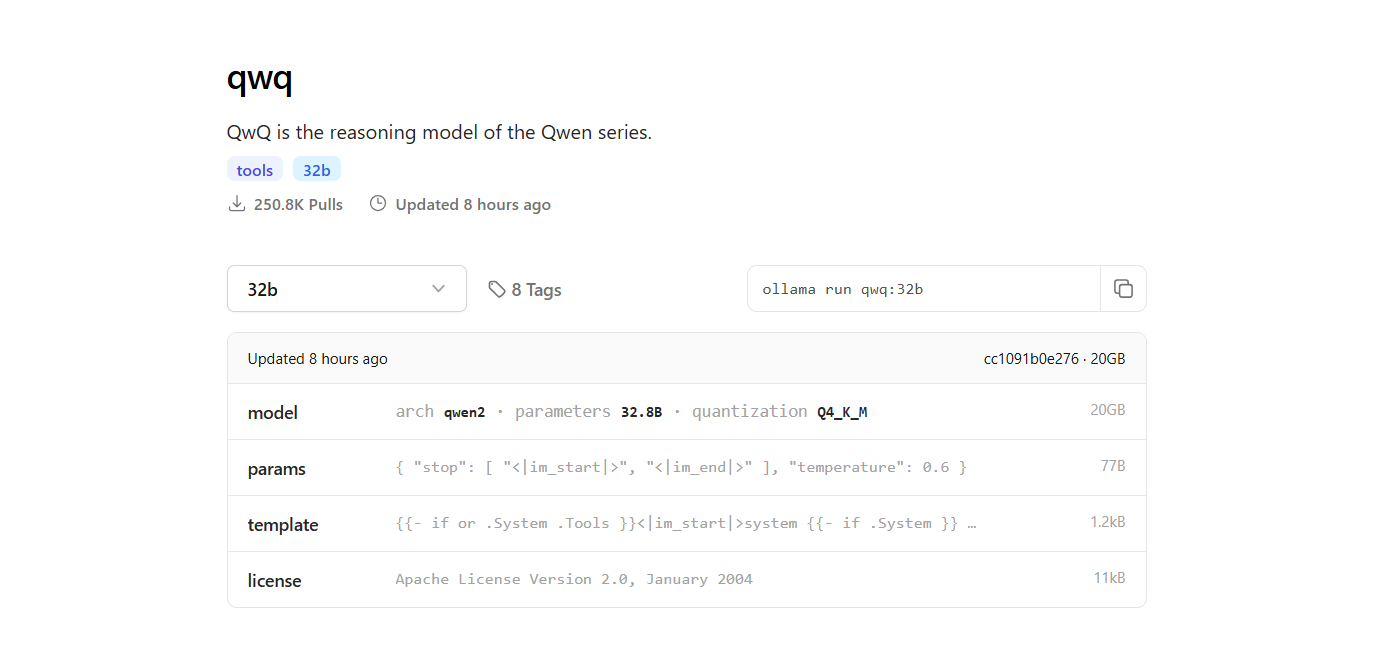
Passo 4: Executar o Modelo QwQ-32B
Executar o Modelo no Terminal:
- Para interagir diretamente com o modelo QwQ-32B no terminal, use o seguinte comando:
ollama run qwq:32b
- Você pode fazer perguntas ou fornecer comandos no terminal, e o modelo responderá de acordo.
Usar uma Interface de Chat Interativa:
- Alternativamente, você pode usar ferramentas como Chatbox ou OpenWebUI para criar uma interface gráfica interativa para conversar com o modelo QwQ-32B.
- Essas interfaces proporcionam uma maneira mais amigável de interagir com o modelo, especialmente se você preferir uma interface gráfica em vez de uma interface de linha de comando.
4. Executar o QwQ-32B localmente usando o LM Studio
LM Studio é uma interface amigável para executar e gerenciar modelos de linguagem localmente. Veja como configurá-lo:
Passo 1: Baixar o LM Studio:
- Para começar, visite o site oficial do LM Studio em lmstudio.ai. É aqui que você pode baixar o aplicativo LM Studio para o seu sistema operacional.
- Na página deles, navegue até a seção de download e selecione a versão que corresponde ao seu sistema operacional (Windows, macOS ou Linux).
Passo 2: Instalar o LM Studio:
- Siga as simples instruções de instalação para o seu sistema operacional.
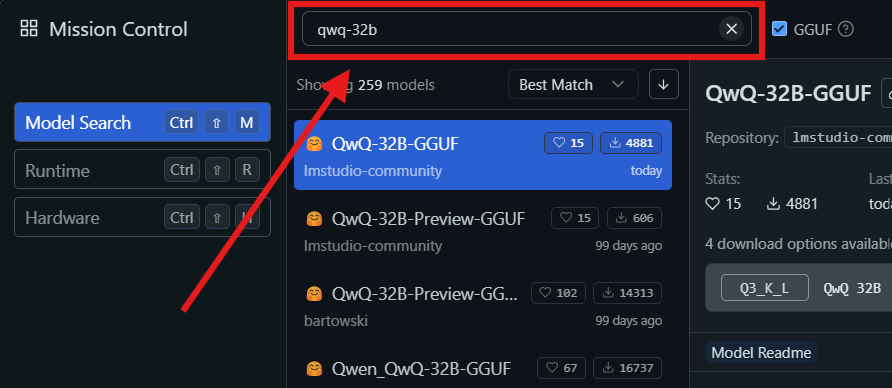
Passo 3: Encontrar e Baixar o Modelo QwQ-32B:
- Abra o LM Studio e navegue até a seção “Meus Modelos”.
- Clique no ícone de pesquisa e digite "QwQ-32B" na barra de pesquisa.
- Selecione a versão desejada do modelo QwQ-32B nos resultados da pesquisa. Você pode encontrar diferentes versões quantizadas, como um modelo quantizado de 4 bits, que pode ajudar a reduzir o uso de memória enquanto mantém o desempenho.
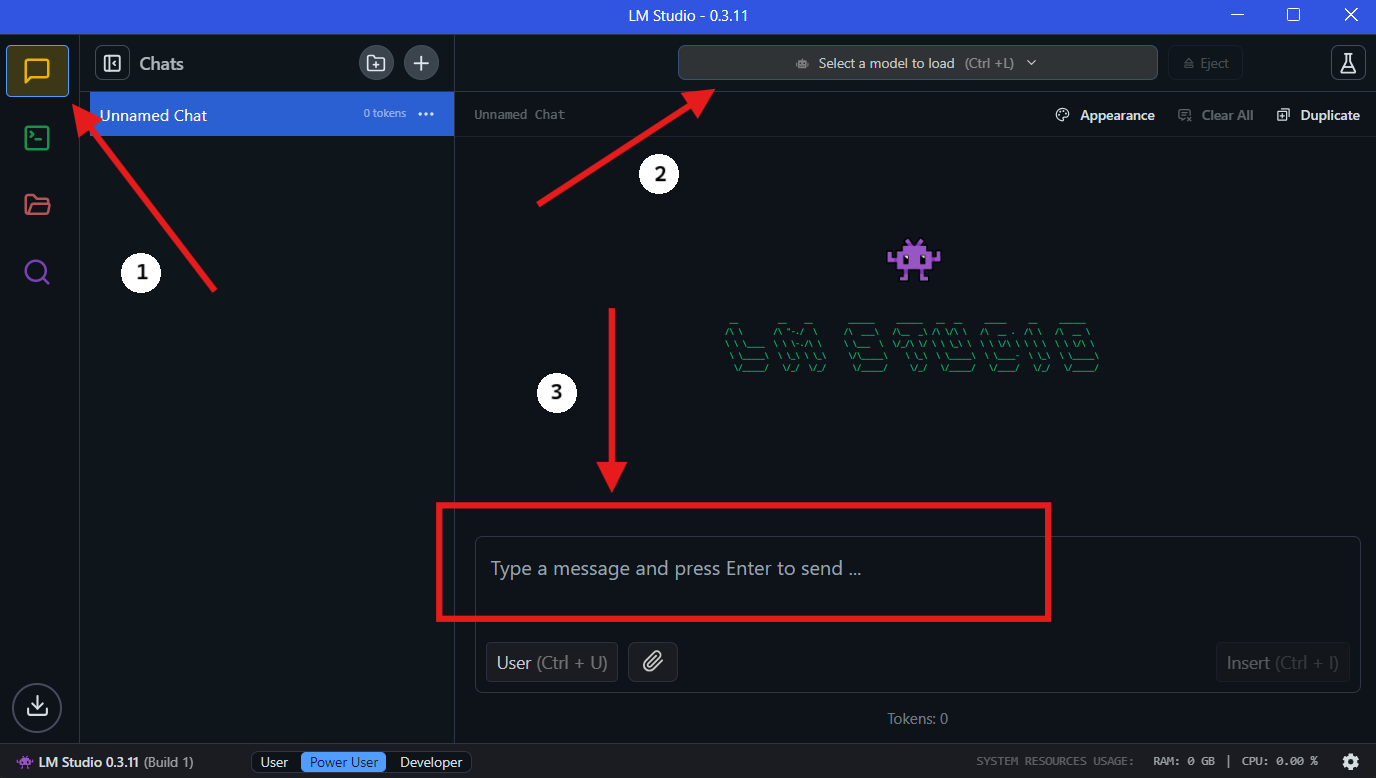
Passo 4: Executar o QwQ-32B Localmente no LM Studio
- Selecionar o Modelo: Assim que o download estiver completo, vá para a seção "Chat" no LM Studio. Na interface de chat, selecione o modelo QwQ-32B no menu suspenso.
- Interagir com o QwQ-32B: Comece a fazer perguntas ou fornecer comandos na janela de chat. O modelo processará seu input e gerará respostas.
- Configurar Configurações: Você pode ajustar as configurações do modelo com base em suas preferências na guia de "configuração avançada".
5. Agilizando o Desenvolvimento de API com Apidog
Integrar o QwQ-32B em suas aplicações requer um gerenciamento eficiente de APIs. O Apidog é uma plataforma colaborativa de desenvolvimento de APIs tudo-em-um que simplifica esse processo. Os principais recursos do Apidog incluem Design de API, Documentação de API e Depuração de API. Para tornar o processo de integração tranquilo, siga estes passos para configurar o Apidog para gerenciar e testar suas APIs com QwQ-32B.

Passo 1: Baixar e Instalar o Apidog
- Visite o site oficial do Apidog e baixe a versão compatível com o seu sistema operacional (Windows, macOS ou Linux).
- Siga as instruções de instalação para configurar o Apidog em sua máquina.
Passo 2: Criar um Novo Projeto de API
- Abra o Apidog e crie um novo projeto de API.
- Defina seus endpoints de API, especificando os formatos de requisição e resposta para interagir com o QwQ-32B.
Passo 3: Conectar o QwQ-32B ao Apidog via API Local
Para interagir com o QwQ-32B através de uma API, você precisa expor o modelo usando um servidor local. Use FastAPI ou Flask para criar uma API para seu modelo QwQ-32B local.
Exemplo: Configurando um Servidor FastAPI para o QwQ-32B:
from fastapi import FastAPI
from pydantic import BaseModel
import subprocess
app = FastAPI()
class RequestData(BaseModel):
prompt: str
@app.post("/generate")
async def generate_text(request: RequestData):
result = subprocess.run(
["python", "run_model.py", request.prompt],
capture_output=True, text=True
)
return {"response": result.stdout}
# Execute com: uvicorn script_name:app --reload
Passo 4: Testar Chamadas de API com Apidog
- Abra o Apidog e crie uma requisição POST para
http://localhost:8000/generate. - Insira um prompt de exemplo no corpo da requisição e clique em "Enviar".
- Se tudo estiver configurado corretamente, você deverá receber uma resposta gerada do QwQ-32B.
Passo 5: Automatizar Testes e Depuração da API
- Use os recursos de teste integrados do Apidog para simular diferentes entradas e analisar como o QwQ-32B responde.
- Ajuste os parâmetros da requisição e otimize o desempenho da API monitorando o tempo de resposta.
🚀 Com o Apidog, gerenciar seus fluxos de trabalho de API se torna effortless, garantindo uma integração suave entre o QwQ-32B e suas aplicações.
6. Dicas para Otimizar o Desempenho
Executar um modelo de 32 bilhões de parâmetros pode ser intensivo em recursos. Aqui estão algumas dicas para otimizar o desempenho:
- Use uma GPU de Alto Desempenho: Uma GPU potente acelerará significativamente a inferência.
- Ajuste o Tamanho do Lote: Experimente diferentes tamanhos de lote para encontrar a configuração ideal.
- Monitore o Uso de Recursos: Use ferramentas como
htopounvidia-smipara monitorar o uso da CPU e da GPU.
7. Solucionando Problemas Comuns
Executar o QwQ-32B localmente pode às vezes ser complicado. Aqui estão alguns problemas comuns e como solucioná-los:
- Fora de Memória: Reduza o tamanho do lote ou faça um upgrade no seu hardware.
- Desempenho Lento: Certifique-se de que seus drivers de GPU estão atualizados.
- Modelo Não Carregando: Verifique o caminho do modelo e a integridade do arquivo.
8. Considerações Finais
Executar o QwQ-32B localmente é uma maneira poderosa de aproveitar as capacidades de modelos avançados de IA sem depender de serviços em nuvem. Com ferramentas como Ollama e LM Studio, o processo é mais acessível do que nunca.
E lembre-se, se você estiver trabalhando com APIs, Apidog é sua ferramenta indispensável para testes e documentação. Baixe gratuitamente e leve seus fluxos de trabalho de API para o próximo nível!