
Quer turbinar seu fluxo de trabalho de codificação com o GPT-OSS, o modelo de peso aberto da Open AI, diretamente no Claude Code? Você veio ao lugar certo! Lançado em agosto de 2025, o GPT-OSS (variantes 20B ou 120B) é uma potência para codificação e raciocínio, e você pode combiná-lo com a elegante interface CLI do Claude Code para configurações gratuitas ou de baixo custo. Neste guia conversacional, vamos te mostrar três caminhos para integrar o GPT-OSS com o Claude Code usando Hugging Face, OpenRouter ou LiteLLM. Vamos mergulhar e colocar seu assistente de codificação de IA para funcionar!
Quer uma plataforma integrada e completa para sua Equipe de Desenvolvedores trabalharem juntos com máxima produtividade?
Apidog atende a todas as suas demandas e substitui o Postman por um preço muito mais acessível!
O Que É GPT-OSS e Por Que Usá-lo com Claude Code?
O GPT-OSS é a família de modelos de peso aberto da Open AI, com as variantes 20B e 120B oferecendo desempenho estelar para codificação, raciocínio e tarefas agenticas. Com uma janela de contexto de 128K tokens e licença Apache 2.0, é perfeito para desenvolvedores que desejam flexibilidade e controle. O Claude Code, ferramenta CLI da Anthropic (versão 0.5.3+), é um favorito entre os desenvolvedores por suas capacidades de codificação conversacional. Ao rotear o Claude Code para o GPT-OSS via APIs compatíveis com OpenAI, você pode desfrutar da interface familiar do Claude enquanto aproveita o poder de código aberto do GPT-OSS — sem os custos de assinatura da Anthropic. Pronto para fazer acontecer? Vamos explorar as opções de configuração!

Pré-requisitos para Usar GPT-OSS com Claude Code
Antes de começarmos, certifique-se de ter:
- Claude Code ≥ 0.5.3: Verifique com
claude --version. Instale viapip install claude-codeou atualize compip install --upgrade claude-code. - Conta Hugging Face: Cadastre-se em huggingface.co e crie um token de leitura/escrita (Configurações > Tokens de Acesso).
- Chave API OpenRouter: Opcional, para o Caminho B. Obtenha uma em openrouter.ai.
- Python 3.10+ e Docker: Para configurações locais ou LiteLLM (Caminho C).
- Conhecimento Básico de CLI: Familiaridade com variáveis de ambiente e comandos de terminal ajuda.
Caminho A: Auto-hospedar GPT-OSS no Hugging Face
Quer controle total? Hospede o GPT-OSS nos Inference Endpoints do Hugging Face para uma configuração privada e escalável. Veja como:
Passo 1: Obtenha o Modelo
- Visite o repositório do GPT-OSS no Hugging Face (openai/gpt-oss-20b ou openai/gpt-oss-120b).
- Aceite a licença Apache 2.0 para acessar o modelo.
- Alternativamente, experimente o Qwen3-Coder-480B-A35B-Instruct (Qwen/Qwen3-Coder-480B-A35B-Instruct) para um modelo focado em codificação (use uma versão GGUF para hardware mais leve).
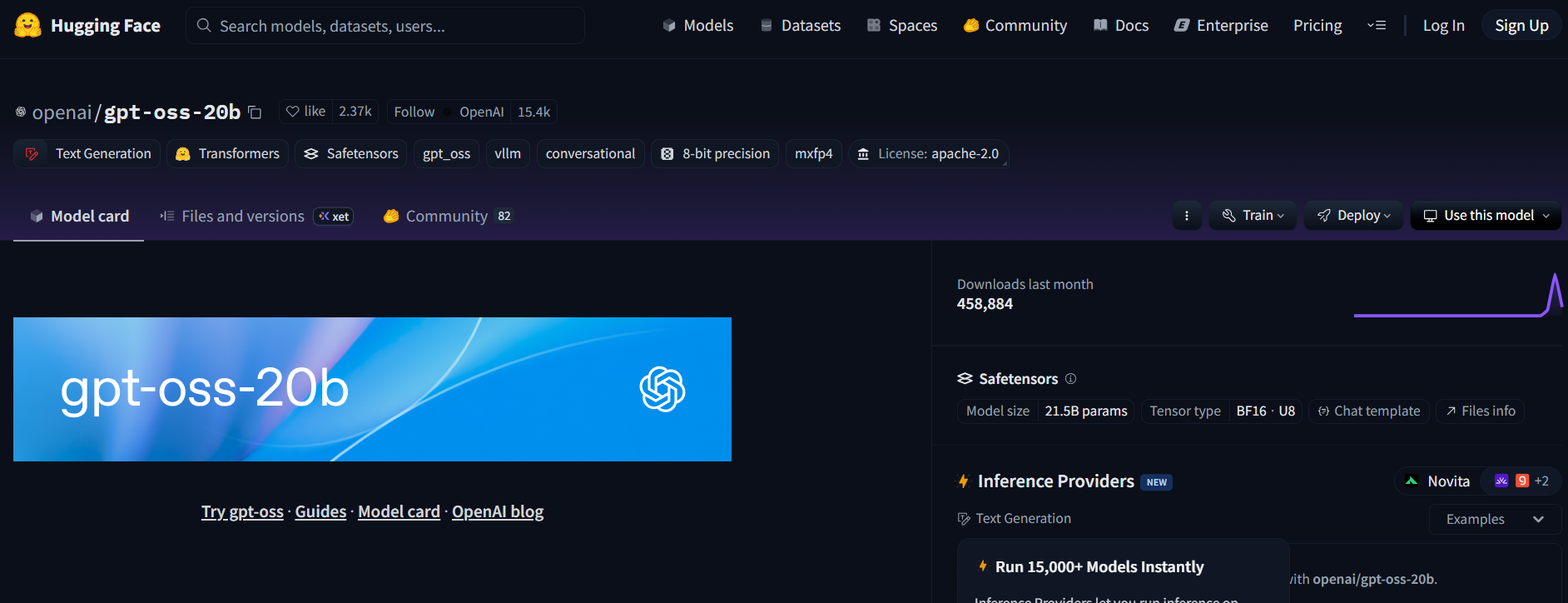
Passo 2: Implementar um Endpoint de Inferência de Geração de Texto
- Na página do modelo, clique em Deploy (Implementar) > Inference Endpoint (Endpoint de Inferência).
- Selecione o template Text Generation Inference (TGI) (≥ v1.4.0).
- Habilite a compatibilidade com OpenAI marcando Enable OpenAI compatibility (Habilitar compatibilidade com OpenAI) ou adicionando
--enable-openainas configurações avançadas. - Escolha o hardware: A10G ou CPU para 20B, A100 para 120B. Crie o endpoint.
Passo 3: Coletar Credenciais
- Assim que o status do endpoint for Running (Em execução), copie:
- ENDPOINT_URL: Parece com
https://<seu-endpoint>.us-east-1.aws.endpoints.huggingface.cloud. - HF_API_TOKEN: Seu token Hugging Face de Configurações > Tokens de Acesso.
2. Anote o ID do modelo (por exemplo, gpt-oss-20b ou gpt-oss-120b).
Passo 4: Configurar o Claude Code
- Defina as variáveis de ambiente em seu terminal:
export ANTHROPIC_BASE_URL="https://<seu-endpoint>.us-east-1.aws.endpoints.huggingface.cloud"
export ANTHROPIC_AUTH_TOKEN="hf_xxxxxxxxxxxxxxxxx"
export ANTHROPIC_MODEL="gpt-oss-20b" # ou gpt-oss-120b
Substitua <seu-endpoint> e hf_xxxxxxxxxxxxxxxxx pelos seus valores.
2. Teste a configuração:
claude --model gpt-oss-20b
O Claude Code roteia para o seu endpoint GPT-OSS, transmitindo respostas via API /v1/chat/completions do TGI, imitando o esquema da OpenAI.
Passo 5: Notas sobre Custo e Escala
- Custos Hugging Face: Os Inference Endpoints escalam automaticamente, então monitore o uso para evitar o esgotamento de créditos. A10G custa ~$0.60/hora, A100 ~$3/hora.
- Opção Local: Para custos zero de nuvem, execute o TGI localmente com Docker:
docker run --name tgi -p 8080:80 -e HF_TOKEN=hf_xxxxxxxxxxxxxxxxx ghcr.io/huggingface/text-generation-inference:latest --model-id openai/gpt-oss-20b --enable-openai
Em seguida, defina ANTHROPIC_BASE_URL="http://localhost:8080".
Caminho B: Proxy GPT-OSS Através do OpenRouter
Sem DevOps? Sem problemas! Use o OpenRouter para acessar o GPT-OSS com configuração mínima. É rápido e lida com a cobrança para você.
Passo 1: Registrar e Escolher um Modelo
- Cadastre-se em openrouter.ai e copie sua chave API da seção Keys (Chaves).
- Escolha um slug de modelo:
openai/gpt-oss-20bopenai/gpt-oss-120bqwen/qwen3-coder-480b(para o modelo de codificação da Qwen)
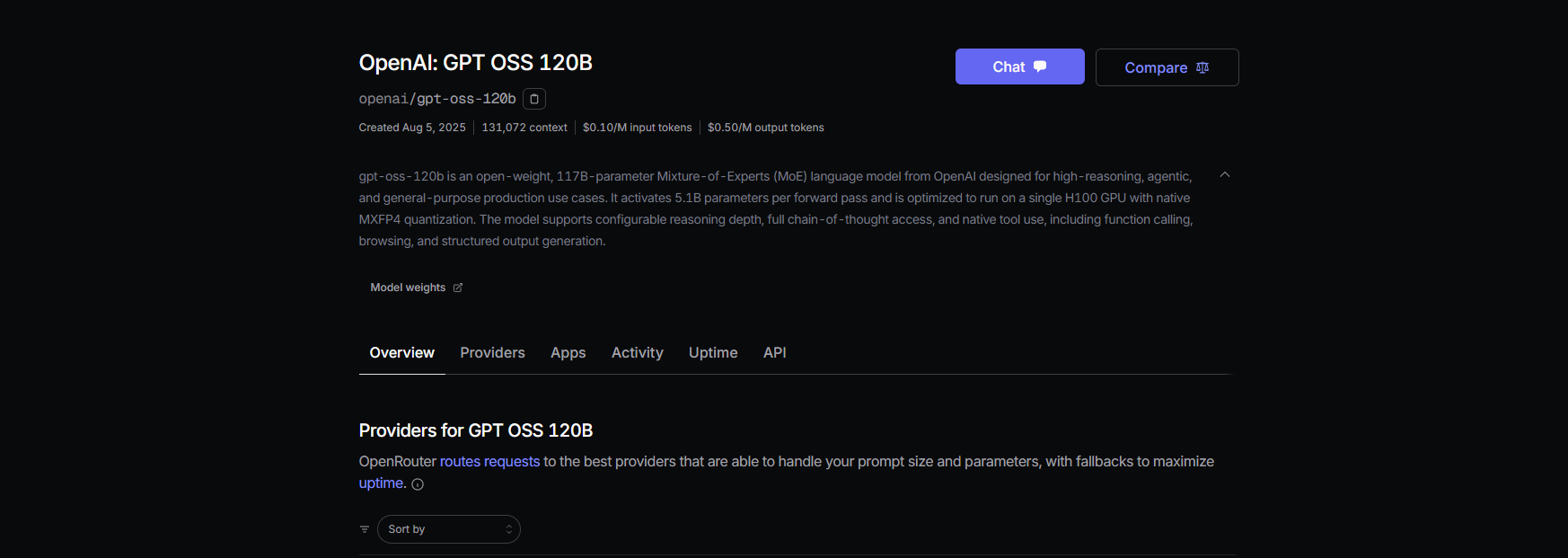
Passo 2: Configurar o Claude Code
- Defina as variáveis de ambiente:
export ANTHROPIC_BASE_URL="https://openrouter.ai/api/v1"
export ANTHROPIC_AUTH_TOKEN="or_xxxxxxxxx"
export ANTHROPIC_MODEL="openai/gpt-oss-20b"
Substitua or_xxxxxxxxx pela sua chave API do OpenRouter.
2. Teste:
claude --model openai/gpt-oss-20b
O Claude Code conecta-se ao GPT-OSS via API unificada do OpenRouter, com suporte a streaming e fallback.
Passo 3: Notas de Custo
- Preços OpenRouter: ~$0.50/M tokens de entrada, ~$2.00/M tokens de saída para GPT-OSS-120B, significativamente mais barato que modelos proprietários como GPT-4 (~$20.00/M).
- Faturamento: O OpenRouter gerencia o uso, então você paga apenas pelo que usa.
Caminho C: Usar LiteLLM para Frotas de Modelos Mistos
Quer alternar entre modelos GPT-OSS, Qwen e Anthropic em um único fluxo de trabalho? O LiteLLM atua como um proxy para trocar modelos de forma contínua.
Passo 1: Instalar e Configurar o LiteLLM
- Instale o LiteLLM:
pip install litellm
2. Crie um arquivo de configuração (litellm.yaml):
model_list:
- model_name: gpt-oss-20b
litellm_params:
model: openai/gpt-oss-20b
api_key: or_xxxxxxxxx # Chave OpenRouter
api_base: https://openrouter.ai/api/v1
- model_name: qwen3-coder
litellm_params:
model: openrouter/qwen/qwen3-coder
api_key: or_xxxxxxxxx
api_base: https://openrouter.ai/api/v1
Substitua or_xxxxxxxxx pela sua chave OpenRouter.
3. Inicie o proxy:
litellm --config litellm.yaml
Passo 2: Apontar o Claude Code para o LiteLLM
- Defina as variáveis de ambiente:
export ANTHROPIC_BASE_URL="http://localhost:4000"
export ANTHROPIC_AUTH_TOKEN="litellm_master"
export ANTHROPIC_MODEL="gpt-oss-20b"
2. Teste:
claude --model gpt-oss-20b
O LiteLLM roteia as requisições para o GPT-OSS via OpenRouter, com registro de custos e roteamento simple-shuffle para confiabilidade.
Passo 3: Notas
- Evitar Roteamento de Latência: Use o modo simple-shuffle no LiteLLM para evitar problemas com modelos Anthropic.
- Rastreamento de Custos: O LiteLLM registra o uso para transparência.
Testando GPT-OSS com Claude Code
Vamos garantir que o GPT-OSS esteja funcionando! Abra o Claude Code e experimente estes comandos:
Geração de Código:
claude --model gpt-oss-20b "Write a Python REST API with Flask"
Espere uma resposta como:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api', methods=['GET'])
def get_data():
return jsonify({"message": "Hello from GPT-OSS!"})
if __name__ == '__main__':
app.run(debug=True)
Análise de Base de Código:
claude --model gpt-oss-20b "Summarize src/server.js"
O GPT-OSS aproveita sua janela de contexto de 128K para analisar seu arquivo JavaScript e retornar um resumo.
Depuração:
claude --model gpt-oss-20b "Debug this buggy Python code: [paste code]"
Com uma taxa de aprovação de 87.3% no HumanEval, o GPT-OSS deve identificar e corrigir problemas com precisão.
Dicas de Solução de Problemas
- 404 em /v1/chat/completions? Certifique-se de que
--enable-openaiesteja ativo no TGI (Caminho A) ou verifique a disponibilidade do modelo do OpenRouter (Caminho B). - Respostas Vazias? Verifique se
ANTHROPIC_MODELcorresponde ao slug (por exemplo,gpt-oss-20b). - Erro 400 Após Troca de Modelo? Use o roteamento simple-shuffle no LiteLLM (Caminho C).
- Primeiro Token Lento? Aqueça os endpoints do Hugging Face com um pequeno prompt após escalar para zero.
- Claude Code Travando? Atualize para ≥ 0.5.3 e certifique-se de que as variáveis de ambiente estejam configuradas corretamente.
Por Que Usar GPT-OSS com Claude Code?
Emparelhar o GPT-OSS com o Claude Code é o sonho de todo desenvolvedor. Você obtém:
- Economia de Custos: Os $0.50/M tokens de entrada do OpenRouter superam os modelos proprietários, e as configurações locais do TGI são gratuitas após os custos de hardware.
- Poder de Código Aberto: A licença Apache 2.0 do GPT-OSS permite que você personalize ou implemente de forma privada.
- Fluxo de Trabalho Contínuo: A CLI do Claude Code parece conversar com um colega de codificação, enquanto o GPT-OSS lida com o trabalho pesado com pontuações de 94.2% MMLU e 96.6% AIME.
- Flexibilidade: Alterne entre modelos GPT-OSS, Qwen ou Anthropic com LiteLLM ou OpenRouter.
Os usuários estão elogiando a proeza de codificação do GPT-OSS, chamando-o de "uma fera econômica para projetos com vários arquivos". Seja auto-hospedando ou usando proxy através do OpenRouter, esta configuração mantém os custos baixos e a produtividade alta.
Conclusão
Agora você está pronto para arrasar com o GPT-OSS e o Claude Code! Seja auto-hospedando no Hugging Face, usando proxy via OpenRouter ou LiteLLM para alternar modelos, você tem uma configuração de codificação poderosa e econômica. Desde a geração de APIs REST até a depuração de código, o GPT-OSS entrega, e o Claude Code faz com que pareça sem esforço. Experimente, compartilhe seus prompts favoritos nos comentários e vamos nos empolgar com a codificação de IA!
Quer uma plataforma integrada e completa para sua Equipe de Desenvolvedores trabalharem juntos com máxima produtividade?
Apidog atende a todas as suas demandas e substitui o Postman por um preço muito mais acessível!