
A paisagem de gerenciamento e recuperação de dados no desenvolvimento de software tem sido significativamente moldada por duas tecnologias distintas: GraphQL e SQL. Cada uma serve a um propósito único e é adequada para diferentes cenários no desenvolvimento de sites e aplicativos. Compreender as principais diferenças entre GraphQL e SQL é crucial para desenvolvedores e arquitetos de dados na escolha da ferramenta certa para suas necessidades específicas.
Clique no botão Download e transforme sua conectividade com o SQL Server hoje! 🚀🌟
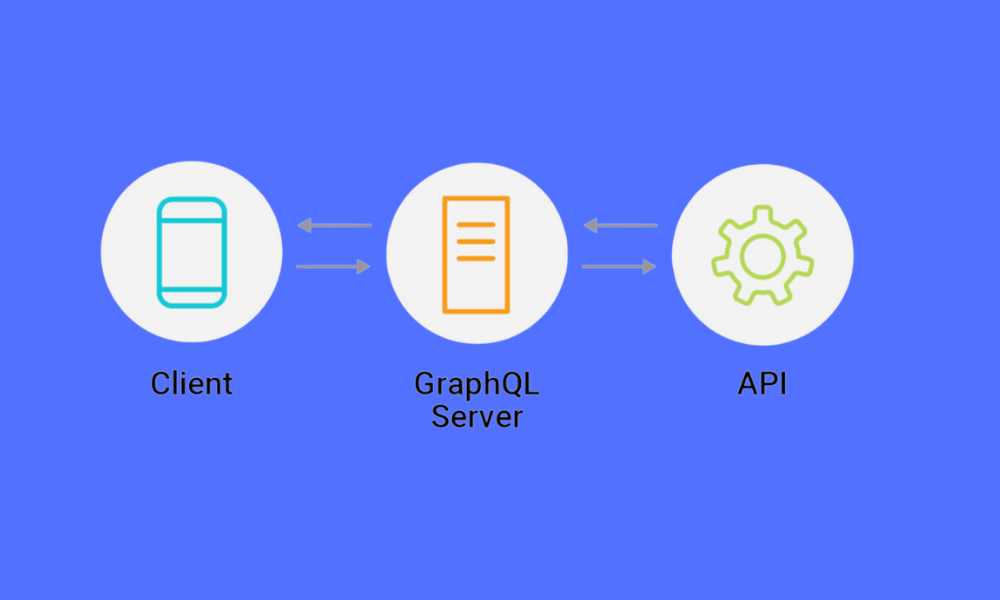
O que é GraphQL?
GraphQL é uma linguagem de consulta desenvolvida pelo Facebook para APIs, bem como um tempo de execução para executar essas consultas usando um sistema de tipos definido para seus dados. Não é uma tecnologia de banco de dados, mas sim uma maneira de interagir com dados por meio de APIs.
type Query {
user(id: ID!): User
}
type User {
id: ID!
name: String
email: String
}
# Query
{
user(id: "123") {
name
email
}
}
Principais Características do GraphQL
- Consultas Específicas do Cliente: Permite que os clientes solicitem exatamente quais dados precisam, mesmo com estruturas profundamente aninhadas.
- Ponto Único: Usa um único ponto de extremidade da API e aproveita as consultas para buscar várias formas de dados.
- Dados em Tempo Real com Assinaturas: Suporta atualizações de dados em tempo real por meio de assinaturas.
- Redução da Transferência Excessiva: Reduz a transferência desnecessária de dados ao permitir que os clientes especifiquem exatamente o que precisam.
O que é SQL?
SQL (Structured Query Language) é uma linguagem específica de domínio usada em programação e projetada para gerenciar dados mantidos em sistemas de gerenciamento de banco de dados relacionais (RDBMS). É particularmente eficaz para lidar com dados estruturados com relações entre diferentes entidades claramente definidas.

SELECT name, email FROM users WHERE id = 123;
Principais Características do SQL
- Linguagem de Consulta Padronizada: Um padrão amplamente aceito para consultar e manipular dados em bancos de dados relacionais.
- Representação de Dados Tabular: Os dados são organizados em tabelas e relações podem ser formadas usando chaves primárias e estrangeiras.
- Consultas Complexas: Suporta consultas complexas com operações JOIN, agregações e subconsultas.
- Controle Transacional: Fornece robusto controle transacional para garantir a integridade dos dados.
Principais Diferenças Entre GraphQL e SQL
Propósito e Escopo:
- GraphQL é uma linguagem de consulta especificamente projetada para interações cliente-servidor, usada principalmente para APIs web.
- SQL é uma linguagem para gerenciar e manipular dados em um banco de dados relacional.
Recuperação de Dados:
- GraphQL permite que os clientes especifiquem exatamente quais dados precisam em uma única solicitação.
- As consultas SQL são mais focadas na recuperação de dados de um banco de dados por meio de consultas SELECT, joins e outras operações.
Dados em Tempo Real:
- GraphQL pode manipular dados em tempo real com assinaturas.
- SQL não suporta nativamente atualizações de dados em tempo real da mesma maneira.
Flexibilidade na Consulta:
- GraphQL oferece alta flexibilidade, permitindo consultas personalizadas adaptadas às necessidades do cliente.
- SQL segue uma abordagem mais estruturada, com esquemas predefinidos e formatos de consulta rígidos.
Manipulação da Transferência Excessiva:
- GraphQL reduz efetivamente a transferência excessiva ao permitir consultas específicas.
- SQL pode resultar em transferência excessiva se a consulta não for bem estruturada ou muito ampla.
Complexidade e Curva de Aprendizado:
- GraphQL pode ter uma curva de aprendizado mais íngreme devido à sua abordagem única na recuperação de dados.
- SQL é amplamente ensinado e utilizado, com uma vasta quantidade de recursos e uma abordagem padronizada.
Tabela de Comparação: GraphQL vs SQL
| Aspecto | GraphQL | SQL |
|---|---|---|
| Definição Básica | Uma linguagem de consulta para APIs, permitindo que os clientes solicitem dados específicos. | Uma linguagem para gerenciar e consultar dados em bancos de dados relacionais. |
| Abordagem de Recuperação de Dados | Permite que os clientes solicitem exatamente o que precisam, reduzindo a transferência excessiva. | Utiliza consultas predefinidas para recuperar dados, o que pode levar à transferência excessiva. |
| Apoio a Dados em Tempo Real | Suporta atualizações em tempo real com assinaturas. | Geralmente não suporta atualizações em tempo real nativamente. |
| Tipo de Comunicação | Opera tipicamente sobre HTTP/HTTPS com um único ponto de extremidade. | Opera sobre conexões de banco de dados, utilizando vários protocolos com base no sistema de banco de dados. |
| Flexibilidade na Consulta | Altamente flexível; os clientes podem adaptar solicitações às suas necessidades exatas. | Mais estruturado; depende de esquemas predefinidos e formatos de consulta. |
| Estrutura de Dados | Funciona bem com estruturas de dados hierárquicas e aninhadas. | Mais adequado para dados tabulares em formas normalizadas. |
| Casos de Uso | Ideal para APIs e aplicativos complexos e em evolução com necessidades de dados diversas. | Adequado para aplicativos que requerem transações complexas e integridade dos dados em bancos de dados. |
| Complexidade | Pode ser complexo de configurar e otimizar para desempenho. | Amplamente utilizado com muitos recursos educacionais, mas consultas complexas podem ser desafiadoras. |
| Controle Transacional | Não lida com transações; focado na busca de dados. | Fornece controle transacional robusto para a integridade dos dados. |
| Comunidade e Ecossistema | Crescendo rapidamente, especialmente popular no desenvolvimento de aplicativos web e móveis. | Madura, com extensas ferramentas, recursos e uma vasta comunidade de usuários. |
| Ambiente de Uso Típico | Comumente usado em aplicativos web e móveis para recuperação flexível de dados. | Usado em sistemas onde a integridade dos dados, consultas complexas e relatórios são cruciais. |
Como Conectar ao SQL Server no Apidog
Conectar-se a um SQL Server no Apidog é um processo semelhante a conectar-se a um banco de dados Oracle, mas com algumas diferenças específicas voltadas para o SQL Server. Aqui está um guia conciso para ajudá-lo a configurar essa conexão:
Passo 1: Instalar Apidog
- Baixar Apidog: Visite o site oficial do Apidog e baixe o aplicativo. Certifique-se de que é compatível com seu sistema operacional (Windows ou Linux).

Passo 2: Criar um Novo Projeto
- Novo Projeto: No Apidog, vá para a seção 'Meu Espaço de Trabalho', selecione 'Novo Projeto' e escolha 'HTTP' como tipo. Digite um nome para o seu projeto.
Passo 3: Acessar Conexões de Banco de Dados
- Configurações: Clique na opção de configurações no menu lateral.
- Conexões de Banco de Dados: Navegue até o menu 'Conexões de Banco de Dados'.

Passo 4: Configurar uma Nova Conexão
- Adicionar Conexão: Clique em '+ Novo' para criar uma nova conexão de banco de dados. Uma nova janela aparecerá para configuração.

Passo 5: Configurar Conexão com o SQL Server
- Detalhes da Conexão: Forneça um nome para sua conexão de banco de dados e selecione 'SQL Server' como tipo de banco de dados.
- Detalhes do Servidor: Insira o Host, a Porta e outros detalhes relevantes específicos para sua instância do SQL Server.
- Autenticação: Use o nome de usuário e a senha apropriados do SQL Server. Normalmente, isso pode ser uma conta de administrador como 'sa' ou uma conta específica de usuário.
- Testar Conexão: Clique no botão 'testar conexão' para verificar se a configuração foi bem-sucedida.

Passo 6: Definir Pontos de Extremidade da API
- Definir Pontos de Extremidade: Especifique URLs para operações de envio/recebimento de dados do seu aplicativo, marcando o tipo de operação (GET, POST, PUT, DELETE).
- Configurar Processadores: Defina quaisquer pré-processadores ou pós-processadores para diferentes operações de banco de dados.
Passo 7: Testar e Validar
- Testes de API: Utilize as ferramentas do Apidog para testar cada ponto de extremidade. O editor destacará quaisquer erros.
- Depurar e Retestar: Investigue quaisquer problemas, faça correções e reteste até que as APIs funcionem como esperado.
Conclusão
Em conclusão, GraphQL e SQL atendem a diferentes aspectos do manuseio e recuperação de dados. O GraphQL se destaca em cenários que requerem consultas flexíveis e específicas do cliente e dados em tempo real, tornando-se uma escolha popular para APIs web modernas. O SQL, por outro lado, continua sendo a base para a manipulação de dados estruturados em bancos de dados relacionais, excelendo em consultas complexas e integridade transacional. Compreender suas características distintas ajuda na escolha da tecnologia certa com base nos requisitos específicos de um projeto.


