
Desenvolvedores buscam constantemente ferramentas poderosas para construir aplicações inteligentes. A OpenAI atende a essa necessidade com o lançamento do GPT-OSS, uma série de modelos de linguagem de peso aberto que fornecem capacidades avançadas de raciocínio. Esses modelos, incluindo gpt-oss-120b e gpt-oss-20b, permitem personalização e implantação em diversos ambientes. Os usuários os acessam por meio de APIs fornecidas por plataformas de hospedagem, possibilitando uma integração perfeita em projetos.
Para começar a trabalhar com a API GPT-OSS, os desenvolvedores obtêm acesso por meio de provedores como OpenRouter ou Together AI. Essas plataformas hospedam os modelos e expõem endpoints padrão compatíveis com o formato da API da OpenAI. Essa compatibilidade simplifica a migração de modelos proprietários.
O Que É GPT-OSS? Principais Recursos e Capacidades
A OpenAI projeta o GPT-OSS como uma família de modelos Mixture-of-Experts (MoE). Essa arquitetura ativa apenas um subconjunto de parâmetros por token, aumentando a eficiência. Por exemplo, o gpt-oss-120b possui 117 bilhões de parâmetros totais, mas ativa apenas 5,1 bilhões por token. Da mesma forma, o gpt-oss-20b usa 21 bilhões de parâmetros com 3,6 bilhões ativos.
Os modelos empregam estruturas baseadas em Transformer com camadas de atenção densas e esparsas alternadas. Eles incorporam Rotary Positional Embeddings (RoPE) para lidar com contextos longos de até 128.000 tokens. Os desenvolvedores se beneficiam disso em aplicações que exigem entrada extensa, como sumarização de documentos.
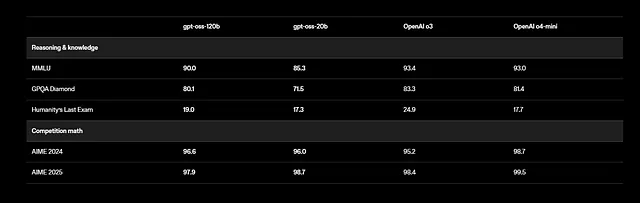
Além disso, o GPT-OSS suporta tarefas multilíngues, embora o treinamento se concentre no inglês com ênfase em dados de STEM e codificação. Os benchmarks mostram resultados impressionantes: o gpt-oss-120b pontua 94,2% no MMLU (Massive Multitask Language Understanding) e 96,6% no AIME (American Invitational Mathematics Examination). Ele supera modelos como o o4-mini em consultas relacionadas à saúde e matemática de competição.
Os desenvolvedores utilizam recursos de chamada de ferramentas (tool calling), onde o modelo invoca funções externas como pesquisa na web ou execução de código. Essa capacidade de agência permite a construção de sistemas autônomos. Por exemplo, o modelo encadeia múltiplas chamadas de ferramentas em uma única resposta para resolver problemas passo a passo.
Além disso, os modelos aderem à licença Apache 2.0, permitindo modificação e implantação gratuitas. A OpenAI fornece pesos no Hugging Face, quantizados no formato MXFP4 para uso reduzido de memória. Os usuários podem executá-los localmente ou por meio de provedores de nuvem.
No entanto, considerações de segurança se aplicam. A OpenAI realiza avaliações sob sua Estrutura de Preparação, testando riscos como desinformação. Os desenvolvedores implementam salvaguardas, como a filtragem de saídas, para mitigar problemas.
Em essência, o GPT-OSS combina poder com acessibilidade. Sua natureza aberta incentiva contribuições da comunidade, levando a melhorias rápidas. Em seguida, identifique os provedores que oferecem acesso à API para esses modelos.
Escolhendo Provedores para Acesso à API GPT-OSS
Várias plataformas hospedam modelos GPT-OSS e fornecem endpoints de API. Os desenvolvedores selecionam com base em necessidades como velocidade, custo e escalabilidade. O OpenRouter, por exemplo, oferece o gpt-oss-120b com preços competitivos e fácil integração.
A Together AI oferece outra opção, enfatizando implantações prontas para empresas. Ela suporta o modelo por meio de um endpoint /v1/chat/completions, compatível com clientes OpenAI. Os desenvolvedores enviam payloads JSON especificando mensagens, max_tokens e temperatura.
Além disso, Fireworks AI e Cerebras oferecem inferência de alta velocidade. A Cerebras atinge até 3.000 tokens por segundo, ideal para aplicações em tempo real. Os preços variam: o OpenRouter cobra cerca de US$ 0,15 por milhão de tokens de entrada, enquanto a Together AI oferece taxas semelhantes com descontos por volume.
Os desenvolvedores também consideram o auto-hospedagem para privacidade. Ferramentas como vLLM ou Ollama permitem executar o GPT-OSS em servidores locais, expondo uma API. Por exemplo, o vLLM serve o modelo com rotas compatíveis com OpenAI, exigindo um único comando para iniciar.
No entanto, provedores de nuvem simplificam o dimensionamento. AWS, Azure e Vercel integram o GPT-OSS por meio de parcerias com a OpenAI. Essas opções lidam com balanceamento de carga e auto-dimensionamento automaticamente.
Além disso, avalie a latência. O gpt-oss-20b é adequado para dispositivos de borda com requisitos mais baixos, enquanto o gpt-oss-120b exige GPUs como a NVIDIA H100. Os provedores otimizam para hardware, garantindo desempenho consistente.
Em resumo, o provedor certo se alinha aos objetivos do projeto. Uma vez escolhido, prossiga para obter as credenciais da API.
Obtendo Acesso à API e Configurando Seu Ambiente
Os desenvolvedores começam registrando-se no site de um provedor. Para o OpenRouter, visite openrouter.ai, crie uma conta e navegue até a seção Chaves. Gere uma nova chave de API, nomeando-a para referência, e copie-a com segurança.
Em seguida, instale as bibliotecas cliente. Em Python, use pip para adicionar openai: pip install openai. Configure o cliente com a URL base e a chave. Por exemplo:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
Este setup permite enviar requisições para modelos gpt-oss.
Além disso, para a Together AI, use o SDK deles: pip install together. Inicialize com:
import together
together.api_key = "your_together_api_key"
Teste a conexão listando modelos ou enviando uma consulta simples.
No entanto, verifique o hardware se for auto-hospedar. Baixe os pesos do Hugging Face: huggingface-cli download openai/gpt-oss-120b. Em seguida, use o vLLM para servir: vllm serve openai/gpt-oss-120b.
Além disso, defina variáveis de ambiente para segurança. Armazene as chaves em arquivos .env e carregue-as com a biblioteca dotenv.
Em caso de problemas, verifique a documentação do provedor para limites de taxa ou erros de autenticação. Essa preparação garante interações suaves com a API.
Fazendo Sua Primeira Chamada de API para o GPT-OSS
Os desenvolvedores criam requisições usando o endpoint de chat completions. Especifique o modelo, como "openai/gpt-oss-120b", no payload.
Para uma chamada básica, prepare as mensagens como uma lista de dicionários. Cada um inclui função (sistema, usuário, assistente) e conteúdo.
Aqui está um exemplo em Python:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
Isso gera uma resposta explicando o conceito tecnicamente.
Além disso, ajuste os parâmetros para controle. A temperatura influencia a criatividade – valores mais baixos produzem saídas determinísticas. Top_p limita a amostragem de tokens, enquanto presence_penalty desencoraja a repetição.
Em seguida, incorpore a chamada de ferramentas. Defina as ferramentas na requisição:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
O modelo responde com uma chamada de ferramenta, que os desenvolvedores executam e realimentam.
No entanto, lide com as respostas com cuidado. Analise o JSON para conteúdo, finish_reason e estatísticas de uso, como contagens de tokens.
Além disso, para cadeia de pensamento, solicite com "Pense passo a passo." Defina o esforço de raciocínio nas mensagens do sistema: "reasoning_effort: medium".
Experimente com gpt-oss-20b para testes mais rápidos: Substitua o nome do modelo nas chamadas.
Em cenários avançados, transmita respostas usando stream=True para saída em tempo real.
Esses passos constroem habilidades fundamentais. Agora, integre ferramentas de teste como o Apidog.
Integrando o Apidog para Testes Eficientes da API GPT-OSS
Os desenvolvedores confiam no Apidog para testar e depurar interações de API. Essa ferramenta fornece uma interface amigável para enviar requisições para endpoints gpt-oss.
Primeiro, instale o Apidog a partir do site deles. Crie um novo projeto e adicione um endpoint de API, como https://openrouter.ai/api/v1/chat/completions.
Em seguida, configure os cabeçalhos: Adicione Authorization com token Bearer e Content-Type como application/json.
Além disso, construa o corpo da requisição. Use o editor JSON do Apidog para inserir modelo, mensagens e parâmetros. Por exemplo, teste uma chamada gpt-oss para geração de código.
O Apidog visualiza as respostas, destacando erros ou sucessos. Ele suporta variáveis de ambiente para alternar chaves de API entre provedores.
No entanto, aproveite as coleções para organizar os testes. Agrupe as consultas GPT-OSS por tarefa, como raciocínio ou uso de ferramentas, e execute-as em lotes.
Além disso, o Apidog gera snippets de código em linguagens como Python ou cURL a partir de suas requisições, acelerando o desenvolvimento.
Para colaboração, compartilhe projetos com equipes. Isso garante testes consistentes das integrações do gpt-oss.
Na prática, use o Apidog para monitorar o uso de tokens e otimizar os prompts, reduzindo custos.
No geral, o Apidog aumenta a produtividade ao trabalhar com a API GPT-OSS.
Uso Avançado: Fine-Tuning e Implantação
Os desenvolvedores realizam o fine-tuning do GPT-OSS para domínios específicos. Use a biblioteca transformers do Hugging Face para carregar pesos e treinar em conjuntos de dados personalizados.
Por exemplo, prepare dados no formato JSONL com pares de prompt-completion. Execute scripts de fine-tuning do repositório GitHub.
Além disso, implante modelos ajustados via vLLM para servir a API. Isso suporta cargas de produção com recursos como o batching dinâmico.
Em seguida, explore extensões multimodais. Embora focado em texto, integre com modelos de visão para aplicações híbridas.
No entanto, monitore o overfitting durante o fine-tuning. Use conjuntos de validação e early stopping.
Além disso, dimensione com inferência distribuída em clusters. Provedores como a AWS oferecem opções gerenciadas.
Em configurações de agente, encadeie o GPT-OSS com APIs externas para fluxos de trabalho como pesquisa automatizada.
Essas técnicas expandem as capacidades além das chamadas básicas.
Melhores Práticas, Limitações e Solução de Problemas
Os desenvolvedores seguem as melhores práticas para obter resultados ótimos. Crie prompts claros, use exemplos few-shot e itere com base nas saídas.
Além disso, respeite os limites de taxa – verifique os painéis do provedor para evitar o throttling.
No entanto, reconheça as limitações: o GPT-OSS pode alucinar, então valide respostas críticas. Ele carece de atualizações de conhecimento em tempo real.
Além disso, proteja as chaves de API e registre o uso para controle de custos.
Solucione problemas revisando os códigos de erro; 401 indica autenticação inválida, 429 significa que o limite de taxa foi atingido.
Em resumo, siga estas diretrizes para um desempenho confiável.
Conclusão: Potencialize Seus Projetos com a API GPT-OSS
Os desenvolvedores agora possuem as ferramentas para integrar o GPT-OSS de forma eficaz. Desde a configuração até os recursos avançados, este guia o equipa para o sucesso. Experimente, refine e inove com o gpt-oss e o Apidog para criar soluções de IA impactantes.