Desenvolvedores buscam constantemente modelos de linguagem poderosos que ofereçam desempenho robusto em diversas aplicações. A Zhipu AI apresenta o GLM-4.6, uma iteração avançada na série GLM que expande os limites das capacidades de inteligência artificial. Este modelo baseia-se em versões anteriores, incorporando aprimoramentos significativos no tratamento de contexto, raciocínio e utilidade prática. Engenheiros integram o GLM-4.6 em seus fluxos de trabalho para lidar com tarefas complexas, desde a geração de código até a criação de conteúdo, com maior eficiência e precisão.
A Zhipu AI projeta o GLM-4.6 como parte do GLM Coding Plan, um serviço baseado em assinatura que começa com um preço acessível. Os usuários acessam este modelo por meio de ferramentas integradas como Claude Code, Cline, OpenCode e outras, permitindo um desenvolvimento assistido por IA sem interrupções. O modelo se destaca em cenários do mundo real, onde processa contextos extensos e gera saídas de alta qualidade. Além disso, o GLM-4.6 demonstra desempenho superior em benchmarks, rivalizando com líderes internacionais como Claude Sonnet 4. Isso o posiciona como uma escolha principal para desenvolvedores na China e em outros lugares que exigem suporte de IA confiável.
Transitando da compreensão da base do modelo, vamos examinar suas principais características e como elas beneficiam as implementações técnicas.
O Que É GLM-4.6?
A Zhipu AI desenvolve o GLM-4.6 como um modelo de linguagem grande otimizado para uma ampla gama de tarefas técnicas e criativas. O modelo apresenta uma arquitetura Mixture of Experts (MoE) de 355 bilhões de parâmetros, que permite computação eficiente enquanto mantém alto desempenho. Os usuários apreciam sua janela de contexto expandida de 200 mil tokens, uma atualização notável em relação ao limite de 128 mil em versões anteriores. Essa expansão permite que o modelo gerencie interações complexas e de formato longo sem perder a coerência.
Além disso, o GLM-4.6 suporta modalidades de entrada e saída de texto, tornando-o versátil para aplicações que exigem processamento de linguagem preciso. O limite máximo de tokens de saída atinge 128 mil, oferecendo amplo espaço para respostas detalhadas. Desenvolvedores aproveitam essas especificações para construir sistemas que lidam com dados extensos, como análise de documentos ou cadeias de raciocínio multi-etapas.
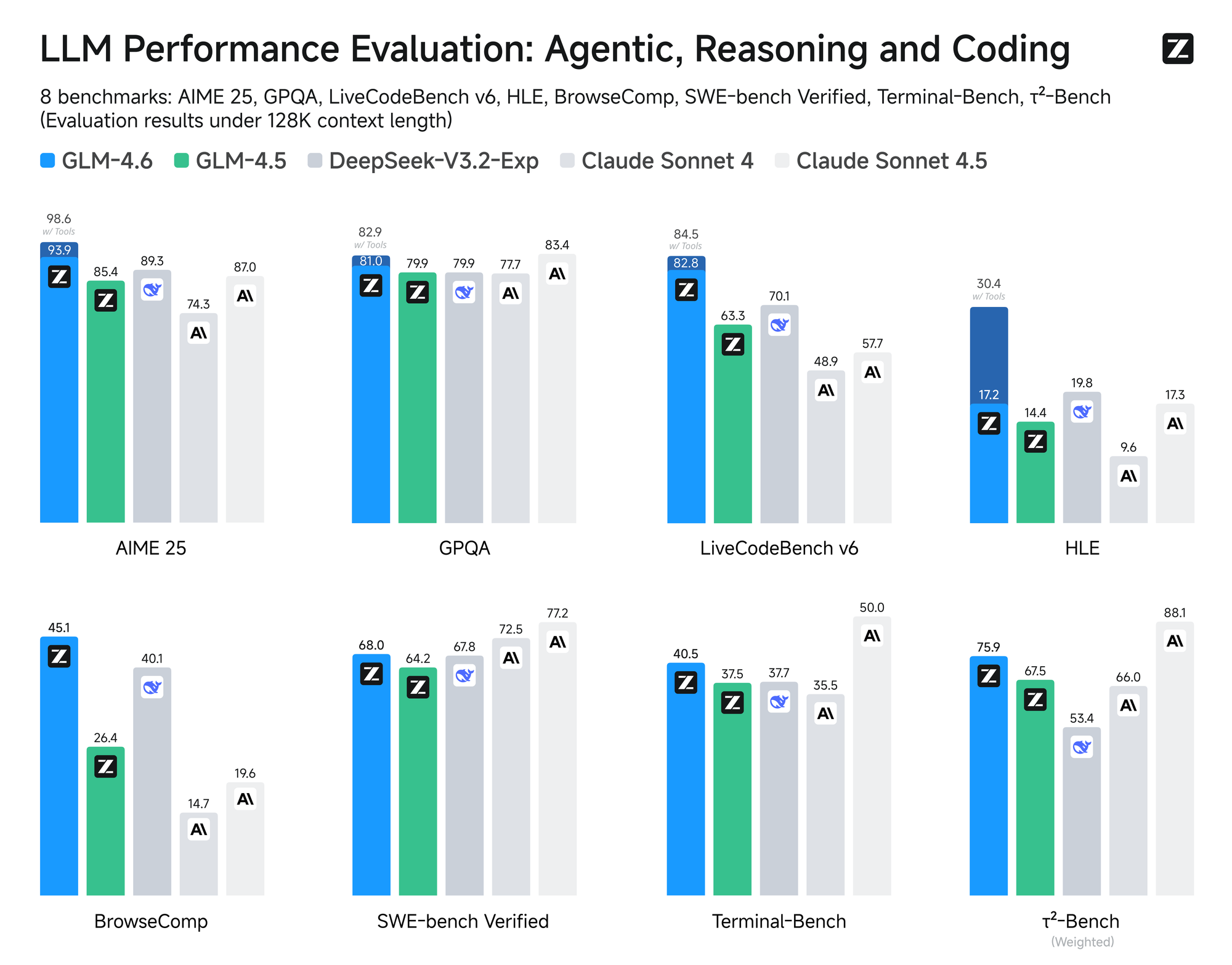
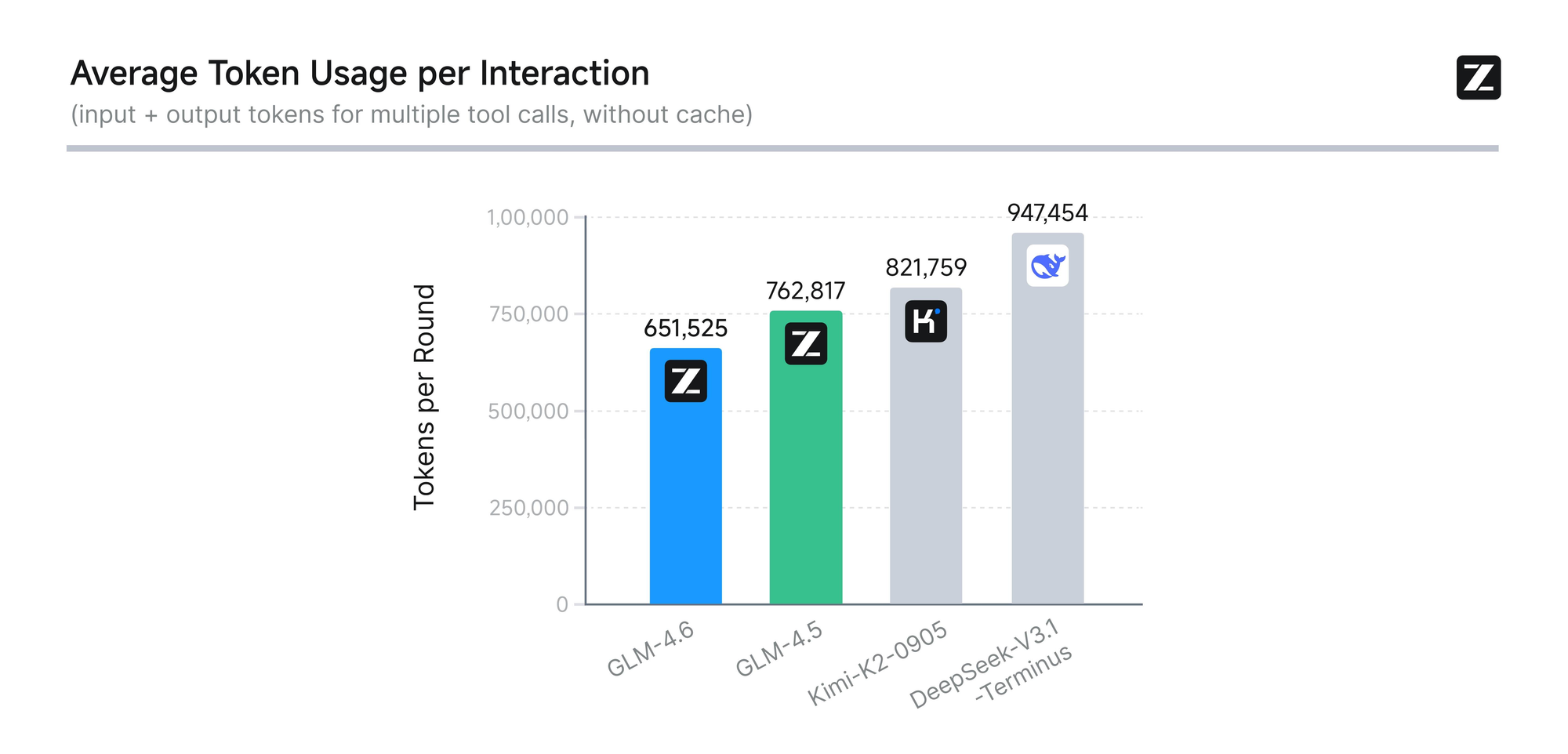
O modelo passa por uma avaliação rigorosa em oito benchmarks autorizados, incluindo AIME 25, GPQA, LCB v6, HLE e SWE-Bench Verified. Os resultados mostram que o GLM-4.6 tem um desempenho semelhante ao de modelos líderes como Claude Sonnet 4 e 4.6. Por exemplo, em testes de codificação no mundo real conduzidos no ambiente Claude Code, o GLM-4.6 supera os concorrentes em 74 cenários práticos. Ele consegue isso com mais de 30% de maior eficiência no consumo de tokens, reduzindo os custos operacionais para usuários de alto volume.
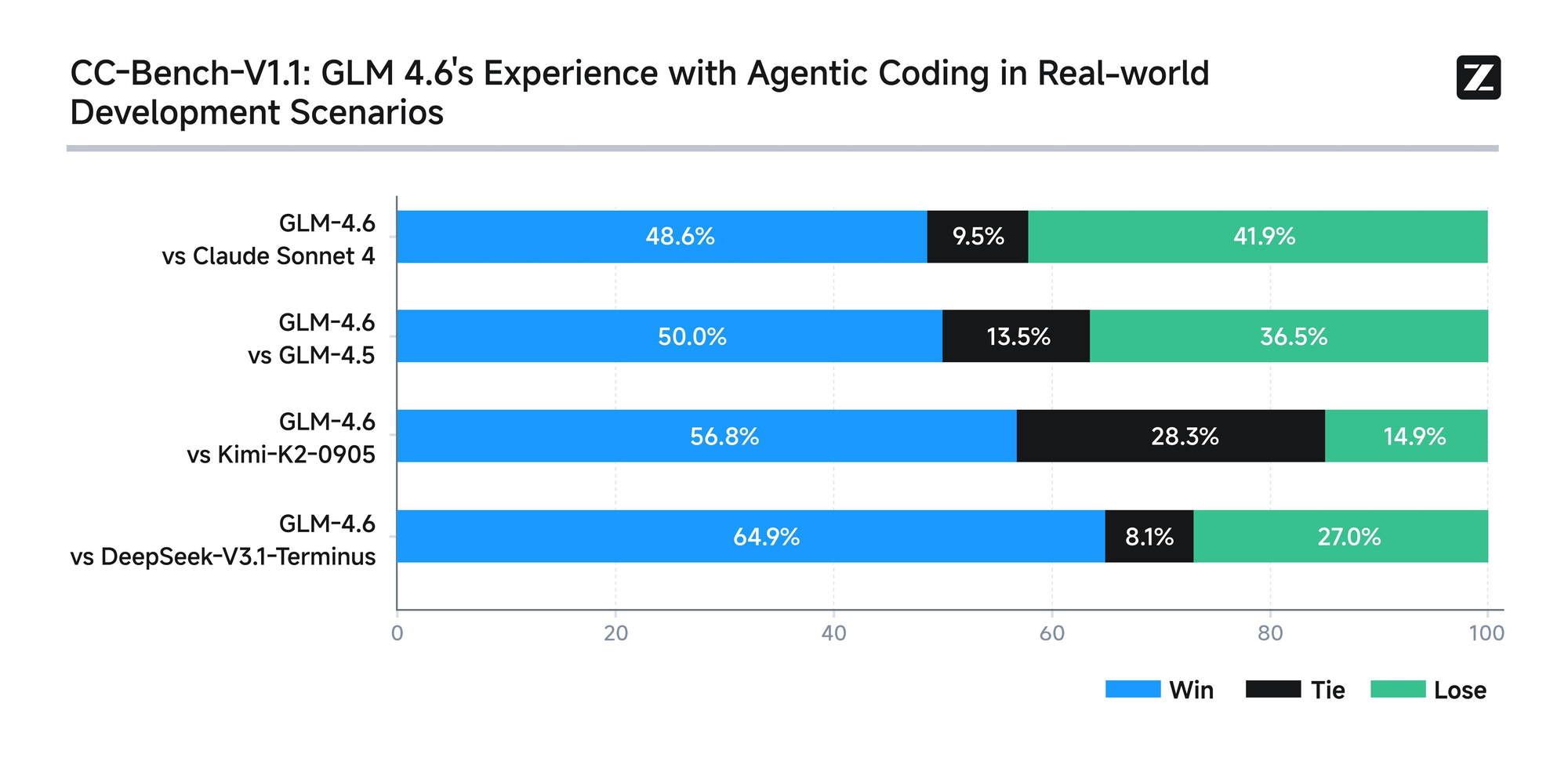
Além disso, a Zhipu AI se compromete com a transparência, divulgando publicamente todas as perguntas de teste e trajetórias de agentes. Essa prática permite que os desenvolvedores verifiquem as alegações e reproduzam os resultados, promovendo a confiança na tecnologia. O GLM-4.6 também integra capacidades avançadas de raciocínio, suportando o uso de ferramentas durante a inferência. Esse recurso aprimora sua utilidade em estruturas de agentes, onde o modelo planeja e executa tarefas de forma autônoma.
Além da codificação, o GLM-4.6 se destaca em outros domínios. Ele aprimora a escrita para se alinhar de perto às preferências humanas, melhorando o estilo, a legibilidade e a autenticidade na interpretação de papéis. Em tarefas de tradução, o modelo otimiza para idiomas menores como francês, russo, japonês e coreano, garantindo coerência semântica em contextos informais. Criadores de conteúdo o utilizam para romances, roteiros e copywriting, beneficiando-se da expansão contextual e da nuance emocional.
O desenvolvimento de personagens virtuais representa outra força, pois o GLM-4.6 mantém um tom consistente em conversas de várias rodadas. Isso o torna ideal para IA social e personificação de marcas. Em busca inteligente e pesquisa aprofundada, o modelo aprimora a compreensão da intenção e a síntese de resultados, entregando saídas perspicazes.
No geral, o GLM-4.6 capacita os desenvolvedores a criar aplicações mais inteligentes. Sua combinação de processamento de contexto longo, uso eficiente de tokens e ampla aplicabilidade o diferencia no cenário da IA. Agora que compreendemos a essência do modelo, passamos ao acesso à sua API para implementação prática.
Como Acessar a API GLM-4.6
A Zhipu AI oferece acesso direto à API GLM-4.6 através de sua plataforma aberta. Os desenvolvedores começam criando uma conta no site da Zhipu AI, especificamente em open.bigmodel.cn ou z.ai. O processo exige a verificação de um e-mail ou número de telefone para garantir um registro seguro.
Após o registro, os usuários assinam o GLM Coding Plan. Este plano desbloqueia o GLM-4.6 e modelos relacionados. Os assinantes obtêm acesso ao painel da API, onde geram chaves de API. Essas chaves servem como credenciais para autenticar solicitações.
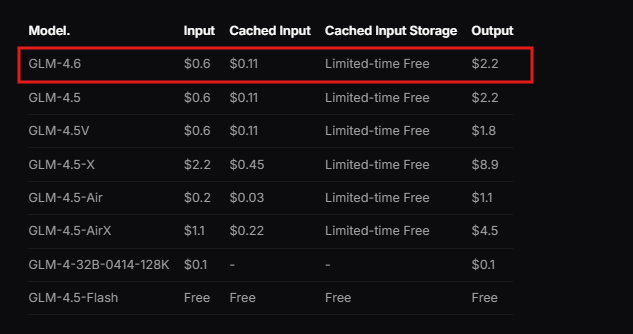
Além disso, a Zhipu AI oferece documentação, que detalha as etapas de integração. Os desenvolvedores revisam este recurso para entender os pré-requisitos, como ambientes de programação compatíveis. A API segue um design RESTful, compatível com clientes HTTP padrão.
Para começar, os usuários navegam até a seção de gerenciamento de API em sua conta. Aqui, eles criam uma nova chave de API e anotam seu valor com segurança. A Zhipu AI recomenda a rotação periódica de chaves por segurança. Além disso, a plataforma fornece cotas de uso com base nos níveis de assinatura, evitando o uso excessivo.
Se os desenvolvedores encontrarem problemas, a equipe de suporte da Zhipu AI ajuda por e-mail ou fóruns. Eles também oferecem recursos da comunidade para solucionar problemas comuns de acesso. Com o acesso garantido, o próximo passo envolve configurar a autenticação para interagir com a API GLM-4.6 de forma eficaz.
Autenticação e Configuração para a API GLM-4.6
A autenticação forma a espinha dorsal das interações seguras da API. A Zhipu AI emprega autenticação de token Bearer para a API GLM-4.6. Os desenvolvedores incluem a chave da API no cabeçalho Authorization de cada solicitação.
Para a configuração, instale as bibliotecas necessárias em seu ambiente de desenvolvimento. Usuários de Python, por exemplo, utilizam a biblioteca requests. Você a importa e configura os cabeçalhos da seguinte forma:
import requests
api_key = "your-api-key"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
Este código prepara o ambiente para enviar solicitações. Da mesma forma, em JavaScript com Node.js, os desenvolvedores usam a API fetch ou a biblioteca axios. Eles definem os cabeçalhos no objeto options.
Além disso, certifique-se de que seu sistema atende aos requisitos de rede. O endpoint da API GLM-4.6 reside em https://api.z.ai/api/paas/v4/chat/completions. Teste a conectividade pingando o domínio ou enviando uma solicitação simples.
Durante a configuração, os desenvolvedores configuram variáveis de ambiente para armazenar a chave da API com segurança. Essa prática evita a codificação rígida de informações sensíveis em scripts. Ferramentas como dotenv em Python ou process.env em Node.js facilitam isso.
Se estiver usando um proxy ou VPN, verifique se ele permite o tráfego para os servidores da Zhipu AI. Falhas de autenticação geralmente decorrem de formatação incorreta da chave ou assinaturas expiradas. A Zhipu AI registra erros nas respostas, ajudando a diagnosticar problemas.
Uma vez autenticados, os desenvolvedores prosseguem para explorar os endpoints. Essa configuração garante acesso confiável e seguro às capacidades do GLM-4.6.
Explorando os Endpoints da API GLM-4.6
A API GLM-4.6 se concentra em um endpoint principal para conclusões de chat. Desenvolvedores enviam solicitações POST para https://api.z.ai/api/paas/v4/chat/completions para gerar respostas.
Este endpoint lida com os modos básico e de streaming. No modo básico, o servidor processa toda a solicitação e retorna uma resposta completa. O modo de streaming, no entanto, entrega a saída incrementalmente, ideal para aplicações em tempo real.
Para invocar o endpoint, construa um payload JSON com os parâmetros necessários. O campo model especifica "glm-4.6". O array messages contém pares role-content, simulando conversas.
Por exemplo, uma solicitação curl básica se parece com isto:
curl -X POST "https://api.z.ai/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-4.6",
"messages": [
{"role": "user", "content": "Generate a Python function for sorting a list."}
]
}'
O servidor responde com JSON contendo o conteúdo gerado. Os desenvolvedores analisam isso para extrair as mensagens do assistente.
Além disso, o endpoint suporta recursos avançados como etapas de raciocínio. Defina o objeto thinking para habilitar o raciocínio detalhado nas saídas.
Compreender este endpoint permite que os desenvolvedores construam sistemas de IA interativos. Em seguida, detalharemos os parâmetros da solicitação.
Explicação Detalhada dos Parâmetros de Solicitação da API GLM-4.6
Os parâmetros de solicitação controlam o comportamento da API GLM-4.6. O parâmetro model exige "glm-4.6" para selecionar esta versão específica.
O array messages impulsiona a conversa. Cada objeto inclui um role – "user" para entradas, "assistant" para respostas anteriores – e content como strings de texto. Desenvolvedores estruturam diálogos multi-turno alternando os papéis.
Além disso, max_tokens limita o comprimento da resposta, evitando saída excessiva. Defina-o para 4096 para resultados equilibrados. Temperature ajusta a aleatoriedade; valores mais baixos como 0.6 produzem saídas determinísticas, enquanto valores mais altos incentivam a criatividade.
Para streaming, inclua "stream": true. Isso altera o formato da resposta para dados em blocos.
O parâmetro thinking permite o raciocínio passo a passo. Defina "thinking": {"type": "enabled"} para incluir pensamentos intermediários nas respostas.
Outros parâmetros opcionais incluem top_p para amostragem de núcleo e presence_penalty para desencorajar a repetição. Os desenvolvedores ajustam estes com base nos casos de uso.
Parâmetros inválidos acionam respostas de erro com códigos como 400 para solicitações inválidas. Sempre valide os payloads antes de enviar.
Ao dominar esses parâmetros, os desenvolvedores personalizam as chamadas da API GLM-4.6 para um desempenho ideal.
Lidando com Respostas da API GLM-4.6
As respostas da API GLM-4.6 chegam em formato JSON. Os desenvolvedores analisam o array choices para acessar o conteúdo gerado.
No modo básico, a resposta inclui:
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1694123456,
"model": "glm-4.6",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Your generated text here."
},
"finish_reason": "stop"
}
]
}
Extraia o campo content para uso em aplicações.
No modo de streaming, as respostas são transmitidas como Server-Sent Events (SSE). Cada bloco segue:
data: {"id":"chatcmpl-...","choices":[{"delta":{"content":" partial text"}}]}
Os desenvolvedores acumulam deltas para construir a saída completa.
O tratamento de erros envolve a verificação de códigos de status. Um 401 indica falha de autenticação, enquanto um 429 sinaliza limites de taxa.
Registre as respostas para depuração. Essa abordagem garante uma integração robusta com a API GLM-4.6.
Exemplos de Código para Integrar a API GLM-4.6
Desenvolvedores implementam a API GLM-4.6 em várias linguagens. Em Python, use requests para uma chamada básica:
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
payload = {
"model": "glm-4.6",
"messages": [{"role": "user", "content": "Explain quantum computing."}],
"max_tokens": 500,
"temperature": 0.7
}
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Este código envia uma consulta e imprime a resposta.
Em JavaScript com Node.js:
const fetch = require('node-fetch');
const url = 'https://api.z.ai/api/paas/v4/chat/completions';
const payload = {
model: 'glm-4.6',
messages: [{ role: 'user', content: 'Write a haiku about AI.' }],
max_tokens: 100
};
const headers = {
'Authorization': 'Bearer your-api-key',
'Content-Type': 'application/json'
};
fetch(url, {
method: 'POST',
body: JSON.stringify(payload),
headers
})
.then(res => res.json())
.then(data => console.log(data.choices[0].message.content));
Para streaming em Python, use bibliotecas de análise SSE como sseclient.
Esses exemplos demonstram integração prática, permitindo que os desenvolvedores criem protótipos rapidamente.
Usando o Apidog para Testar a API GLM-4.6
O Apidog serve como uma excelente ferramenta para testar a API GLM-4.6. Esta plataforma completa permite que os desenvolvedores projetem, depurem, simulem e automatizem interações de API.
Comece baixando o Apidog em apidog.com e criando um projeto. Importe o endpoint da API GLM-4.6 adicionando uma nova API com a URL https://api.z.ai/api/paas/v4/chat/completions.
Defina a autenticação na seção de cabeçalhos do Apidog, adicionando "Authorization: Bearer your-api-key". Configure o corpo da solicitação com parâmetros JSON como model e messages.
O Apidog permite enviar solicitações e visualizar respostas em uma interface amigável. Os desenvolvedores testam variações duplicando solicitações e ajustando parâmetros.
Além disso, automatize testes criando cenários no Apidog. Defina asserções para validar o conteúdo da resposta, garantindo que a API GLM-4.6 se comporte conforme o esperado.
Servidores mock no Apidog simulam respostas para desenvolvimento offline. Esse recurso acelera a prototipagem sem chamadas de API ao vivo.

Ao incorporar o Apidog, os desenvolvedores otimizam os fluxos de trabalho da API GLM-4.6, reduzindo erros e acelerando a implantação.
Melhores Práticas e Limites de Taxa para a API GLM-4.6
Aderir às melhores práticas maximiza o potencial da API GLM-4.6. Os desenvolvedores monitoram o uso para permanecer dentro dos limites de taxa, tipicamente definidos por tokens por minuto ou solicitações por dia com base na assinatura.
Implemente o backoff exponencial para retentativas em erros como 429. Isso evita sobrecarregar o servidor.
Otimize os prompts para clareza para melhorar a qualidade da resposta. Use mensagens de sistema para definir o contexto, guiando o modelo de forma eficaz.
Proteja as chaves da API em ambientes de produção. Evite expô-las em código do lado do cliente.
Registre as interações para auditoria e análise de desempenho. Esses dados informam os aprimoramentos.
Lide com casos extremos, como respostas vazias ou tempos limite, com mecanismos de fallback.
A Zhipu AI atualiza os limites de taxa na documentação; verifique regularmente.
Seguir essas práticas garante o uso eficiente e confiável da API GLM-4.6.
Uso Avançado da API GLM-4.6
Usuários avançados exploram o streaming para aplicações interativas. Defina "stream": true e processe blocos em tempo real.
Incorpore ferramentas incluindo chamadas de função nas mensagens. O GLM-4.6 suporta a invocação de ferramentas, permitindo que agentes executem ações externas.
Por exemplo, defina ferramentas no payload:
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {...}
}
}
]
O modelo responde com chamadas de ferramentas se necessário.
Ajuste a temperatura para tarefas específicas; baixa para consultas factuais, alta para as criativas.
Combine com contextos longos para sumarização de documentos. Alimente textos grandes nas mensagens.
Integre em frameworks de agentes como LangChain para fluxos de trabalho complexos.
Essas técnicas liberam todo o potencial do GLM-4.6 em sistemas sofisticados.
Conclusão
A API GLM-4.6 oferece aos desenvolvedores uma ferramenta poderosa para a inovação em IA. Seguindo este guia, você a integrará perfeitamente em seus projetos. Experimente os recursos, teste usando o Apidog e aplique as melhores práticas para o sucesso. A Zhipu AI continua a evoluir o GLM-4.6, prometendo capacidades ainda maiores no futuro.