
Olá, entusiastas de IA! Preparem-se porque a OpenAI acaba de lançar uma bomba com seu novo modelo de peso aberto, o GPT-OSS-120B, e ele está chamando a atenção na comunidade de IA. Lançado sob a licença Apache 2.0, este gigante foi projetado para raciocínio, codificação e tarefas de agente, tudo isso enquanto roda em uma única GPU. Neste guia, vamos mergulhar no que torna o GPT-OSS-120B especial, seus benchmarks estelares, preços acessíveis e como você pode usá-lo via API OpenRouter. Vamos explorar esta joia de código aberto e fazer você codificar com ela em pouco tempo!
Quer uma plataforma integrada e completa para sua Equipe de Desenvolvedores trabalharem juntos com produtividade máxima?
Apidog atende a todas as suas demandas e substitui o Postman por um preço muito mais acessível!
O Que É GPT-OSS-120B?
O GPT-OSS-120B da OpenAI é um modelo de linguagem de 117 bilhões de parâmetros (com 5,1 bilhões ativos por token) que faz parte de sua nova série GPT-OSS de peso aberto, ao lado do menor GPT-OSS-20B. Lançado em 5 de agosto de 2025, é um modelo Mixture-of-Experts (MoE) otimizado para eficiência, rodando em uma única GPU NVIDIA H100 ou até mesmo em hardware de consumidor com quantização MXFP4. Ele é construído para tarefas como raciocínio complexo, geração de código e uso de ferramentas, com uma enorme janela de contexto de 128K tokens — pense em 300 a 400 páginas de texto! Sob a licença Apache 2.0, você pode personalizá-lo, implantá-lo ou até mesmo comercializá-lo, tornando-o um sonho para desenvolvedores e empresas que desejam controle e privacidade.

Benchmarks: Como o GPT-OSS-120B se Compara?
O GPT-OSS-120B não fica para trás quando o assunto é desempenho. Os benchmarks da OpenAI mostram que ele é um forte concorrente contra modelos proprietários como o próprio o4-mini e até mesmo o Claude 3.5 Sonnet. Aqui está o resumo:
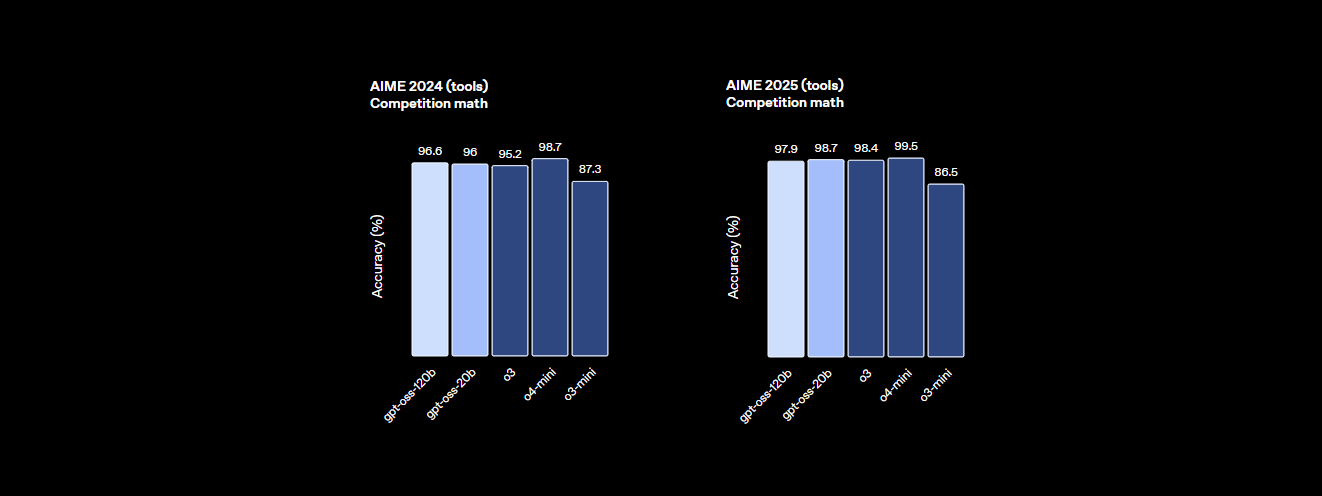
- Poder de Raciocínio: Ele atinge 94,2% no MMLU (Massive Multitask Language Understanding), um pouco abaixo dos 95,1% do GPT-4, e acerta 96,6% nas competições de matemática AIME, superando muitos modelos fechados.
- Habilidade de Codificação: No Codeforces, ele ostenta uma classificação Elo de 2622, e atinge uma taxa de aprovação de 87,3% no HumanEval para geração de código, tornando-o o melhor amigo de um programador.
- Saúde e Uso de Ferramentas: Ele supera o o4-mini no HealthBench para consultas relacionadas à saúde e se destaca em tarefas de agente como o TauBench, graças ao seu raciocínio de cadeia de pensamento (CoT) e capacidades de chamada de ferramentas.
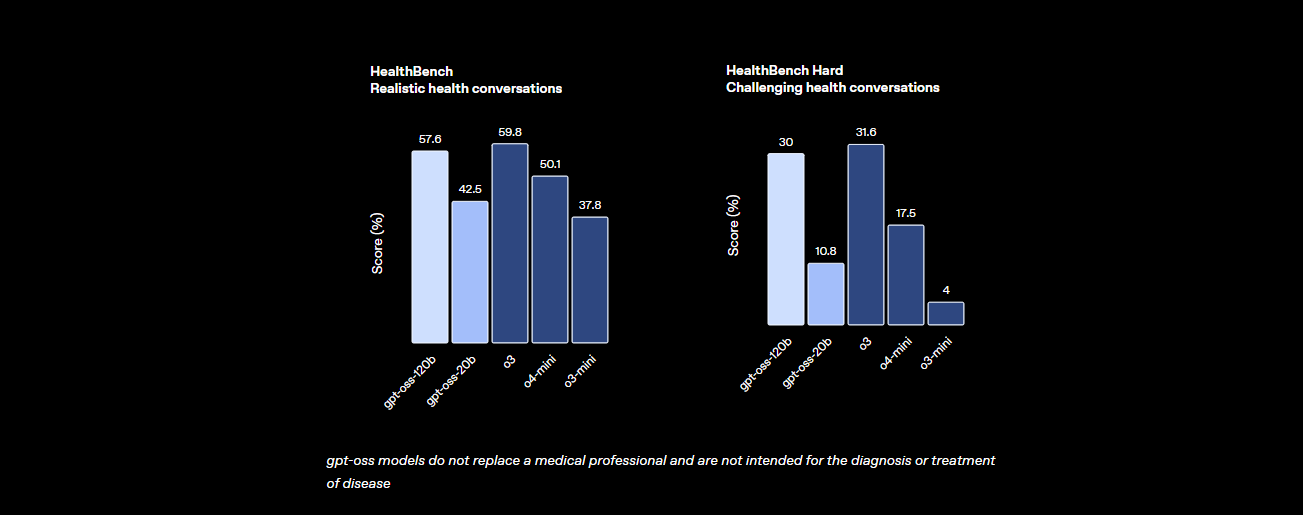
- Velocidade: Em uma GPU H100, ele processa 45 tokens por segundo, com provedores como Cerebras atingindo até 3.000 tokens/seg para necessidades de alto volume. O OpenRouter entrega ~500 tokens/seg, superando muitos modelos fechados.
Essas estatísticas mostram que o GPT-OSS-120B está quase em paridade com modelos proprietários de ponta, sendo ao mesmo tempo aberto e personalizável. É uma fera para matemática, codificação e resolução geral de problemas, com segurança incorporada através de ajuste fino adversarial para manter os riscos baixos.
Preços: Acessíveis e Transparentes
Uma das melhores partes sobre o GPT-OSS-120B? É econômico, especialmente em comparação com modelos proprietários. Veja como ele se divide entre os principais provedores, com base em dados recentes para uma janela de contexto de 131K:
- Implantação Local: Execute-o em seu próprio hardware (por exemplo, uma GPU H100 ou configuração de 80GB VRAM) para custos de API zero. Uma configuração GMKTEC EVO-X2 custa ~€2000 e usa menos de 200W, perfeita para pequenas empresas que priorizam a privacidade.
- Baseten: $0.10/M tokens de entrada, $0.50/M tokens de saída. Latência: 0.20s, Vazão: 491.1 tokens/seg. Saída máxima: 131K tokens.
- Fireworks: $0.15/M entrada, $0.60/M saída. Latência: 0.56s, Vazão: 258.9 tokens/seg. Saída máxima: 33K tokens.
- Together: $0.15/M entrada, $0.60/M saída. Latência: 0.28s, Vazão: 131.1 tokens/seg. Saída máxima: 131K tokens.
- Parasail: $0.15/M entrada, $0.60/M saída (quantização FP4). Latência: 0.40s, Vazão: 94.3 tokens/seg. Saída máxima: 131K tokens.
- Groq: $0.15/M entrada, $0.75/M saída. Latência: 0.24s, Vazão: 1.065 tokens/seg. Saída máxima: 33K tokens.
- Cerebras: $0.25/M entrada, $0.69/M saída. Latência: 0.42s, Vazão: 1.515 tokens/seg. Saída máxima: 33K tokens. Ideal para necessidades de alta velocidade, atingindo até 3.000 tokens/seg em algumas configurações.
Com o GPT-OSS-120B, você obtém alto desempenho por uma fração do custo do GPT-4 (~$20.00/M tokens), com provedores como Groq e Cerebras oferecendo vazão incrivelmente rápida para aplicações em tempo real.
Como Usar o GPT-OSS-120B com Cline via OpenRouter
Quer aproveitar o poder do GPT-OSS-120B para seus projetos de codificação? Embora o Claude Desktop e o Claude Code não suportem integração direta com modelos OpenAI como o GPT-OSS-120B devido à sua dependência do ecossistema da Anthropic, você pode usar facilmente este modelo com o Cline, uma extensão gratuita de código aberto para VS Code, via API OpenRouter. Além disso, o Cursor recentemente restringiu sua opção Bring Your Own Key (BYOK) para usuários não-Pro, bloqueando recursos como os modos Agente e Edição por trás de uma assinatura de $20/mês, tornando o Cline uma alternativa mais flexível para usuários BYOK. Veja como configurar o GPT-OSS-120B com Cline e OpenRouter, passo a passo.
Passo 1: Obtenha uma Chave de API OpenRouter
- Cadastre-se no OpenRouter:
- Visite openrouter.ai e crie uma conta gratuita usando Google ou GitHub.
2. Encontre o GPT-OSS-120B:
- Na aba Modelos, procure por “gpt-oss-120b” e selecione-o.
3. Gere uma Chave de API:
- Vá para a seção Chaves, clique em Criar Chave de API, nomeie-a (por exemplo, “GPT-OSS-Cursor”) e copie-a. Guarde-a em segurança.
Passo 2: Use o Cline no VS Code com BYOK
Para acesso BYOK irrestrito, o Cline (uma extensão de código aberto para VS Code) é uma fantástica alternativa ao Cursor. Ele suporta o GPT-OSS-120B via OpenRouter sem bloqueios de recursos. Veja como configurá-lo:
- Instale o Cline:
- Abra o VS Code (code.visualstudio.com).
- Vá para o painel de Extensões (
Ctrl+Shift+XouCmd+Shift+X). - Procure por “Cline” e instale-o (por nickbaumann98, github.com/cline/cline).
2. Configure o OpenRouter:
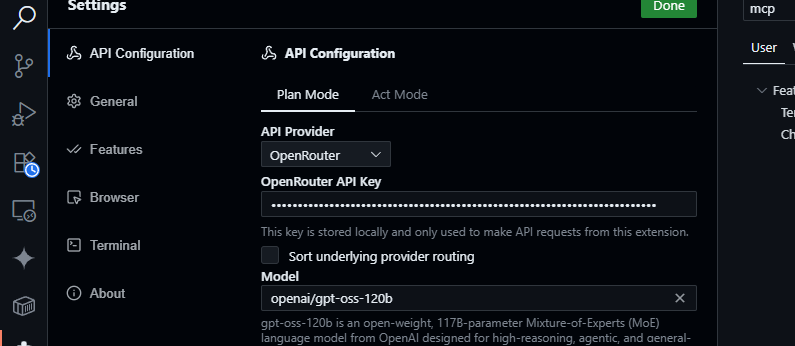
- Abra o painel do Cline (clique no ícone do Cline na Barra de Atividades).
- Clique no ícone de engrenagem no painel do Cline.
- Selecione OpenRouter como provedor.
- Cole sua chave de API OpenRouter.
- Escolha
openai/gpt-oss-120bcomo o modelo.
3. Salve e Teste:
- Salve as configurações. No painel de chat do Cline, tente:
Gerar uma função JavaScript para analisar dados JSON.
- Espere uma resposta como:
function parseJSON(data) {
try {
return JSON.parse(data);
} catch (e) {
console.error("Invalid JSON:", e.message);
return null;
}
}
- Teste consultas de base de código:
Resumir src/api/server.js
- O Cline analisará seu projeto e retornará um resumo, aproveitando a janela de contexto de 128K do GPT-OSS-120B.
Por Que Cline em Vez de Cursor ou Claude?
- Sem Integração com Claude: O Claude Desktop e o Claude Code estão restritos aos modelos da Anthropic (por exemplo, Claude 3.5 Sonnet) e não suportam modelos OpenAI como o GPT-OSS-120B devido a restrições do ecossistema.
- Restrições BYOK do Cursor: A recente proibição do Cursor de BYOK para usuários não-Pro significa que você não pode acessar os modos Agente ou Edição sem uma assinatura de $20/mês, mesmo com uma chave de API OpenRouter válida. O Cline não tem tais limites, oferecendo acesso total aos recursos gratuitamente com sua chave de API.
- Privacidade e Controle: O Cline envia solicitações diretamente para o OpenRouter, ignorando servidores de terceiros (ao contrário do roteamento AWS do Cursor), aumentando a privacidade.
Dicas de Solução de Problemas
- Chave de API Inválida? Verifique sua chave no painel do OpenRouter e certifique-se de que ela esteja ativa.
- Modelo Não Disponível? Verifique a lista de modelos do OpenRouter para openai/gpt-oss-120b. Se estiver faltando, tente provedores como Fireworks AI ou entre em contato com o suporte do OpenRouter.
- Respostas Lentas? Certifique-se de que sua internet esteja estável. Para um desempenho mais rápido, considere modelos mais leves como o GPT-OSS-20B.
- Erros do Cline? Atualize o Cline via o painel de Extensões e verifique os logs no painel de Saída do VS Code.
Por Que Usar o GPT-OSS-120B?
O modelo GPT-OSS-120B é um divisor de águas para desenvolvedores e empresas, oferecendo uma combinação atraente de desempenho, flexibilidade e custo-benefício. Veja por que ele se destaca:
- Liberdade de Código Aberto: Licenciado sob Apache 2.0, você pode ajustar, implantar ou comercializar o GPT-OSS-120B sem restrições, dando-lhe controle total sobre seus fluxos de trabalho de IA.
- Economia de Custos: Execute-o localmente em uma única GPU H100 ou hardware de consumidor (80GB VRAM) para custos de API zero. Via OpenRouter, o preço é altamente competitivo em ~$0.50/M tokens de entrada e ~$2.00/M tokens de saída, uma fração dos ~$20.00/M tokens do GPT-4, oferecendo até 90% de economia para usuários pesados. Outros provedores como Groq ($0.15/M entrada, $0.75/M saída) e Cerebras ($0.25/M entrada, $0.69/M saída) também mantêm os custos baixos.
- Desempenho: Ele atinge quase a paridade com o o4-mini da OpenAI, pontuando 94,2% no MMLU, 96,6% em matemática AIME e 87,3% no HumanEval para codificação. Sua janela de contexto de 128K tokens (300-400 páginas) lida com grandes bases de código ou documentos com facilidade.
- Raciocínio de Cadeia de Pensamento (CoT): A transparência total do CoT do modelo permite que você veja seu raciocínio passo a passo, tornando mais fácil depurar saídas e detectar vieses ou erros. Você pode ajustar o esforço de raciocínio (baixo, médio, alto) via prompts do sistema (por exemplo, “Raciocínio: alto”) para tarefas como matemática complexa ou codificação, equilibrando velocidade e profundidade. Este design CoT não supervisionado ajuda pesquisadores a monitorar o comportamento do modelo sem supervisão direta, aumentando a confiança e a segurança.
- Capacidades de Agente: Suporte nativo para uso de ferramentas, como navegação na web e execução de código Python, o torna ideal para fluxos de trabalho de agente. Ele pode encadear múltiplas chamadas de ferramentas (por exemplo, 28 pesquisas web consecutivas em uma demonstração) para tarefas complexas como agregação de dados ou automação.
- Privacidade: Hospede-o no local (por exemplo, via Dell Enterprise Hub) para controle completo dos dados, perfeito para empresas ou usuários preocupados com a privacidade.
- Flexibilidade: Compatível com OpenRouter, Fireworks AI, Cerebras e configurações locais como Ollama ou LM Studio, ele roda em diversos hardwares, de GPUs RTX a Apple Silicon.
O burburinho da comunidade no X destaca sua velocidade (até 1.515 tokens/seg no Cerebras) e proeza de codificação, com desenvolvedores adorando sua capacidade de lidar com projetos de múltiplos arquivos e sua natureza de peso aberto para personalização. Se você está construindo agentes de IA ou ajustando para tarefas de nicho, o GPT-OSS-120B oferece um valor incomparável.
Conclusão
O GPT-OSS-120B da OpenAI é um modelo revolucionário de peso aberto, combinando desempenho de ponta com implantação econômica. Seus benchmarks rivalizam com modelos proprietários, seu preço é amigável ao bolso e é fácil de integrar com Cursor ou Cline via API do OpenRouter. Seja você codificando, depurando ou raciocinando através de problemas complexos, este modelo entrega. Experimente, explore sua janela de contexto de 128K e nos conte seus casos de uso interessantes nos comentários — estou ansioso para saber!
Para mais detalhes, confira o repositório em github.com/openai/gpt-oss ou o anúncio da OpenAI em openai.com.
Quer uma plataforma integrada e completa para sua Equipe de Desenvolvedores trabalharem juntos com produtividade máxima?
Apidog atende a todas as suas demandas e substitui o Postman por um preço muito mais acessível!