

Você já quis executar modelos sofisticados de visão de IA diretamente em sua própria máquina, sem depender de serviços caros na nuvem ou se preocupar com a privacidade dos dados? Bem, você está com sorte! Hoje, vamos mergulhar fundo em como executar modelos Qwen 3 VL (Vision Language) localmente com Ollama e, acredite, isso vai ser um divisor de águas para o seu fluxo de trabalho de desenvolvimento de IA.
Agora, antes de mergulharmos nas questões técnicas, deixe-me perguntar algo: Você está cansado de atingir limites de taxa de API, pagar custos altíssimos por inferência na nuvem, ou simplesmente quer mais controle sobre seus modelos de IA? Se você acenou que sim, então este guia foi projetado especificamente para você. Além disso, se você está procurando uma ferramenta poderosa para testar e depurar suas APIs de IA locais, eu recomendo fortemente baixar o Apidog gratuitamente – é uma excelente plataforma de teste de API que funciona perfeitamente com os endpoints locais do Ollama.
Neste guia, abordaremos tudo o que você precisa para executar modelos Qwen 3 VL localmente usando Ollama, desde a instalação até a inferência, solução de problemas e até mesmo a integração com ferramentas como o Apidog. Ao final deste guia abrangente, você terá um Qwen3-VL de visão-linguagem totalmente funcional, privado e responsivo rodando perfeitamente em sua máquina local, e estará equipado com todo o conhecimento necessário para integrá-lo em seus projetos.
Então, aperte os cintos, pegue sua bebida favorita e vamos embarcar nesta emocionante jornada juntos.
Compreendendo o Qwen3-VL: O Revolucionário Modelo de Visão-Linguagem

Por que Qwen 3 VL? E Por que Executá-lo Localmente?
Antes de mergulharmos nas etapas técnicas, vamos falar sobre por que o Qwen 3 VL é importante e por que executá-lo localmente é um divisor de águas.
O Qwen 3 VL faz parte da série Qwen da Alibaba, mas foi especificamente projetado para tarefas de visão-linguagem. Ao contrário dos LLMs tradicionais que entendem apenas texto, o Qwen 3 VL pode:
- Analisar imagens e responder perguntas sobre elas (“O que há nesta foto?”)
- Gerar legendas detalhadas
- Extrair dados estruturados de gráficos, diagramas ou documentos
- Suportar RAG multimodal (geração aumentada por recuperação) com contexto visual
E por ser de código aberto (sob a licença Tongyi Qianwen), os desenvolvedores podem usá-lo, modificá-lo e implantá-lo livremente, desde que cumpram os termos da licença.
Agora, por que executá-lo localmente?
- Privacidade: Suas imagens e prompts nunca saem da sua máquina.
- Custo: Sem taxas de API ou limites de uso.
- Personalização: Ajuste fino, quantize ou integre com seus próprios pipelines.
- Acesso offline: Perfeito para ambientes seguros ou isolados.
Mas a implantação local costumava significar lidar com versões CUDA, ambientes Python e Dockerfiles enormes. Entre no Ollama.
Variantes de Modelo: Algo para Cada Caso de Uso
O Qwen3-VL vem em vários tamanhos para se adequar a diferentes configurações de hardware e casos de uso. Quer você esteja trabalhando em um laptop leve ou tenha acesso a uma workstation poderosa, há um modelo Qwen3-VL que se encaixa perfeitamente nas suas necessidades.
Modelos Densos (Arquitetura Tradicional):
- Qwen3-VL-2B: Perfeito para dispositivos de borda e aplicações móveis
- Qwen3-VL-4B: Ótimo equilíbrio entre desempenho e uso de recursos
- Qwen3-VL-8B: Excelente para tarefas de uso geral com raciocínio moderado
- Qwen3-VL-32B: Tarefas de ponta que exigem raciocínio forte e contexto extenso
Modelos Mixture-of-Experts (MoE) (Arquitetura Eficiente):
- Qwen3-VL-30B-A3B: Desempenho eficiente com apenas 3B parâmetros ativos
- Qwen3-VL-235B-A22B: Aplicações em larga escala com 235B parâmetros totais, mas apenas 22B ativos
A beleza dos modelos MoE é que eles ativam apenas um subconjunto de redes neurais "especialistas" para cada inferência, permitindo uma contagem massiva de parâmetros, mantendo os custos computacionais gerenciáveis.
Ollama: Sua Porta de Entrada para a Excelência da IA Local
Agora que entendemos o que o Qwen3-VL oferece, vamos falar sobre por que o Ollama é a plataforma ideal para executar esses modelos localmente. Pense no Ollama como o maestro de uma orquestra – ele orquestra todos os processos complexos que acontecem nos bastidores para que você possa se concentrar no que mais importa: usar seus modelos de IA.
O que é Ollama e Por que é Perfeito para Qwen 3 VL
Ollama é uma ferramenta de código aberto que permite executar grandes modelos de linguagem (e agora, modelos multimodais) localmente com um único comando. Pense nele como o “Docker para LLMs”, mas ainda mais simples.
Principais características:
- Aceleração automática de GPU (via Metal no macOS, CUDA no Linux)
- Biblioteca de modelos integrada (incluindo Llama 3, Mistral, Gemma e agora Qwen)
- API REST para fácil integração
- Leve e amigável para iniciantes
O melhor de tudo, o Ollama agora suporta modelos Qwen 3 VL, incluindo variantes como qwen3-vl:4b e qwen3-vl:8b. Estas são versões quantizadas otimizadas para hardware local – o que significa que você pode executá-las em GPUs de nível de consumidor ou até mesmo em laptops poderosos.
A Magia Técnica por Trás do Ollama
O que acontece nos bastidores quando você executa um comando Ollama? É como assistir a uma dança bem coreografada de processos tecnológicos:
1.Download e Cache de Modelo: O Ollama baixa e armazena em cache os pesos do modelo de forma inteligente, garantindo tempos de inicialização rápidos para modelos frequentemente usados.
2.Otimização de Quantização: Os modelos são otimizados automaticamente para a sua configuração de hardware, escolhendo o melhor método de quantização (4 bits, 8 bits, etc.) para sua GPU e RAM.
3.Gerenciamento de Memória: Técnicas avançadas de mapeamento de memória garantem o uso eficiente da memória da GPU, mantendo o alto desempenho.
4.Processamento Paralelo: O Ollama aproveita múltiplos núcleos de CPU e fluxos de GPU para máxima taxa de transferência.
Pré-requisitos: O Que Você Precisará Antes de Instalar
Antes de instalar qualquer coisa, vamos garantir que seu sistema esteja pronto.
Requisitos de Hardware
- RAM: Pelo menos 16 GB (32 GB recomendado para modelos de 8B)
- GPU: GPU NVIDIA com 8 GB+ VRAM (para Linux) ou Mac Apple Silicon (M1/M2/M3 com 16 GB+ de memória unificada)
- Armazenamento: 10–20 GB de espaço livre (os modelos são grandes!)
Requisitos de Software
- Sistema Operacional: macOS (12+) ou Linux (Ubuntu 20.04+ recomendado)
- Ollama: Versão mais recente (v0.1.40+ para suporte Qwen 3 VL)
- Opcional: Docker (se preferir implantação em contêiner), Python (para scripts avançados)
Guia de Instalação Passo a Passo: Seu Caminho para o Domínio da IA Local
Passo 1: Instalando o Ollama - A Base
Vamos começar com a base de toda a nossa configuração. Instalar o Ollama é surpreendentemente simples – ele foi projetado para ser acessível a todos, desde novatos em IA até desenvolvedores experientes.
Para Usuários de macOS:
1.Visite ollama.com/download
2.Baixe o instalador do macOS
3.Abra o arquivo baixado e arraste o Ollama para a sua pasta Aplicativos
4.Inicie o Ollama a partir da sua pasta Aplicativos ou da pesquisa Spotlight
O processo de instalação é incrivelmente suave no macOS, e você verá o ícone do Ollama aparecer na sua barra de menus assim que a instalação for concluída.
Para Usuários de Windows:
1.Navegue até ollama.com/download
2.Baixe o instalador do Windows (arquivo .exe)
3.Execute o instalador com privilégios de administrador
4.Siga o assistente de instalação (é bastante intuitivo)
5.Uma vez instalado, o Ollama iniciará automaticamente em segundo plano
Usuários de Windows podem ver uma notificação do Windows Defender – não se preocupe, isso é normal na primeira execução. Basta clicar em "Permitir" e o Ollama funcionará perfeitamente.
Para Usuários de Linux:
Usuários de Linux têm duas opções:
Opção A: Script de Instalação (Recomendado)
bash
curl -fsSL <https://ollama.com/install.sh> | sh
Opção B: Instalação Manual
bash
# Baixe o binário mais recente do Ollamacurl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# Torne-o executávelchmod +x ollama
# Mova para o PATHsudo mv ollama /usr/local/bin/
Passo 2: Verificando Sua Instalação
Agora que o Ollama está instalado, vamos garantir que tudo esteja funcionando corretamente. Pense nisso como um teste de fumaça para garantir que nossa base seja sólida.
Abra seu terminal (ou prompt de comando no Windows) e execute:
bash
ollama --version
Você deve ver uma saída semelhante a:
ollama version is 0.1.0
Em seguida, vamos testar a funcionalidade básica:
bash
ollama serve
Este comando inicia o servidor Ollama. Você deve ver uma saída indicando que o servidor está rodando em http://localhost:11434. Deixe o servidor rodar – vamos usá-lo para testar nossa instalação do Qwen3-VL.
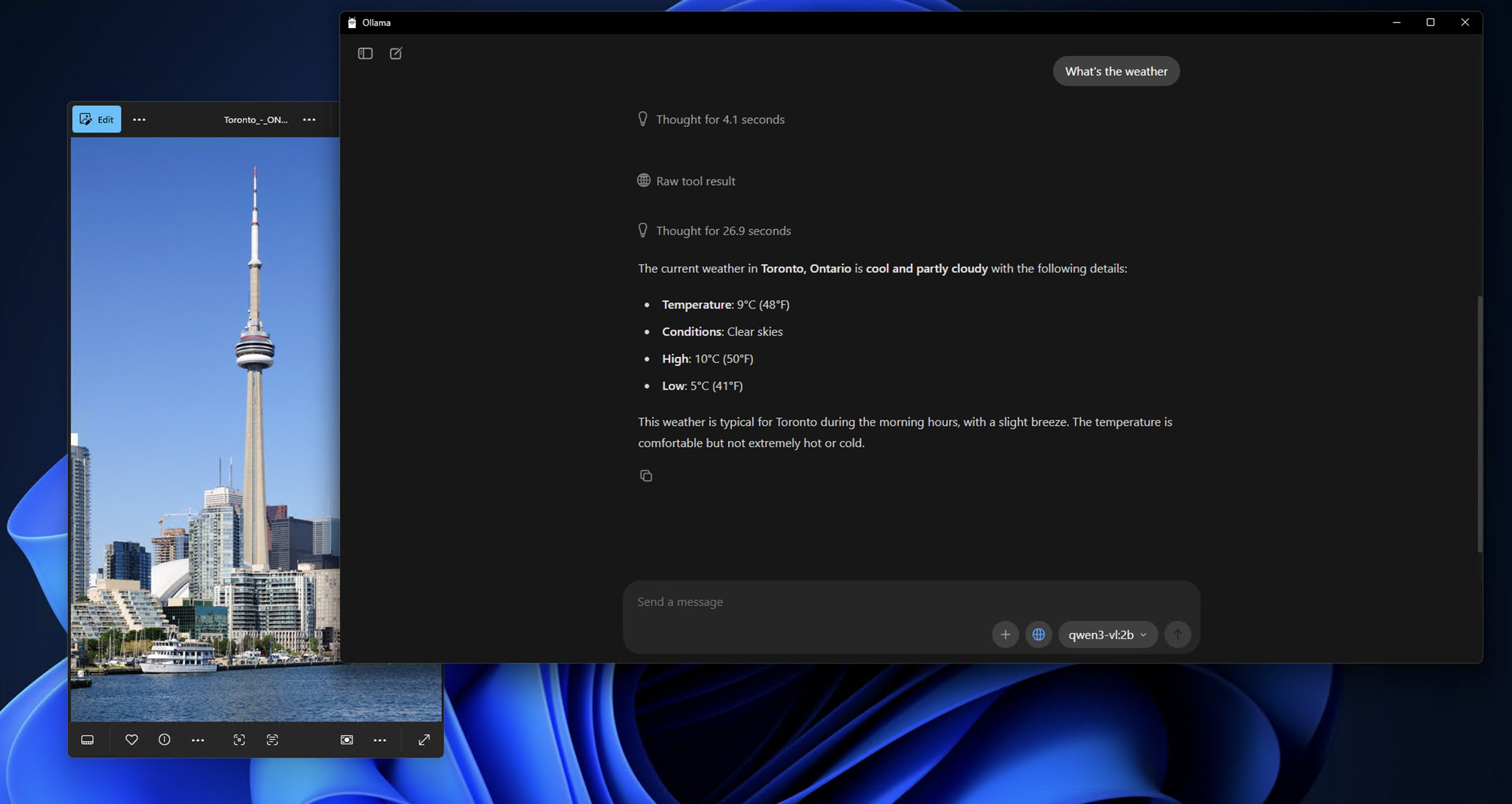
Passo 3: Baixando e Executando Modelos Qwen3-VL
Agora a parte emocionante! Vamos baixar e executar nosso primeiro modelo Qwen3-VL. Começaremos com um modelo menor para testar as águas, depois passaremos para variantes mais poderosas.
Testando com Qwen3-VL-4B (Ótimo Ponto de Partida):
bash
ollama run qwen3-vl:4b
Este comando irá:
1.Baixar o modelo Qwen3-VL-4B (aproximadamente 2.8GB)
2.Otimizá-lo para o seu hardware
3.Iniciar uma sessão de chat interativa
Executando Outras Variantes de Modelo:
Se você tiver hardware mais potente, experimente estas alternativas:
bash
# Para sistemas com GPU de 8GB+ollama run qwen3-vl:8b
# Para sistemas com RAM de 16GB+ollama run qwen3-vl:32b
# Para sistemas de ponta com múltiplas GPUsollama run qwen3-vl:30b-a3b
# Para desempenho máximo (requer hardware sério)ollama run qwen3-vl:235b-a22b
Passo 4: Primeira Interação com Seu Qwen3-VL Local
Assim que o modelo for baixado e estiver em execução, você verá um prompt como este:
Send a message (type /? for help)
Vamos testar as capacidades do modelo com uma análise de imagem simples:
Prepare uma Imagem de Teste:
Encontre qualquer imagem em seu computador – pode ser uma foto, captura de tela ou ilustração. Para este exemplo, vou assumir que você tem uma imagem chamada test_image.jpg em seu diretório atual.

Teste de Chat Interativo:
bash
What do you see in this image? /path/to/your/image.jpg
Alternativa: Usando a API para Testes
Se você preferir testar programaticamente, pode usar a API Ollama. Aqui está um teste simples usando curl:
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "What is in this image? Describe it in detail.",
"images": ["base64_encoded_image_data_here"]
}'

Passo 5: Opções de Configuração Avançadas
Agora que você tem uma instalação funcionando, vamos explorar algumas opções de configuração avançadas para otimizar sua configuração para seu hardware e caso de uso específicos.
Otimização de Memória:
Se você estiver enfrentando problemas de memória, pode ajustar o comportamento de carregamento do modelo:
bash
# Define o uso máximo de memória (ajuste com base na sua RAM)export OLLAMA_MAX_LOADED_MODELS=1
# Habilita o offloading da GPUexport OLLAMA_GPU=1
# Define uma porta personalizada (se 11434 já estiver em uso)export OLLAMA_HOST=0.0.0.0:11435
Opções de Quantização:
Para sistemas com VRAM limitada, você pode forçar níveis de quantização específicos:
bash
# Carrega o modelo com quantização de 4 bits (mais compatível, mais lento)ollama run qwen3-vl:4b --format json
# Carrega com quantização de 8 bits (equilibrado)ollama run qwen3-vl:8b --format json
Configuração Multi-GPU:
Se você tiver várias GPUs, pode especificar quais usar:
bash
# Usa IDs de GPU específicos (Linux/macOS)export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# No macOS com múltiplas GPUs Apple Siliconexport CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
Testando e Integrando com Apidog: Garantindo Qualidade e Desempenho

Agora que você tem o Qwen3-VL rodando localmente, vamos falar sobre como testá-lo e integrá-lo adequadamente em seu fluxo de trabalho de desenvolvimento. É aqui que o Apidog realmente brilha como uma ferramenta indispensável para desenvolvedores de IA.
Apidog não é apenas mais uma ferramenta de teste de API – é uma plataforma abrangente projetada especificamente para fluxos de trabalho modernos de desenvolvimento de API. Ao trabalhar com modelos de IA locais como o Qwen3-VL, você precisa de uma ferramenta que possa:
1.Lidar com Estruturas JSON Complexas: As respostas de modelos de IA geralmente contêm JSON aninhado com tipos de conteúdo variados
2.Suportar Uploads de Arquivos: Muitos modelos de IA precisam de entradas de imagem, vídeo ou documento
3.Gerenciar Autenticação: Teste seguro de endpoints com tratamento de autenticação adequado
4.Criar Testes Automatizados: Testes de regressão para consistência de desempenho do modelo
5.Gerar Documentação: Crie automaticamente documentação de API a partir de seus casos de teste
Solução de Problemas Comuns
Mesmo com a simplicidade do Ollama, você pode encontrar alguns obstáculos. Aqui estão soluções para problemas frequentes.
❌ “Modelo não encontrado” ou “Modelo não suportado”
- Certifique-se de estar usando o Ollama v0.1.40 ou mais recente
- Execute
ollama pull qwen3-vl:4bnovamente – às vezes o download falha silenciosamente
❌ “Sem memória” na GPU
- Tente a versão 4B em vez da 8B
- Feche outros aplicativos que utilizam muito a GPU (Chrome, jogos, etc.)
- No Linux, verifique a VRAM com
nvidia-smi
❌ Imagem não reconhecida
- Confirme que a imagem tem menos de 4MB
- Use PNG ou JPG (evite HEIC, BMP)
- Certifique-se de que a string base64 não tenha quebras de linha (use
base64 -w 0no Linux)
❌ Inferência lenta na CPU
- O Qwen 3 VL é grande, mesmo quantizado. Espere 1–5 tokens/segundo na CPU
- Atualize para Apple Silicon ou GPU NVIDIA para um aumento de velocidade de 10x
Casos de Uso Reais para Qwen 3 VL Local
Por que passar por todo esse trabalho? Aqui estão aplicações práticas:
- Inteligência de Documentos: Extraia tabelas, assinaturas ou cláusulas de PDFs digitalizados
- Ferramentas de Acessibilidade: Descreva imagens para usuários com deficiência visual
- Bots de Conhecimento Interno: Responda a perguntas sobre diagramas ou painéis internos
- Educação: Construa um tutor que explique problemas de matemática a partir de fotos
- Análise de Segurança: Analise diagramas de rede ou capturas de tela de arquitetura de sistema
Por ser local, você evita enviar visuais sensíveis para APIs de terceiros – uma grande vantagem para empresas e desenvolvedores preocupados com a privacidade.
Conclusão: Sua Jornada na Excelência da IA Local
Parabéns! Você acaba de completar uma jornada épica no mundo da IA local com Qwen3-VL e Ollama. A esta altura, você deve ter:
- Uma instalação Qwen3-VL totalmente funcional rodando localmente
- Configuração de teste abrangente com Apidog
- Compreensão profunda das capacidades e limitações do modelo
- Conhecimento prático para integrar esses modelos em aplicações do mundo real
- Habilidades de solução de problemas para lidar com questões comuns
- Estratégias de prova de futuro para sucesso contínuo
O fato de você ter chegado até aqui mostra seu compromisso em entender e aproveitar a tecnologia de IA de ponta. Você não apenas instalou um modelo – você ganhou experiência em uma tecnologia que está remodelando a forma como interagimos com informações visuais e textuais.
O Futuro é a IA Local
O que realizamos aqui representa mais do que apenas uma configuração técnica – é um passo em direção a um futuro onde a IA é acessível, privada e sob controle individual. À medida que esses modelos continuam a melhorar e se tornam mais eficientes, estamos caminhando para um mundo onde capacidades sofisticadas de IA estão disponíveis para todos, independentemente de seu orçamento ou experiência técnica.
Lembre-se, a jornada não termina aqui. A tecnologia de IA evolui rapidamente, e manter a curiosidade, a adaptabilidade e o engajamento com a comunidade garantirá que você continue a aproveitar essas ferramentas poderosas de forma eficaz.
Considerações Finais
Executar o Qwen 3 VL localmente com Ollama não é apenas uma demonstração de tecnologia ou sobre conveniência ou economia de custos – é um vislumbre do futuro da IA no dispositivo. À medida que os modelos se tornam mais eficientes e o hardware mais poderoso, veremos mais desenvolvedores lançarem recursos privados e multimodais diretamente em seus aplicativos. Você agora tem as ferramentas para explorar a tecnologia de IA sem limitações, experimentar livremente e construir aplicações que são importantes para você e sua organização.
A combinação das impressionantes capacidades multimodais do Qwen3-VL e da interface amigável do Ollama cria oportunidades de inovação que antes estavam disponíveis apenas para grandes corporações com recursos massivos. Você agora faz parte de uma comunidade crescente de desenvolvedores que estão democratizando a tecnologia de IA.
E com ferramentas como Ollama simplificando a implantação e Apidog otimizando o desenvolvimento de API, a barreira de entrada nunca foi tão baixa.
Então, seja você um hacker solo, um fundador de startup ou um engenheiro corporativo, agora é o momento perfeito para experimentar modelos de visão-linguagem de forma segura, acessível e local.