
O cenário da IA de código aberto acaba de testemunhar outra mudança sísmica. A Z.ai, a empresa chinesa de IA anteriormente conhecida como Zhipu, lançou o GLM-4.5 e o GLM-4.5 Air, prometendo superar o DeepSeek e estabelecer novos padrões para o desempenho e a acessibilidade da IA. Esses modelos representam mais do que melhorias incrementais — eles incorporam uma reformulação fundamental de como o raciocínio híbrido e as capacidades de agente devem funcionar em ambientes de produção.
O lançamento chega em um momento crucial, quando os desenvolvedores demandam cada vez mais alternativas econômicas aos modelos proprietários, sem sacrificar a capacidade. Tanto o GLM-4.5 quanto o GLM-4.5 Air cumprem essa promessa por meio de inovações arquitetônicas sofisticadas que maximizam a eficiência, mantendo o desempenho de ponta em tarefas de raciocínio, codificação e multimodais.
Compreendendo a Revolução da Arquitetura GLM-4.5
A série GLM-4.5 representa uma partida significativa das arquiteturas de transformadores tradicionais. Construído em uma arquitetura totalmente autodesenvolvida, o GLM-4.5 alcança desempenho SOTA (State-of-the-Art) em modelos de código aberto por meio de várias inovações chave que o distinguem dos concorrentes.
O GLM-4.5 possui 355 bilhões de parâmetros totais com 32 bilhões de parâmetros ativos, enquanto o GLM-4.5 Air adota um design mais compacto com 106 bilhões de parâmetros totais e 12 bilhões de parâmetros ativos. Essa configuração de parâmetros reflete um equilíbrio cuidadoso entre eficiência computacional e capacidade do modelo, permitindo que ambos os modelos entreguem um desempenho impressionante, mantendo custos de inferência razoáveis.
Os modelos utilizam uma arquitetura sofisticada de Mixture of Experts (MoE) que ativa apenas um subconjunto de parâmetros durante a inferência. Ambos aproveitam o design de Mixture of Experts para otimização da eficiência, permitindo que o GLM-4.5 processe tarefas complexas usando apenas 32 bilhões de seus 355 bilhões de parâmetros. Enquanto isso, o GLM-4.5 Air mantém capacidades de raciocínio comparáveis com apenas 12 bilhões de parâmetros ativos de seu pool total de 106 bilhões de parâmetros.
Essa abordagem arquitetônica aborda diretamente um dos desafios mais urgentes na implantação de grandes modelos de linguagem: a sobrecarga computacional da inferência. Modelos densos tradicionais exigem a ativação de todos os parâmetros para cada operação de inferência, criando uma carga computacional desnecessária para tarefas mais simples. A série GLM-4.5 resolve isso por meio de roteamento inteligente de parâmetros que corresponde a complexidade computacional aos requisitos da tarefa.
Além disso, os modelos suportam janelas de contexto de até 128k de entrada e 96k de saída, fornecendo capacidades substanciais de manipulação de contexto que permitem raciocínio de formato longo sofisticado e análise abrangente de documentos. Essa janela de contexto estendida prova ser particularmente valiosa para aplicações de agente, onde os modelos devem manter a consciência de interações complexas de várias etapas.
Características de Desempenho Otimizadas do GLM-4.5 Air
O GLM-4.5 Air surge como o campeão de eficiência da série, projetado especificamente para cenários onde os recursos computacionais exigem gerenciamento cuidadoso. O GLM-4.5 Air é um modelo fundamental projetado especificamente para aplicações de agente de IA, construído sobre uma arquitetura Mixture-of-Experts (MoE) que prioriza a velocidade e a otimização de recursos sem comprometer as capacidades essenciais.
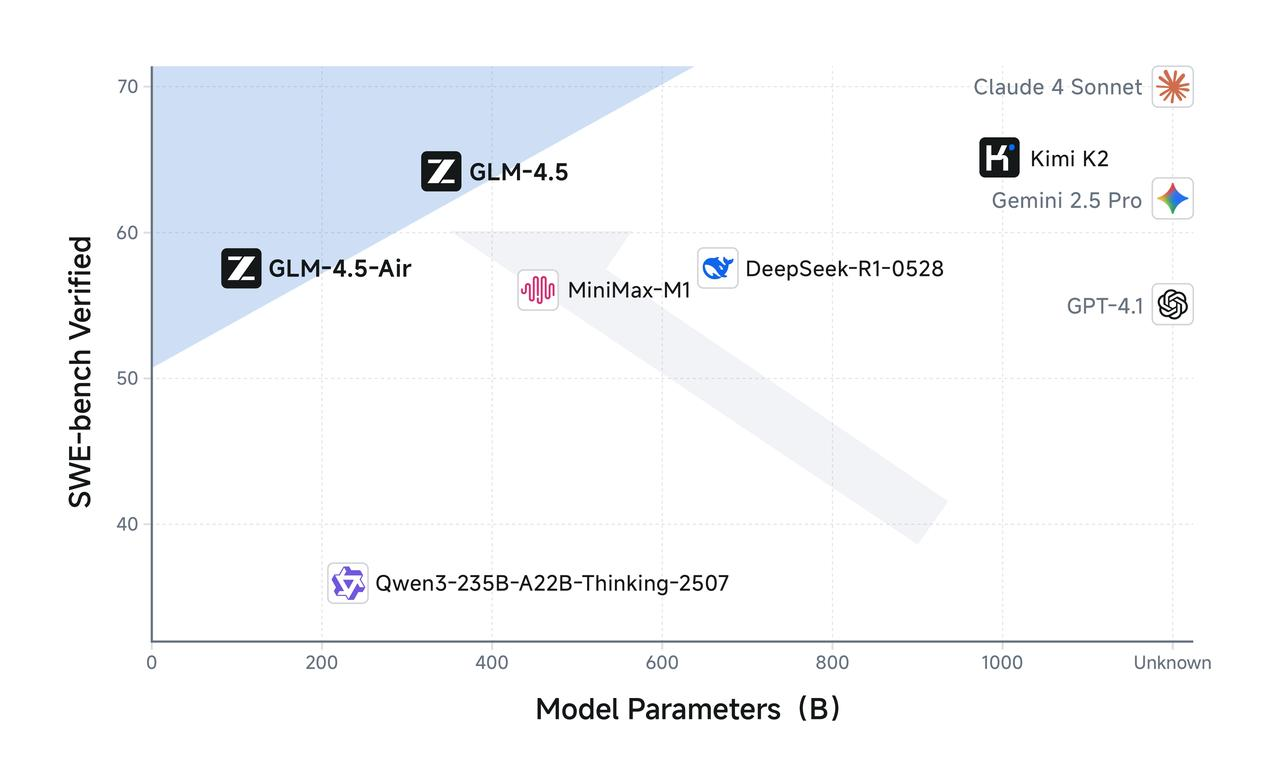
A variante Air demonstra como a redução cuidadosa de parâmetros pode manter a qualidade do modelo, melhorando dramaticamente a viabilidade de implantação. Com 106 bilhões de parâmetros totais e 12 bilhões de parâmetros ativos, o GLM-4.5 Air alcança ganhos de eficiência notáveis que se traduzem diretamente em custos de inferência reduzidos e tempos de resposta mais rápidos.
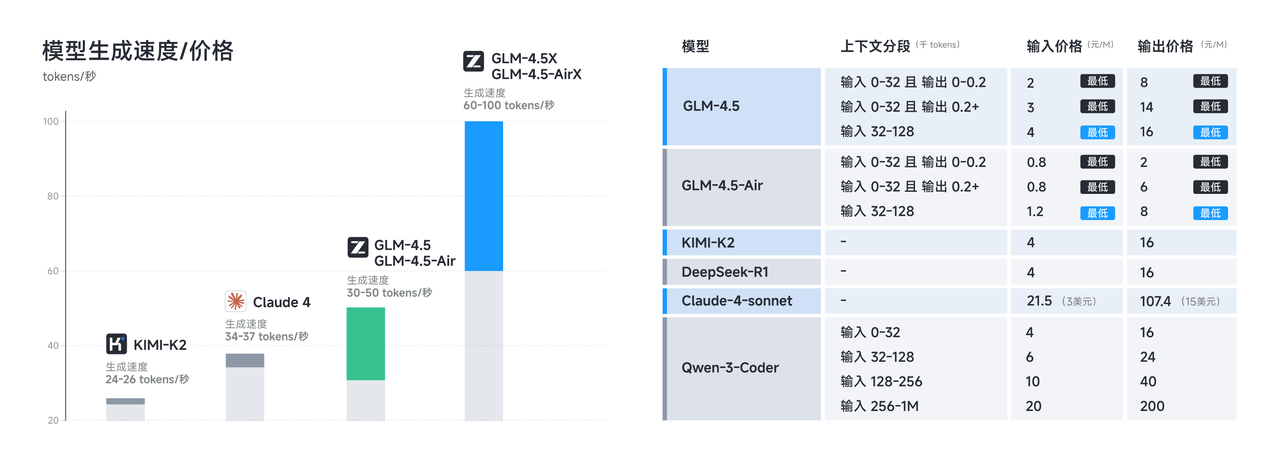
Os requisitos de memória representam outra área em que o GLM-4.5 Air se destaca. O GLM-4.5 Air requer 16GB de memória GPU (INT4 quantizado em ~12GB), tornando-o acessível a organizações com restrições moderadas de hardware. Esse fator de acessibilidade é crucial para a adoção generalizada, já que muitas equipes de desenvolvimento não conseguem justificar os custos de infraestrutura associados a modelos maiores.
A otimização se estende além da pura eficiência de parâmetros para abranger treinamento especializado para tarefas orientadas a agentes. Ele foi extensivamente otimizado para uso de ferramentas, navegação na web, desenvolvimento de software e desenvolvimento front-end, permitindo integração perfeita com agentes de codificação. Essa especialização significa que o GLM-4.5 Air oferece desempenho superior em tarefas práticas de desenvolvimento em comparação com modelos de propósito geral de tamanho similar.
A latência de resposta torna-se particularmente importante em aplicações interativas onde os usuários esperam feedback quase instantâneo. A contagem reduzida de parâmetros do GLM-4.5 Air e o pipeline de inferência otimizado permitem tempos de resposta em menos de um segundo para a maioria das consultas, tornando-o adequado para aplicações em tempo real, como preenchimento de código, depuração interativa e geração de documentação ao vivo.
Implementação e Benefícios do Raciocínio Híbrido
A característica definidora de ambos os modelos GLM-4.5 reside em suas capacidades de raciocínio híbrido. Tanto o GLM-4.5 quanto o GLM-4.5 Air são modelos de raciocínio híbrido que oferecem dois modos: modo de pensamento para raciocínio complexo e uso de ferramentas, e modo não-pensamento para respostas imediatas. Essa arquitetura de modo duplo representa uma inovação fundamental na forma como os modelos de IA lidam com diferentes tipos de tarefas cognitivas.
O modo de pensamento é ativado quando os modelos encontram problemas complexos que exigem raciocínio em várias etapas, uso de ferramentas ou análise estendida. Durante o modo de pensamento, os modelos geram etapas de raciocínio intermediárias que permanecem visíveis para os desenvolvedores, mas ocultas para os usuários finais. Essa transparência permite a depuração e otimização dos processos de raciocínio, mantendo interfaces de usuário limpas.
Por outro lado, o modo não-pensamento lida com consultas diretas que se beneficiam de respostas imediatas, sem sobrecarga de raciocínio estendido. O modelo determina automaticamente qual modo empregar com base na complexidade e contexto da consulta, garantindo a utilização ideal dos recursos em diversos casos de uso.
Essa abordagem híbrida resolve um desafio persistente em sistemas de IA de produção: equilibrar a velocidade de resposta com a qualidade do raciocínio. Modelos tradicionais sacrificam a velocidade por um raciocínio abrangente ou fornecem respostas rápidas, mas potencialmente superficiais. O sistema híbrido do GLM-4.5 elimina essa compensação, combinando a complexidade do raciocínio com os requisitos da tarefa.
Ambos fornecem modo de pensamento para tarefas complexas e modo não-pensamento para respostas imediatas, criando uma experiência de usuário fluida que se adapta a diversas demandas cognitivas. Os desenvolvedores podem configurar parâmetros de seleção de modo para ajustar o equilíbrio entre velocidade e profundidade de raciocínio com base nos requisitos específicos da aplicação.
O modo de pensamento prova ser particularmente valioso para aplicações de agente, onde os modelos devem planejar ações em várias etapas, avaliar opções de uso de ferramentas e manter um raciocínio coerente em interações estendidas. Enquanto isso, o modo não-pensamento garante desempenho responsivo para consultas simples, como pesquisas de fatos ou tarefas diretas de preenchimento de código.
Especificações Técnicas e Detalhes de Treinamento
A base técnica que sustenta as impressionantes capacidades do GLM-4.5 reflete um extenso esforço de engenharia e metodologias de treinamento inovadoras. Treinados em 15 trilhões de tokens, com suporte para janelas de contexto de até 128k de entrada e 96k de saída, os modelos demonstram a escala e a sofisticação necessárias para um desempenho de ponta.
A curadoria de dados de treinamento representa um fator crítico na qualidade do modelo, particularmente para aplicações especializadas como geração de código e raciocínio de agente. O corpus de treinamento de 15 trilhões de tokens incorpora diversas fontes, incluindo repositórios de código, documentação técnica, exemplos de raciocínio e conteúdo multimodal que permite uma compreensão abrangente em todos os domínios.
As capacidades da janela de contexto distinguem o GLM-4.5 de muitos modelos concorrentes. O GLM-4.5 oferece 128k de comprimento de contexto e capacidade de chamada de função nativa, permitindo análise sofisticada de formato longo e conversas multi-turno sem truncamento de contexto. A janela de contexto de saída de 96k garante que os modelos possam gerar respostas abrangentes sem limitações artificiais de comprimento.
A chamada de função nativa representa outra vantagem arquitetônica que elimina a necessidade de camadas de orquestração externas. Os modelos podem invocar diretamente ferramentas e APIs externas como parte de seu processo de raciocínio, criando fluxos de trabalho de agente mais eficientes e confiáveis. Essa capacidade é essencial para aplicações de produção onde os modelos devem interagir com bancos de dados, serviços externos e ferramentas de desenvolvimento.
O processo de treinamento incorpora otimização especializada para tarefas de agente, garantindo que os modelos desenvolvam fortes capacidades no uso de ferramentas, raciocínio em várias etapas e manutenção de contexto. A arquitetura unificada para raciocínio, codificação e fluxos de trabalho de percepção-ação multimodal permite transições perfeitas entre diferentes tipos de tarefas dentro de interações únicas.
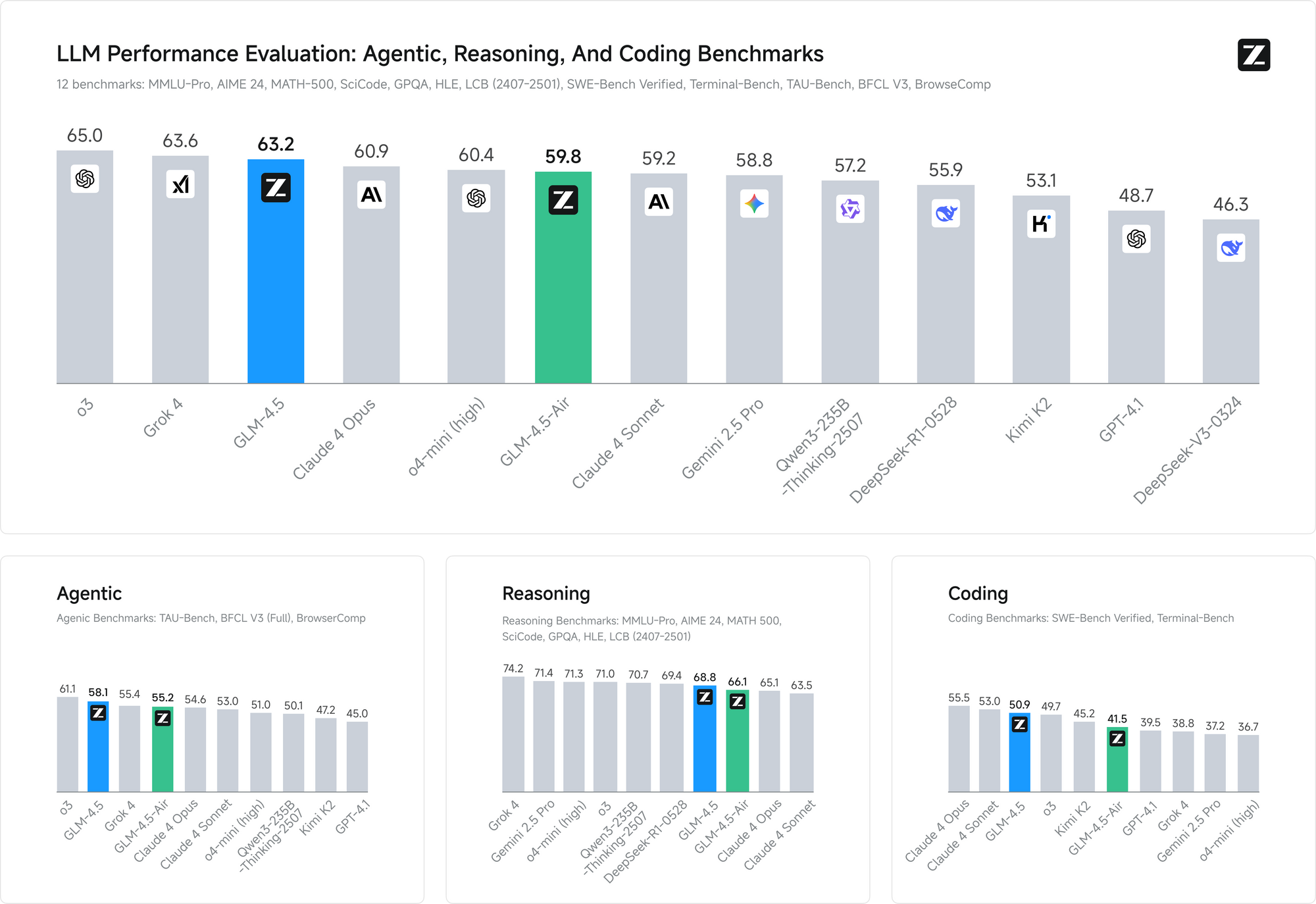
Os benchmarks de desempenho validam a eficácia dessas abordagens de treinamento. Em ambos os benchmarks, o GLM-4.5 iguala o desempenho do Claude em avaliações de capacidade de agente, demonstrando capacidade competitiva contra modelos proprietários líderes, mantendo a acessibilidade de código aberto.
Vantagens de Licenciamento e Implantação Comercial
O licenciamento de código aberto representa uma das vantagens competitivas mais significativas do GLM-4.5 no cenário atual da IA. Os modelos base, os modelos híbridos (pensamento/não-pensamento) e as versões FP8 são todos lançados para uso comercial irrestrito e desenvolvimento secundário sob a licença MIT, proporcionando uma liberdade sem precedentes para a implantação comercial.
Essa abordagem de licenciamento elimina muitas restrições que limitam outros modelos de código aberto. As organizações podem modificar, redistribuir e comercializar implementações do GLM-4.5 sem taxas de licenciamento ou restrições de uso. A licença MIT aborda especificamente as preocupações comerciais que muitas vezes complicam as implantações de IA empresarial.
Múltiplos Métodos de Acesso e Integração de Plataforma
O GLM-4.5 e o GLM-4.5 Air oferecem aos desenvolvedores múltiplos caminhos de acesso, cada um otimizado para diferentes casos de uso e requisitos técnicos. Compreender essas opções de implantação permite que as equipes selecionem o método de integração mais apropriado para suas aplicações específicas.
Site Oficial e Acesso Direto à API
O método de acesso principal envolve o uso da plataforma oficial da Z.ai em chat.z.ai, que fornece uma interface amigável para interação imediata com o modelo. Essa interface baseada na web permite prototipagem e testes rápidos sem exigir trabalho de integração técnica. Os desenvolvedores podem avaliar as capacidades do modelo, testar estratégias de engenharia de prompt e validar casos de uso antes de se comprometerem com implementações de API.
O acesso direto à API por meio dos endpoints oficiais da Z.ai fornece capacidades de integração de nível de produção com documentação e suporte abrangentes. A API oficial oferece controle granular sobre os parâmetros do modelo, incluindo seleção do modo de raciocínio híbrido, utilização da janela de contexto e opções de formatação de resposta.
Integração com OpenRouter para Acesso Simplificado
O OpenRouter fornece acesso simplificado aos modelos GLM-4.5 por meio de sua plataforma de API unificada em openrouter.ai/z-ai. Esse método de integração é particularmente valioso para desenvolvedores que já utilizam a infraestrutura multi-modelo do OpenRouter, pois elimina a necessidade de gerenciamento separado de chaves de API e padrões de integração.
A implementação do OpenRouter lida automaticamente com autenticação, limitação de taxa e tratamento de erros, reduzindo a complexidade de integração para as equipes de desenvolvimento. Além disso, o formato de API padronizado do OpenRouter permite fácil troca de modelos e testes A/B entre o GLM-4.5 e outros modelos disponíveis sem modificações de código.
O gerenciamento de custos torna-se mais transparente por meio do sistema de faturamento unificado do OpenRouter, que fornece análises detalhadas de uso e controles de gastos em vários provedores de modelos. Essa abordagem centralizada simplifica o gerenciamento de orçamento para organizações que utilizam múltiplos modelos de IA em suas aplicações.
Hugging Face Hub para Implantação de Código Aberto
O Hugging Face Hub hospeda modelos GLM-4.5, fornecendo cards de modelo abrangentes, documentação técnica e exemplos de uso impulsionados pela comunidade. Essa plataforma se mostra essencial para desenvolvedores que preferem padrões de implantação de código aberto ou que exigem extensa personalização de modelos.
A integração com o Hugging Face permite a implantação local usando a biblioteca Transformers, dando às organizações controle total sobre a hospedagem do modelo e a privacidade dos dados. Os desenvolvedores podem baixar os pesos do modelo diretamente, implementar pipelines de inferência personalizados e otimizar as configurações de implantação para ambientes de hardware específicos.
Opções de Implantação Auto-Hospedada
Organizações com requisitos rigorosos de privacidade de dados ou necessidades de infraestrutura especializada podem implantar modelos GLM-4.5 usando configurações auto-hospedadas. A licença MIT permite a implantação irrestrita em ambientes de nuvem privada, infraestrutura local ou arquiteturas híbridas.
A implantação auto-hospedada oferece controle máximo sobre o comportamento do modelo, configurações de segurança e padrões de integração. As organizações podem implementar sistemas de autenticação personalizados, infraestrutura de monitoramento especializada e otimizações específicas de domínio sem dependências externas.
A implantação baseada em contêineres usando Docker ou Kubernetes permite implementações auto-hospedadas escaláveis que podem se adaptar a diversas demandas de carga de trabalho. Esses padrões de implantação provam ser particularmente valiosos para organizações com experiência existente em orquestração de contêineres.
Integração com Fluxos de Trabalho de Desenvolvimento Usando Apidog
O desenvolvimento moderno de IA exige ferramentas sofisticadas para gerenciar a integração de modelos, testes e fluxos de trabalho de implantação de forma eficaz em todos esses vários métodos de acesso. O Apidog fornece capacidades abrangentes de gerenciamento de API que simplificam a integração do GLM-4.5, independentemente da abordagem de implantação escolhida.
Ao implementar modelos GLM-4.5 em diferentes plataformas — seja via OpenRouter, acesso direto à API, implantações Hugging Face ou configurações auto-hospedadas — os desenvolvedores devem validar o desempenho em diversos casos de uso, testar diferentes configurações de parâmetros e garantir tratamento de erros confiável. A estrutura de teste de API do Apidog permite a avaliação sistemática das respostas do modelo, características de latência e padrões de utilização de recursos em todos esses métodos de implantação.
As capacidades de geração de documentação da plataforma provam ser particularmente valiosas ao implantar o GLM-4.5 através de múltiplos métodos de acesso simultaneamente. Os desenvolvedores podem gerar automaticamente documentação abrangente da API que inclui opções de configuração do modelo, esquemas de entrada/saída e exemplos de uso específicos para as capacidades de raciocínio híbrido do GLM-4.5 em implantações OpenRouter, API direta e auto-hospedadas.
Recursos colaborativos dentro do Apidog facilitam o compartilhamento de conhecimento entre equipes de desenvolvimento que trabalham com implementações GLM-4.5. Os membros da equipe podem compartilhar configurações de teste, documentar as melhores práticas e colaborar em padrões de integração que maximizam a eficácia do modelo.
As capacidades de gerenciamento de ambiente garantem implantações consistentes do GLM-4.5 em ambientes de desenvolvimento, staging e produção, independentemente de as equipes usarem o serviço gerenciado do OpenRouter, integração direta de API ou implementações auto-hospedadas. Os desenvolvedores podem manter configurações separadas para diferentes ambientes, garantindo padrões de implantação reproduzíveis.
Estratégias de Implementação e Melhores Práticas
A implantação bem-sucedida de modelos GLM-4.5 requer consideração cuidadosa dos requisitos de infraestrutura, técnicas de otimização de desempenho e padrões de integração que maximizam a eficácia do modelo. As organizações devem avaliar seus casos de uso específicos em relação às capacidades do modelo para determinar as configurações de implantação ideais.
Os requisitos de hardware variam significativamente entre o GLM-4.5 e o GLM-4.5 Air, permitindo que as organizações selecionem variantes que correspondam às suas restrições de infraestrutura. Equipes com infraestrutura de GPU robusta podem aproveitar o modelo GLM-4.5 completo para capacidade máxima, enquanto ambientes com recursos limitados podem achar que o GLM-4.5 Air oferece desempenho suficiente com custos de infraestrutura reduzidos.
O ajuste fino do modelo representa outra consideração crítica para organizações com requisitos especializados. A licença MIT permite a personalização abrangente do modelo, permitindo que as equipes adaptem o GLM-4.5 para aplicações específicas de domínio. No entanto, o ajuste fino requer curadoria cuidadosa de conjuntos de dados e experiência em treinamento para alcançar resultados ótimos.
A configuração do modo híbrido requer ajuste cuidadoso de parâmetros para equilibrar a velocidade de resposta com a qualidade do raciocínio. Aplicações com requisitos rigorosos de latência podem preferir padrões mais agressivos do modo não-pensamento, enquanto aplicações que priorizam a qualidade do raciocínio podem se beneficiar de limites mais baixos do modo de pensamento.
Os padrões de integração de API devem aproveitar as capacidades de chamada de função nativa do GLM-4.5 para criar fluxos de trabalho de agente eficientes. Em vez de implementar camadas de orquestração externas, os desenvolvedores podem confiar nas capacidades de uso de ferramentas incorporadas ao modelo para reduzir a complexidade do sistema e melhorar a confiabilidade.
Considerações de Segurança e Gerenciamento de Riscos
A implantação de modelos de código aberto como o GLM-4.5 introduz considerações de segurança que as organizações devem abordar por meio de estratégias abrangentes de gerenciamento de riscos. A disponibilidade dos pesos do modelo permite uma auditoria de segurança completa, mas também exige manuseio cuidadoso para evitar acesso não autorizado ou uso indevido.
A segurança da inferência do modelo exige proteção contra entradas adversárias que possam comprometer o comportamento do modelo ou extrair informações sensíveis dos dados de treinamento. As organizações devem implementar validação de entrada, filtragem de saída e sistemas de detecção de anomalias para identificar interações potencialmente problemáticas.
A segurança da infraestrutura de implantação torna-se crítica ao hospedar modelos GLM-4.5 em ambientes de produção. Práticas de segurança padrão, incluindo isolamento de rede, controles de acesso e criptografia, aplicam-se às implantações de modelos de IA da mesma forma que se aplicam a aplicações tradicionais.
As considerações de privacidade de dados exigem atenção cuidadosa aos fluxos de informação entre aplicações e modelos GLM-4.5. As organizações devem garantir que as entradas de dados sensíveis recebam proteção apropriada e que as saídas do modelo não exponham inadvertidamente informações confidenciais.
A segurança da cadeia de suprimentos se estende à proveniência do modelo e à verificação de integridade. As organizações devem validar os checksums do modelo, verificar as fontes de download e implementar controles que garantam que os modelos implantados correspondam às configurações pretendidas.
A natureza de código aberto do GLM-4.5 permite uma auditoria de segurança abrangente que oferece vantagens sobre modelos proprietários, onde as propriedades de segurança permanecem opacas. As organizações podem analisar a arquitetura do modelo, as características dos dados de treinamento e as potenciais vulnerabilidades por meio de exame direto, em vez de depender de afirmações de segurança do fornecedor.
Conclusão
O GLM-4.5 e o GLM-4.5 Air representam avanços significativos nas capacidades de IA de código aberto, entregando desempenho competitivo enquanto mantêm a acessibilidade e a flexibilidade que definem projetos de código aberto bem-sucedidos. A Z.ai lançou seu modelo base de próxima geração, o GLM-4.5, alcançando desempenho SOTA em modelos de código aberto por meio de inovações arquitetônicas que abordam desafios de implantação no mundo real.
A arquitetura de raciocínio híbrido demonstra como um design cuidadoso pode eliminar as compensações tradicionais entre velocidade de resposta e qualidade de raciocínio. Essa inovação fornece um modelo para o desenvolvimento futuro de modelos que prioriza a utilidade prática em detrimento do desempenho puro de benchmarking.
As vantagens de eficiência de custo tornam o GLM-4.5 acessível a organizações que anteriormente consideravam as capacidades avançadas de IA proibitivamente caras. A combinação de custos de inferência reduzidos e licenciamento permissivo cria oportunidades para a implantação de IA em diversas indústrias e tamanhos de organização.