
Parece que a cada semana, surgem novos modelos de Geração de Imagens por IA capazes de criar visuais deslumbrantes. Um desses modelos poderosos é o HiDream-I1-Full. Embora executar esses modelos localmente possa ser exigente em recursos, aproveitar APIs fornece uma maneira conveniente e escalável de integrar essa tecnologia em suas aplicações ou fluxos de trabalho.
Este tutorial irá guiá-lo através de:
- Entendendo o HiDream-I1-Full: O que é e suas capacidades.
- Opções de API: Explorando duas plataformas populares que oferecem o HiDream-I1-Full via API: Replicate e Fal.ai.
- Testando com Apidog: Um guia passo a passo sobre como interagir e testar essas APIs usando a ferramenta Apidog.
Quer uma plataforma integrada, All-in-One para sua equipe de desenvolvedores trabalhar unida com máxima produtividade?
Apidog atende todas as suas demandas, e substitui o Postman a um preço muito mais acessível!
Público-Alvo: Desenvolvedores, designers, entusiastas de IA, e qualquer pessoa interessada em usar geração avançada de imagens por IA sem configurações locais complexas.
Pré-requisitos:
- Compreensão básica de APIs (requisições HTTP, JSON).
- Uma conta no Replicate e/ou Fal.ai para obter chaves de API.
- Apidog instalado (ou acesso à sua versão web).
O que é o HiDream-I1-Full?

O HiDream-I1-Full é um modelo avançado de difusão de texto para imagem desenvolvido pela HiDream AI. Ele pertence à família de modelos projetados para gerar imagens de alta qualidade, coerentes e esteticamente agradáveis com base em descrições textuais (prompts).

Detalhes do Modelo: Você pode encontrar o cartão oficial do modelo e mais informações técnicas no Hugging Face: https://huggingface.co/HiDream-ai/HiDream-I1-Full
Principais Capacidades (Típicas para modelos desta classe):
- Geração de Texto para Imagem: Cria imagens a partir de prompts textuais detalhados.
- Alta Resolução: Capaz de gerar imagens em resoluções razoavelmente altas adequadas para várias aplicações.
- Aderência ao Estilo: Pode muitas vezes interpretar pistas estilísticas dentro do prompt (por exemplo, "no estilo de Van Gogh", "fotorealista", "anime").
- Composição de Cena Complexa: Capacidade de gerar imagens com múltiplos sujeitos, interações e fundos detalhados com base na complexidade do prompt.
- Parâmetros de Controle: Muitas vezes permite ajustes fino através de parâmetros como prompts negativos (coisas a evitar), sementes (para reprodutibilidade), escala de orientação (quão fortemente seguir o prompt), e potencialmente variações de imagem para imagem ou entradas de controle (dependendo da implementação específica da API).
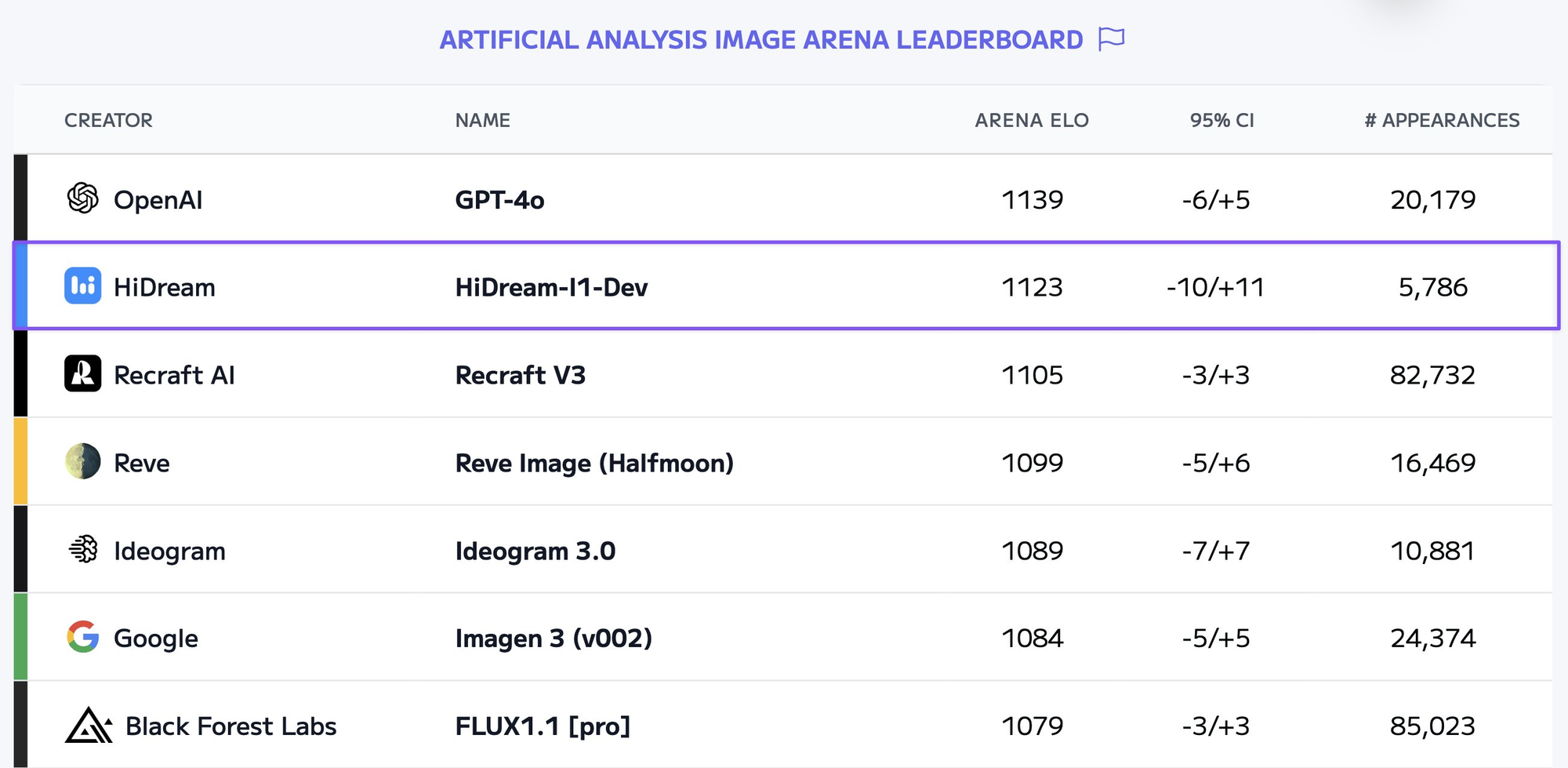
Por que usar uma API?
Executar grandes modelos de IA como o HiDream-I1-Full localmente requer recursos computacionais significativos (GPUs potentes, RAM ampla e armazenamento) e configuração técnica (gerenciamento de dependências, pesos do modelo, configurações de ambiente). Usar uma API oferece várias vantagens:
- Sem Requisitos de Hardware: Descarregue a computação para uma infraestrutura de nuvem poderosa.
- Escalabilidade: Lidar facilmente com cargas variáveis sem gerenciar infraestrutura.
- Facilidade de Integração: Integre capacidades de geração de imagem em websites, aplicativos ou scripts usando requisições HTTP padrão.
- Sem Manutenção: O provedor da API cuida de atualizações do modelo, manutenção e gerenciamento de backend.
- Pagamento conforme o uso: Muitas vezes, você só paga pelo tempo de computação que usa.
Como usar o HiDream-I1-Full via API
Várias plataformas hospedam modelos de IA e fornecem acesso à API. Vamos nos concentrar em duas opções populares para o HiDream-I1-Full:
Opção 1: Usar a API HiDream do Replicate
O Replicate é uma plataforma que facilita a execução de modelos de aprendizado de máquina via uma API simples, sem a necessidade de gerenciar infraestrutura. Eles hospedam uma vasta biblioteca de modelos publicados pela comunidade.
- Página do Replicate para o HiDream-I1-Full: https://replicate.com/prunaai/hidream-l1-full (Nota: A URL menciona
l1-full, mas é o link relevante fornecido no prompt para o modelo HiDream no Replicate. Assuma que corresponde ao modelo pretendido para este tutorial).
Como o Replicate Funciona:
- Autenticação: Você precisará de um token de API do Replicate, que pode ser encontrado nas configurações da sua conta. Este token é passado no cabeçalho
Authorization. - Iniciando uma Previsão: Você envia uma requisição POST para o endpoint da API do Replicate para previsões. O corpo da requisição contém a versão do modelo e os parâmetros de entrada (como
prompt,negative_prompt,seed, etc.). - Operação Assíncrona: O Replicate geralmente opera de forma assíncrona. A requisição POST inicial retorna imediatamente com um ID de previsão e URLs para verificar o status.
- Obtendo Resultados: Você precisa verificar a URL de status (fornecida na resposta inicial) usando requisições GET até que o status seja
succeeded(oufailed). A resposta final bem-sucedida conterá a(s) URL(s) da(s) imagem(ns) gerada(s).
Exemplo Conceitual em Python (usando requests):
import requests
import time
import os
REPLICATE_API_TOKEN = "SUA_REPLICATE_API_TOKEN" # Use variáveis de ambiente em produção
MODEL_VERSION = "VERSÃO_DO_MODELO_ALVO_DA_PÁGINA_REPLICATE" # ex: "9a0b4534..."
# 1. Iniciar Previsão
headers = {
"Authorization": f"Token {REPLICATE_API_TOKEN}",
"Content-Type": "application/json"
}
payload = {
"version": MODEL_VERSION,
"input": {
"prompt": "Uma cidade cyberpunk majestosa ao pôr do sol, luzes de néon refletindo nas ruas molhadas, ilustração detalhada",
"negative_prompt": "feio, deformado, embaçado, baixa qualidade, texto, marca d'água",
"width": 1024,
"height": 1024,
"seed": 12345
# Adicione outros parâmetros conforme necessário com base na página do modelo Replicate
}
}
start_response = requests.post("https://api.replicate.com/v1/predictions", json=payload, headers=headers)
start_response_json = start_response.json()
if start_response.status_code != 201:
print(f"Erro ao iniciar a previsão: {start_response_json.get('detail')}")
exit()
prediction_id = start_response_json.get('id')
status_url = start_response_json.get('urls', {}).get('get')
print(f"Previsão iniciada com ID: {prediction_id}")
print(f"URL de Status: {status_url}")
# 2. Verificar Resultados
output_image_url = None
while True:
print("Verificando status...")
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status')
if status == 'succeeded':
output_image_url = status_response_json.get('output') # Normalmente uma lista de URLs
print("Previsão bem-sucedida!")
print(f"Saída: {output_image_url}")
break
elif status == 'failed' or status == 'canceled':
print(f"Previsão falhou ou foi cancelada: {status_response_json.get('error')}")
break
elif status in ['starting', 'processing']:
# Aguardar antes de verificar novamente
time.sleep(5) # Ajuste o intervalo de verificação conforme necessário
else:
print(f"Status desconhecido: {status}")
print(status_response_json)
break
# Agora você pode usar o output_image_url
Preços: O Replicate cobra com base no tempo de execução do modelo em seu hardware. Verifique a página de preços deles para detalhes.
Opção 2: Fal.ai
Fal.ai é outra plataforma focada em fornecer inferência rápida, escalável e econômica para modelos de IA via APIs. Eles geralmente enfatizam o desempenho em tempo real.
Como o Fal.ai Funciona:
- Autenticação: Você precisa de credenciais da API do Fal (ID da Chave e Chave Secreta, muitas vezes combinadas como
KeyID:KeySecret). Isso é passado no cabeçalhoAuthorization, tipicamente comoKey YourKeyID:YourKeySecret. - Endpoint da API: O Fal.ai fornece uma URL de endpoint direta para a função específica do modelo.
- Formato da Requisição: Você envia uma requisição POST para o URL do endpoint do modelo. O corpo da requisição é tipicamente JSON contendo os parâmetros de entrada exigidos pelo modelo (semelhante ao Replicate:
prompt, etc.). - Síncrono vs. Assíncrono: O Fal.ai pode oferecer ambos. Para tarefas que podem demorar, como a geração de imagem, eles podem usar:
- Funções Sem Servidor: Um ciclo padrão de requisição/resposta, possivelmente com timeouts mais longos.
- Filas: Um padrão assíncrono semelhante ao Replicate, onde você envia um trabalho e verifica os resultados usando um ID de requisição. A página específica da API vinculada detalhará o padrão de interação esperado.
Exemplo Conceitual em Python (usando requests - assumindo fila assíncrona):
import requests
import time
import os
FAL_API_KEY = "SUA_FAL_KEY_ID:SEU_FAL_KEY_SECRET" # Use variáveis de ambiente
MODEL_ENDPOINT_URL = "https://fal.run/fal-ai/hidream-i1-full" # Verifique a URL exata no Fal.ai
# 1. Enviar Requisição para a Fila (Exemplo - verifique a documentação do Fal para estrutura exata)
headers = {
"Authorization": f"Key {FAL_API_KEY}",
"Content-Type": "application/json"
}
payload = {
# Os parâmetros estão frequentemente diretamente no carregamento para funções sem servidor do Fal.ai
# ou dentro de um objeto 'input' dependendo da configuração. Verifique a documentação!
"prompt": "Um retrato hiper-realista de um astronauta flutuando no espaço, a Terra refletindo no visor do capacete",
"negative_prompt": "cartoon, desenho, ilustração, esboço, texto, letras",
"seed": 98765
# Adicione outros parâmetros suportados pela implementação do Fal.ai
}
# O Fal.ai pode exigir adicionar '/queue' ou parâmetros de consulta específicos para assíncrono
# Exemplo: POST https://fal.run/fal-ai/hidream-i1-full/queue
# Verifique a documentação deles! Assumindo um endpoint que retorna uma URL de status:
submit_response = requests.post(f"{MODEL_ENDPOINT_URL}", json=payload, headers=headers, params={"fal_webhook": "OPTIONAL_WEBHOOK_URL"}) # Verifique a docs para parâmetros de consulta como webhook
if submit_response.status_code >= 300:
print(f"Erro ao enviar requisição: {submit_response.status_code}")
print(submit_response.text)
exit()
submit_response_json = submit_response.json()
# A resposta assíncrona do Fal.ai pode diferir - pode retornar um request_id ou uma URL de status direta
# Assumindo que retorna uma URL de status semelhante ao Replicate para este exemplo conceitual
status_url = submit_response_json.get('status_url') # Ou construa a partir do request_id, verifique a documentação
request_id = submit_response_json.get('request_id') # Identificador alternativo
if not status_url and request_id:
# Você pode precisar construir a URL de status, por exemplo, https://fal.run/fal-ai/hidream-i1-full/requests/{request_id}/status
# Ou consultar um endpoint de status genérico: https://fal.run/requests/{request_id}/status
print("É necessário construir a URL de status ou usar request_id, verifique a documentação do Fal.ai.")
exit() # Necessita de implementação específica com base na documentação do Fal
print(f"Requisição enviada. URL de Status: {status_url}")
# 2. Verificar Resultados (se assíncrono)
output_data = None
while status_url: # Só verifique se temos uma URL de status
print("Verificando status...")
# A verificação pode exigir autenticação também
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status') # Verifique a documentação do Fal.ai para as chaves de status ('COMPLETED', 'FAILED', etc.)
if status == 'COMPLETED': # Exemplo de status
output_data = status_response_json.get('response') # Ou 'result', 'output', verifique a documentação
print("Requisição concluída!")
print(f"Saída: {output_data}") # A estrutura de saída depende do modelo no Fal.ai
break
elif status == 'FAILED': # Exemplo de status
print(f"Requisição falhou: {status_response_json.get('error')}") # Verifique o campo de erro
break
elif status in ['IN_PROGRESS', 'IN_QUEUE']: # Exemplo de status
# Aguardar antes de verificar novamente
time.sleep(3) # Ajustar intervalo de verificação
else:
print(f"Status desconhecido: {status}")
print(status_response_json)
break
# Use o output_data (que pode conter URLs de imagens ou outras informações)
Preços: O Fal.ai normalmente cobra com base no tempo de execução, muitas vezes com cobrança por segundo. Verifique os detalhes de preços para o modelo específico e recursos de computação.
Testar a API HiDream com Apidog
O Apidog é uma poderosa ferramenta de design, desenvolvimento e teste de API. Ela fornece uma interface amigável para enviar requisições HTTP, inspecionar respostas e gerenciar detalhes da API, tornando-a ideal para testar as APIs do Replicate e do Fal.ai antes de integrá-las ao código.
Passos para testar a API HiDream-I1-Full usando Apidog:
Passo 1. Instalar e abrir o Apidog: Baixe e instale o Apidog ou use sua versão web. Crie uma conta se necessário.

Passo 2. Criar uma nova requisição:
- No Apidog, crie um novo projeto ou abra um existente.
- Clique no botão "+" para adicionar uma nova Requisição HTTP.
Passo 3. Definir o Método HTTP e a URL:
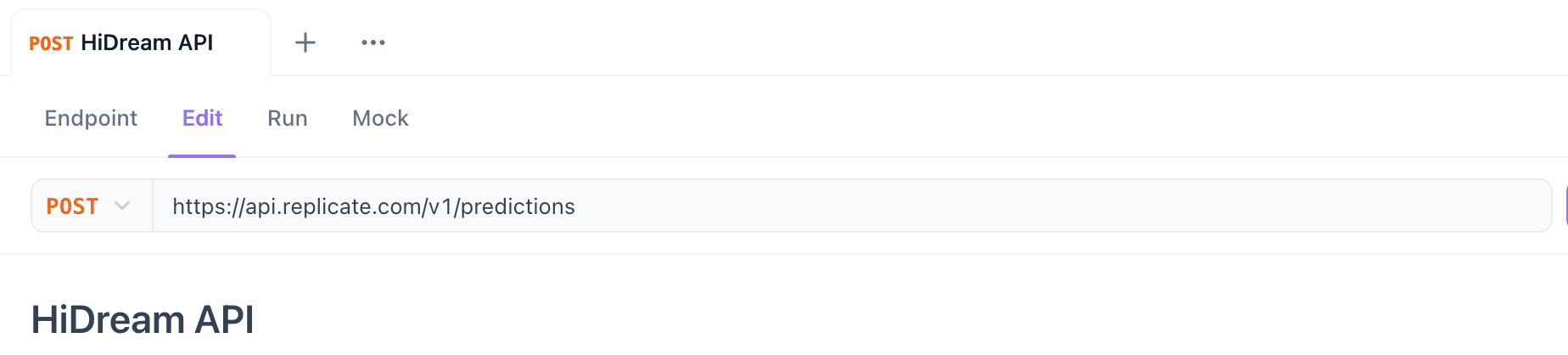
- Método: Selecione
POST. - URL: Insira a URL do endpoint da API.
- Para Replicate (Iniciando Previsão):
https://api.replicate.com/v1/predictions - Para Fal.ai (Submetendo Requisição): Use a URL do endpoint específico do modelo fornecida na página deles (ex:
https://fal.run/fal-ai/hidream-i1-full- verifique se necessita de/queueou parâmetros de consulta para assíncrono).
Passo 4. Configurar Cabeçalhos:
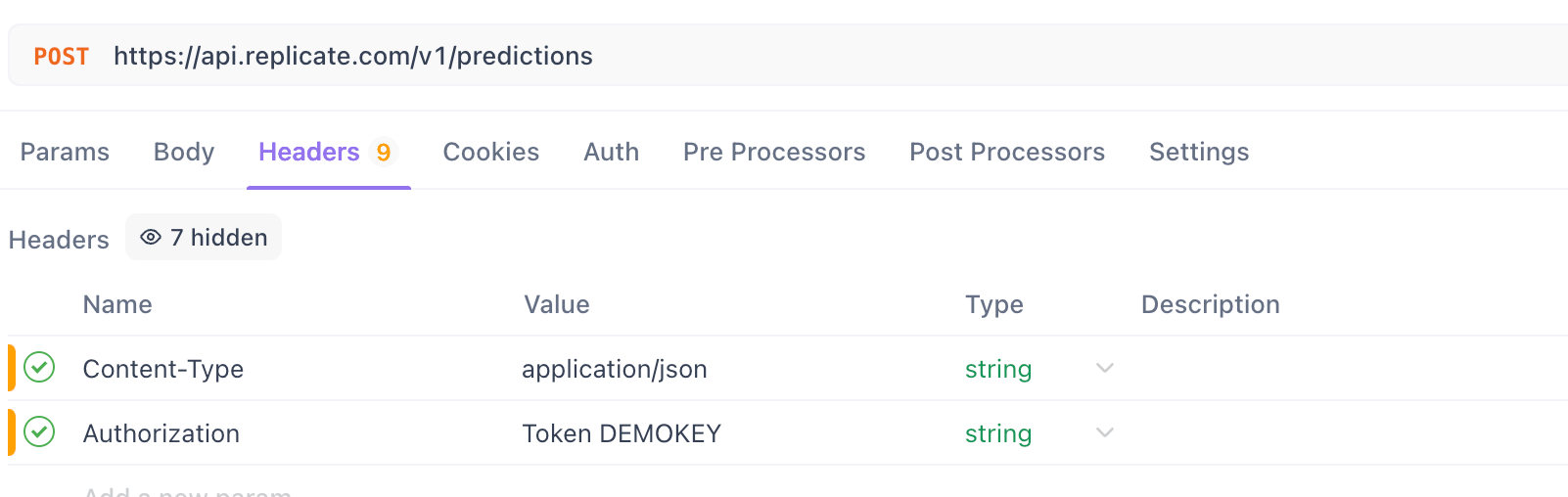
- Vá para a aba
Headers.
Adicione o cabeçalho Content-Type:
- Chave:
Content-Type - Valor:
application/json
Adicione o cabeçalho Authorization:
Para Replicate:
- Chave:
Authorization - Valor:
Token SUA_REPLICATE_API_TOKEN(Substitua pela sua token real)
Para Fal.ai:
- Chave:
Authorization - Valor:
Key SUA_FAL_KEY_ID:SEU_FAL_KEY_SECRET(Substitua pelas suas credenciais reais) - Dica: Use as variáveis de ambiente do Apidog para armazenar suas chaves de API com segurança em vez de codificá-las diretamente na requisição. Crie um ambiente (ex: "Replicate Dev", "Fal Dev") e defina variáveis como
REPLICATE_TOKENouFAL_API_KEY. Então, no valor do cabeçalho, useToken {{REPLICATE_TOKEN}}ouKey {{FAL_API_KEY}}.
Passo 5. Configurar o Corpo da Requisição:
Vá para a aba Body.
Selecione o formato raw e escolha JSON no dropdown.
Cole o JSON payload de acordo com os requisitos da plataforma.
Exemplo de Corpo JSON para Replicate:
{
"version": "COLE_A_VERSÃO_DO_MODELO_DA_PÁGINA_REPLICATE_AQUI",
"input": {
"prompt": "Uma pintura aquarela de um canto acolhedor de biblioteca com um gato dormindo",
"negative_prompt": "fotorealista, render 3d, arte ruim, deformado",
"width": 1024,
"height": 1024,
"seed": 55555
}
}
Exemplo de Corpo JSON para Fal.ai
{
"prompt": "Uma pintura aquarela de um canto acolhedor de biblioteca com um gato dormindo",
"negative_prompt": "fotorealista, render 3d, arte ruim, deformado",
"width": 1024,
"height": 1024,
"seed": 55555
// Outros parâmetros como 'model_name' podem ser necessários dependendo da configuração do Fal.ai
}
Importante: Consulte a documentação específica nas páginas do Replicate ou do Fal.ai para os parâmetros exatos exigidos e opcionais para a versão do modelo HiDream-I1-Full que você está usando. Parâmetros como guidance_scale, num_inference_steps, etc., podem estar disponíveis.
Passo 6. Enviar a Requisição:
- Clique no botão "Enviar".
- O Apidog irá exibir o código de status da resposta, cabeçalhos e corpo.
- Para Replicate: Você deve receber um status
201 Created. O corpo da resposta conterá oidda previsão e uma URLurls.get. Copie esta URLget. - Para Fal.ai (Assíncrono): Você pode receber um
200 OKou202 Accepted. O corpo da resposta pode conter umrequest_id, umastatus_urldireta, ou outros detalhes com base na implementação deles. Copie a URL ou ID relevante necessária para verificação. Se for síncrono, você pode obter o resultado diretamente após o processamento (menos provável para geração de imagem).
Verificar Resultados (para APIs Assíncronas):
- Crie outra nova requisição no Apidog.
- Método: Selecione
GET. - URL: Cole a
URL de statusque você copiou da resposta inicial (ex: aurls.getdo Replicate ou a URL de status do Fal.ai). Se o Fal.ai forneceu umrequest_id, construa a URL de status de acordo com a documentação deles (ex:https://fal.run/requests/{request_id}/status). - Configurar Cabeçalhos: Adicione o mesmo cabeçalho
Authorizationque na requisição POST. (O Content-Type geralmente não é necessário para GET). - Enviar a Requisição: Clique em "Enviar".
- Inspecionar Resposta: Verifique o campo
statusna resposta JSON. - Se
processing,starting,IN_PROGRESS,IN_QUEUE, etc., aguarde alguns segundos e clique em "Enviar" novamente. - Se
succeededouCOMPLETED, procure o campooutput(Replicate) ouresponse/result(Fal.ai) que deverá conter a(s) URL(s) da(s) imagem(ns) gerada(s). - Se
failedouFAILED, verifique o campoerrorpara detalhes.
Visualizar a Imagem: Copie a URL da imagem da resposta final bem-sucedida e cole-a em seu navegador para visualizar a imagem gerada.
Quer uma plataforma integrada, All-in-One para sua Equipe de Desenvolvimento trabalhar unida com máxima produtividade?
Apidog atende todas as suas demandas, e substitui o Postman a um preço muito mais acessível!

Conclusão
O HiDream-I1-Full oferece poderosas capacidades de geração de imagem, e usar APIs de plataformas como Replicate ou Fal.ai torna essa tecnologia acessível sem a necessidade de gerenciar infraestrutura complexa. Ao entender o fluxo de trabalho da API (requisição, verificação potencial, resposta) e utilizar ferramentas como Apidog para testes, você pode facilmente experimentar e integrar geração de imagens por IA de ponta em seus projetos.
Lembre-se de sempre consultar a documentação específica no Replicate e Fal.ai para as URLs de endpoint mais atualizadas, parâmetros exigidos, métodos de autenticação e detalhes de preços, pois estes podem mudar ao longo do tempo. Boa geração!