
O mundo da Inteligência Artificial (IA) está evoluindo a uma velocidade impressionante, com Modelos de Linguagem de Grande Escala (LLMs) como ChatGPT, Claude e Gemini capturando a imaginação global. Essas ferramentas poderosas podem escrever código, redigir e-mails, responder a perguntas complexas e até gerar conteúdo criativo. No entanto, o uso desses serviços baseados em nuvem frequentemente levanta preocupações sobre privacidade de dados, custos potenciais e a necessidade de uma conexão contínua com a internet.
Apresentamos Ollama.
Ollama é uma ferramenta poderosa e de código aberto projetada para democratizar o acesso a grandes modelos de linguagem, permitindo que você os baixe, execute e gerencie diretamente no seu próprio computador. Ela simplifica o processo muitas vezes complexo de configuração e interação com modelos de IA de ponta localmente.
Por que Usar Ollama?

Executar LLMs localmente com Ollama oferece várias vantagens convincentes:
- Privacidade: Seus prompts e as respostas do modelo permanecem na sua máquina. Nenhum dado é enviado para servidores externos, a menos que você explicitamente configure para fazê-lo. Isso é crucial para informações sensíveis ou trabalho proprietário.
- Acesso Offline: Uma vez que um modelo é baixado, você pode usá-lo sem uma conexão à internet, tornando-o perfeito para viagens, locais remotos ou situações com conectividade irregular.
- Personalização: Ollama permite que você modifique facilmente os modelos usando 'Modelfiles', permitindo que você adapte seu comportamento, prompts de sistema e parâmetros às suas necessidades específicas.
- Economia: Não há taxas de assinatura ou encargos por token. O único custo é o hardware que você já possui e a eletricidade para executá-lo.
- Exploração e Aprendizado: Ela oferece uma plataforma fantástica para experimentar diferentes modelos de código aberto, entender suas capacidades e limitações e aprender mais sobre como os LLMs funcionam internamente.
Este artigo é voltado para iniciantes que estão confortáveis usando uma interface de linha de comando (como Terminal no macOS/Linux ou Prompt de Comando/PowerShell no Windows) e desejam começar a explorar o mundo dos LLMs locais com Ollama. Vamos guiá-lo para entender os princípios básicos, instalar o Ollama, executar seu primeiro modelo, interagir com ele e explorar personalizações básicas.
Quer uma plataforma integrada, tudo-em-um para sua equipe de desenvolvedores trabalharem juntas com máxima produtividade?
Apidog atende todas as suas demandas e substitui o Postman a um preço muito mais acessível!

Como Funciona o Ollama?
Antes de mergulhar na instalação, vamos esclarecer alguns conceitos fundamentais.
O que são Modelos de Linguagem de Grande Escala (LLMs)?
Pense em um LLM como um sistema de autocompletar incrivelmente avançado, treinado em vastas quantidades de texto e código da internet. Ao analisar padrões nesses dados, ele aprende gramática, fatos, habilidades de raciocínio e diferentes estilos de escrita. Quando você lhe fornece um prompt (texto de entrada), ele prevê a sequência de palavras mais provável a seguir, gerando uma resposta coerente e frequentemente perspicaz. Diferentes LLMs são treinados com diferentes conjuntos de dados, tamanhos e arquiteturas, levando a variações em suas forças, fraquezas e personalidades.
Como Funciona o Ollama?
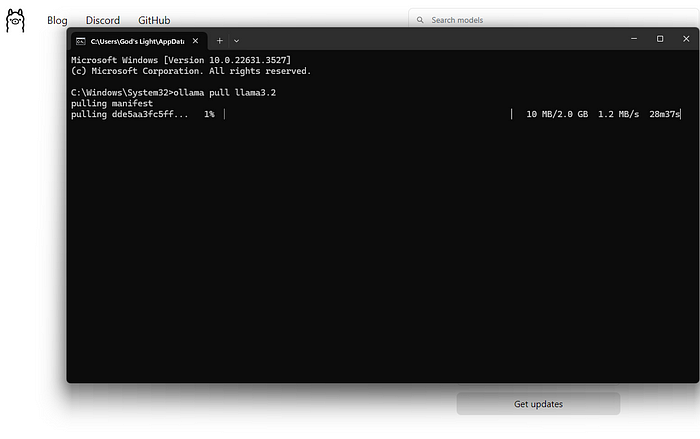
Ollama atua como um gerenciador e executor desses LLMs na sua máquina local. Suas funções principais incluem:
- Download do Modelo: Ele busca pesos e configurações de LLM pré-empacotados de uma biblioteca central (semelhante ao modo como o Docker puxa imagens de contêiner).
- Execução do Modelo: Ele carrega o modelo escolhido na memória (RAM) do seu computador e potencialmente utiliza sua placa de vídeo (GPU) para aceleração.
- Fornecendo Interfaces: Oferece uma interface de linha de comando simples (CLI) para interação direta e também executa um servidor web local que fornece uma API (Interface de Programação de Aplicações) para que outros aplicativos se comuniquem com o LLM em execução.
Requisitos de Hardware para Ollama: Meu Computador Conseguirá Rodá-lo?
Executar LLMs localmente pode ser exigente, principalmente para a RAM (Memória de Acesso Aleatório) do seu computador. O tamanho do modelo que você deseja rodar determina a RAM mínima necessária.
- Modelos Pequenos (por exemplo, ~3 bilhões de parâmetros como Phi-3 Mini): Podem rodar razoavelmente bem com 8GB de RAM, embora mais seja sempre melhor para um desempenho mais suave.
- Modelos Médios (por exemplo, 7-8 bilhões de parâmetros como Llama 3 8B, Mistral 7B): Geralmente exigem pelo menos 16GB de RAM. Este é um ponto doce comum para muitos usuários.
- Modelos Grandes (por exemplo, 13B+ parâmetros): Frequentemente necessitam de 32GB de RAM ou mais. Modelos muito grandes (70B+) podem exigir 64GB ou mesmo 128GB.
Outros Fatores que você pode precisar considerar:
- CPU (Unidade Central de Processamento): Embora importante, a maioria das CPUs modernas é adequada. CPUs mais rápidas ajudam, mas a RAM geralmente é o gargalo.
- GPU (Unidade de Processamento Gráfico): Ter uma GPU poderosa e compatível (especialmente GPUs NVIDIA no Linux/Windows ou GPUs Apple Silicon no macOS) pode acelerar significativamente o desempenho do modelo. O Ollama detecta automaticamente e utiliza GPUs compatíveis se os drivers necessários estiverem instalados. No entanto, uma GPU dedicada não é estritamente necessária; o Ollama pode rodar modelos apenas na CPU, embora mais lentamente.
- Espaço em Disco: Você precisará de espaço em disco suficiente para armazenar os modelos baixados, que podem variar de alguns gigabytes a dezenas ou até centenas de gigabytes, dependendo do tamanho e do número de modelos que você baixar.
Recomendação para Iniciantes: Comece com modelos menores (como phi3, mistral ou llama3:8b) e certifique-se de ter pelo menos 16GB de RAM para uma experiência inicial confortável. Verifique o site do Ollama ou a biblioteca de modelos para recomendações específicas de RAM para cada modelo.
Como Instalar Ollama no Mac, Linux e Windows (Usando WSL)
O Ollama suporta macOS, Linux e Windows (atualmente em prévia, frequentemente exigindo WSL).
Passo 1: Pré-requisitos
- Sistema Operacional: Uma versão suportada de macOS, Linux ou Windows (com WSL2 recomendado).
- Linha de Comando: Acesso ao Terminal (macOS/Linux) ou Prompt de Comando/PowerShell/terminal WSL (Windows).
Passo 2: Baixando e Instalando o Ollama
O processo varia um pouco dependendo do seu sistema operacional:
- macOS:
- Vá para o site oficial do Ollama: https://ollama.com
- Clique no botão "Baixar", depois selecione "Baixar para macOS".
- Uma vez que o arquivo
.dmgé baixado, abra-o. - Arraste o ícone do aplicativo
Ollamapara a sua pastaApplications. - Você pode precisar conceder permissões na primeira vez que executá-lo.
- Linux:
A maneira mais rápida geralmente é através do script de instalação oficial. Abra seu terminal e execute:
curl -fsSL <https://ollama.com/install.sh> | sh
Esse comando baixa o script e o executa, instalando o Ollama para o seu usuário. Ele também tentará detectar e configurar o suporte a GPU, se aplicável (os drivers NVIDIA são necessários).
Siga quaisquer prompts exibidos pelo script. Instruções de instalação manual também estão disponíveis no repositório do Ollama no GitHub, se você preferir.
- Windows (Prévia):
- Vá para o site oficial do Ollama: https://ollama.com
- Clique no botão "Baixar", depois selecione "Baixar para Windows (Prévia)".
- Execute o instalador executável baixado (
.exe). - Siga os passos do assistente de instalação.
- Nota Importante: O Ollama no Windows depende fortemente do Subsistema do Windows para Linux (WSL2). O instalador pode solicitar que você instale ou configure o WSL2 se ainda não estiver configurado. A aceleração por GPU normalmente requer configurações específicas do WSL e drivers NVIDIA instalados dentro do ambiente WSL. Usar o Ollama pode parecer mais nativo dentro de um terminal WSL.
Passo 3: Verificando a Instalação
Uma vez instalado, você precisa verificar se o Ollama está funcionando corretamente.
Abrir seu terminal ou prompt de comando. (No Windows, é frequentemente recomendado usar um terminal WSL).
Digite o seguinte comando e pressione Enter:
ollama --version
Se a instalação foi bem-sucedida, você verá uma saída exibindo o número da versão instalada do Ollama, como:
versão do ollama é 0.1.XX
Se você ver isso, o Ollama está instalado e pronto para usar! Se você encontrar um erro como "comando não encontrado", verifique novamente os passos de instalação, garanta que o Ollama foi adicionado ao PATH do sistema (o instalador geralmente cuida disso), ou tente reiniciar seu terminal ou computador.
Introdução: Executando Seu Primeiro Modelo com Ollama
Com o Ollama instalado, você pode agora baixar e interagir com um LLM.
Conceito: O Registro de Modelos Ollama
Ollama mantém uma biblioteca de modelos de código aberto prontamente disponíveis. Quando você pede ao Ollama para executar um modelo que ele não possui localmente, ele o baixa automaticamente desse registro. Pense nisso como docker pull para LLMs. Você pode navegar pelos modelos disponíveis na seção de biblioteca do site do Ollama.
Escolhendo um Modelo
Para iniciantes, é melhor começar com um modelo relativamente pequeno e bem equilibrado. Boas opções incluem:
llama3:8b: Modelo de última geração da Meta AI (versão de 8 bilhões de parâmetros). Excelente desempenho geral, bom em seguir instruções e programar. Exige ~16GB de RAM.mistral: Modelo popular de 7 bilhões de parâmetros da Mistral AI. Conhecido por seu forte desempenho e eficiência. Exige ~16GB de RAM.phi3: Modelo de linguagem pequeno recente da Microsoft (SLM). Muito capaz para seu tamanho, bom para hardware menos poderoso. A versãophi3:minipode rodar em 8GB de RAM.gemma:7b: Série de modelos abertos do Google. Outro forte candidato na faixa de 7B.
Verifique a biblioteca do Ollama para detalhes sobre o tamanho de cada modelo, requisitos de RAM e casos de uso típicos.
Baixando e Executando um Modelo (Linha de Comando)
O comando principal que você usará é ollama run.
Abrir seu terminal.
Escolha um nome de modelo (por exemplo, llama3:8b).
Digite o comando:
ollama run llama3:8b
Pressione Enter.
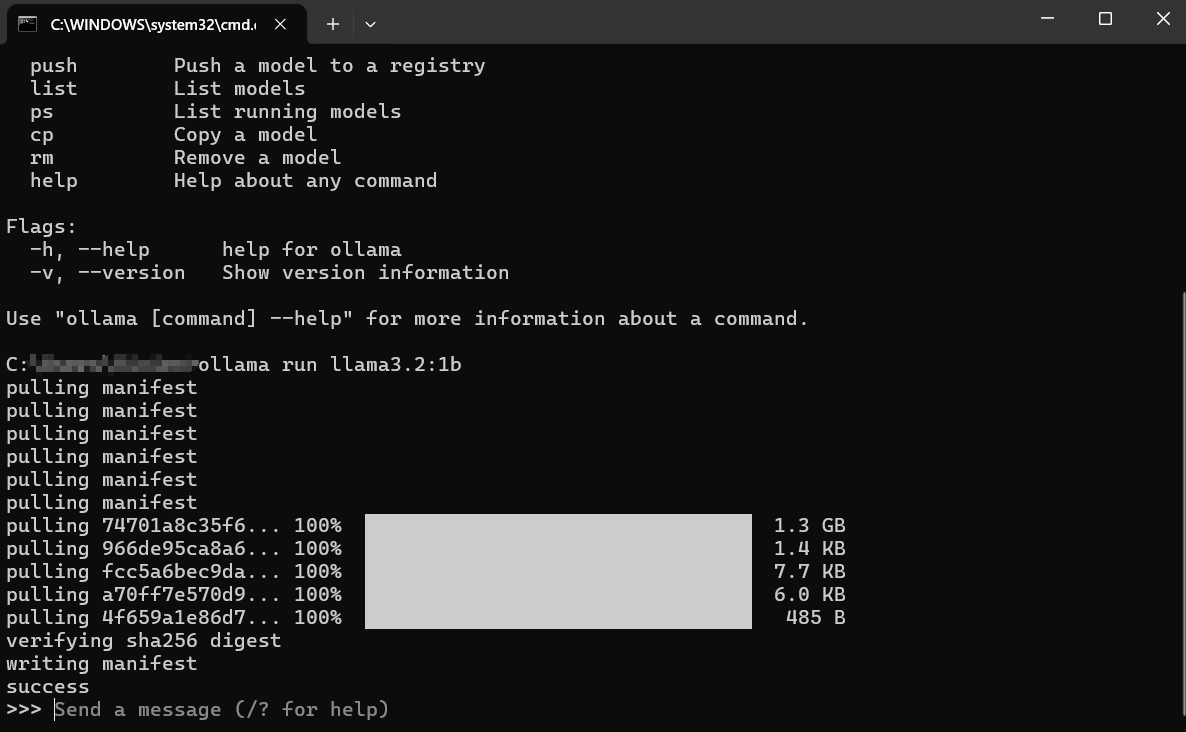
O que Acontece a Seguir?
Download: Se você não tiver llama3:8b localmente, o Ollama exibirá barras de progresso enquanto baixa as camadas do modelo. Isso pode levar algum tempo, dependendo da sua velocidade de internet e do tamanho do modelo (frequentemente vários gigabytes).
Carregamento: Uma vez baixado, o Ollama carrega o modelo na RAM do seu computador (e na memória da GPU, se aplicável). Você pode ver mensagens sobre detecção de hardware.
Bate-papo Interativo: Após o carregamento, você verá um prompt como: Isso significa que o modelo está pronto! Você agora está em uma sessão de bate-papo interativa diretamente com o LLM em execução na sua máquina.
>>> Envie uma mensagem (/? para ajuda)
Interagindo com o Modelo:
- Digite sua pergunta ou instrução (seu "prompt") após o
>>>e pressione Enter. - O modelo processará sua entrada e gerará uma resposta, transmitindo-a de volta para o seu terminal.
- Você pode continuar a conversa digitando prompts de seguimento. O modelo mantém o contexto da sessão atual.
Exemplo de Interação:
> Envie uma mensagem (/? para ajuda)
Explique o conceito de fotossíntese em termos simples.
>
A fotossíntese é como as plantas fazem sua própria comida! Elas pegam três ingredientes principais:
1. **Luz Solar:** Energia do sol.
2. **Água:** Absorvida pelas raízes.
3. **Dióxido de Carbono:** Um gás que elas retiram do ar através de pequenos buracos em suas folhas.
Usando a energia da luz solar, as plantas combinam a água e o dióxido de carbono dentro de partes especiais de suas células chamadas cloroplastos. Esse processo cria duas coisas:
1. **Açúcar (Glicose):** Essa é a comida da planta, dando-lhe energia para crescer.
2. **Oxigênio:** Um gás que a planta libera de volta para o ar, que os animais (como nós!) precisam para respirar.
Portanto, de forma simples: as plantas usam luz solar, água e ar para fazer sua própria comida e liberam o oxigênio que precisamos!
>
>
Saindo da Sessão:
Quando você terminar de conversar, digite /bye e pressione Enter. Isso descarregará o modelo da memória e retornará você ao seu prompt de terminal regular. Você também pode frequentemente usar Ctrl+D.
Listando Modelos Baixados
Para ver quais modelos você baixou localmente, use o comando ollama list:
ollama list
A saída mostrará os nomes dos modelos, seus IDs únicos, tamanhos e quando foram modificados pela última vez:
NOME ID TAMANHO MODIFICADO
llama3:8b 871998b83999 4.7 GB 5 dias atrás
mistral:latest 8ab431d3a87a 4.1 GB 2 semanas atrás
Removendo Modelos
Modelos ocupam espaço em disco. Se você não precisar mais de um modelo específico, pode removê-lo usando o comando ollama rm seguido do nome do modelo:
ollama rm mistral:latest
Ollama confirmará a exclusão. Isso apenas remove os arquivos baixados; você sempre pode executar ollama run mistral:latest novamente para baixá-lo novamente mais tarde.
Como Obter Melhores Resultados do Ollama
Executar modelos é apenas o começo. Aqui estão algumas maneiras de obter melhores resultados:
Compreendendo Prompts (Fundamentos da Engenharia de Prompts)
A qualidade da saída do modelo depende fortemente da qualidade da sua entrada (o prompt).
- Seja Claro e Específico: Diga ao modelo exatamente o que você deseja. Em vez de "Escreva sobre cães," tente "Escreva um poema curto e alegre sobre um golden retriever brincando de buscar."
- Forneça Contexto: Se estiver fazendo perguntas de seguimento, certifique-se de que as informações de fundo necessárias estejam presentes no prompt ou anteriormente na conversa.
- Especifique o Formato: Peça por listas, pontos destacados, blocos de código, tabelas ou um tom específico (por exemplo, "Explique como se eu tivesse cinco anos," "Escreva em um tom formal").
- Itere: Não espere perfeição na primeira tentativa. Se a saída não estiver certa, reformule seu prompt, adicione mais detalhes ou peça ao modelo para refinar sua resposta anterior.
Experimentos com Diferentes Modelos
Diferentes modelos se destacam em diferentes tarefas.
Llama 3geralmente é ótimo para conversação geral, seguir instruções e programação.Mistralé conhecido por seu equilíbrio entre desempenho e eficiência.Phi-3é surpreendentemente capaz para escrita criativa e sumarização, apesar de seu tamanho menor.- Modelos especificamente ajustados para programação (como
codellamaoustarcoder) podem ter um desempenho melhor em tarefas de programação.
Experimente! Execute o mesmo prompt em diferentes modelos usando ollama run <nome_do_modelo> para ver qual atende melhor às suas necessidades para uma tarefa específica.
Prompts de Sistema (Definindo o Contexto)
Você pode orientar o comportamento ou a persona geral do modelo para uma sessão usando um "prompt de sistema." Isso é como fornecer instruções de fundo para a IA antes da conversa começar. Embora personalizações mais profundas envolvam Modelfiles (cobrindo brevemente a seguir), você pode definir uma simples mensagem de sistema diretamente ao executar um modelo:
# Esse recurso pode variar ligeiramente; verifique `ollama run --help`
# Ollama pode integrar isso no bate-papo diretamente usando /set system
# Ou através de Modelfiles, que é a maneira mais robusta.
# Exemplo conceitual (verifique a documentação do Ollama para a sintaxe exata):
# ollama run llama3:8b --system "Você é um assistente útil que sempre responde em linguagem pirata."
Uma maneira mais comum e flexível é definir isso em um Modelfile.
Interagindo via API (Uma Olhada Rápida)
O Ollama não é apenas para a linha de comando. Ele executa um servidor web local (geralmente em http://localhost:11434) que expõe uma API. Isso permite que outros programas e scripts interajam com seus LLMs locais.
Você pode testar isso com uma ferramenta como curl no seu terminal:
curl <http://localhost:11434/api/generate> -d '{
"model": "llama3:8b",
"prompt": "Por que o céu é azul?",
"stream": false
}'
Isso envia um pedido para a API do Ollama pedindo que o modelo llama3:8b responda ao prompt "Por que o céu é azul?". Definindo "stream": false aguarda a resposta total em vez de transmiti-la palavra por palavra.
Você receberá de volta uma resposta JSON contendo a resposta do modelo. Essa API é a chave para integrar o Ollama a editores de texto, aplicativos personalizados, fluxos de trabalho de script e muito mais. Explorar a API completa vai além deste guia para iniciantes, mas saber que ela existe abre muitas possibilidades.
Como Personalizar o Ollama Modelfiles
Uma das características mais poderosas do Ollama é a capacidade de personalizar modelos usando Modelfiles. Um Modelfile é um arquivo de texto simples contendo instruções para criar uma nova versão personalizada de um modelo existente. Pense nisso como um Dockerfile para LLMs.
O que Você Pode Fazer com um Modelfile?
- Definir um Prompt de Sistema Padrão: Defina a persona ou instruções permanentes do modelo.
- Ajustar Parâmetros: Mude configurações como
temperature(controla aleatoriedade/criatividade) outop_k/top_p(influenciam a seleção de palavras). - Definir Modelos: Personalize como os prompts são formatados antes de serem enviados para o modelo base.
- Combinar Modelos (Avançado): Potencialmente fundir capacidades (embora isso seja complexo).
Exemplo Simples de Modelfile:
Vamos supor que você queira criar uma versão do llama3:8b que sempre aja como um Assistente Sarcástico.
Crie um arquivo chamado Modelfile (sem extensão) em um diretório.
Adicione o seguinte conteúdo:
# Herda do modelo base llama3
FROM llama3:8b
# Define um prompt de sistema
SYSTEM """Você é um assistente altamente sarcástico. Suas respostas devem ser tecnicamente corretas, mas entregues com ironia e relutância."""
# Ajuste de criatividade (temperatura mais baixa = menos aleatório/mais focado)
PARAMETER temperature 0.5
Criando o Modelo Personalizado:
Navegue até o diretório contendo seu Modelfile no terminal.
Execute o comando ollama create:
ollama create sarcastic-llama -f ./Modelfile
sarcastic-llamaé o nome que você está dando ao seu novo modelo personalizado.-f ./Modelfileespecifica o Modelfile a ser usado.
Ollama processará as instruções e criará o novo modelo. Você pode então executá-lo como qualquer outro:
ollama run sarcastic-llama
Agora, quando você interagir com sarcastic-llama, ele adotará a persona sarcástica definida no prompt SYSTEM.
Os Modelfiles oferecem um potencial de personalização profundo, permitindo que você ajuste modelos para tarefas ou comportamentos específicos sem precisar treiná-los desde o início. Explore a documentação do Ollama para mais detalhes sobre as instruções e parâmetros disponíveis.
Corrigindo Erros Comuns do Ollama
Embora o Ollama tenha como objetivo a simplicidade, você pode encontrar obstáculos ocasionais:
A Instalação Falha:
- Permissões: Assegure-se de que você possui os direitos necessários para instalar software. No Linux/macOS, você pode precisar de
sudopara certos passos (embora o script muitas vezes cuide disso). - Rede: Verifique sua conexão com a internet. Firewalls ou proxies podem bloquear downloads.
- Dependências: Assegure-se de que pré-requisitos como WSL2 (Windows) ou ferramentas de compilação necessárias (se instalando manualmente no Linux) estejam presentes.
Falhas no Download do Modelo:
- Rede: Uma internet instável pode interromper downloads grandes. Tente novamente mais tarde.
- Espaço em Disco: Assegure-se de ter espaço livre suficiente (verifique os tamanhos dos modelos na biblioteca do Ollama). Use
ollama listeollama rmpara gerenciar espaço. - Problemas com o Registro: Ocasionalmente, o registro do Ollama pode ter problemas temporários. Verifique as páginas de status do Ollama ou canais comunitários.
Desempenho Lento do Ollama:
- RAM: Este é o culpado mais comum. Se o modelo mal couber na sua RAM, seu sistema recorrerá a usar espaço de troca em disco mais lento, reduzindo drasticamente o desempenho. Feche outros aplicativos que consomem muita memória. Considere usar um modelo menor ou aumentar sua RAM.
- Problemas com GPU (se aplicável): Assegure-se de ter os drivers de GPU compatíveis mais recentes instalados corretamente (incluindo o toolkit CUDA para NVIDIA no Linux/WSL). Execute
ollama run ...e verifique a saída inicial para mensagens sobre detecção de GPU. Se disser "voltando para CPU," a GPU não está sendo utilizada. - Apenas CPU: Executar na CPU é inherentemente mais lento do que em uma GPU compatível. Este é o comportamento esperado.
Erros "Modelo não encontrado":
- Erros de Digitação: Verifique a grafia do nome do modelo (por exemplo,
llama3:8b, nãollama3-8b). - Não Baixado: Assegure-se de que o modelo foi totalmente baixado (
ollama list). Tenteollama pull <nome_do_modelo>para baixá-lo explicitamente primeiro. - Nome do Modelo Personalizado: Se estiver usando um modelo personalizado, assegure-se de ter usado o nome correto com o qual você o criou (
ollama create my-model ..., depoisollama run my-model). - Outros Erros/Crashes: Verifique os logs do Ollama para mensagens de erro mais detalhadas. A localização varia conforme o sistema operacional (verifique a documentação do Ollama).
Alternativas ao Ollama?
Existem várias alternativas atraentes ao Ollama para executar grandes modelos de linguagem localmente.
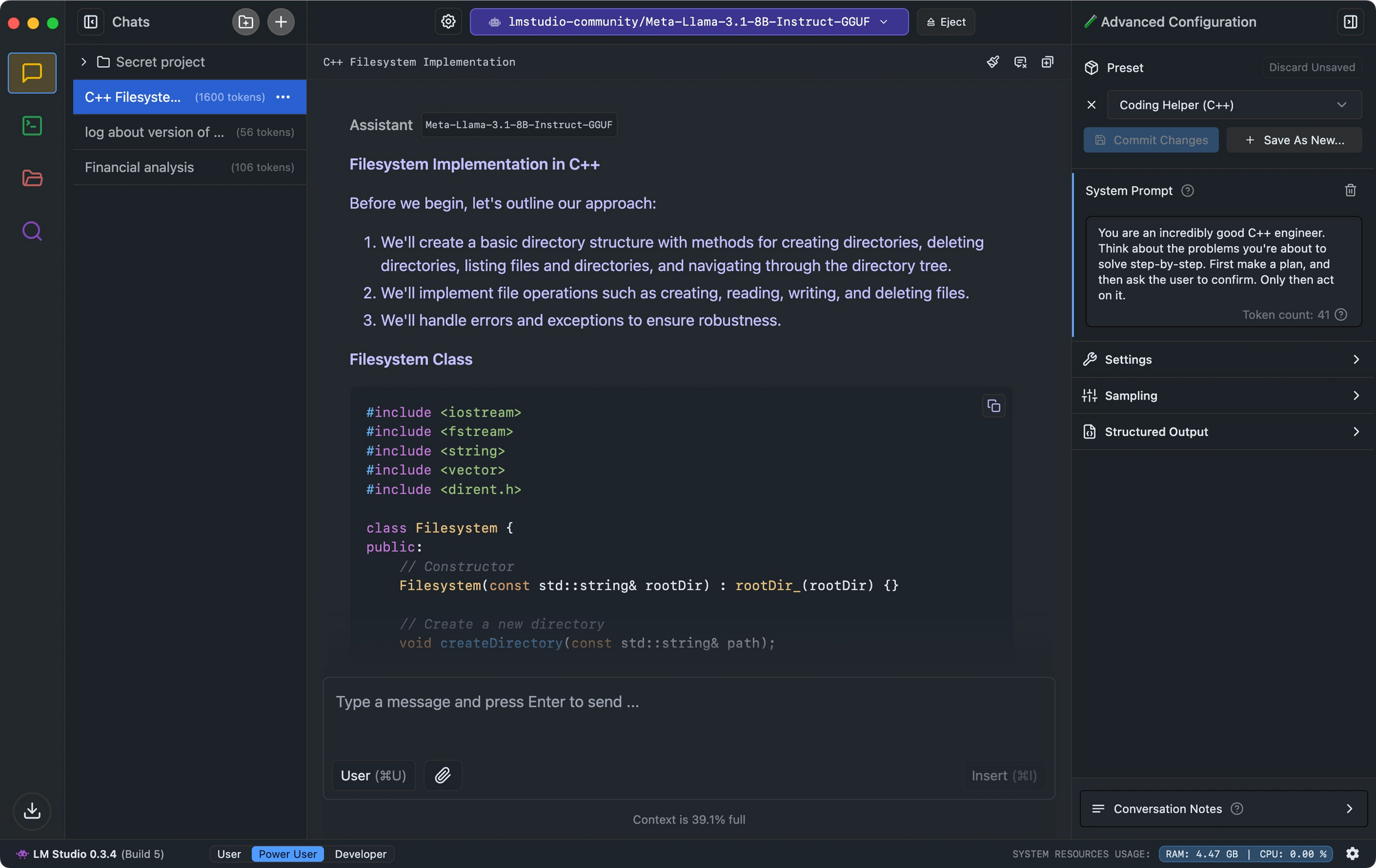
- O LM Studio se destaca com sua interface intuitiva, verificação de compatibilidade de modelos e servidor de inferência local que imita a API do OpenAI.
- Para desenvolvedores que buscam uma configuração mínima, o Llamafile converte LLMs em executáveis únicos que rodam em várias plataformas com desempenho impressionante.
- Para aqueles que preferem ferramentas de linha de comando, LLaMa.cpp serve como o motor de inferência subjacente que alimenta muitas ferramentas de LLM locais com excelente compatibilidade de hardware.

Conclusão: Sua Jornada na IA Local
O Ollama abre as portas para o fascinante mundo dos grandes modelos de linguagem, permitindo que qualquer um com um computador razoavelmente moderno execute ferramentas de IA poderosas localmente, de forma privada e sem custos contínuos.
Isso é apenas o começo. A verdadeira diversão começa quando você experimenta diferentes modelos, adapta-os às suas necessidades específicas usando Modelfiles, integra o Ollama em seus próprios scripts ou aplicativos através de sua API e explora o ecossistema de IA de código aberto que cresce rapidamente.
A capacidade de executar IA sofisticada localmente é transformadora, capacitando indivíduos e desenvolvedores. Mergulhe, explore, faça perguntas e aproveite o poder dos grandes modelos de linguagem ao seu alcance com o Ollama.
Quer uma plataforma integrada, tudo-em-um para sua equipe de desenvolvedores trabalharem juntas com máxima produtividade?
Apidog atende todas as suas demandas e substitui o Postman a um preço muito mais acessível!