
Se você tem acompanhado os desenvolvimentos de IA em 2025, provavelmente ouviu muito burburinho em torno do Google Gemini 3, o modelo de IA multimodal de próxima geração projetado para competir com (e às vezes superar) o GPT-5. Quer você seja um engenheiro de software, um fundador de startup, um entusiasta de IA ou apenas alguém curioso sobre o que o Gemini 3 pode fazer, aprender a trabalhar com a API Google Gemini 3 abre as portas para a criação de aplicativos muito mais inteligentes e dinâmicos.
Mas sejamos honestos; a documentação do Google pode ser um pouco densa se você está apenas começando. Então, neste guia, vamos detalhar tudo de uma forma clara, amigável e acessível para iniciantes.
Agora, vamos liberar o poder do modelo de IA mais avançado do Google!
O Que É o Google Gemini 3?
Google Gemini 3 é o modelo mais recente da família de IA multimodal do Google. Ao contrário dos modelos anteriores, o Gemini 3 é otimizado para:
- raciocínio e resolução de problemas
- entrada/saída multimodal (texto, imagens, áudio, incorporações de vídeo)
- uso de ferramentas e fluxos de trabalho de agente
- inferência rápida com endpoints de baixa latência
- troca dinâmica de modelos dependendo da sua tarefa
Mas o maior destaque é este:
Gemini 3 introduz dois principais “modos de pensamento”:
O parâmetro thinking_level controla a profundidade **máxima** do processo de raciocínio interno do modelo antes que ele produza uma resposta. O Gemini 3 trata esses níveis como permissões relativas para o pensamento, em vez de garantias de token estritas. Se thinking_level não for especificado, o Gemini 3 Pro usará o padrão high.
- Pensamento de Alto/Dinâmico: Maximiza a profundidade do raciocínio. O modelo pode levar significativamente mais tempo para alcançar o primeiro token, mas a saída será mais cuidadosamente raciocinada.
- Pensamento de Baixo: Minimiza a latência e o custo. Melhor para seguir instruções simples, chat ou aplicativos de alto throughput.
Muitos iniciantes ainda não sabem disso, mas escolher o modo correto melhora drasticamente a qualidade da saída e ajuda a controlar seus custos.
Em breve, abordaremos como escolher um modo usando a API.
Por Que Usar a API Gemini 3 em Vez de uma Ferramenta de UI?
Claro, você poderia usar o Gemini dentro do Google AI Studio. Mas se você quiser:
- construir aplicativos
- automatizar tarefas
- integrar o modelo em fluxos de trabalho
- criar chatbots
- processar dados
- treinar agentes
- executar tarefas multimodais
você precisará da API Gemini 3.
Este guia foca na API REST porque:
- é mais fácil para iniciantes
- não são necessárias bibliotecas de cliente
- você pode testá-la rapidamente no Apidog ou Postman
- funciona em qualquer ambiente de backend
Como a API Gemini 3 Funciona (Visão Geral Simples)
Mesmo que o Gemini possua capacidades avançadas, a própria API é bastante direta.
Você envia uma solicitação POST para…
<https://generativelanguage.googleapis.com/v1beta/models/{MODEL_ID}:generateContent?key=YOUR_API_KEY>
Você inclui JSON como:
- o prompt de texto
- uma lista de mensagens (opcional)
- configurações do modelo
- configurações de segurança
Você recebe…
- texto de saída do modelo
- estrutura de raciocínio (para pensamento de Alto/Dinâmico)
- citações
- metadados
- objetos multimodais (se aplicável)
Uma vez que você entende essa estrutura, todo o resto se torna mais fácil.
Primeiros Passos: Seus Primeiros Passos com a API Gemini
Passo 1: Obtenha Sua Chave de API
Pense na sua chave de API como uma senha especial que diz ao Google: "Sim, tenho permissão para usar o Gemini." Veja como obter uma:
- Vá para Google AI Studio
- Faça login com sua conta Google
- Clique em "Create API Key" na barra lateral esquerda
- Dê um nome à sua chave e crie-a
- Copie e salve esta chave em um local seguro! Você não poderá vê-la novamente.
Importante: Nunca compartilhe sua chave de API nem a publique em repositórios de código públicos. Trate-a como sua senha.
Passo 2: Escolha Sua Abordagem
Você pode interagir com o Gemini de duas maneiras principais:
- API REST: A abordagem universal. Funciona com qualquer linguagem de programação que possa fazer requisições HTTP. Focaremos neste método.
- SDKs Oficiais: O Google fornece bibliotecas convenientes para Python, Node.js e outras linguagens que lidam com os detalhes HTTP para você.
Como estamos focando nos fundamentos, usaremos a abordagem da API REST, que funciona em qualquer lugar e ajuda você a entender o que está acontecendo por baixo dos panos.
Compreendendo os Modos de Pensamento do Gemini
Uma das características mais poderosas do Gemini é sua capacidade de operar em diferentes "modos de pensamento". Isso não é apenas marketing; ele muda fundamentalmente como o modelo processa suas requisições.
Pensamento de Baixo (O Demônio da Velocidade)
Quando usar: Para tarefas simples, respostas rápidas e quando você está otimizando para velocidade e custo.
- Velocidade: Respostas muito rápidas
- Custo: Mais acessível
- Casos de Uso: Perguntas e respostas simples, classificação de texto, sumarização básica, traduções diretas
Por exemplo:
gemini-3-flash
gemini-3-mini
Pense no modo de Pensamento de Baixo como ter uma conversa rápida com um amigo experiente que lhe dá respostas imediatas.
Pensamento de Alto/Dinâmico (O Analista Atencioso)
Quando usar: Para raciocínio complexo, problemas em várias etapas e tarefas que exigem análise profunda.
- Velocidade: Mais lento (ele "pensa" mais antes de responder)
- Custo: Mais caro
- Casos de Uso: Problemas matemáticos complexos, raciocínio lógico, depuração de código, escrita criativa, planejamento estratégico
O Pensamento de Alto/Dinâmico é como consultar um especialista que leva tempo para considerar todos os ângulos antes de lhe dar uma resposta bem fundamentada.
Por exemplo:
gemini-3-pro
gemini-3-pro-thinking
Esses modelos oferecem raciocínio mais profundo, janelas de atenção mais longas e melhores capacidades de planejamento.
A beleza é que você pode escolher ambos os modelos: Pensamento de Alto/Dinâmico e Pensamento de Baixo, dependendo das suas necessidades específicas. Para a maioria dos aplicativos simples, o Pensamento de Baixo é perfeito. Quando você precisa de raciocínio mais profundo, mude para o Pensamento de Alto.
Como regra geral:
| Tipo de Tarefa | Modo do Modelo |
|---|---|
| Pesquisa | Pensamento de Alto/Dinâmico |
| Matemática/Lógica | Pensamento de Alto/Dinâmico |
| Geração de Código | Pensamento de Alto/Dinâmico |
| Chat de cliente | Pensamento de Baixo |
| Geração de texto básica | Pensamento de Baixo |
| Assistentes de UI | Pensamento de Baixo |
| Aplicativos em tempo real | Pensamento de Baixo |
Mostraremos como selecionar cada modelo na API REST.
Construa Sua Primeira Chamada de API REST do Gemini 3
Vamos começar com o exemplo mais simples possível.
Endpoint
POST <https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>
Exemplo de Corpo da Requisição (JSON)
{
"contents": [
{ "role": "user",
"parts": [{ "text": "Explique como os aviões voam." }]
}
]
}
Exemplo de Comando Curl
curl -X POST \\
-H "Content-Type: application/json" \\
-d '{
"contents": [
{
"role": "user",
"parts": [{ "text": "Explique como os aviões voam." }]
}
]
}' \\
"<https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>"
Usando o Modo de Pensamento de Alto/Dinâmico
Para ativar o modo de raciocínio, você deve usar um modelo que o suporte, como gemini-3-pro-thinking.
Exemplo de API REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Encontre a condição de corrida neste trecho de código C++ multi-threaded: [código aqui]"}]
}]
}'Ao usar o modo de Pensamento de Alto/Dinâmico, você geralmente receberá:
- estruturas de cadeia de pensamento (ocultas, a menos que solicitadas)
- respostas mais coerentes
- tempos de resposta mais lentos
- custos de inferência mais caros
Recomendo usar este modo apenas quando realmente importa, como para raciocínio de longo formato ou planejamento de código.
Usando o Modo de Pensamento de Baixo
Os modelos de Pensamento de Baixo são otimizados para velocidade e são perfeitos para:
- autocompletar
- mensagens curtas
- respostas de UI
- pequenos assistentes
- recursos secundários de chatbot
Exemplo de API REST Usando “Flash”
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Como a IA funciona?"}]
}],
"generationConfig": {
thinkingConfig: {
thinkingLevel: "low"
}
}
}'Modelos de Pensamento de Baixo custam muito menos e retornam respostas quase instantâneas.
Lidando com Entradas Multimodais (Imagens, PDFs, Áudio, Vídeo)
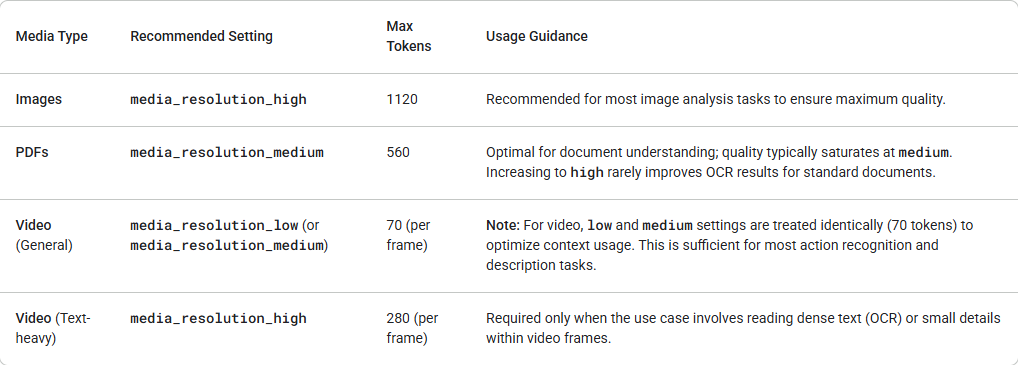
O Gemini 3 introduz controle granular sobre o processamento de visão multimodal através do parâmetro media_resolution. Resoluções mais altas melhoram a capacidade do modelo de ler textos finos ou identificar pequenos detalhes, mas aumentam o uso de tokens e a latência. O parâmetro media_resolution determina o número máximo de tokens alocados por imagem de entrada ou quadro de vídeo.
Você pode agora definir a resolução para media_resolution_low, media_resolution_medium ou media_resolution_high por parte de mídia individual ou globalmente (via generation_config). Se não especificado, o modelo usa padrões ótimos com base no tipo de mídia.
O Gemini 3 suporta embeddings multimodais em:
- imagens
- áudio
- quadros de vídeo
- documentos
Exemplo para upload de uma imagem (base64):
curl "https://generativelanguage.googleapis.com/v1alpha/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [
{ "text": "O que há nesta imagem?" },
{
"inlineData": {
"mimeType": "image/jpeg",
"data": "..."
},
"mediaResolution": {
"level": "media_resolution_high"
}
}
]
}]
}'Testando e Depurando com Apidog
Embora os comandos curl sejam ótimos para testes rápidos, eles se tornam complicados quando você está desenvolvendo um aplicativo real. É aqui que o Apidog se destaca.
Com o Apidog, você pode:
- Salvar Sua Configuração de API: Configure seu endpoint Gemini e chave de API uma vez, depois reutilize-os em todos os seus testes.
- Criar Modelos de Requisição: Salve diferentes tipos de prompts (iniciadores de conversa, solicitações de análise, escrita criativa) como modelos.
- Testar Modos de Pensamento Lado a Lado: Alterne facilmente entre os modos de Pensamento de Baixo e Alto para comparar respostas e desempenho.
- Gerenciar Histórico de Conversas: Use as variáveis de ambiente do Apidog para manter o contexto da conversa em várias requisições.
- Automatizar Testes: Crie suítes de teste que verifiquem se sua integração Gemini está funcionando corretamente.
Veja como você pode configurar uma requisição Gemini no Apidog:
- Crie uma nova requisição POST para:
https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={{api_key}} - Configure uma variável de ambiente
api_keycom sua chave de API real - No corpo, use JSON:
{
"contents": [{
"parts": [{
"text": "{{prompt}}"
}]
}],
"generationConfig": {
"temperature": 0.7,
"maxOutputTokens": 800
}
}
4. Defina outra variável de ambiente prompt com o que você quiser perguntar ao Gemini
Essa abordagem torna a experimentação muito mais rápida e organizada.
Melhores Práticas para a API Gemini
1. Lide com Erros de Forma Elegante
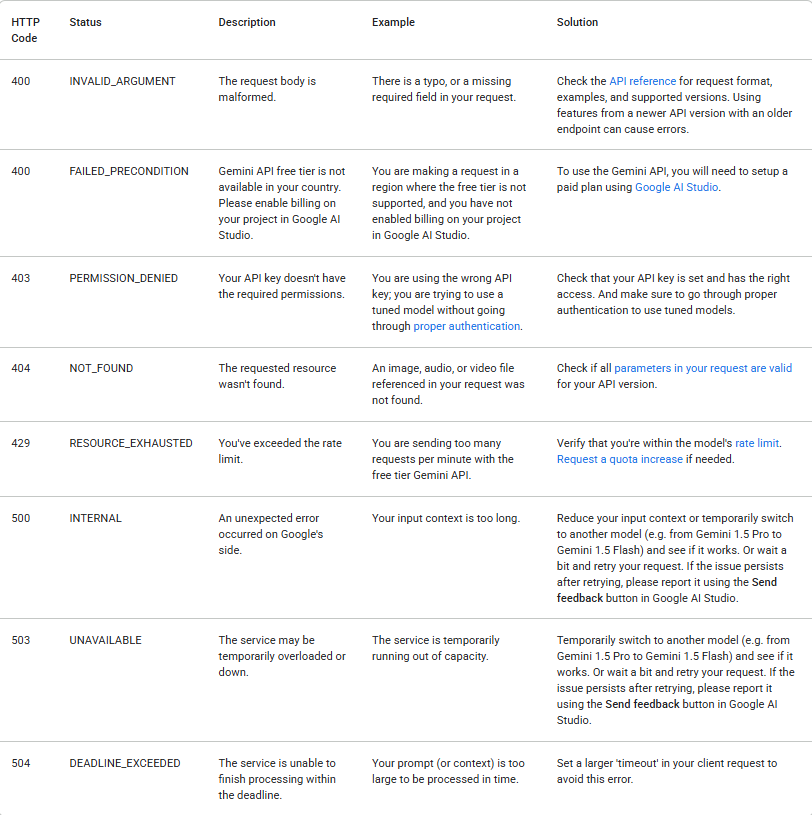
Chamadas de API podem falhar por muitos motivos. Sempre verifique o status da resposta e trate os erros de forma apropriada. A tabela a seguir lista os códigos de erro comuns de backend que você pode encontrar, juntamente com explicações para suas causas e etapas de solução de problemas:
2. Gerencie Seus Custos
O uso da API Gemini é medido e custa dinheiro (após os limites da camada gratuita). Tenha estas dicas em mente:
- Comece com a camada gratuita para experimentar
- Use o modo de Pensamento de Baixo quando possível para tarefas simples
- Defina limites razoáveis de
maxOutputTokens - Monitore seu uso no Google AI Studio
Tokens podem ser caracteres únicos como z ou palavras inteiras como gato. Palavras longas são divididas em vários tokens. O conjunto de todos os tokens usados pelo modelo é chamado de vocabulário, e o processo de dividir o texto em tokens é chamado de tokenização.
Quando o faturamento está ativado, o custo de uma chamada para a API Gemini é determinado em parte pelo número de tokens de entrada e saída, então saber como contar tokens pode ser útil.
3. Crie Prompts Melhores
A qualidade da sua saída depende muito da sua entrada. Aqui estão algumas dicas de engenharia de prompt:
Em vez de: "Escreva sobre cães"
Tente: "Escreva uma postagem de blog educacional de 200 palavras sobre os benefícios de adotar cães de resgate, escrita em um tom amigável e encorajador para potenciais donos de animais de estimação."
Em vez de: "Corrija este código"
Tente: "Por favor, depure esta função Python que deveria calcular o fatorial, mas retorna resultados incorretos para a entrada 5. Explique o que está errado e forneça o código corrigido."

4. Escolha o Modelo Certo
O Google oferece vários modelos Gemini, cada um com diferentes pontos fortes. Verifique se seus parâmetros de modelo estão dentro dos seguintes valores:
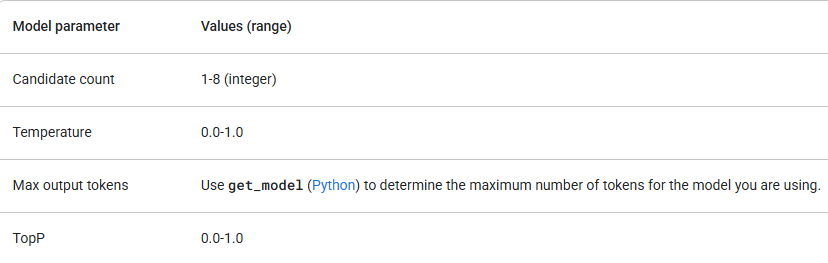
Comece com gemini-1.5-flash e só atualize se precisar de mais capacidade de raciocínio. Além de verificar os valores dos parâmetros, certifique-se de que está usando a versão correta da API (por exemplo, /v1 ou /v1beta) e o modelo que suporta os recursos de que você precisa. Por exemplo, se um recurso estiver em versão Beta, ele só estará disponível na versão /v1beta da API.
Conclusão: Sua Jornada de IA Começa
Agora você tem tudo o que precisa para começar a construir com a API Google Gemini. Você aprendeu como obter uma chave de API, fazer requisições básicas, entender os diferentes modos de pensamento e até mesmo viu alguns exemplos avançados.
Lembre-se de que trabalhar com APIs de IA é um processo iterativo. Você ficará melhor em criar prompts e escolher as configurações certas com a prática. Não tenha medo de experimentar, é assim que você descobrirá todo o potencial do que pode construir.
O passo mais importante a seguir é começar a experimentar. Pegue os exemplos deste guia, modifique-os, desfaça-os e veja o que acontece. A melhor maneira de aprender é fazendo.
Para iniciantes, recomendo fortemente usar o Apidog como sua ferramenta de teste de API REST. Ele ajuda você a:
- depurar requisições
- armazenar variáveis de ambiente
- executar coleções
- comparar rapidamente as saídas do modelo
- compartilhar seus casos de teste de API com colegas de equipe
E como é gratuito, não há desvantagem alguma.