
Os modelos gpt-oss-safeguard da OpenAI abordam essa necessidade, permitindo raciocínio baseado em políticas para tarefas de classificação. Engenheiros integram esses modelos para classificar conteúdo gerado pelo usuário, detectar violações e manter a integridade da plataforma.
Entendendo o GPT-OSS-Safeguard: Recursos e Capacidades
Os engenheiros da OpenAI desenvolveram o gpt-oss-safeguard como modelos de raciocínio de peso aberto adaptados para classificação de segurança. Eles ajustam esses modelos a partir da base gpt-oss, lançando-os sob a licença Apache 2.0. Desenvolvedores baixam os modelos do Hugging Face e os implantam livremente. A linha inclui gpt-oss-safeguard-20b e gpt-oss-safeguard-120b, onde os números indicam as escalas de parâmetros.
Esses modelos processam duas entradas principais: uma política definida pelo desenvolvedor e o conteúdo para avaliação. O sistema aplica o raciocínio de cadeia de pensamento para interpretar a política e classificar o conteúdo. Por exemplo, ele determina se uma mensagem de usuário viola as regras sobre trapaça em fóruns de jogos. Essa abordagem permite atualizações dinâmicas de políticas sem retreinamento, o que classificadores tradicionais exigem.
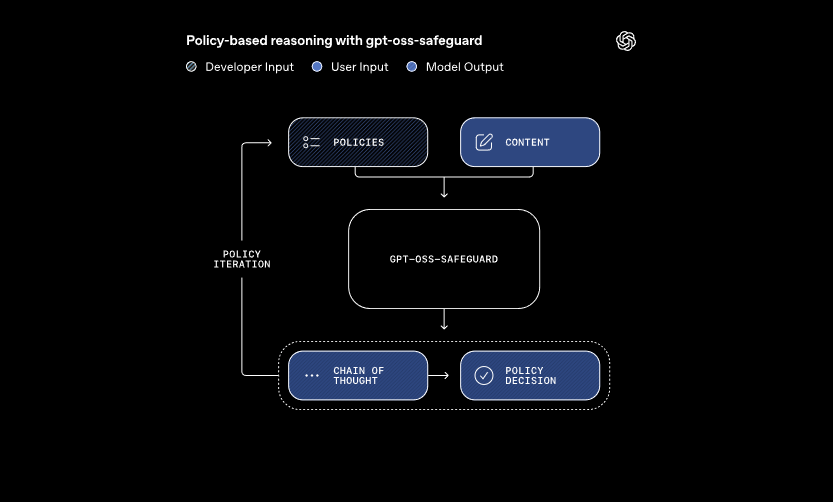
Além disso, o gpt-oss-safeguard suporta múltiplas políticas simultaneamente. Desenvolvedores inserem várias regras em uma única chamada de inferência, e o modelo avalia o conteúdo contra todas elas. Essa capacidade otimiza os fluxos de trabalho para plataformas que lidam com diversos riscos, como desinformação ou discurso de ódio. No entanto, o desempenho pode cair ligeiramente com políticas adicionais, então as equipes devem testar as configurações minuciosamente.
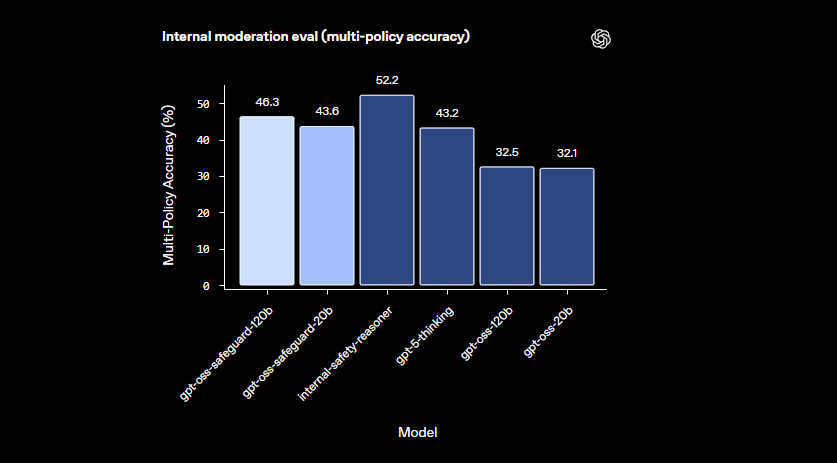
Os modelos se destacam em domínios nuances onde classificadores menores falham. Eles lidam com danos emergentes adaptando-se rapidamente a políticas revisadas. Além disso, a saída de cadeia de pensamento oferece transparência — desenvolvedores revisam o rastreamento de raciocínio para auditar decisões. Esse recurso é inestimável para equipes de conformidade que exigem IA explicável.
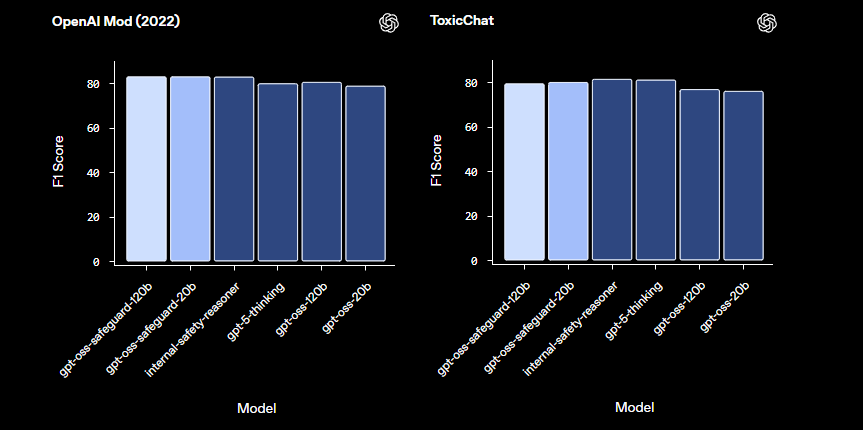
Em comparação com modelos de segurança pré-configurados como o LlamaGuard, o gpt-oss-safeguard oferece maior personalização. Ele evita taxonomias fixas, capacitando as organizações a definir seus próprios limites. Consequentemente, a integração é adequada para engenheiros de Confiança e Segurança que constroem pipelines de moderação escaláveis. Agora que compreendemos os fundamentos, vamos prosseguir para a configuração do ambiente.
Configurando Seu Ambiente para Acesso à API GPT-OSS-Safeguard
Desenvolvedores começam preparando seus sistemas para executar o gpt-oss-safeguard. Como os modelos são de peso aberto, você pode implantá-los localmente ou por meio de provedores hospedados. Essa flexibilidade acomoda várias configurações de hardware, desde máquinas pessoais até servidores em nuvem.
Primeiro, instale as dependências necessárias. Python 3.10 ou superior serve como base. Use pip para adicionar bibliotecas como Hugging Face Transformers: pip install transformers. Para inferência acelerada, inclua torch com suporte CUDA se você possuir uma GPU compatível. Engenheiros com hardware NVIDIA ativam isso para processamento mais rápido.
Em seguida, baixe os modelos do Hugging Face. Acesse a coleção. Selecione gpt-oss-safeguard-20b para necessidades de recursos mais leves ou gpt-oss-safeguard-120b para precisão superior. O comando transformers-cli download openai/gpt-oss-safeguard-20b recupera os arquivos.
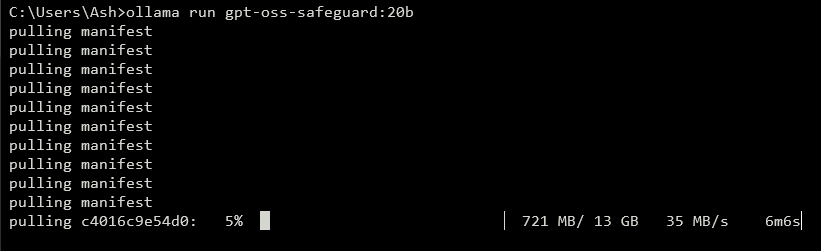
Para expor uma API, execute um servidor local. Ferramentas como vLLM lidam com isso de forma eficiente. Instale o vLLM com pip install vllm. Em seguida, inicie o servidor: vllm serve openai/gpt-oss-safeguard-20b. Este comando inicia um endpoint compatível com OpenAI em http://localhost:8000/v1. Da mesma forma, o Ollama simplifica a implantação: ollama run gpt-oss-safeguard:20b. Ele fornece APIs REST para integração.
Para testes locais, o LM Studio oferece uma interface amigável. Execute lms get openai/gpt-oss-safeguard-20b para buscar o modelo. O software emula a API de Conclusões de Chat da OpenAI, permitindo transições de código contínuas para produção.
Opções hospedadas eliminam preocupações com hardware. Provedores como Groq suportam gpt-oss-safeguard-20b através de sua API. Cadastre-se em https://console.groq.com, gere uma chave de API e direcione o modelo nas requisições. Os preços começam em US$ 0,075 por milhão de tokens de entrada. OpenRouter também o hospeda.
Uma vez configurado, verifique a instalação. Envie uma requisição de teste via curl: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'. Uma resposta bem-sucedida confirma a prontidão. Com o ambiente configurado, você criará políticas em seguida.
Elaborando Políticas Eficazes para o GPT-OSS-Safeguard
As políticas formam a espinha dorsal das operações do gpt-oss-safeguard. Desenvolvedores as escrevem como prompts estruturados que guiam a classificação. Uma política bem projetada maximiza o poder de raciocínio do modelo, garantindo saídas precisas e explicáveis.
Estruture sua política com seções distintas. Comece com Instruções, especificando as tarefas do modelo. Por exemplo, direcione-o para classificar o conteúdo como violador (1) ou seguro (0). Prossiga com Definições, esclarecendo termos-chave como "linguagem desumanizadora". Em seguida, descreva os Critérios para violações e conteúdo seguro. Finalmente, inclua Exemplos — forneça 4-6 casos limítrofes rotulados de acordo.
Use a voz ativa nas políticas: "Sinalize conteúdo que promova violência" em vez de alternativas passivas. Mantenha a linguagem precisa; evite ambiguidades como "geralmente inseguro". Se surgirem conflitos entre regras, defina a precedência explicitamente. Para cenários de múltiplas políticas, concatene-as na mensagem do sistema.
Controle a profundidade do raciocínio via o parâmetro "reasoning_effort": defina-o como "high" para casos complexos ou "low" para velocidade. O formato harmony, integrado ao gpt-oss-safeguard, separa o raciocínio da saída final. Isso garante respostas de API limpas, preservando os rastros de auditoria.
Otimize o comprimento da política em torno de 400-600 tokens. Políticas mais curtas correm o risco de simplificação excessiva, enquanto as mais longas podem confundir o modelo. Teste iterativamente: classifique o conteúdo de amostra e refine com base nas saídas. Ferramentas como contadores de tokens no Hugging Face auxiliam aqui.
Para formatos de saída, escolha binário para simplicidade: Retorne exatamente 0 ou 1. Adicione justificativa para profundidade: {"violation": 1, "rationale": "Explicação aqui"}. Essa estrutura JSON se integra facilmente com sistemas downstream. À medida que você refina as políticas, faça a transição para a implementação da API.
Implementando Chamadas de API com GPT-OSS-Safeguard
Desenvolvedores interagem com o gpt-oss-safeguard através de endpoints compatíveis com OpenAI. Seja local ou hospedado, o processo segue padrões de conclusão de chat padrão.
Prepare seu cliente. Em Python, importe OpenAI: from openai import OpenAI. Inicialize com a URL base e a chave: client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy") para local, ou valores específicos do provedor.
Construa as mensagens. O papel do sistema contém a política: {"role": "system", "content": "Sua política detalhada aqui"}. O papel do usuário contém o conteúdo: {"role": "user", "content": "Conteúdo para classificar"}.
Chame a API: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0). A temperatura em 0 garante saídas determinísticas para tarefas de segurança.
Analise a resposta: result = completion.choices[0].message.content. Para saídas estruturadas, use a análise JSON. O Groq aprimora isso com cache de prompt — reutilize políticas em chamadas para reduzir custos em 50%.
Lide com streaming para feedback em tempo real: defina stream=True e itere sobre os blocos. Isso é adequado para moderação de alto volume.
Incorpore ferramentas, se necessário, embora o gpt-oss-safeguard se concentre na classificação. Defina funções no parâmetro tools para capacidades estendidas, como buscar dados externos.
Monitore o uso de tokens: a entrada inclui a política mais o conteúdo, as saídas adicionam o raciocínio. Limite max_tokens para evitar estouros. Com as chamadas dominadas, explore exemplos.
Recursos Avançados na API GPT-OSS-Safeguard
O gpt-oss-safeguard oferece ferramentas avançadas para controle refinado. O cache de prompt no Groq reutiliza políticas, reduzindo a latência e os custos.
Ajuste o reasoning_effort na mensagem do sistema: "Reasoning: high" para análise profunda. Isso lida melhor com conteúdo ambíguo.
Aproveite a janela de contexto de 128k para chats longos ou documentos. Alimente conversas inteiras para classificação holística.
Integre com sistemas maiores: Encaminhe as saídas para filas de escalonamento ou registro. Use webhooks para alertas em tempo real.
Ajuste ainda mais, se necessário, embora a base se destaque na adesão a políticas. Combine com modelos menores para pré-filtragem, otimizando o cálculo.
A segurança importa: Proteja as chaves de API e monitore por injeções de prompt. Valide as entradas para evitar explorações.
Escalabilidade: Implante em clusters com vLLM para alto throughput. Provedores como Groq entregam mais de 1000 tokens/segundo.
Esses recursos elevam o gpt-oss-safeguard de classificador básico para ferramenta empresarial. No entanto, siga as melhores práticas para obter resultados ótimos.
Melhores Práticas e Otimização para o GPT-OSS-Safeguard
Engenheiros otimizam o gpt-oss-safeguard iterando sobre políticas. Teste com diversos conjuntos de dados, medindo a precisão por meio de métricas como F1-score.
Equilibre o tamanho do modelo: Use 20b para velocidade, 120b para precisão. Quantize os pesos para reduzir o consumo de memória.
Monitore o desempenho: Registre os rastros de raciocínio para auditorias. Ajuste a temperatura minimamente — 0.0 é adequado para necessidades determinísticas.
Lide com limitações: O modelo pode ter dificuldades com domínios altamente especializados; complemente com dados do domínio.
Garanta o uso ético: Alinhe as políticas com as regulamentações. Evite vieses diversificando os exemplos.
Atualize regularmente: À medida que a OpenAI evolui o gpt-oss-safeguard, incorpore melhorias.
Gerenciamento de custos: Para APIs hospedadas, acompanhe os gastos com tokens. Implantações locais minimizam as despesas.
Ao aplicar essas práticas, você maximiza a eficiência. Em resumo, o gpt-oss-safeguard capacita sistemas de segurança robustos.
Conclusão: Integrando o GPT-OSS-Safeguard ao Seu Fluxo de Trabalho
Desenvolvedores utilizam o gpt-oss-safeguard para construir classificadores de segurança adaptáveis. Desde a configuração até o uso avançado, este guia o equipa com conhecimento técnico. Implemente políticas, execute chamadas de API e otimize para suas necessidades. À medida que as plataformas evoluem, o gpt-oss-safeguard se adapta perfeitamente, garantindo ambientes seguros.